Я форкнул и модифицировал компилятор Rust rustc. Одна фича — кэширование раскрытия процедурных макросов — привела к снижению времени инкрементальных сборок на 11-40% в различных реальных крейтах. Благодаря этому ускорились dev-сборки и меньше стал тормозить rust-analyzer (IDE IntelliSense).
Если вы специалист в повышении производительности компилятора Rust, то можете сразу перейти к разделу «Кэширование раскрытия макросов: ускорение инкрементальных сборок Rust на 40%».
Компиляция Rust может быть медленной…
У языка Rust есть множество хороших свойств, но жалобы на время компиляции уже превратились в настоящий мем. Настолько, что кнопка «Мне повезёт» переносит пользователя в группу поддержки вот этого несчастного:

При написании кода все разработчики стремятся к максимально быстрому циклу «редактирование-компиляция-запуск». Чем быстрее ты получаешь обратную связь, тем выше продуктивность. Разработчики на Go уже привыкли к быстрым инкрементальным сборкам, однако их коллеги-разработчики на Rust чаще привыкают к медленным инкрементальным сборкам, приводящим к выученной беспомощности.
Примечание: что такое инкрементальная сборка?
Допустим, вы скачали и скомпилировали кодовую базу на Rust. Это «чистая сборка», потому что компилятору нужно обрабатывать этот код с нуля.
Допустим, у нас уже есть чистая сборка, мы изменили пару строк, а затем начали компилировать её заново. Это называется «инкрементальной сборкой». За день разработчик может выполнить сотни инкрементальных сборок (повторить этот цикл: внести изменения в код, скомпилировать и иногда запустить/протестировать). Лишнее время быстро накапливается.
Существующие опции компилятора ограниченно помогают в снижении времени инкрементальных сборок
Хорошая новость: Rust предоставляет множество (часто нестабильных) фич, способных оптимизировать поведение компилятора. Во многих постах (1, 2, 3) всего за несколько последних месяцев есть список конфигураций, снижающих время компиляции Rust:
Использовать компоновщик lld или mold
Использовать бэкенд кодогенерации Cranelift
Собирать исполняемые файлы без возможности изменения переназначения адресов
Вырезать отладочную информацию
Включить параллельный фронтенд
Использовать релизные (оптимизированные сборки) для крейтов процедурных макросов
Плохая новость: эти опции ограниченно помогают в снижении времени инкрементальных сборок.
Представленные выше опции 1 - 4 оптимизируют генерацию кода. Если вы собираете исполняемый файл (при помощи
cargo build), то они могут помочь. Однако большинство разработчиков (включая меня) в процессе кодинга просто хочет знать, может ли скомпилироваться их код (то естьcargo checkилиcargo clippy). Им не нужно создавать исполняемый файл, так что оптимизации генерации кода ничем не помогут.Опция 5 привносит межпроцессную параллелизацию. Она может существенно ускорить dev-сборки* (разумеется, если у вашей машины достаточно CPU и памяти). Тем не менее, лично я заметил практически отсутствующее снижение времени инкрементальных сборок, потому что этап распараллеленного «анализа» гораздо короче, чем у чистых сборок.
[*Параллельный фронтенд по-прежнему есть только в nightly-компиляторе, и он как будто бы появится в стабильном rustc в конце 2024 года. Подробности см. в статье.]
Опция 6 привносит интересную предпосылку: раскрытие процедурных макросов — это медленный процесс! Однако за такое решение приходится платить высокую цену, так как релизная сборка крейта процедурных макросов существенно медленнее, чем dev-сборка.
Вероятно, вы тратите существенную часть времени сборки на раскрытие процедурных макросов
Процедурные макросы в Rust — это «мета-функции», расширяющие написанный пользователем код. Грубо говоря, fn procmacro(user_code: string) -> /* output_code */ string**.
[**Строго говоря, это неверно по нескольким причинам. А именно: вводы и выводы — это объекты TokenStream, которые ближе к AST, чем к сырым строкам. Кроме того, процедурные макросы атрибутов получают два ввода (сам атрибут и тело, к которому он прикреплён), а не один. Тем не менее, это полезная модель; подробности можно изучить в статье.]
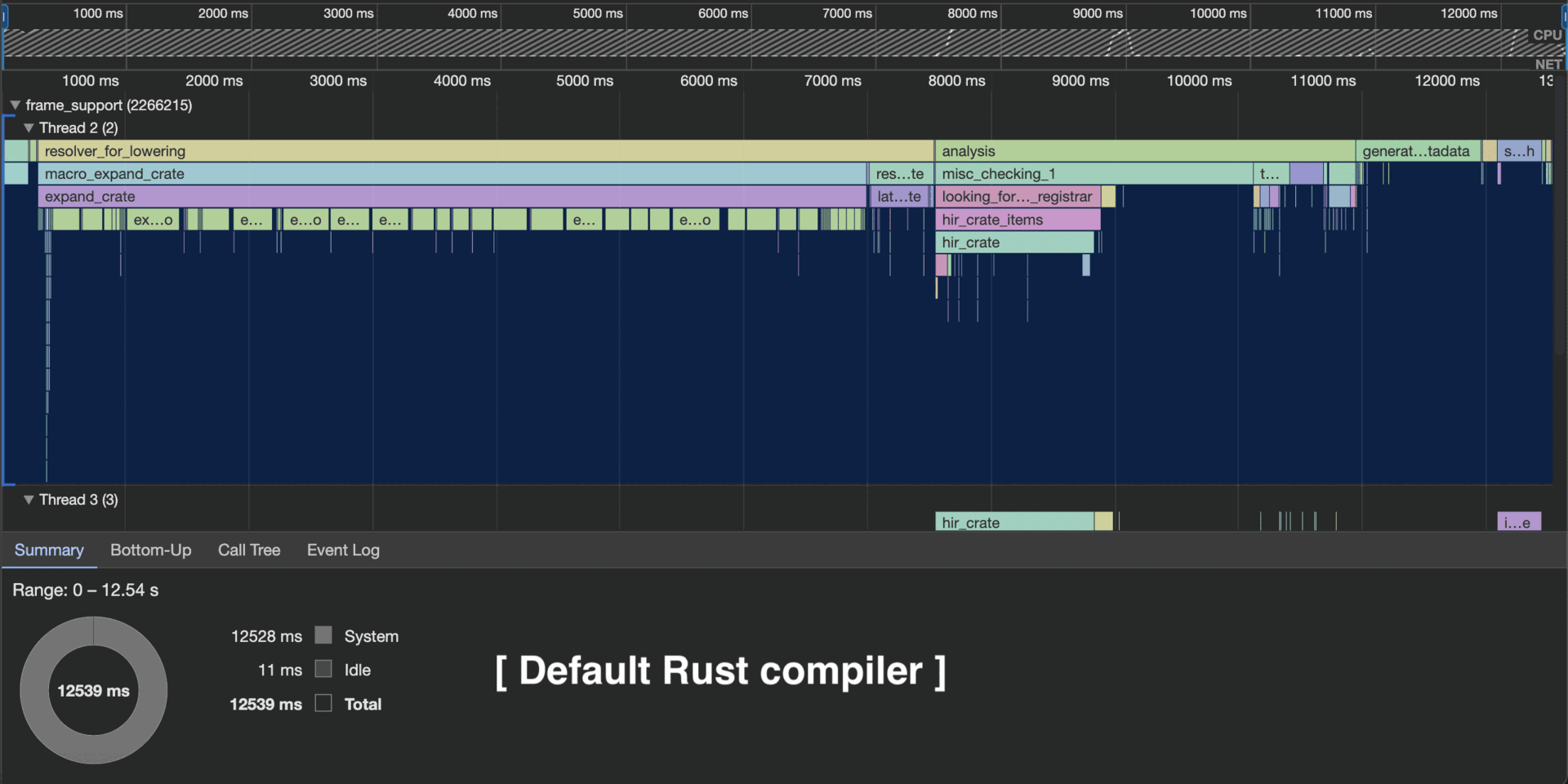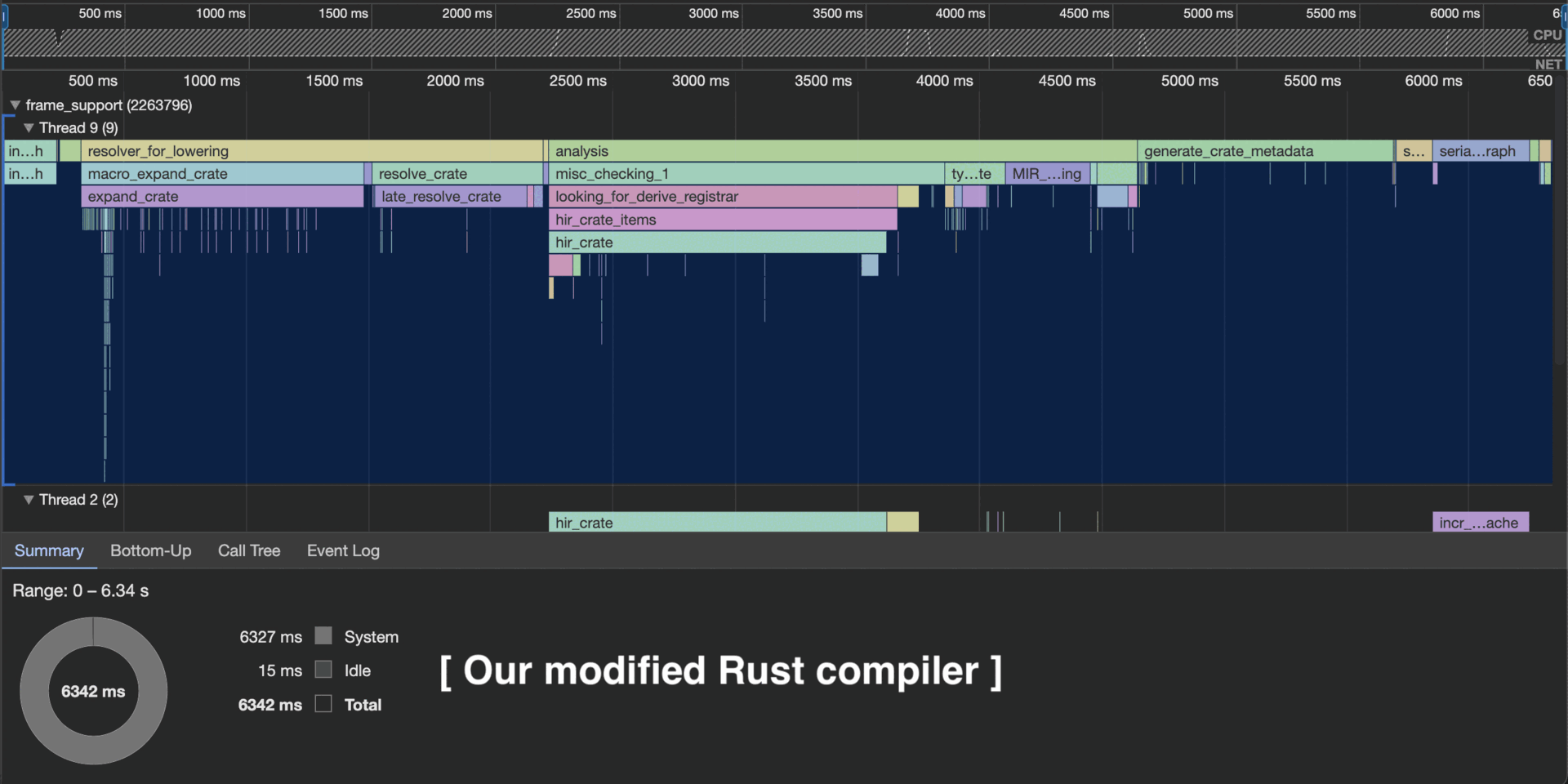
Исполнение этой мета-функции называется раскрытием макроса, а macro_expand_crate (который виден в профиле в начале этой статьи) — это самый первый этап компиляции. Важно то, что если вы измените хотя бы одну строку в своём крейте, то все макросы в этом крейте будут раскрываться с нуля. В отличие от остальной части компилятора***, кэширование здесь отсутствует.
[***Почти весь «фронтенд» компилятора (то есть до этапа генерации кода) реализует кэширование для обеспечения инкрементальной компиляции. Подробности о компиляции на основе очередей см. в статье.]
Почему нам это важно? Вероятно, вы не пишете или почти не пишете процедурные макросы самостоятельно, но я предполагаю, что они активно используются в зависимостях ваших крейтов. Вот примеры одних из самых популярных крейтов с большим количеством макросов: serde, tokio, sqlx, actix-web, leptos, wasm-bindgen, async-[attributes / graphql / trait / stripe]. В их репозиториях GitHub часто обсуждают долгое время сборки: 1, 2, 3.
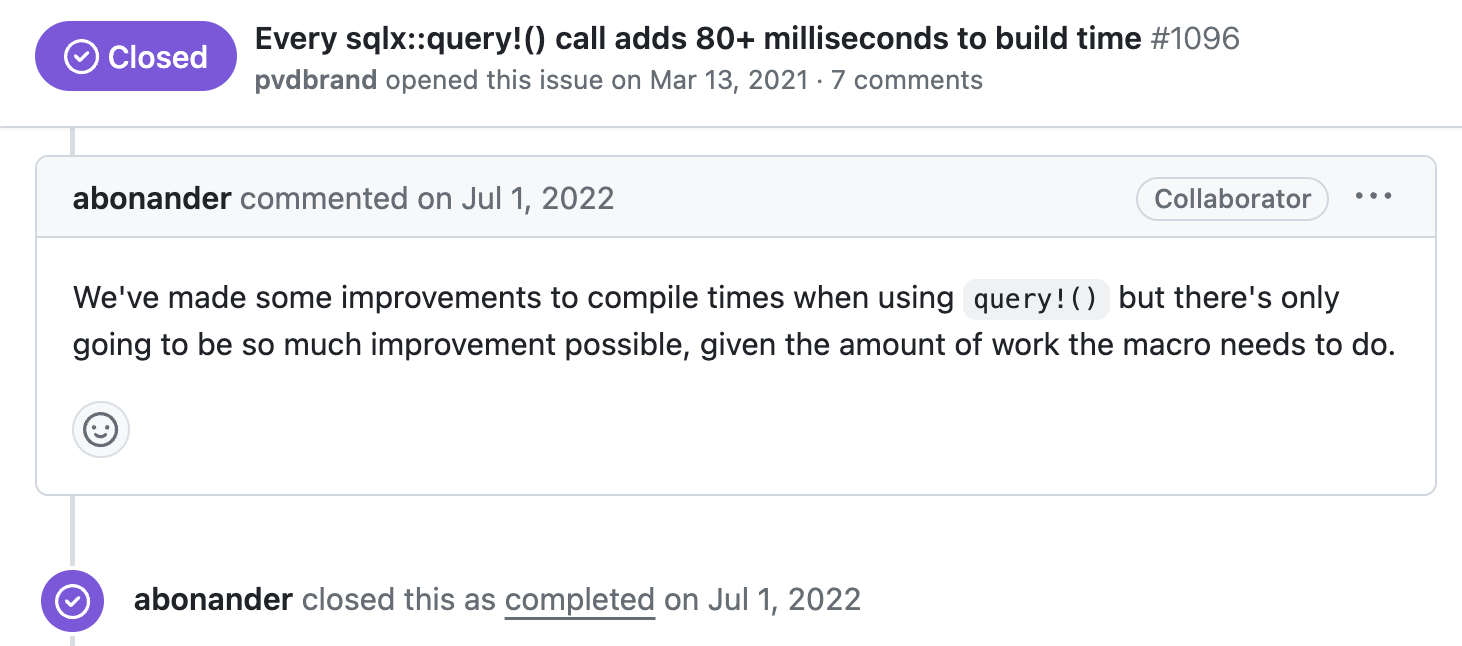
TLDR: медленное раскрытие макросов из ваших зависимостей приводит к медленным сборкам.
Кэширование раскрытия макросов: ускорение инкрементальных сборок Rust на 40%
Есть много умных людей и команд, целенаправленно работающих над совершенствованием компилятора Rust. Сегодня наилучшим результатом улучшения стало ускорение сборок в бенчмарках на 1-2%****. К сожалению, для утомлённого разработчика 1-2% не играют никакой роли.
[****Николас Незеркот написал несколько превосходных статей о недавних улучшениях компилятора. В этих статьях он также продемонстрировал одни из лучших инструментов для измерения производительности компилятора Rust. Его статью за март 2024 года можно найти здесь.]
Моё решение: снижение времени инкрементальных сборок для конкретных проектов
Моё решение, которое мы теперь используем в нашей компании, вынужденно оказалось другим:
Меня волнует исключительно сокращение цикла «редактирование-компиляция-запуск». Моя цель: ускорение инкрементальных dev-сборок.
Мне нужны серьёзные (на десятки процентов) улучшения в ограниченном числе проектов, а не мелкие улучшения во множестве проектов. Решение: профилирование проекта с ужасно долгими инкрементальными сборками, выявление причины медленности, её устранение.
Способы: ускорение раскрытия макросов
Я сразу заметил, что многие проекты, зависящие от async-graphql и sqlx , страдают от низкого времени сборки. Профилировав их, я выяснил, что раскрытие макросов иногда занимает больше трети этого времени. Судя по прочитанному, это довольно слабо оптимизированная часть компилятора.
Решения, которые я рассмотрел и от которых отказался
Я рассмотрел несколько подходов:
Параллелизация раскрытия макросов: компилятор многократно обходит все вызовы макросов, пока не выполнит резолвинг всех имён и пока вложенные макросы не будут развёрнуты. Хотя я и считаю, что параллелизацию вполне можно реализовать, вложенные макросы и резолвинг имён представляют серьёзные трудности при наивном подходе.
Применение среды исполнения Watt*****, то есть компиляция процедурных макросов в WebAssembly: я быстро осознал, что хотя Watt избавляет пользователей от необходимости компиляции процедурных макросов, он не помогает с исполнением этих макросов при раскрытии (и даже немного снижает производительность). Тем не менее, Watt заставил меня сосредоточиться на идее возможности моделирования макросов как чисто детерминированных функций.
[*****Дэвид Толнэй — автор Watt. Подробности см. здесь.]
Кэширование AST и «пушинг» изменений: если между сборками в код вносятся лишь небольшие изменения, описывающее крейт AST (Abstract Syntax Tree) меняется очень незначительно. Тем не менее, компилятор выполняет лексический анализ и парсинг, а также раскрытие******.
[******Во время раскрытия макросов макрос преобразует входное AST в выходное AST. Затем AST вставляется в более крупное AST крейта.]
У меня появилась смутная идея: кэшировать AST из последнего запуска, выявлять изменения кода в новой версии и пушить эти изменения AST в AST предыдущего крейта. Этот путь казался хорошим, но дьявол таился в деталях:
Каким образом будут представлены «изменения в коде»?
Что если новое AST сильно отличается от старого?
Затратны ли вообще лексический анализ и парсинг, то есть существует ли выигрыш от их кэширования?
Кэширование раскрытия процедурных макросов
В конечном итоге, я пришёл к кэшированию раскрытия процедурных макросов. Основная идея проста: процедурные макросы получают в качестве ввода TokenStream (описывающий AST), а на вывод передают другой TokenStream. Компилятор будет кэшировать это отображение из текущей сборки; если в следующей сборке ввод не изменился, то он повторно использует тот же вывод, а не будет вычислять его заново.
Это гораздо более совершенное решение по сравнению с рассмотренным выше применением релизных сборок крейтов процедурных макросов. В случае подавляющего большинства макросов вместо того, чтобы выполнять ту же работу быстрее, компилятор не выполняет никакой работы.
Примечание: побочные эффекты
Процедурные макросы Rust не всегда бывают детерминированными «чистыми» функциями (https://news.ycombinator.com/item?id=29302382). Иными словами, раскрытие макроса с одним и тем же вводом может привести к разным результатам. Например, часто используемый макрос include_bytes считывает содержимое файла. Даже если имя файла остаётся неизменным, результат очевидно изменится, если изменится содержимое этого файла.
Однако на практике подавляющее большинство макросов остаётся чистым. Это основа упомянутой выше среды исполнения Watt, а также причина время от времени возникающих обсуждений процедурных макросов «const» (https://internals.rust-lang.org/t/const-fn-proc-macros/14714).
Дополняем компилятор
Чтобы обеспечить кэширование раскрытия макросов, мне нужно дополнить возможности компилятора. В частности, компилятор должен быть способен на следующее:
Пропускать извлечение макроса из кэша. Как говорилось выше, может потребоваться отказаться от кэширования некоторых раскрытий макросов в случае, если у них есть побочные эффекты. Я просто сделал так, что их можно указывать в переменной окружения. На практике я пока не встречал крейт, в котором нужно пропускать больше трёх макросов.
Хэшировать вызовы макросов (bang, attribute и derive). Кэш раскрытия макросов —это хэш-таблица, сопоставляющая хэши вызовов с раскрытиями. Как и в других частях компилятора, необходимо использовать
StableHash, чтобы обеспечить согласованность хэшей между запусками. Здесь я по возможности избегал хэшированияspan(представляющих позиции в коде), потому что в идеале кэш остаётся валидным, даже если новая строка кода спускает код ниже.Обрабатывать пограничные случаи: дублирующиеся хэши вызовов, интерполированные токены******** и вложенные макросы. Всё это создаёт сложности при вычислении уникальных хэшей вызовов и согласованных выходных AST. Обычно я по возможности делал AST более плоскими и отбрасывал те некэшируемые из них, которые было невозможно.
[********Интерполированные токены — это вложенные узлы AST. Сам исходный код считает их «очень странной» концепцией, от которой команда разработки компилятора «стремится избавиться».]
Сериализовать вывод макросов. К счастью, я мог использовать многими структурами данных для инкрементальных сборок вниз по потоку в компиляторе. Тем не менее, мне всё равно пришлось реализовать собственный механизм сериализации, потому что я кэширую новые
TokenStreamи AST.
Фрагмент кода
На случай, если что-то непонятно, я привёл ниже фрагмент кода с основной логикой.
pub fn expand_crate(&mut self, krate: ast::Crate) -> ast::Crate { // ... Truncated ... // let (mut krate_ast_fragment_with_placeholders, mut invocations) = self.collect_invocations(AstFragment::Crate(krate), &[]); loop { let (invoc, ext) = invocations.pop(); // Gather newly discovered nested invocations and expanded fragments let (expanded_fragment, new_invocations) = self.expand_invoc(invoc, &ext.kind); invocations.extend(new_invocations.into_iter().rev()); } // Insert expanded fragments into the crate AST's placeholders // let expanded_krate = ... let bytes = on_disk_cache.serialize( file_encoder, &self.invoc_hash_and_expanded_stream ); info!( "Cached {} bytes of macro expansion cache (holding {} invocations)", bytes, self.invoc_hash_and_expanded_stream.len() ); expanded_krate } fn expand_macro_invoc( &mut self, invoc: Invocation, // holds macro invocation context ext: &SyntaxExtensionKind, // holds the procedural macro callable ) -> TokenStream { // ... Truncated ... // let invoc_hash = self.disk_cache.as_ref().and_then(|_| self.hash_item_no_spans(&invoc.kind)); let expander = ext.get_macro(); let tok_result: TokenStream = { // 1. Perform lookup of the macro invocation hash in the new macro cache if !self.should_skip_cache() && let Some(cached_stream) = self.disk_cache .as_ref() .unwrap() .try_load_query_result::<TokenStream>(invoc_hash) { // 2a. Pull from cache if it exists debug!("Pulled from cache with hash {:?}!", invoc_hash); cached_stream } else { // 2b. Else compute macro expansion from the proc macro crate debug!("Not found in cache with hash {:?}!", invoc_hash); expander.expand(self.cx, span, mac.args.tokens.clone()) } }; // 3. Cache macro invocation hash with expanded TokenStream self.invoc_hash_and_expanded_stream.push((invoc_hash, tok_result.clone())); tok_result }
Результаты
Я профилировал свой модифицированный компилятор, чтобы сравнить его со стандартным компилятором на множестве реальных проектов Rust. Все подробности представлены в моём репозитории rustc-profiles.
Ниже представлена краткая сводка этих результатов (на 16 марта 2024 года).
Проект | Ускорение, % | Время сборки стандартного компилятора | Время сборки изменённого компилятора | Подробный анализ |
|---|---|---|---|---|
40% | 19.3 s | 11.7 s | ||
35% | 30 s | 19 s | ||
25% | 10.7 s | 8.0 s | ||
21% | 6.3 s | 5.0 s | ||
11% | 18.4 s | 16.4 s |
Картинка в доказательство
Как видно из этого профиля rustc, мой модифицированный компилятор раскрывает только изменённые процедурные макросы.

Полноразмерный PDF можно найти здесь.

