Меня зовут Галимов Айрат, я патентный поверенный. Моя работа заключается в том, что я помогаю изобретателям получить патентную защиту их технических разработок (изобретений и полезных моделей).
В последнее время Роспатент начал, на мой взгляд, неправомерно выдавать отказы по решениям, которые основаны на использовании компьютеров и другой вычислительной техники (процессоры, контроллеры и т.д.). Неправомерность, по моему мнению, заключается в том, что нельзя вдруг менять правила оценки конкретного типа решений. Если появилась новая концепция проведения экспертизы, то должно меняться законодательство, а сейчас в ручном режиме и с надругательством над логикой выносятся отказы только по компьютерным решениям.
Роспатент сам устанавливает правила выдачи патентов, но это не значит, что ему можно их нарушать. Существуют разные устные разъяснения экспертов Роспатента, как теперь патентовать решения на основе вычислительных средств, но эти устные разъяснения меняются быстрее, чем заявка доходит до стадии экспертизы по существу.
Мне стало интересно, как изменился процент выдач патентов на компьютерные решения статистически, чтобы понять масштаб проблемы. Дальше я тезисно буду описывать, что делал и как, чтобы получить необходимые мне данные, и какие интересные закономерности нашел.
Сбор данных
У Роспатента есть открытая база данных по заявкам и выданным по ним патентам. База состоит из двух частей: база на изобретения (ИЗ) и полезные модели (ПМ), здесь я анализирую только ПМ, а в следующей статье расскажу про ИЗ. Каждая заявка и патент имеют свой url, но какой-то полной сводной таблицы нет, поэтому пришлось собрать все данные с помощью парсера.
Все заявки состоят из 10 цифр, начинаются с ГОДА (4 цифры), далее идет 1, далее ХХХХХ (5 цифр), например, 2018100001. Заявки на ИЗ и ПМ перемешаны, номера присваиваются в порядке поступления заявок.
На сайте Роспатента есть раздел (https://www1.fips.ru/registers-web/action?acName=clickRegister®Name=RUPMAP), в котором указаны все поданные заявки. Я написал небольшой код, который пробежался по всем интересующим диапазонам (Селениум щелкал на кнопку "предыдущий диапазон" здесь и собрал номера заявок с каждой новой страницы), так были получены все номера заявок на ПМ.
import time from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Firefox() url = 'https://www1.fips.ru/registers-web/' driver.get(url) # Click the link for applications button_applications = driver.find_element(By.XPATH, '//*[@id="mainpagecontent"]/div[2]/div/div[2]/div/table/tbody/tr[3]/td[3]/a') button_applications.click() # Click the link for applications button_range = driver.find_element(By.XPATH, '/html/body/div[3]/div/div/div[1]/div[2]/div[2]/div/ul/ul/ul/ul/ul/li[1]/a') button_range.click() # click on the button 'previous range' applications = [] for i in range(10000): app_numbers = driver.find_element(By.XPATH, '//*[@id="mainpagecontent"]/div[2]/div/div[4]/div/table').text with open('application UM.txt', 'a') as file: file.write(app_numbers) applications.append(app_numbers) print('app_numbers', app_numbers) button_prev = driver.find_element(By.XPATH, '//*[@id="mainpagecontent"]/div[2]/div/div[2]/div[2]/div[1]/a[1]') button_prev.click() time.sleep(1) driver.quit()
Далее необходимо было пройтись по страницам всех заявок на ПМ, используя такой шаблон url: https://www1.fips.ru/registers-doc-view/fips_servlet?DB=RUPM&DocNumber=2018134878
Был написан парсер, который последовательно открывал страницы каждой заявки на ПМ, собирал с них всю необходимую информацию и сохранял всю извлеченную информацию в файл. Потом другой парсер проходил по полученной таблице и добирал данные по тем заявкам, по которым выдан патент. Это нужно было сделать, так как на странице заявок нет данных, которые есть на страницах патентов, например данных об авторах и заявителях.
Раньше у Роспатента было ограничение на частоту запросов к базе (1 запрос в 10 секунд, кажется), потом появился лимит на 1000 запросов в сутки и на 1 запрос в 3 секунды. Поскольку за последние 5 лет было подано примерно 45 тысяч заявок на ПМ, то я купил 10 прокси-адресов и примерно за 10 дней (не считая времени на написание кода) скачал всю информацию. 10 дней, потому что большую часть заявок надо было парсить дважды (сначала заявку, потом патент).
В собранных данных могут быть небольшие (менее 0,1%) погрешности, так как часть страниц не открывалась и соответственно моя база данных неполная.
Код первого парсера представлен ниже:
limit = 1 i = 0 proxy_num = 0 stop = 0 for app in all_applications[:]: if app not in parsed_numbers: proxy_num = (proxy_num + 1) % len(proxies) i += 1 print('current app for parsing', app, i) bad_connection = 0 with open(applications_data, 'a', encoding='utf8') as stat_file: url = url_form + str(app) data = '' exit = 0 while True: exit += 1 try: response = requests.get(url, proxies=proxies[proxy_num]) time.sleep(0.25) data = BeautifulSoup(response.text, 'lxml') response.close() bad_connection = 0 break except: proxy_num = (proxy_num + 1) % len(proxies) time.sleep(5) bad_connection = 1 if exit == 4: break if bad_connection == 1: print('connection is bad') break if 'Превышен допустимый предел количества просмотров документов в день' in data.text[:200]: print('limit is reached, continue tommorow') limit = 0 break if 'Документ с данным номером отсутствует' in data.text[:200]: print('Документ с данным номером отсутствует') with open(log_file, 'a') as file: file.write(str(app) + 'Документ с данным номером отсутствует\n') continue try: parsed_data = get_data_from_app_soup(data, url) except: print('smth wrong with getting data from web page') with open(log_file, 'a') as file: file.write(str(app) + 'problem with getting data from web page\n') continue stat_file.write('\t'.join(parsed_data) + '\n') print('======================finish with applications=========================\n\n')
Код второго парсера представлен ниже:
# open target patent, get data from it, and saving to the file final_data_from_patents counter = 0 with open(final_data_from_patents, 'a', encoding='utf8') as file: for app_line in app_data[:]: if int(app_line.split()[0]) not in second_stage_app_numbers: data_line = app_line.split('\t') if data_line[4] != 'no_data': # check is patent number available patent_url = app_line.split('\t')[5] patent_number = int(app_line.split('\t')[4]) app_number = int(app_line.split('\t')[0]) if app_number not in second_stage_app_numbers: proxy_num += 1 print('patent_number', patent_number, 'patent_url', patent_url) try: content = requests.get(patent_url, proxies=proxies[proxy_num % len(proxies)]) # content = requests.get(patent_url) # without proxy soup = BeautifulSoup(content.text, 'lxml') content.close() time.sleep(0.25) except: time.sleep(1) continue if 'Документ с данным номером отсутствует' in soup.text[:200]: print('Документ с данным номером отсутствует', app_number) with open(log_file_2, 'a', encoding='utf8') as log: log.write(str(app_number) + ' Документ с данным номером отсутствует\n') continue if 'Превышен допустимый предел количества просмотров документов в день' in soup.text[:200]: print('limit is reached, continue tommorow') break if len(soup.text) < 10: print('smth wrong with page') continue additional_data = get_patent_data(soup, claim_title) new_applicant = additional_data[0] new_authors = additional_data[1] new_ipc = additional_data[2] new_claims = additional_data[3] status = additional_data[4] filing_date = additional_data[5] data_line[8] = new_applicant data_line[9] = new_authors data_line[16] = new_ipc data_line[17] = new_claims data_line[18] = status data_line[3] = filing_date print('new data_line', data_line) counter += 1 print('counter', counter) file.write(('\t').join(data_line) + '\n') else: print('no data to add') file.write(('\t').join(data_line)) print('======================parsing is finished========================')
В парсерах есть функции get_data_from_app_soup и get_patent_data, они собирают нужные данные со страницы, думаю, нет особого смысла приводить их код прямо в статье, так она посвящена анализу данных, а не сбору. Весь код доступен по ссылке на colab.
Анализ собранных данных
Поскольку был собран большой массив данных и на это было потрачено много времени и сил (возникали ошибки технического характера и ошибки, связанные с переосмыслением того, что я хочу, которые заставляли начинать парсинг с начала), то не хотелось ограничиваться анализом того, сколько патентов в интересующей области техники выдали или не выдали, поэтому я решил провести более глубокое исследование.
План анализа данных:
Динамика подачи заявок по годам
Динамика подачи заявок по месяцам
Количество российских и зарубежных патентообладателей
Типы заявителей
Топ-авторы
Топ-патентообладатели
Динамика выдачи патентов по классам МПК
Дальше будет много букв и графиков, постараюсь писать так, чтобы было интересно читать, буду благодарен обратной связи по этому разделу, так как у меня профессиональная деформация в области патентования, и я иначе оцениваю интересность данной темы.
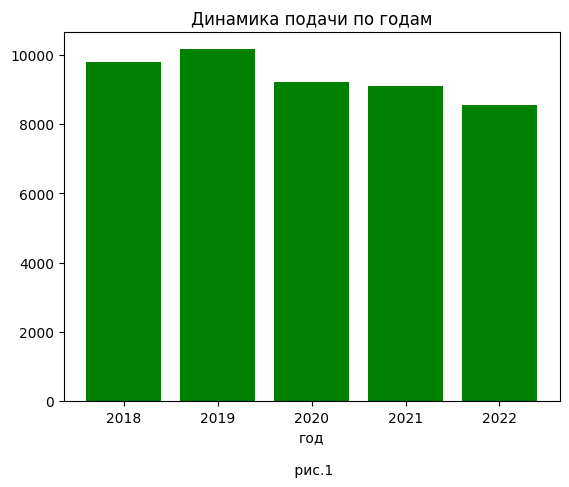
1. Динамика подачи заявок по годам
Все данные по заявкам я собрал в словарь voc_data, в котором ключи - года, значения - списки данных по заявке (номер патента, дата подачи, автор, заявитель и т.д.)
Код для визуализации динамики подачи по годам и гистограмма показаны ниже. Видно, что в последние четыре года наблюдается устойчивый "отрицательный рост".
year_total = [] years = [] for year in data_voc.keys(): years.append(year) year_total.append(len(data_voc[year]['filing date'])) print('подача заявок по годам', '\n', pd.DataFrame(year_total, index=years, columns=['кол-во'])) plt.bar(years, year_total, color='g') plt.title('Динамика подачи по годам') plt.xlabel('год\n\n рис.1') plt.show()
2. Динамика подачи заявок по месяцам
Мне стало интересно посмотреть динамику подачи не только по годам, но и по месяцам (см. рис.2). Оказалось, что год от года наблюдается одна и та же картина: минимум в январе, волнообразный спад с марта по сентябрь и ударный рост с сентября по декабрь. Предполагаю, что в коротком январе люди отдыхают и отходят от празднования Нового года новогодних отпусков и т.п., до мая набирают темп подачи, в праздничном мае снова отдыхают, еще два месяца изобретают, после чего следует ежегодный августо-сентябрьский провал (возможно, он объясняется отпусками), ну а пик подачи от года к году в декабре. Исходя из моего опыта работы в бюджетных учреждениях, скорее всего, во многом это они выполняют годовые планы по подаче заявок.
each_year_month_dynamic = [] for year in data_voc.keys(): moth_dynamic = [] filing_dates = [] for filing_date in data_voc[year]['filing date']: if filing_date != 'no_data' and filing_date != '': filing_dates.append(int(filing_date.split('.')[1])) for month in range(1, 13): moth_dynamic.append(filing_dates.count(month)) each_year_month_dynamic += [moth_dynamic] months_names = ['Янв', 'Фев', 'Мар', 'Апр', 'Май', 'Июн', 'Июл', 'Авг', 'Сен', 'Окт', 'Ноя', 'Дек'] each_year_month_dynamic_df = pd.DataFrame(np.transpose(each_year_month_dynamic), columns=years) each_year_month_dynamic_df['months'] = months_names each_year_month_dynamic_df.plot(x='months', y = years, figsize=(10, 5), grid=True, yticks=[0, 200, 400, 600, 800, 1000, 1200, 1400], title='Месячная динамика по годам', xlabel='месяц\n\nРис.2') plt.show()

3. Количество российских и зарубежных патентообладателей
Посмотрим сколько российских патентообладателей в общем числе выданных патентов. На рисунке 2 серый столбец показывает заявки, по которым нет данных, так как по ПМ публикуются только патенты, но не сами заявки, а в заявках нет данных о патентообладателях. Доля зарубежных патентообладателей ничтожно мала и за 5 лет уменьшилась в 4 раза (с примерно 400 до примерно 100). Такое малое количество патентов на полезные модели у зарубежных патентообладателей связано с тем, что в основном зарубежные заявители защищают изобретения. Но динамика все равно очень плохая.
Кто-то может считать, что нет зарубежных патентов и хорошо, но нет. Конкуренция - хорошо, стремление придумать свое, чтобы обойти чужой патент - хорошо, только так создается что-то лучшее, а в тепличных условиях создается то, что работает только в таких условиях.
app_ru = [] app_not_ru = [] app_no_country = [] regex_country = r'(\([A-Z]{2}\))' for df in data_voc.values(): ru, not_ru, no_country = 0, 0, 0 for app in df['applicant']: if 'RU' in app: ru += 1 elif len(re.findall(regex_country, app)) != 0: # если нет двух заглавных букв в круглых скобках, то нет данных о стране заявителя not_ru += 1 else: no_country += 1 app_ru.append(ru) app_not_ru.append(not_ru) app_no_country.append(no_country) applicants_df = pd.DataFrame(np.transpose([app_ru, app_not_ru, app_no_country]), columns=['RU', 'не RU', 'нет данных']) applicants_df['год'] = years applicants_df.plot(x='год', y = ['RU', 'не RU', 'нет данных'], kind='bar', stacked=True, title='Ru-Foreign applicants dynamics', color=['green', 'red', 'grey'], figsize=(10, 6), xlabel='\nYears', table=False)

4. Типы заявителей
Существует 4 типа заявителей:
образовательные организации
государственные организации
юридические лица (подразумевается ООО, АО и т.д., которые не попали в первые две категории)
физические лица
Роспатент не разделяет заявителей на типы, поэтому я написал код, который по разным признакам определял кто представлен в столбце "Заявитель", например, три слова и все начинаются с Заглавной буквы или первое слово ЗАГЛАВНЫМИ буквами, второе слово начинается с Заглавной - физлицо.
Для распределения по категориям я создал 4 переменные с признаками 4 типов заявителей:
education = ['бразован', 'нститут', 'ниверс', 'ЮНИВЕРСИТИ', 'юниверсити', 'УНИВЕР', 'ИНСТИТЬЮТ', 'ИНСТИТУТ', 'ЮНИВЕРСИТЕ'] government = ['осударственн', 'министерство', 'Российская Федерация', 'государственное бюджетное учреждение', 'ФГБНУ', 'ойсковая часть'] legal = ['бщество', 'ЛТД.', 'ЛИМИТЕД', 'КОРПОРЕЙШН', 'ИНК.', 'Лимитед', 'ИНКОРПОРЕЙТЕД', 'ГМБХ', 'КОНИНКЛЕЙКЕ', 'ИНТЕРНЭШНЛ', 'ФРАНС', 'ЛЛС', 'КАЙСЯ', 'С.П.А', 'С.А.', 'ЛТД', ' АГ', 'СИМЕНС', 'КОМПАНИ', 'Лтд', 'КОРПОРЭЙШН', 'ЭЛЕКТРОНИКС', 'Компани', 'ОБЩЕСТВО', 'ЭлЭлСи', 'ХОЛДИНГ', 'БАСФ', 'ООО', 'ГмбХ', 'Инк.', 'А/С', 'АКЦИЕНГЕЗЕЛЛЬШАФТ', 'АКЦИЕНГЕЗЕЛЬШАФТ', 'С.Р.Л.', ' АБ ', 'ЛЛК', 'Акциенгезельшафт', ' СПА ', 'СОЛЮШНС', 'ЗАО', 'ПАО', 'АКТИЕНГЕЗЕЛЛЬШАФТ', 'Текнолоджиз', 'олюшн', 'ЭлЭЛСи', 'орпорейшн', 'ГРУП', 'ДиЭмСиСи', '(ПАБЛ)', 'ЭЛЕКТРИК', 'ТЕКНОЛО', 'АО ', 'БОЛАГЕТ', 'САФРАН', ' ОЙ ', 'ОЮЙ', 'ОЙЙ', ' САС ', ' СА ', ' АС ', 'СОЛЮШН', ' ИНК ', ' НВ ', 'АКТИЕБОЛАГ', 'ГОБЭН', 'ИНТЕРНЕЙШНЛ', 'ЛЛЦ', 'СЕРВИС', 'ФАРМА', 'ЭЛЭЛСИ'] physic = [' оглы', 'анович ', 'СЕРГЕ', 'ВЛАДИМИР', 'ЕВИЧ ', 'ОВИЧ ', 'Чон-Ын']
Эти переменные заполнялись поэтапно, исходя из того, что у меня оставалось в неотсортированном списке после каждой итерации разделения всего списка заявителей на типы. Указанные переменные и признаки использовались в функции app_categories, код которой я не привожу в статье.
types = ['патент не выдан', 'образование', 'государство', 'юрлица', 'физлица'] app_types_data = [] for app_df in data_voc.values(): year_data = app_categories(app_df['applicant']) app_types_data.append(year_data) app_types_df = pd.DataFrame(app_types_data, columns=types) app_types_df['years'] = years app_types_df.plot(x='years', y=types, kind='bar', figsize=(10, 7), xlabel='год\n\n рис.4', color = ['grey', 'red', 'black', 'green', 'blue'])
Визуализация типов заявителей (на самом деле, патентообладателей, так как данные по заявителям появляются только, когда выдан патент) по годам показана ниже:

Из рисунка видно, что лидерами по получению патентов из года в год являются юрлица, что очень хорошо, и образовательные организации, что плохо, далее с небольшим отставанием следуют физлица, доля госучреждений несоизмеримо меньше.
Почему плохо, что образовательные организации так много патентуют. Потому что на данный момент они делают это для отчетности, качество патентов низкое, они не поддерживаются в силе, то есть никому не нужны, что будет показано ниже.
Что еще интересного можно на рис.4:
Доля заявок по которым не был выдан патент на ПМ растет с 2018 по 2021 года. С учетом общего спада подачи (см. рис.1), доля невыдач патентов относительно общего количества поданных заявок растет еще быстрее, чем видно на рисунке 4. Это отдельно будет исследовано ниже. Это увеличение невыдач (отказы + отзывы заявок) говорит, что с 2018 года подход к оценке заявок начал меняться.
Хуже всех динамика получения патентов у физлиц, скорее всего, это связано с тем, что физлица часто сами подают заявки, не отслеживают изменяющиеся требования, и поэтому чаще не получают патенты.
5. Топ-авторы
Изучим патенты топ-авторов по годам, код для этого представлен ниже.
# проверка действуют ли патенты автора def author_status_check(author_name, year): author_status = [] total = 0 active = 0 author_patents = data_voc[year][data_voc[year]['authors'].str.contains(author_name)]['status'].tolist() for status in author_patents: author_status.append(status.split('(')[0].strip()) author_status_df = pd.DataFrame(author_status) try: active = author_status_df.value_counts().loc[['действует']][0] except: active = 0 non_active = sum(author_status_df.value_counts().values) - active authhor_data_line = [author_name, non_active, active] return authhor_data_line # топ авторов for app_df, year in zip(data_voc.values(), years): print('====================', year, '====================') author_patent_status_voc = {} all = [] authors_status = [] authors_column = app_df['authors'] authors_column = authors_column for author in authors_column[:]: regex = r' \(\w\w\)' separated = re.split(regex, author)[:-1] for s in separated: all.append(s.replace(',', '').replace(';', '')) all_authors_df = pd.DataFrame(all) top_10_authors = all_authors_df.value_counts()[:10] counter = 1 for author_name in top_10_authors.index: author_patent_status = author_status_check(author_name[0], year) authors_status.append(author_patent_status + [counter]) counter += 1 authors_df = pd.DataFrame(authors_status, columns=['name', 'Не действует', 'Действует', 'number']) names = '' for name, num in zip(authors_df['name'], authors_df['number']): names += str(num) + '. ' + name + '\n' authors_df.plot(x='number', y=[ 'Действует', 'Не действует'], kind='bar', figsize=(10, 5), stacked=True, color=['green', 'red'], xlabel=names, grid=True, title = year)
2018 год
Ниже топ-10 авторов за 2018 год с визуализацией, сколько из их патентов действуют. Отдельно надо указать, что в действующие я записывал все патенты, у которых статус "действует" или "действует, но может прекратить свое действие". Есть еще категории "не действует, но может быть восстановлен", "не действует". Как правило, если у патента статус "не действует, но может быть восстановлен", значит, что его перестали продлевать, и через какое-то время он станет просто не действующим. Такое разделение дискуссионное, заранее согласен с возражениями, но, думаю, что так ближе к объективной картине.
Также следует отметить, что данные о действии патентов получена в августе-сентябре 2023 года, то есть, возможно, что до этого времени какие-то из этих патентов действовали. Но если они не действуют сейчас, значит, время только подтвердило, что они не нужны даже заявителям.

Рассмотрим авторов на рисунке 5.
Савушкин, Кякк, Орлова, Шевченко являются топ-менеджерами связанных крупных компаний и встречаются в соавторах в одних и тех же патентах, эти патенты принадлежат РЕЙЛ 1520 АйПи ЛТД (КИПР) (около 2/3 патентов) и ООО "Всесоюзный научно-исследовательский центр транспортных технологий" (ООО "ВНИЦТТ") (РФ) (около 1/3 патентов). Как видно из рисунка 5, эти компании поддерживают патенты в силе. Чтобы подать больше 80 заявок в год, надо сильно постараться, подозреваю, что на эту великолепную четверку работало несколько отделов ВНИЦТТ, но настоящих авторов в патенты не вписали.
Селявко Леонид Евгеньевич - ученый, кандидат психологических наук, судя по всему является правомерным автором 60 патентов. Это очень высокая продуктивность, но только 9 из патентов за его авторством действуют на сегодняшний момент. Причем необычно, что он сам является патентообладателем большинства патентов, а не вуз, в котором он работает. Ниже показано облако слов из названий его патентов.

Из рисунка 6 понятно, что Селявко Леонид Евгеньевич разрабатывает тренажеры для реабилитации.
Следующие авторы Курдюмов Владимир Иванович, Зыкин Евгений Сергеевич, Сутягин Сергей Алексеевич, Смирнов Алексей Сергеевич - представители профессорско-преподавательского состава, патенты принадлежат вузам, в которых они работали, но все они не действуют. Это обычная практика в вузе - клепать патенты, потому что есть план, но качество таких патентов оставляет желать лучшего.
Отдельно следует выделить Бороненко Юрия Павловича, патенты под его авторством принадлежат Акционерному обществу "Научно-внедренческий центр "Вагоны" (АО "НВЦ "Вагоны"). Это коммерческое предприятие, а он его основатель. Почти все патенты действуют. Вполне могу поверить, что 35 патентов на ПМ были получены с его творческим вкладом. Во-первых, он основатель НВЦ "Вагоны", во-вторых, он профессионал в этой области, в-третьих, он не выглядит, как "успешный" бизнесмен, а выглядит, как представитель творческой интеллигенции. Понятно, что субъективно, но вот фильм о нем.
А ниже облако из названий патентов с его авторством (рис.7), темы патентов соответствуют названию НВЦ, что не удивительно.

Дальше коротко представлена информация о топ-авторах 2019-2022 годов
2019 год

Опять Савушкин, Орлова, Шевченко. А вот Кякк почему-то мало в этом году придумывал идей для патентов - в два раза меньше чем Савушкин. Их патенты все также по большей части поддерживаются в силе в отличие от патентов почти всех остальных авторов.
Господин Селявко продолжает ударно трудиться над созданием заявок и получил уже 73 патента - на 13 больше чем годом ранее. Все также большая часть патентов принадлежит ему, а не вузу. Феноменальная продуктивность! Небольшая часть его патентов поддерживается в силе, видимо, те, которые являются перспективными или используются на практике.
Зыкин и Курдюмов все еще в топе авторов, оно и понятно, патентование в вузах вознаграждается, хочешь премию, будь добр - подай заявку.
Рыкина Дмитрия Владимировича гугл не знает, но он в соавторах с Зыкиным и Курдюмовым, причем указан всегда последним, наверное, молодой преподаватель или аспирант.
Голованчиков Александр Борисович - профессор ВолгГТУ, похоже, руководитель множества аспирантов, поэтому оказывался в авторах многих патентов.
Соколов Алексей Михайлович придумывает идеи для патентов РЕЙЛ 1520 АйПи ЛТД (КИПР) и ООО "ВНИЦТТ" вместе с Савушкиным и ко.
2020 год
10
Пропали Савушкин и компания, и сразу картина действующих патентов сильно ухудшилась. В топе с прошлого года остались Зыкин, Селявко, Голованчиков, Рыкин. Посмотрим на новые лица.
Исайчев Виталий Александрович - ректор ФГБОУ ВО Ульяновский ГАУ, вот уж ректор точно 62 идеи для патента придумал. Он второй автор в патентах Зыкина (профессора того же вуза).
Сергеев Артём Юрьевич - старший преподаватель, Военный университет МО РФ. Тут надо отметить, что они чуть ли не всю кафедру вписывают в авторы, в одном патенте у них 21 автор. Понятно, почему за его авторством 50 патентов.
Мишта Валерий Павлович - ктн, доцент в ВогГТУ, в 36-ти патентах он единственный автор, поэтому мало сомнений, что он настоящий автор. Не понятно, как преподаватель может успевать писать по 3 заявки в месяц, но факт остается фактом.
Лямзин из компании с Сергеевым, где под 20 авторов у каждого патента
Лаптева Наталья Алексеевна - ведущий инженер-патентовед в Брянском государственном аграрном университете. Конечно же, патентовед не может себя вписывать в авторы, если не внес творческого вклада в создание изобретения. Скорее всего, имеет место нарушение законодательства.
Патенты всех этих топ-авторов почти все не поддерживаются в силе, что говорит об отсутствии их ценности.
2021 год

Дальше я буду описывать авторов очень коротко.
Зыкин, Исайчев, Лаптева, Селявко - знакомые фигуры. Кудряшова Ирина Владимировна, Гаврилова Василиса Львовна из компании авторов с Зыкиным.
Неожиданно снова появился Шевченко, это тот, который был связан с РЕЙЛ 1520 АйПи ЛТД (КИПР), но теперь все патенты с его авторством принадлежат российским компаниям. Савушкина, судя по открытым данным, уволили, Орлова все еще гендир ВНИЦТТ, про судьбу Кякка гугл ничего не знает, но из лидеров патентования они пропали.
Кузнецов, Купреенко и Исаев - преподаватели в Брянском государственном аграрном университете, в большинстве патентов они в соавторах.
Некоторое количество действующих патентов в столбцах 6-10, вероятно, связано с тем, что патенты получены в конце года и просто не вышел срок, когда они становятся недействующими из-за неуплаты пошлины. По оставшимся, вероятнее всего, просто прекратили платить пошлины.
2022 год

Зыкин в ударе - 182 патента в год! Человек придумывает идею каждые два дня, совмещая эту ударную деятельность с работой директором Технологического института-филиала ФГБОУ ВО Ульяновский ГАУ. Все патенты, в которых он автор, принадлежат Ульяновскому государственному аграрному университету имени П.А. Столыпина, а всего в 2022 году у этого вуза 224 патента, то есть больше 80% всех патентов вуза получены с авторским участием Зыкина. Стахановец!
Пробежимся по новым лицам. Казанчев Андрей Федорович в соавторах с Зыкиным, видимо, стал аспирантом, потому что в 2018-2021 годах, патентов у студента Казанчева не было, а в 2022 появилось сразу 88. Вот что значит попасть в правильное место! Можно поизучать эти патенты, чтобы разобраться, как аспирант становится автором 88 патентов, но и так понятно, что это просто конвейер для выполнения вузовского плана по получению патентов и получению премий за них.
Лазуткина и Жаркова одни из соавторов вместе с Зыкиным.
Исаев Самир Хафизович - соавтор Исаева Хафиз Мубариз-оглы и по совместительству его сын.
Почти все патенты действуют, но потому что срок уплаты пошлин за поддержание в силе по большей части из них не подошел.
Я проанализировал динамику перехода действующих патентов в недействующие (см. рис. 11). Картина требует анализа и пояснений. Пройдемся по жизненному пути патента. Сначала выданный патент является действующим, если через год с даты подачи заявки не заплатить пошлину за поддержание патента в силе его статус станет "может прекратить действие", если еще полгода не платить пошлину, то статус становится "не действует, но может быть восстановлен", если три года не платить пошлину, то статус становится "не действует".
Что мы видим на рис.11 и в таблице 1. Процент действующих патентов снижается с удалением от текущего момента, то есть полученные патенты перестают поддерживать в силе. Как я вижу из своего опыта и что логично, это делается в силу того, что эти патенты никому не нужны.
Часть патентов, выданных по заявкам 2022 года, уже находятся в синей зоне (их не продлили в основной срок), непродленные патенты 2021 года частично находятся в синей зоне, частично - в серой (не действуют, но могут быть восстановлены), в 2019 году уже появляется большое количество красных (недействующих) патентов, так как проходят все сроки для продления. Еще больше красных патентов в 2018 году.
Какие-то патенты не продлевают со второго года, какие-то с третьего, какие-то с четвертого, это видно по столбцам синим, серым и красным столбцам. В разные года разная ситуация с продлением, но видно, что процент действующих патентов неуклонно падает с удалением от их выдачи.
Можно сделать вывод, что меньше половины патентов живут дольше 5 лет, то есть меньше половины патентов нужны своим правообладателям.


Выводы по авторам
Среди топ-авторов почти сплошь преподаватели и несколько топ-менеджеров, на их фоне выделяется Бороненко Юрий Павлович.
Наибольшая группа действующих патентов принадлежит топ-менеджерам, а настоящие авторы лишены их авторских прав.
Патенты сотрудников вузов почти все не поддерживаются в силе.
6. Топ-патентообладатели
В этом разделе схожим образом проведен анализ топ-патентообладателей, ниже приведены диаграммы, в которых указаны топ-патентообладатели и соотношение действующих и не действующих патентов у них.
Код для анализа патентообладателей:
# проверка действуют ли патенты заявителя def app_status_check(data_voc, app_name, year): applicant = '' original_app_name = app_name app_name = app_name.split('(')[0] app_patents = data_voc[year][data_voc[year]['applicant'].str.contains(app_name)]['status'].tolist() app_status_active = 0 app_status_total = 0 for status in app_patents: app_status_total += 1 if status.split('(')[0].strip() == 'действует': app_status_active += 1 original_app_name = original_app_name.replace('Федеральное государственное бюджетное образовательное учреждение высшего образования', '') original_app_name = original_app_name.replace('Публичное акционерное общество', 'ПАО') original_app_name = original_app_name.replace('Общество с ограниченной ответственностью', 'ООО') original_app_name = original_app_name.replace('Федеральное государственное автономное образовательное учреждение высшего образования', '') original_app_name = original_app_name.replace('Федеральное государственное автономное образовательное учреждение высшего образования', '') original_app_name = original_app_name.replace('Федеральное государственное казенное военное образовательное учреждение высшего образования', '') original_app_name = original_app_name.replace('Федеральное государственное автономное образовательное учреждение высшего образования', '') original_app_name = original_app_name.replace('Федеральное государственное бюджетное образовательное учреждение высшего образования', '') original_app_name = original_app_name.replace('Федеральное государственное казенное военное образовательное учреждение высшего образования', '') original_app_name = original_app_name.replace('Федеральное государственное бюджетное образовательное учреждение высшего образования', '') original_app_name = original_app_name.replace('Федеральное государственное бюджетное научное учреждение', '') original_app_name = original_app_name.replace('ФЕДЕРАЛЬНОЕ ГОСУДАРСТВЕННОЕ КАЗЕННОЕ ВОЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ВЫСШЕГО ОБРАЗОВАНИЯ', '') original_app_name = original_app_name.replace('Федеральное государственное казенное военное образовательное учреждение высшего образования', '') original_app_name = original_app_name.replace('Министерства обороны Российской Федерации', '') original_app_name = original_app_name.replace('ОБЩЕСТВО С ОГРАНИЧЕННОЙ ОТВЕТСТВЕННОСТЬЮ', 'ООО') original_app_name = original_app_name.replace('Акционерное общество', 'АО') app_status_info = [original_app_name, app_status_total, app_status_total-app_status_active, app_status_active] return app_status_info # топ заявителей for app_df, year in zip(data_voc.values(), years): print('====================', year, '====================') all = [] app_column = app_df['applicant'] top_10_app = app_column.value_counts()[1:11] print(top_10_app, '\n') applicant_visualisation = [] counter = [i for i in range(1, 11)] for app_name in (top_10_app.index): app_status_results = app_status_check(data_voc, app_name, year) applicant_visualisation.append(app_status_results) applicant_visualisation_df = pd.DataFrame(applicant_visualisation, columns=['Патентообладатель', 'Всего', 'Не действуют', 'Дейсвуют']).sort_values(by='Всего', ascending=False) applicant_visualisation_df['№'] = counter x_visual = '' for num, app in zip(applicant_visualisation_df['№'], applicant_visualisation_df['Патентообладатель']): x_visual += (str(num) + ' ' + app + '\n') applicant_visualisation_df.plot(x='№', y=[ 'Дейсвуют', 'Не действуют'], kind='bar', figsize=(10, 5), xlabel=x_visual, stacked=True, grid=True, title = year, color=['green', 'red'])



Выводы по топ-патентообладателям
В топе всех годов в основном вузы, но они почти не поддерживают патенты в силе, что говорит о том, что они не имеют ценности даже для самих вузов.
Стабильно получают много патентов и поддерживают их в силе Камаз и Татнефть. В последние два года в топе появился Рузхиммаш, ниже облако из слов в названиях его патентов.

Удивительно, но Рузхиммаш тоже занимается вагонами. Судя по патентам, ж/д направление развивается ударными темпами в последние пять лет.
Не знаю по поводу Камаза, но в Татнефти есть план по патентованию, что приводит к тому, что патентуют они все, что видят. При этом у них количество порой переходит в качество, в Татнефти есть действительно хорошие разработки, и компания платит вознаграждение авторам за эффективные решения.
Переход количества патентов в качество не происходит всегда и везде, и в вузах это правило, не работает, потому что вузы патентуют исключительно для выполнения плана, а, например, в Татнефти патентуют и придумывают что-то применяемое на практике, пусть и делают это в том числе из-под палки.
Технический прогресс возможен в основном силами коммерческих организаций, которые стремятся улучшить экономические показатели, при правильной организации взаимодействия вузы должны помогать им посредством науки и исследований. Сейчас же они выполняют планы по количеству патентов.
Есть вероятность, что вузы действительно делают что-то ценное для коммерческих организаций по договору. Обычно по таким договорам правообладателем вузовской разработки становится коммерческая организация, но авторами должны оставаться вузовские работники - непосредственные исполнители. Среди топ-авторов я не нашел тех, чьи фамилии присутствовали бы в патентах каких-то коммерческих организаций.
Есть немаленькая вероятность, что права авторов в таких договорах нарушаются и коммерческая организация вписывает в авторы своих топ-менеджеров, как в случае Савушкина и ко, также есть некоторая вероятность, что авторы просят не упоминать их таковыми в опубликованных патентах. Но все же то, что среди сотен проанализированных патентов нет таких, в которых авторы - сотрудники вуза, а правообладатели - коммерческие организации, явно свидетельствует, что взаимодействие вузов с бизнесом крайне слабое.
7. Динамика выдачи патентов по классам МПК
В этом разделе мы уже приближаемся к выявлению ответа на основной вопрос статьи. Сначала посмотрим как меняется динамика выдачи патентов, потом проверим, есть ли какая-то явная неравномерность в выдаче патентов на решения из разных областей техники.
Динамика выдачи патентов приведена ниже на рисунке 16, код для получения этого графика также показан ниже. Данные по вертикальной оси нормированы к общему количеству заявок в году.
year_total = [] years = [] for year in data_voc.keys(): years.append(year) total = len(data_voc[year])/100 year_total.append(len(data_voc[year][data_voc[year]['grant date'] != 'no_data'])/1) print(year_total) plt.bar(years, year_total, color='g') plt.title('Динамика выдачи патентов по годам') plt.xlabel('год') plt.ylabel('количество') for x, y in zip(years, year_total): plt.text(x, y + 0.05, '%d' % y, ha='center', va = 'bottom') plt.show()

Из рисунка 16 видно, что в 2020 году резко уменьшилось (на 15%) количество выдаваемых патентов (увеличилось количество отказов в выдаче или заявки были отозваны, так как заявитель их забросил или ходатайствовал об отзыве). Далее спад продолжился, но не так резко, спад с 2019 года по 2022 составил около 23%.
У патентов есть параметр "класс МПК (международная патентная классификация)", который определяет, к какой области техники относится решение (http://allpatents.ru/mpk/). Посмотрим, что происходило с выдачами по классам МПК по годам (рис.17).
# выдача патентов по МПК year_total = [] years = [] ipc_stat_df = pd.DataFrame() for year in data_voc.keys(): total = len(data_voc[year])/100 ipc_short = [] years.append(year) for i in (','.join(data_voc[year][data_voc[year]['grant date'] != 'no_data']['ipc'].to_list()).replace(' ','').split(',')): ipc_short.append(i[:1]) ipc_stat_df = pd.concat([ipc_stat_df, pd.DataFrame(ipc_short).value_counts()[:30]], axis=1) ipc_stat_df.columns = years ipc_stat_df = ipc_stat_df.drop(index='n') # нормализация к общему числу патентов, поданных в год ipc_stat_df_normalized = pd.DataFrame() for column, total in zip(ipc_stat_df, app_per_year): ipc_stat_df_normalized = pd.concat([ipc_stat_df_normalized, (ipc_stat_df[column]/int(total)*100)], axis=1) pc_stat_df_normalized.plot(kind='bar', color = ['grey', 'black', 'red', 'green', 'blue'], xlabel='класс МПК', ylabel='процент', title = 'Динамика выдачи патентов по классам МПК \n(нормализовано к общему числу патентов)')

Наиболее явный и стабильный спад с 2020 года наблюдается в классах F (Машиностроение; освещение; отопление; двигатели и насосы; оружие и боеприпасы; взрывные работы ) и G (Физика), к которому относятся компьютерные решения.
Класс G достаточно большой, заглянем в его подклассы:
# выдача патентов по МПК new_df = pd.DataFrame() year_total = [] years = [] ipc_stat_df = pd.DataFrame() for year in data_voc.keys(): total = len(data_voc[year])/100 ipc_short = [] years.append(year) for i in (','.join(data_voc[year][data_voc[year]['grant date'] != 'no_data']['ipc'].to_list()).replace(' ','').split(',')): ipc_short.append(i[:3]) ipc_stat_df = pd.concat([ipc_stat_df, pd.DataFrame(ipc_short).value_counts()[:100]], axis=1) ipc_stat_df.columns = years for i in ipc_stat_df.index: if 'G' in i[0]: new_df = pd.concat([new_df, ipc_stat_df.loc[i]], axis=1) new_df.transpose().iloc[:8].plot(kind='bar', color = ['grey', 'black', 'red', 'green', 'blue'], xlabel='класс МПК')

Спад мы видим в подклассе G01 (Измерение) и G06 (Вычисление; счет), в этих классах очевидно широко применяется вычислительная техника. В классе G01 спад 2019-2020 годов составил 20%, а в классе G06 - 27%, это значительно больше общего спада в 15%. Справедливости ради необходимо отметить, что патентные специалисты адаптировались к новым требованиям Роспатента и в 2022 году уже наблюдается некоторый рост выданных патентов.
Выводы
В процентах спад в классе компьютерных решений очень большой, однако в абсолютных величинах это примерно 200 заявок в год, что не кажется критическим.
Однако с учетом того, что наблюдается общий спад подачи заявок, а их уровень таков, что половину из них не поддерживают в силе, не кажется разумным со стороны Роспатента не давать развивать компьютерные решения, которые, очевидно, с большими шансами могут оказаться востребованными в реальном секторе экономики.
В следующей части исследования я планирую проанализировать по тем же критериям заявки на изобретения, и, поскольку по умолчанию они публикуются, то станет понятно, по каким именно решениям Роспатент перестал выдавать патенты.

