Комментарии 18
Год-два назад встречал статью, выводы которой заключались в том, что если продолжать учить модель длительное время после того, как она переобучилась, эффект переобучения постепенно начинает пропадать. В ней было сделано предположение, что модель начинает со временем выучивать не конкретные наблюдения, а реальные взаимосвязи и растет ее обобщающая способность.
Может этот эффект как раз и был связан с тем, что сперва модель формирует большое количество размерностей, а потом начинает их снижать?
Вы говорите про явление Grokking. Да, похоже, что это явление и компрессия репрезентаций очень плотно связаны. Схожая интуиция была в статье про OmniGrok. Было бы очень интересно посмотреть что происходит с внутренней размерностью при переходе от оверфита к генерализации, предположу что там будет "ступенька" на графике внутренней размерности.

А не было попытки узнать, есть ли смысл у осей многомерного пространства? Может если как-то повернуть, на всех осях окажутся определенные типы слов
Да, были работы про "линейный пробинг" эмбеддингов, удалось выявить направления, связанные с координатами и временем (Language Models Represent Space and Time). Работает не идеально, но работает)

Получается, что современный подход к организации обучения позволяет моделям самопроизвольно находить оптимальную комбинацию мыслительных процессов - накопление знаний и их редукцию для формулирования выводов.
Напрашиваются закономерные вопросы:
1) можно ли использовать средний слой с максимальным объёмом знаний как репрезентацию внутреннего мира модели?
2) если учесть, что левая половина слоёв кодирует информацию, а правая - декодирует, то не присутствует ли некая параллель между соответствующими слоями, отстоящими от середины? Можно ли использовать эти параллели для оптимизации графа вычислений (можно ли провести какую-то нормализацию модели типа зеркалирования половин слоёв, но чтобы ответы были такими же, как у исходной)?
Было бы интересно в дальнейшем узнать, как влияют LoRa на поведение внутренних размерностей.
Кстати, на задачах линейного пробинга действительно видно, что средние слои декодеров дают лучшую точность классификации. То есть если модель заморожена и можно обучать только логистическую регрессию поверх эмбеддингов, то лучше брать эмбеддинги из середины.
Вот такой у нас получился график для классификации CIFAR в другой статье про imageGPT.

Если посмотреть на профиль анизотропии по слоям, то становится видно, что в начале и в конце декодеров эмбеддинги гораздо более изотропны, а экстремально высокая анизотропия наблюдается только в середине, где и должен происходить весь мыслительный процесс.
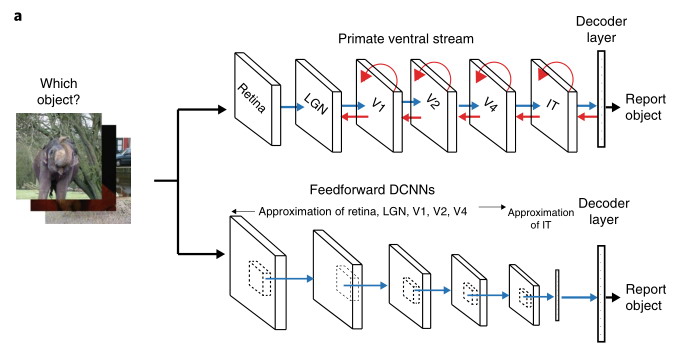
Интересно наблюдать как исследователи свойств ИНС проходят в облегченной форме исследования которые проводили нейрофизиологи на биологических сетях) В облегченной потому как не нужно возится с подопытными и аппаратурой, типа фМРТ и др, а манипулировать только массивами чисел - весов. С другой стороны это полезно, как моделирование нейрофизиологии. В данном случае речь о компрессии информации в мозге. Разнообразных исследований на эту тему множество, они ведутся давно, с тех пор, как была установлена суммативная функция нейронов и сетей в целом, в частности, при сенсорном вводе. Сети, как правило, производят нелинейную фильтрацию информации. Лучшей моделью для сенсорных сетей являются глубокие сверточные с архитектурой подобной структуре вентрального тракта зрительной системы приматов. Но и ассоциативные области мозга, отвечающие за обработку языка, которые условно моделируются в ЯМ, также подчиняются похожим закономерностям. Генерализация - обобщение, в этом случае это абстрагирование, а абстракции связаны с компрессией.
{kind=link}
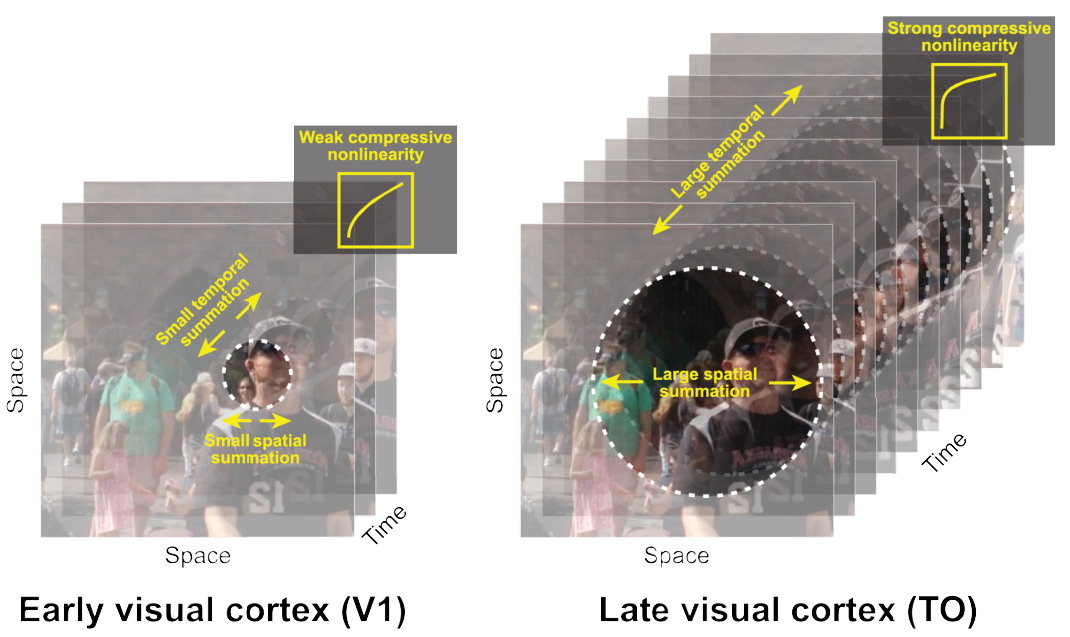
Приведу пример исследования по временной суммации (компресси) в зрительной системе. Аналогичные закономерности наблюдаются и при пространственной суммации, и иллюстрируются такой схемой. Степень сжатия в последовательных отделах зрительного тракта, прототипах слоев в ИНС сверточного типа, изображена на рис. 3 C. Вполне напоминает приведенные в статье по анизотропии по слоям для ЯМ. И видимо будет лучше соответствовать, если к весам применить процедуру обработки подобную фМРТ.
{kind=link}
Важность компрессии информации в мозге настолько велика, что существует даже подход к объяснению сознания и др. ментальных явлений, который основывается на этих представлениях, получивший название компрессионизма. Если приведенная работа является больше методологической, то в этой делается попытка ее некоторой реализации.
Удачи в исследованиях!
А можно подробнее про то, как в данном случае считается анизотропия в сигнале, и что более важно, как нормируется сигнал прежде чем её считать. Потому что центрирование на среднее очень контрпродуктивно если для сигнала характерно ненормальное распределение.
Например в AlexNet распределение logit-ов такое, что 3/4 значений меньше нуля, то есть активации ReLU будут в 3/4 случаев просто 0, а в остальных сигнал. Если такой треугольник относительно 0 отцентровать на среднее вы получите 3/4 одинаковых но не нулевых значений. Для других сетей у меня под рукой насчитанных активаций сейчас нет, вот тут можно графики посмотреть: https://t.me/GradientWitnesses/38, https://t.me/GradientWitnesses/39, но этот случай наводит на мысль.
Это может порождать проблемы, характерные для проблемы шкурки многомерного арбуза - в сильно многомерном пространстве обычная наша трехмерная интуиция ведёт к неправильным выводам.
Например: если у вас миллион логитов, матрица 1000x1000 и все они равны 0 и только по одному в каждой размерности равны 1, то эти вектора ортогональны интуитивно, но на сколько испортится картина если их отцентровать как-то? Интуитивно кажется, что не сильно.
Но если мы сделаем от такой матрицы активаций softmax как это делает multihead attention - то получим матрицу активаций в которой все элементы 0.001 кроме одного строки со значениями 0.027. Угол между этими двумя векторами - всего 4 градуса. А если миллион не один, а сто, то угол вообще может потеряться на фоне ошибки округления. Как вы справляетесь с этой проблемой?
Потому что если посмотреть на ситуацию с этой стороны, то рост анизотропии может свидетельствовать только о том, что Большая часть активаций не задействованы в каждом конкретном случае. А из этого могут следовать большие последствия - значительную часть сети можно не учитывать, а сети в процессе обучения сами стараются привести себя к "сигнальному" состоянию даже если об этом их никто специально не просил.
Не смотрели анизотропию для трансформера-декодера для эмбеддингов с выходов отдельно внимания и FFN?
Извините за небольшое отступление. А кто-нибудь помнит видео с демонстрацией обучения нейросети изнутри? Там на искривленной черно-серой плоскости искались ее наиболее низкие точки. Не могу найти, и не помню деталей.
Добрый день. Подскажите, пожалуйста, что такое "взрывы лосса"? Мои потуги в самостоятельных поисках завершились неудачей.
Добрый день! Взрывы лосса — резкие скачки (спайки) значения лосса во время обучения. Про одну из попыток объяснить это явление для LLM у меня есть довольно понятная и интересная статья (тык). Сейчас приходится перезапускать обучение с другой последовательностью батчей, чтобы модель не разошлась.

Как устроено пространство, в котором думают языковые модели?