
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
k = (i + j) / 2;
+indexFrom :)while fromIndex < toIndex? Ну и так можно, это всего лишь вариант решения, а по сути — идентичный алгоритм (однако рекурсия в этом случае гораздо выразительнее, т.к. алгоритм рекурсивен по своей сути). И тогда же читать книги Кнута, жаль что из всего 3

Left join — это ещё ничего, а вот когда налепят восемь inner join-ов — вот это да
Или того хлеще, просто перечислят таблицы во from через запятую.
a=range(50,200,2); bsearch = lambda a,s,i=False,step=False:(not step and bsearch(a,s,len(a)/2,len(a)/4+1)) or (a[i]==s and str(i)) or (s<a[i] and bsearch(a,s,i-step,step/2+step%2)) or (bsearch(a,s,i+step,step/2+step%2)); bsearch(a,178); bsearch(a,54);
int binsearch(int* a, int n, int key)
{
int lo = 0;
int hi = n - 1;
while (lo < hi)
{
int mid = lo + (hi - lo) / 2;
if (key > a[mid])
lo = mid + 1;
else
hi = mid;
}
return a[hi] == key ? hi : -1;
}
function array_search($needle, $haystack) {
if (!is_numeric($needle)) {
trigger_error('Invalid argument needle. Numeric expected.');
return false;
}
if (!is_array($haystack)) {
trigger_error('Invalid argument haystack. Array expected.');
return false;
}
sort($haystack, SORT_NUMERIC); // это тестировал
$length = count($haystack);
$from = 0;
$to = $length - 1;
$result = false;
while ($result === false) {
if ($to > $length - 1 || $from < 0) {
$result = null;
} else {
$index = floor(($from + $to) / 2);
if (!is_numeric($haystack[$index])) {
trigger_error('Invalid value of argument haystack. Only numeric values allowed.');
return false;
}
if ($haystack[$index] > $needle) {
$to = $index - 1;
} elseif ($haystack[$index] < $needle) {
$from = $index + 1;
} else {
$result = $index;
}
}
}
return $result;
}
echo array_search(5, array(3, 76, 8, 4, 2, 2, 1, 5, 2, 3, 1, 2, 5, 7, 2, 3)) . "\n";
С массивами так: есть упорядоченный массив, берем число из середины массива, сравниваем с искомым.
arr = [1,2,3,4,5]
(arr+[7]).each{|z| p bis(arr,z)}
begin
end if (__FILE__ == $0)
user system total real
Built-in Array::index 6.950000 0.020000 6.970000 ( 7.735154)
My own binary search 0.900000 0.030000 0.930000 ( 1.195101)
function bins(a,n) {
var res=null, l=0, r=a.length, s;
do {
s=Math.floor((l+r)/2);
if (n<a[s]) {r=s;} else {l=s;}
if (a[l]==n) {res=n;s=r=l;}
if (a[r]==n) {res=n;s=l=r;}
if (r-l==1) l=r;
} while (l<r);
return [res,s];
}
var ar=[1,2,3,6,8,10,13,14,17,18,19,25];
bins(ar,1) // ok
bins(ar,6) // ok
bins(ar,4) // null
* This source code was highlighted with Source Code Highlighter.(defun dixotomy (obj vector) (let ((len (length vec))) (and (not (zerop len)) (finder obj vec 0 (- len 1)))))
(defun bin-search (obj vec)
(let ((len (length vec)))
(and (not (zerop len))
(finder obj vec 0 (- len 1)))))
(defun finder (obj vec start end)
(let ((range (- end start)))
(if (zerop range)
(if (eql obj (aref vec start))
obj
nil)
(let ((mid (+ start (round (/ range 2)))))
(let ((obj2 (aref vec mid)))
(if (< obj obj2)
(finder obj vec start (- mid 1))
(if (> obj obj2)
(finder obj vec (+ mid 1) end)
obj)))))))
return nil if arr.nil? or arr.empty?
>> find([],5)
NoMethodError: undefined method `<' for nil:NilClass
return nil if l == r and arr[l] != value
return nil if l >= r and arr[l] != value
return m

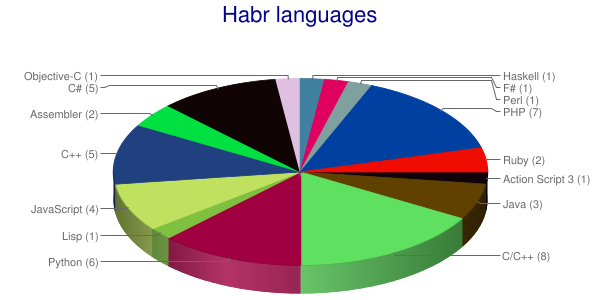
def bin(xs, x):
if not(xs and len(xs)): return None
start, end = 0, len(xs) - 1
while(start != end):
newend = mid = (start + end) // 2
newstart = newend if newend != start else end
start, end = (newstart, end) if (xs[mid] < x) else (start, newend)
return start if (xs[start] == x) else None
def bin(xs, x):
if not(xs and len(xs)): return None
start, end = 0, len(xs) - 1
while(start != end):
mid = (start + end) // 2
start, end = (mid + 1, end) if (xs[mid] < x) else (start, mid)
return start if (xs[start] == x) else None
- public static int Dichotomy(int[] data, int subject)
- {
- if(data!=null)
- for (int step = (data.Length - 1) / 2, stop = (int)Math.Sqrt(data.Length), lim = data.Length;
- stop > -1 && step >= 0 && step < lim;
- step = step + (data[step] > subject ? -1 : 1) * ((step + 1) / 2), stop--)
- if (data[step] == subject)
- return step;
- return - 1;
- }
* This source code was highlighted with Source Code Highlighter.public static int Dichotomy(int[] data, int subject)
{
if (data != null)
for (int step = (data.Length - 1) / 2, index = step, stop = (int)Math.Sqrt(data.Length);
stop > -1 ; step = ((step + 1) / 2), index += (data[index] > subject ? -1 : 1) * step, stop--)
if (data[index] == subject)
return index;
return -1;
}
* This source code was highlighted with Source Code Highlighter.public static int Dichotomy(int[] data, int subject)
{
if (data != null)
for (int len=data.Length, step=(len - 1)/2, index=step, stop=(int)Math.Log(len, 2), sign;
stop-- > -1 && index > -1 && index < len; step=++step/2, index +=sign * step)
if (0 == (sign = subject.CompareTo(data[index])))
return index;
return -1;
}
* This source code was highlighted with Source Code Highlighter.function BinarySearch(value: integer; arr: PIntegerArray; size: integer): integer;
var
mask: cardinal;
index: cardinal;
begin
mask := $80000000;
while mask > size do
mask := mask shr 1;
index := 0;
while mask > 0 do
begin
index := index or mask;
if (index >= size) then
index := index and (not mask)
else if arr[index] > value then
index := index and (not mask)
else if arr[index] = value then
break;
mask := mask shr 1;
end;
if (index < size) and (arr[index] = value) then
Result := index
else
Result := -1;
end;
function BinarySearch(value: integer; arr: PIntegerArray; size: integer): integer;
var
mask: cardinal;
index: cardinal;
begin
mask := $80000000;
while mask > size do
mask := mask shr 1;
index := 0;
while mask > 0 do
begin
index := index or mask;
if (index >= size) or (arr[index] > value) then
index := index and not mask;
if arr[index] = value then
Exit(index);
mask := mask shr 1;
end;
Result := -1;
end;
function binarySearch( inputArray , searchValue ){
var RESULT = false;
var halfLenghtIndex = Math.ceil( ( inputArray.length-1 ) / 2 );
if ( inputArray[ halfLenghtIndex ] === searchValue ){
RESULT = halfLenghtIndex;
} else if ( inputArray[ halfLenghtIndex ] > searchValue ) {
RESULT = binarySearch( inputArray.splice( 0 , halfLenghtIndex ) , searchValue );
} else if ( inputArray[ halfLenghtIndex ] < searchValue && inputArray[ inputArray.length-1 ] >= searchValue ) {
RESULT = halfLenghtIndex + binarySearch( inputArray.splice( halfLenghtIndex , inputArray.length - halfLenghtIndex ) , searchValue );
}
return RESULT;
}
Только 10% программистов способны написать двоичный поиск