В данной серии статей я подробно расскажу о том, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL с использованием Spark RDD API, заточенный на задачи подготовки и трансформации наборов данных.
— Евдокимов, ты что, совсем уже там кукухой поехал?! При живом-то Spark SQL! Опять ты ненормальным программированием маешься, нет бы что-то полезное делал…
— Ну-ну-ну, спокойно, спокойно. Я ещё настолько не уехал, чтобы потратить целый год на страдание полной ерундой. Речь на сей раз пойдёт не о развлекухе, а о диалекте языка, специализированном для решения целого класса задач, для которых любой существующий SQL был бы, в теории, хорошим решением, если бы не несколько серьёзных «но».
Короче, у нас будет немного не такой SQL, который вы все так хорошо знаете, но и этот вариант вы полюбите, я обещаю. Тут лучше другой вопрос задать:
— Разве кому-то нужен голый SQL-ный движок?
Нет, голый — не нужен. Так рассказывать я буду о разработке настоящего production ready инструмента, с интерактивным шеллом с подсветкой синтаксиса и автодополнением, который сможет работать в клиент-серверном режиме, и не только на кластере, но и локально. Да не монолитный, а расширяемый при помощи подключаемых функций. И с автогенератором документации впридачу. Короче, всё будет совсем по-взрослому, с рейтингом M for Mature.
Уровень сложности данной серии статей — высокий. Базовые понятия по ходу текста вообще не объясняются, да и продвинутые далеко не все. Поэтому, если вы не разработчик, уже знакомый с терминологией из области бигдаты и жаргоном из дата инжиниринга, данные статьи будут сложно читаться, и ещё хуже пониматься. Я предупредил.
0. Постановка задачи
Так-так-так, что значит «немножко не такой SQL, который мы знаем»? Дьявол, ведь, как обычно скрывается в деталях постановки задач. Давайте же для начала по пунктам разберём, что у нас есть, а чего хотелось бы поиметь, будь такая возможность.
- Во-первых, Spark SQL — это аналитический инструмент. Основной примитив нём — это запись датафрейма, состоящая из типизированных колонок. Для процессов ETL, где основной примитив — это набор данных целиком, он подходит… так себе.
Как бы вот и всё, второй и последующие пункты уже можно даже не писать. Вот оно, ключевое отличие.
Но процессы ETL — не аналитические, в норме в них не происходит разбора данных на уровне полей записи для последующей хитрой агрегацией и схлопывания в некий показатель. В них обычно набор данных потребляется целиком, а записи в 99% случаев просто итерируются в духе «возьми всё оттуда, профильтруй, и перебутыль в другое местоположение, сменив формат». То есть, манипуляции, происходящие с данными ещё до их анализа, либо уже после него.
Впрочем, для большей полноты картины следует накидать ещё несколько фактоидов.
- Spark SQL бесполезен без статически типизированной схемы данных. Рантайму даже для сериализации заранее нужна информация о типах, а для эффективного процессинга требуется либо доступ к Hive Metastore, либо его эмуляция в том или ином виде. Либо необходимо озаботиться ещё каким-нибудь способом инференса схемы в рантайме, если она неизвестна до запуска процесса — то есть, нужен внешний обвязочный код не на SQL. В самом SQL доопределить частичную схему не получится, а создать колонку таблицы без точного указания её типа вообще нельзя.
- Spark Dataframes под капотом это всего лишь
Dataset[Row], и заточено оно именно под колоночные таблицы. Что же касается объектов произвольной структуры, то некоторая поддержка JSON имеется, но без заранее определённой схемы опять фиг что с ним полезного сделаешь. Да и JSON-объекты не первого класса — они будут не записью целиком, а всего лишь колонкой. - С мутабельностью в широком смысле тоже всё не ахти. Добавить в датафрейм новую колонку можно, как и сменить её тип, но вот смена типа записи, если нам хочется конвертировать объект в другой тип целиком — это уже что-то из области нездоровых фантазий.
- Управление партиционированием несколько, как бы это сказать… контринтуитивное, что ли. По крайней мере, негибкое из-за привязки к изначальной ориентации на колоночную структуру записей. Так просто взять, и запартиционировать датафрейм по взятому от балды выражению не получится.
Ну и так далее.
Spark SQL отлично помогает при выборках записей из данных уже приготовленных, и густо обмазанных метаданными, но не очень подходит для процессов ETL, в которых надо брать сырую дату крупными кусками из ненадёжного источника, и творить с ней всякие непотребства, типа санитизации, фильтрации, и трансформа в требуемый формат, не обращая пристального внимания на всякие мелочи типа NULL там, где его по приблизительной и неполной «схеме» не может быть (но поставщик опять лажанулся, и поэтому мы — бух! — упали на ровном месте).
Впрочем, любой другой классический SQL движок (равно как и большинство NoSQL и NewSQL) всегда изначально затачивается именно для аналитики. Всякие там window functions, UPSERTs, GROUP BY, вот это вот всё — требует статической типизации на уровне колонок.
Может быть, не SQL тогда? Свет клином не сошёлся на нём, зачем вообще так сильно привязываться?
Это хороший вопрос, однако, найти на него ответ лично мне за последние лет этак -надцать так и не удалось. SQL удобен, популярен, идиоматичен, и вообще давно уже является синонимом работы с данными. Аналитики его знают и любят. Просто, факт есть факт, что имеющиеся на рынке имплементации заточены чуточку не в ту сторону, либо совсем уж настолько нишевые, что неудобны в процессах из-за недружелюбности к окружению.
No-code решения? Увольте, но нет. Аналитикам категорически не нравится рисовать процессы квадратиками мышью на канвасе. Это поначалу кажется прикольным, но на 20-й раз уже слишком долго, и муторно. Неэффективно, короче. Аналитикам намного больше нравится писать код. На Питоне или на SQL — не столь важно, лишь бы в любимом редакторе с подсветочкой синтаксиса. Хранить его хочется не где-нибудь, а в гитовом репозитории, деплоить на прод через привычный CD, да в конце концов даже автоматизировать генерацию этого самого кода.
А no-code решения для автоматизации ETL в лучшем случае предлагают какой-нибудь overly glorified cron, и это не то, с чем приятно работать на постоянной основе.
А Spark почему?
Да всё потому же. Spark — это общепринятая платформа для вычислений с большими данными. Инфраструктуры под него много всякой на любой вкус, — любой облачный провайдер предлагает кластера на выбор, но и с запуском на своём железе тоже проблем нет. Технология давно уже повзрослевшая, и накопленных практик много. Попыток заменить Spark предпринимается много, но пока что ни одна к заметному успеху не привела.
Следовательно, почему бы в таком случае не написать на нём что-то своё, только изначально изогнутое в нужном направлении?
Главное ведь начать.
Но перед тем, как сформулировать требования к инструменту, лишённому недостатков и полному удобств, давайте-ка сделаем ещё одно краткое лирическое отступление (или исторический экскурс).
Конвейеры ETL, как бы странно это ни звучало, обычно разрабатываются по остаточному принципу. Инфраструктура продакшена всегда затачивается под аналитику — и это правильно, ведь в анализе данных обычно (!) именно аналитика приносит все деньги. А ETL — это досадные накладные расходы, нужные только на этапе инджеста даты из каких-то внешних (относительно окружения анализа) источников, или выгрузки результата. Вот и получается, что если аналитикам помимо Spark требуется PostgreSQL и Kafka, то operations инженеру придётся строить конвейер инджеста на постгре и кафке. А если аналитикам нужен ClickHouse и Airflow, то на клике с пловом.
Нет каких-то общепринятых инструментов, которые гордо бы позиционировали себя именно как заточенные под ETL решения, вот и получается, что каждый конвейер ETL штука уникальная, не отчуждаемая от окружения, в котором она была выстроена. Попробуй повтори. Попробуй смасштабируй. Попробуй мигрируй, если надо переезжать.
МартышкинСизифов труд.
— Конец отступления.
А теперь представим себе, что на некоем сферическом в вакууме проекте процессы ETL занимают по времени и ресурсам 40% от общего объёма работ, — грубо говоря, столько же, сколько и сама аналитика. Причём, процессы достаточно уникальные, из-за чего аналитики тоже принимают непосредственное в них участие. На таком deeply cursed проекте сделать конвейер по остаточному принципу уже совсем не получится, потому что будет он в таком случае крайне неэффективным.
К моему вящему несчастью, проект, на котором я работаю, именно такой. Из-за его специфики поставщики данных постоянно меняются, из-за чего меняются и форматы, и объёмы, и характеристики, и качество наборов данных. Аналитика остаётся более-менее стабильной, хоть и тоже сильно варьирует от расчёта к расчёту, и ей очень, очень сильно требуется какой-то инструмент для постоянно обновляемых процессов ETL, чтобы было вообще что потреблять, и, главное, было удобно это потреблять.
К моему счастью же, я из тех инженеров, кто может взять жабу голыми руками за правильное место, и написать инструмент для себя и своих пользователей. Я, в общем-то, ведь не столько даже ops, сколько разработчик, и опыта у меня буквально десятилетия, так что при наличии требований, и полугодика времени на проектирование, что-нибудь путное да получится разработать.
Итак, требования.
- Диалект SQL, чтобы был достаточно похож на стандарт (и аналитикам будет удобно, и редакторы кода не смутятся).
- We’re flying fully schema-less. На фиг нам не сдался никакой метастор, ведь у нас поставщики меняются как перчатки, а результат расчёта для каждого проекта имеет свою схему. Пускай скрипт содержит схему у себя внутре, да и то ad hoc, то есть, только там, где она ему реально нужна.
- Основной примитив — это набор данных целиком, а не какая-то там запись…
3.1. Тем не менее, он должен быть с объектной системой типов (причём поддерживать произвольных объектов).
3.2. Мутабельный. Ещё и мутабельный, да! - Поддержка геометрии на уровне языка. Потому что проект моего работодателя таки по-прежнему геоинформационный, вот почему.
- Чистый Spark без ненужных левых зависимостей. Чтобы работало вообще везде. Хоть в облаке, хоть на железе, хоть в локальной виртуалке под WSL.
- REPL с подсветкой синтаксиса и автокомплитом. При отладке процесса что может быть полезнее?
- Неплохо бы поддерживать переменные, интерполяцию строк, ветвления, и циклы. Чутка императивности декларативному языку никогда не помешает.
- Дать возможность управлять партиционированием по произвольному выражению.
- ???
- PROFIT! А не, пускай лучше будет с открытым исходным кодом. Профит мы как-нибудь заработаем на внедрении и техподдержке.
Штош, it sounds like a plan.
Спойлер: ✅ выполнен, кроме последнего пункта. На разработку ушло полгода. На внедрение ещё столько же. Исходники тут лежат, собери да юзай… Правда, не прочитав прилагающийся комплект документации, даже и пытаться не стоит.
Но у нас как бы тут цикл статей о разработке, так что будем теперь рассказывать потихонечку о том, что да почему. А главное, зачем и как.
1. Проектирование языка. Операторы жизненного цикла наборов данных
На самом деле, не с нуля я начал разрабатывать «специальный диалект SQL», ой не с нуля.
Тут вон даже статейку писал как-то о том, как разобрать SELECT при помощи ANTLR, щепотки упоротости, и какой-то там магии. Потом я этот парсер ещё чуточку подшаманил, перенёс на Spark RDD API, и воткнул в другой свой предыдущий инструмент, — так сказать, для пробы пера, проверить, насколько это будет осмысленно. Вдруг окажется настолько сложно в реализации и нефункционально в использовании, что вся затея — это бесполезная трата времени?
Как ни странно, но оказалось не так уж и страшно, и вполне работоспособно. Однако, то было всё наспех сделано, да сбоку присобачено, а теперь пришло время сделать по-нормальному, с интерпретатором в качестве настоящего ядра.
И говоря о «какой-то там магии». Её будет использоваться, но немного: собственно, только ANTLR генератор в виде мавеновского плагина, который из формальной грамматики сделает нам готовый лексер и парсер / AST visitor. Остальное уже мы сами напишем.
Итак, давайте посмотрим на наш синтаксис грамматики парсера (лексикон отдельно рассматривать смысла особого нет, там всё максимально прозрачно):
parser grammar TDL4; options { tokenVocab=TDL4Lexicon; } script : ( statement S_SCOL )* EOF ; loose_expression : ( is_op | between_op | in_op | comparison_op | var_name | L_NUMERIC | L_STRING | S_NULL | S_TRUE | S_FALSE | S_OPEN_PAR | S_CLOSE_PAR | expression_op | digest_op | random_op | bool_op | default_op )+ EOF ;
Что важно понимать: правил верхнего уровня у нас не одно, а два. Первое — скрипт целиком, состоящий из операторов языка, заканчивающихся обязательной точкой с запятой. С ним всё ясно, мы собираемся разбирать их последовательно, в порядке обнаружения, и ж0стко интерпретировать.
А второе правило — «выражение россыпью», которое представляет собой суп из литералов, символов, имён, операторов выражений, — оно нам зачем?
Необходимость следует из требования №7 — про интерполяцию строк. Если мы хотим вычислять на лету литералы типа "typed/{($YEAR * 10000 + $MONTH * 100 + $DAY) DIGEST 'MD5'}", то без разбора таких выражений в отдельном контексте нам не обойтись. По сути, это не что иное как eval, что также может быть полезно как отладочная фича (мотаем на ус для REPL). Вычислять выражения мы будем на стековой машине, а собирать в RPN классическим алгоритмом Shunting Yard при помощи таблицы приоритетов операторов выражений. Но об этом позже.
Сначала операторы языка. Какие ваши операторы?
statement : create_stmt | transform_stmt | copy_stmt | let_stmt | loop_stmt | if_stmt | select_stmt | call_stmt | analyze_stmt | options_stmt ;
Наши операторы языка строго соответствуют жизненному циклу набора данных в типичном процессе ETL. Проясним, наконец, что это за процесс такой, и в чём его правда.
Согласно определению, стоит он из таких фаз: Extract → Transform → Load.
В нашем случае, фаза экстракции — это прежде всего регистрация физического представления набора данных в контексте исполнения, и подгрузка его в память. Файлы, объектное хранилище, БД, или что ещё там у нас может быть источником? Чтобы закрепить за набором данных какое-то имя, нам нужно сказать CREATE DS.
Дальше мы каким-то образом трансформируем набор данных: меняем его формат (например, из текста с разделителями в геометрии точек с именованными атрибутами), фильтруем записи (запросами с предикатом), разделяем набор на несколько (выборками), объединяем несколько в один (какой-нибудь JOIN), аугментируем (добавляя атрибуты по набору правил), и так далее, и тому подобное. Может быть, даже новые наборы генерируем из существующих. Это всё фаза трансформации, тут куча всего происходит. И для всего этого у нас есть операторы TRANSFORM, SELECT, CALL.
Последняя фаза у нас загрузки — точнее, относительно внутренней логики инструмента, выгрузки — подготовленных данных из контекста ETL прямиком в аналитическое хранилище. Оператор COPY DS.
Если в процессе потребуется посмотреть какую-то статистику по набору данных, мы заведём для этого специальный оператор ANALYZE.
Наконец, для управления всей этой красотой на уровне логики скрипта у нас предназначены операторы установки переменных LET, ветвления IF, и цикла LOOP. А также есть ещё OPTIONS, который установит настройки самого нашего контекста исполнения.
Вот и будем разбирать все перечисленные по порядочку.
Сначала оператор CREATE:
create_stmt : K_CREATE K_DS? ds_name func_expr K_FROM expression partition? ( K_BY ( S_HASHCODE | K_SOURCE | S_RANDOM ) )? ; partition : K_PARTITION expression ; func_expr : func ( S_OPEN_PAR params_expr? S_CLOSE_PAR )? ; params_expr : param ( S_COMMA param )* ; param : S_AT L_IDENTIFIER S_EQ expression | S_AT L_IDENTIFIER S_EQ array ; array : S_ARRAY? S_OPEN_BRACKET L_STRING ( S_COMMA L_STRING )* S_CLOSE_BRACKET | S_ARRAY? S_OPEN_BRACKET L_NUMERIC ( S_COMMA L_NUMERIC )* S_CLOSE_BRACKET | S_ARRAY? S_OPEN_BRACKET L_IDENTIFIER ( S_COMMA L_IDENTIFIER )* S_CLOSE_BRACKET ;
Как-то немало всего и сразу, не находите? Но здесь мы разом видим все базовые примитивы синтаксиса нашего диалекта SQL, которые используются и во всех остальных операторах: имена, функциональные выражения, списки параметров, массивы. Но это нормально, потому что вживую получается очень просто всё:
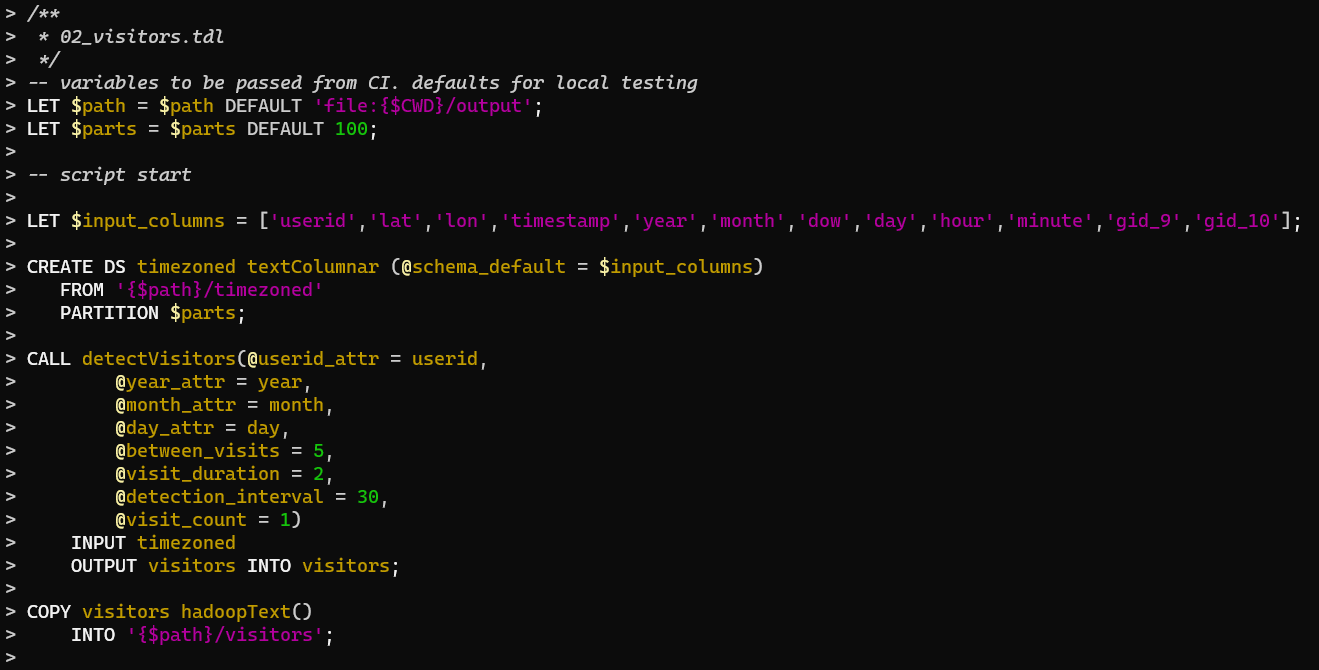
CREATE DS "имяНабораДанных" "имяФункцииЗагрузки"( @параметр1 = выражение1, @параметр2 = ARRAY[ 1, 5, 10, 50, 100 ] ) FROM $path_prefix || '/our_dataset/*' PARTITION $parts BY RANDOM;
И таким незамысловатым образом мы прямо в дизайн языка вносим первую точку расширения: все наши функции загрузки — это подключаемые функции «Адаптеров хранилищ». Объекты, которые загружаются динамически в рантайме, и инициализируются переданными им параметрами.
Это очень (очень!) важно.
Как я уже сказал, хранилищ на свете много всяких, и очень разных. Файловые системы, объектные KV сториджи, базы данных, очереди сообщений. Мало ли откуда завтра придётся грузить наши исходные данные? Вот и я не знаю. Так что на всякий пожарный сразу же закладываемся на то, что в Spark classpath может быть коварно подсунут какой-то новый адаптер, и мы его такие за API хвать.
Ясен перец, что в таком случае класс адаптера хранилища должен что-то о себе сообщить. Имя-отчество, список своих параметров, тип наборов данных, который он умеет загружать. Ну, для этого мы просто предусмотрим в соответствующем интерфейсе метод meta(), а в стандартной поставке нашего инструмента сделаем пару штук таких адаптеров только для тех хранилищ, с которыми сами прям щас работаем. Нужны другие? Fork me on GitHub! Но подробнее об этом потом.
Просто? Пока было просто.
Непросто начинается с предложения PARTITION <N> BY HASHCODE | SOURCE | RANDOM.
Данные у нас «большие», значит, в память одного экзекутора они по определению целиком не помещаются. Чтобы прожевать набор, всегда делим его на части, и потребляем покусочно, покуда не потребим весь. Иначе-то на кой вообще было огород со спарком городить? Вот для этого PARTITION и служит — чтобы указать, на сколько конкретно частей нам хочется поделить наш набор, дабы они точно влезали в память экзекуторов.
Далее, у каждой записи есть некий ключ. Не какой-то там атрибут, обозначенный как «первичный ключ», а прям отдельно посчитанное значение, прицепленное к записи снаружи. Остаток от деления хешкода этого значения на количество партов и определяет, в какой именно парт попадает конкретная запись. Следовательно, если мы по какой-то причине хотим, чтобы какие-то записи всегда попадали в один и тот же парт, мы должны убедиться, что у них одинаковый ключ.
Вот чтобы вычислить первоначальные ключи в самом начале ЖЦ набора данных, мы и указываем алгоритм после BY:
HASHCODE(по умолчанию) — берём результат Java методаhashCode()от объекта записи.SOURCE— просим функцию адаптера хранилища вычислить ключ, исходя из имени файла (или чего-то подобного, если оно применимо к хранилищу), чтобы записи из одного файла попали в один парт. Если неприменимо, то функция должна сама решить, какое значение вернуть, особенно если запрошено больше партов, чем было исходных файлов.RANDOM— тут мы, наоборот, указываем функции адаптера равномерно перемешать все записи по случайным партам. Полезно для избежания data skew, если в данных особенно много повторяющихся записей, или файлы частично очень большие, а частично очень маленькие.
Вроде всё, набор данных зарегистрировали, данные загрузили, по партам их распределили.
Далее у нас происходит TRANSFORM (он же ALTER — для большинства операторов в лексиконе определены синонимы):
transform_stmt : K_TRANSFORM K_DS? ds_name S_STAR? func_expr columns_item* key_item? partition? ; columns_item : K_SET? type_columns K_COLUMNS? S_OPEN_PAR L_IDENTIFIER ( S_COMMA L_IDENTIFIER )* S_CLOSE_PAR | K_SET? type_columns K_COLUMNS? S_OPEN_PAR var_name S_CLOSE_PAR ; type_columns : T_POINT | T_POLYGON | T_SEGMENT | T_TRACK | T_VALUE ; key_item : K_KEY expression ;
Опять какие-то на вид сложности, а на самом деле нет, потому что всё логично, и соответствует определённым нами ожиданиям.
О чём это я? А, о требованиях. Вспомним-ка целую пачку сразу: объектная система типов, поддержка геометрии на уровне языка, партиционирование по произвольному выражению.
Вот и получается:
TRANSFORM DS "mall_geometries/" * h3UniformCoverage( @hash_level = 11 ) SET Value COLUMNS (name, lat, lon, _hash) KEY ('0x' || _hash) >> 5 PARTITION 120;
В этом примере в наборах данных с именами, начинающимися на "mall_geometries/", у нас хранятся полигоны с аутлайнами торговых центров — инстансы объектов JTS с некоторым набором атрибутов, и в переводе на человеческий мы сейчас сказали сделать с ними следующее:
- взять все наборы данных по префиксу имени "mall_geometries/",
- трансформировать их при помощи функции h3UniformCoverage,
- с параметром hash_level, равным 11,
- установить при этом атрибуты записей уровня Value с именами (name, lat, lon, _hash), от остальных избавиться,
- ключами записей задать значение атрибута _hash, сдвинутое на 5 бит вправо,
- и установить им по 120 партиций.
Словами описывать длинно, а на SQL кратко, чётко и ясно. В одну строчку можно уложиться, и половину ключевых слов не указывать, но для читаемости лучше разбивать на несколько строк, и в полном синтаксисе.
После этой трансформации подключаемой функцией h3UniformCoverage (которая делает Polygon → Columnar) у нас наборы данных с именами "mall_geometries/" * стали колоночными, сохранили всего 4 атрибута, приобрели новый ключ, и изменили количество партиций.
В требовании №8, помнится, как раз говорилось об управлении партиционированием. Предложение KEY <выражение> PARTITION <числовоеВыражение> как раз и определит, в какой парт попадёт после трансформации запись, уже по хешкоду от нового ключа. Выражение для его вычисления позволим использовать любое, так что тут можно будет не только любые атрибуты записи скомбинировать, но и RANDOM поставить, и даже константу какую-нибудь, чтобы искусственно вызвать data skew, и посмотреть, как красиво падает наш процесс.
Впрочем, переключевание может произойти перед трансформацией. Это дело такое, что функция трансформации будет самостоятельно определять, потому что в некоторых случаях после трансформации ключ по атрибутам будет уже нельзя вычислить. Впрочем, об этом тоже чуть позже, потому что тут стоит притормозить, и подробнее рассказать о той системе типов, которая нам подходит.
Она отличается от того, что принято в «типичных» движках SQL, и ближе к NewSQL и документо-ориентированным KV хранилищам.
2. Проектирование системы типов
Повторим (для закрепления) ещё разок: в процессах ETL тип конкретного поля конкретной записи гораздо менее важен, чем тип набора данных целиком. Более того, для эффективного описания процессов инджеста он должен быть динамически выводимым в рантайме, и без внешней обвязки кодом на отличном от SQL языке.
Как я уже упомянул, мало ли как там поставщик данных накосячит, и выдаст в поле, которое предполагается Double, что-нибудь типа пустой строки, или, хуже того, какое-нибудь "N/A". Описав такое поле как строгий Double, мы нарвёмся на исключение. Нет, наш путь не таков.
Атрибутам записей мы будем задавать только имена, а типы их значений будем выводить только при прямом обращении к атрибуту динамически. И если что-то где-то не приводится к нужному, заменим это значение на NULL. Или же пусть оператор выражения сам решит, как поступать в случае неправильного формата скармливаемого ему значения — иногда ведь и исключение выкинуть стоит, если приведение значения к NULL бессмысленно.
Таким образом, формальное описание записи набора данных всего лишь задаёт пространство имён внутри этого набора, чтобы можно было обратиться к некоторым атрибутам, но никоим образом не накладывает ограничений на сам объект записи. В нём спокойно может быть как ещё несколько сотен атрибутов, которые не затрагиваются в конкретном процессе ETL, так и указанные могут отсутствовать, — а что касается типов самих атрибутов, то они имеют значение только в контексте выражения. А если мы к ним никогда не обращались, то и вовсе неважны, мы просто протащим их через весь процесс в неизменном виде.
Но тип записей на уровне набора данных нам всё-таки нужен, потому что не всякая подключаемая функция-обработчик у нас будет полиглот, и не должна уметь обрабатывать записи любого вида (да и бессмысленно пытаться сделать какой-нибудь Spatial JOIN между не-геометрическими объектами). Так вот, согласно нашему списку требований, мы ограничимся следующими типами:
PlainText. Неструктурированные данные: текст, он же набор байтов (в системной кодировке; обычно это UTF8).Structured. Данные произвольной структуры: JSON без указания какой-либо схемы.Columnar. Данные с фиксированным набором колонок в порядке их перечисления.- Геометрические данные (с произвольным набором атрибутов):
Point. Точки на карте с опциональным радиусом.Polygon. Геометрии на карте, с произвольным количеством вырезов.SegmentedTrack. Коллекции точек, описывающих движение по карте некоего объекта, отсортированные по времени, и сгруппированные в сегменты.
У записей типа PlainText никаких атрибутов нет. Строка текста (она же набор байтов) является совершенно непрозрачной до тех пор, пока мы не решим трансформировать её во что-то другое. Грубо говоря, прочитав какие-то текстовые, или не очень, файлы с диска мы имеем записи типа PlainText. Без преобразования по ним можно посчитать разве что хеш как по массиву байтов.
Structured и Columnar — типы наборов данных общего назначения. В первом случае, прочитав откуда-нибудь JSON, мы можем обратиться к любому его атрибуту при помощи указания полного пути до этого атрибута (JSON, как мы знаем, состоит из массивов и объектов ключ-значение) — но схемой мы его не станем ограничивать, и задавать будем имена лишь тех атрибутов верхнего уровня, до содержимого которых хотим добраться. А в случае Columnar имена нужны опять только тем колонкам, которые нас интересуют, остальные же будут просто проигнорированы.
В случае геометрий (поддержка которых необходима согласно требованию №4) мы имеем дело с объектами вполне конкретных типов, а именно с расширениями JTS типов Point, Polygon, и GeometryCollection<GeometryCollection<Point>>. Все эти объекты помимо геометрических данных могут иметь произвольный набор атрибутов, которые хранятся как ключ-значение в поле userData, и для SegmentedTrack уровней таких атрибутов три: трек целиком, каждый сегмент, и каждая точка. Читать мы их будем из GeoJSON или чего-то подобного.
Раз мы желаем предоставить доступ к атрибутам любого уровня средствами языка, то в операторах, работающих с наборами данных, предусмотрим синтаксические конструкции для указания уровня. Например, в операторе TRANSFORM в предложении SET <Level> COLUMNS этот самый <Level> может быть равен Value для указания имён атрибутов верхнего уровня любого типа, а для геометрий мы в таком случае сможем уже более конкретно написать SET Point COLUMNS, SET Polygon COLUMNS, SET Track COLUMNS, SET Segment COLUMNS. Ну и в случае расширения системы типов наборов данных список поддерживаемых уровней может быть расширен (вплоть до динамического, но это уже тема для дальнейшей эволюции инструмента).
Но это ещё не всё.
Окромя весьма relaxed системы типов для наборов данных, у нас должна быть ещё одна система типов — для выставления параметров вызываемых нами подключаемых функций, а также для переменных, которые могут использоваться в выражениях разных контекстов — от выборок до управляющих структур языка. Эта система типов уже не настолько расхлябанная, и ближе к традиционной. Впрочем, ограничивать переменные каким-то одним типом при объявлении мы не станем, и разрешим их свободно переназначать.
Итак, для переменных нам понадобятся:
- Имена. Каноническая форма заключается в двойные кавычки.
- Строковые литералы. Всегда в одинарных кавычках (апострофах).
- Numeric-и:
DoubleилиLong. В зависимости от контекста, представление с плавающей точкой, десятичная, или шестнадцатеричная («беззнаковая») строка. - Булев тип: только литералы
TRUEилиFALSE. NULL. Какой SQL безNULL-семантики?! Нонсенс! Вот и у нас будетNULL.- Массивы:
- Имён,
- Строк,
- Numeric-ов.
Имена нам потребуются для обращений к наборам данных и функций (простое имя), к атрибутам записей наборов данных (обычно простое, а составное — через точку — только в случае JOIN; также для доступа к вложенным атрибутам типа Structured), а также для указания параметров функций (с использованием сигила @) и переменных (для них сигил $). Если имя не совпадает с ключевым словом, и не содержит не алфавитно-цифровых символов, заключать его в кавычки не обязательно. Если в закавыченном имени понадобится кавычка, её мы, как обычно в SQL, будем удваивать.
Со строковыми литералами, всегда обрамлёнными в апострофы, всё точно так же.
И имена, и строковые литералы у нас будут интерполируемыми, то есть, если внутри кавычек мы встретим последовательность из открывающей фигурной скобки { и закрывающей фигурной скобки }, то всё, что между ними, будем парсить как «выражение россыпью», и подставлять результат его вычисления. Для отмены парсинга будем ставить перед фигурными скобками обратный слэш \. Подробнее об этом позже.
Касательно Numeric — это контекстно-зависимые числа. -99.99, 25., -.13D, 1.8E-5 — это у нас Double, а 360L, -80085, 0xDEADF00D, 8800h — это Long. (Формат, кстати, описан в лексиконе.)
С булями и нулями всё просто — задаются они фиксированными литералами TRUE / FALSE / NULL, которые являются ключевыми словами. Таблицу трёхзначной истинности между ними утащим из PostgreSQL, которая хоть стандарту и не соответствует, зато хорошо всем знакома.
К массивам мы применим такое ограничение, чтобы они были однородными, а определять будем их через литерал вида ARRAY["_center_lat", "_center_lon", "userid"], ARRAY['a', 'b', 'c'], или даже просто [ 1, 2, 3 ]. Ну или же вернём из подзапроса (впрочем, не будем забегать сильно вперёд, до подзапросов нам ещё как до луны).
Ну, кажись теперь в типах не затупаемся.
Впрочем, на первую статью пока хватит. Не переключайтесь, продолжение (в 4 частях) следует!
Исходники: https://github.com/PastorGL/datacooker-etl
Промо-страница: https://pastorgl.github.io/datacooker-etl
Группа в Телеграме: https://t.me/data_cooker_etl

