В октябре 2020 года Cloudera приобрела компанию Eventador, а в начале 2021 года был выпущен продукт Cloudera Streaming Analytics (CSA) 1.3.0. Это был первый релиз, который включал в себя SQL Stream Builder (SSB), полученный в результате интеграции наработок Eventador в продукт для аналитики потоквых данных на базе Apache Flink.
SQL Stream Builder (SSB) - это новый компонент со своим дружелюбным веб-интерфейсом, позволяющий анализировать потоковые и исторические данные в режиме реального времени в SQL, под капотом которого работает Apache Flink. На сегодняшний день около 3 миллиардов событий анализируется в Apache Fink ежедневно самыми прогрессивными компаниями по всему миру.
Первоначально разработчики сконцентрировались на внедрении в SSB языка определения данных Flink (DDL) и интерфейса для подключения к пакетным данным. Мы хотели использовать разработки последних версий Flink, а также добавить в SSB важные функции. Для заказчиков это открывает огромные новые возможности для интеграции существующих массивов данных с источниками потоковых данных в стеке Cloudera.
Уже в последних версиях (1.4 & 1.5) мы рады анонсировать CSA с унифицированным интерфейсом для работы с потоковыми и пакетными данными . Мы считаем, что это откроет новые возможности для использования в приложениях IoT, финансовой, производственной сфере и многих других отраслях. Это позволяет создавать уникальные потоки ETL, хранилища данных в реальном времени и формировать ценные потоки данных без масштабной модернизации инфраструктуры.
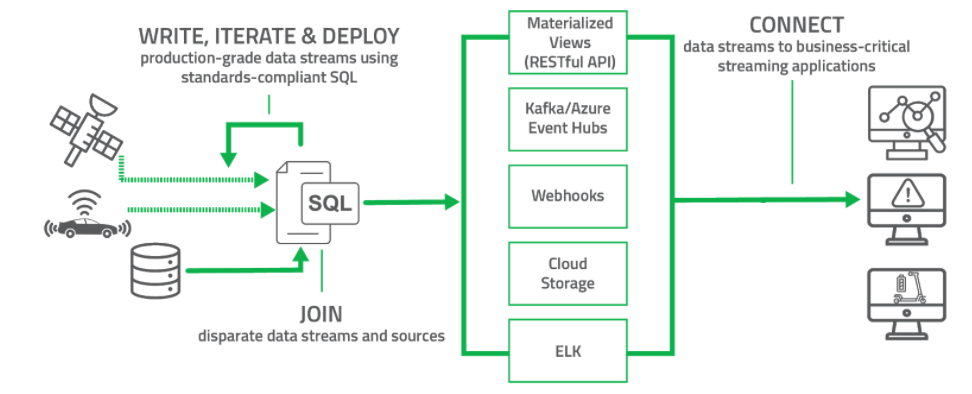
Почему пакетная + потоковая обработка?
Долгое время считалось, что пакетная обработка и потоковая передача (системы с фиксированными и свободными границами) являются ортогональными технологиями - эталонной архитектурой, в которой потоки наполняют озера данных, и не более того.
Но, как работающие с данными специалисты-практики, мы хотели большего. Нам нужна была возможность обращаться к пакетным данным и источникам потоковой передачи данных в логике приложений. Мы хотели иметь инструменты и грамматику SQL, чтобы легко работать с ними. Нам необходимо было легко объединять существующие корпоративные источники данных и потоки данных с высокой скоростью доставки и малой задержкой. Нам нужна была гибкость для решения задач как с помощью пакетных, так и потоковых API, а также возможности прямого подключения к источникам для беспрепятственного чтения и записи данных. Нам нужно было экспериментировать с приложениями, повторять и затем развертывать процессоры, которые можно масштабировать и восстанавливать без массового воспроизведения данных. Мы хотели, чтобы схемы автоматически определялись там, где это возможно, и существовал богатый инструментарий для их создания там, где это необходимо.
В конце концов, бизнесу не важно, каков формат исходных данных. и нам нужен был фреймворк, который позволял бы быстро и легко предоставлять данные как продукт без масштабного наращивания инфраструктуры или использования баз данных нижестоящего уровня. У этой архитектуры нет причудливого названия - в основном потому, что так все так и должно было работать. CSA упрощает создание этих продуктов-данных.
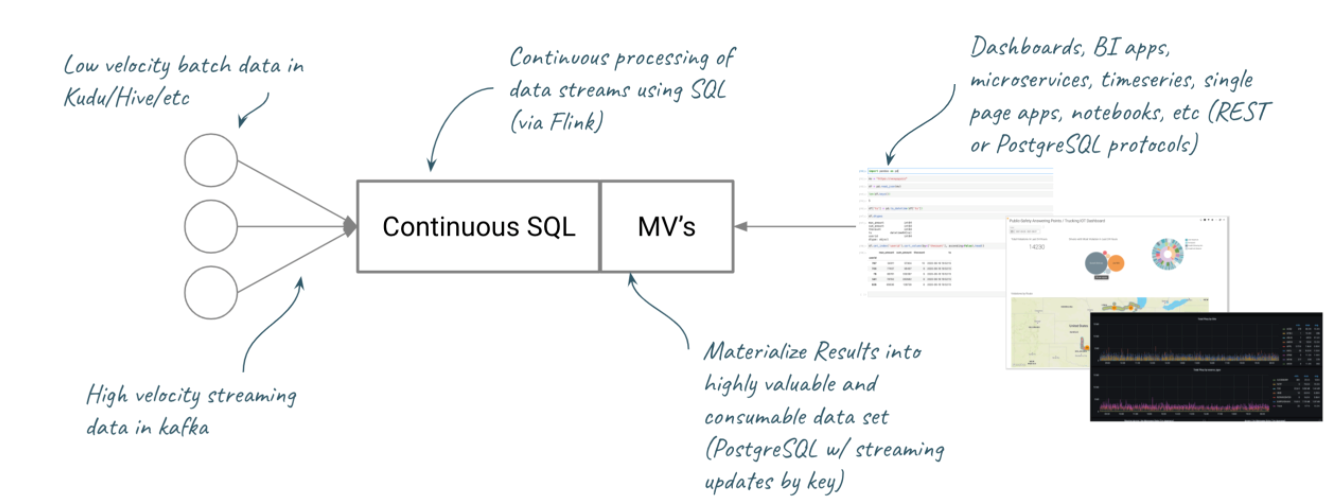
Исторические данные в Kudu/Hive и др.; высокоскоростные потоковые данные в Kafka; непрерывная обработка потоковых данных с помощью SQL (через Flink); информационные панели BI-приложений, микросервисы, временные ряды, одностраничные приложения, блокнот и пр. (протоколы REST или PostgreSQL); материализованные представления в виде ценных и готовых к использованию наборов данных (PostgreSQL с потоковым обновлением по ключу).
Немного из истории Flink
Cloudera Streaming Analytics работает на базе Apache Flink и включает в себя SQL Stream Builder и ядро движка Flink. Возможно, вы не этого знали, но Apache Flink с самого начала был фреймворком для пакетной обработки. Вместе с тем Flink изначально использовал пакетную и потоковую передачу с двумя отдельными API. Предложение 131 по улучшению Flink (Flink Improvement Proposal 131) переопределило API Flink с акцентом на объединение ограниченной/неограниченной обработки в рамках одного и того же API. А раньше нужно было выбирать тот или иной API. С появлением Flip-131 режим обработки будет полностью абстрагирован от программы в табличном API, что позволит разработчику писать программы, которые аккуратно и просто объединяют две парадигмы обработки. Flink всегда ориентировался на корректные результаты и поддерживал однократную обработку. Сочетание мощности движка с грамматикой соединения с ограничением по времени дает нам возможность запрашивать ограниченные (пакетные) и неограниченные (потоковые) данные с использованием простого синтаксиса join. Это полностью меняет правила игры.
SQL Stream Builder и пакетные данные
В отличие от самого Flink, SQL Stream Builder зародился как чисто потоковый интерфейс. Начиная с CSA 1.4, SSB позволяет выполнять запросы для объединения и обогащения потоковых данных с историческими. Для обогащения потоков SSB может присоединять данные из таких источников как Kudu, Hive/Impala и JDBC. Со временем мы продолжим добавление источников и приемников ограниченных данных. SSB всегда мог объединять несколько потоков данных, но теперь он позволяет также обогащать их с помощью источников пакетных данных.
Data Definition Language (DDL)
В основе новой функциональности лежит включение Flink DDL в SSB. Таблицы определяются с помощью схемы (подразумеваемой или указанной), и затем к ним можно применять Continuous SQL, как к любому другому источнику. Кроме того, автоматически доступны все источники данных на платформе Cloudera Data Platform.
-- auto-inferred from CDP catalog import
CREATE TABLE `CDP_Hive_Catalog`.`airplanes`.`faa_aircraft` (
`tailnumber` VARCHAR(255),
`model` VARCHAR(255),
`serial` VARCHAR(255),
`icao` VARCHAR(255),
`owner` VARCHAR(255)
) WITH (
...
)Чтение и обогащение потоковых данных историческими
Например, здесь мы обогащаем поток данных, который измеряет статус тестирования производственных систем. Мы дополняем поток (a) данными о сотрудниках из (b). Мы используем грамматику Flink для указания времени для таблицы (proctime ()) и задаем ключ соединения.
SELECT
a.stationid, a.test, b.managername
FROM
mfgrline AS a
JOIN `CDP_Kudu_Catalog`.`HR_db`.`impala::mfgr.stations`
FOR SYSTEM_TIME AS OF PROCTIME() AS b
ON a.stationid = b.stationidТакже возможно для объединения потоков скомбинировать в одном запросе несколько источников, в том числе потоковых:

Запись данных в системы-приемники
SSB также может писать результаты обработки в различные системы хранения данных. Это мощный инструмент не только для хранения результатов некоторых вычислений, но и для сохранения логического состояния вычислений. Например, можно вести бухгалтерскую книгу для учетных записей, которые вы отключили из-за опасности мошенничества, так что не нужно будет отправлять запросы повторно. Чтобы записать в приемник, достаточно определить таблицу и выбрать ее в качестве приемника.


Новые архитектуры и сценарии использования
Благодаря новым возможностям, которые предоставляет CSA в последней версии 1.5, возможны новые сценарии использования, а также новые реализации, снижающие задержку и ускоряющие выход на рынок.
Распределенное хранилище данных в реальном времени - обогащение потоковых данных историческими с сохранением результата в виде материализованных представлений, доступных по API. Например, возможен расширенный анализ потока кликов или объединение данных с датчиков с историческими измерениями. Новый интерфейс DDL в SSB предоставляет возможность определять источники потоковой передачи и пакетной обработки из любой точки стека CDP и объединять их с помощью Continuous SQL.
Data Science - качественный анализ требует контекста. Например, внедрение персонализированного клиентского опыта в режиме реального времени с обогащением онлайн потоков данных о поведении клиентов исторической информацией о прошлых событиях для ML моделей на Python. SQL Stream Builder предоставляет простой интерфейс REST для материализованных представлений, который легко интегрируется с Python и Pandas внутри блокнотов, поэтому специалисты по данным могут сосредоточиться на небольших, но ценных наборах данных в собственных инструментах, вместо того, чтобы анализировать весь поток данных.
Производственные операции в реальном времени - на производстве важна возможность беспрепятственно обращаться к источникам данных по всему предприятию, а затем материализовать представления для информационных панелей. Это может помочь сократить отходы, контролировать затраты и повысить качество. Пример - объединение исторической частоты отказов станций с текущей телеметрией для отображения прогнозных результатов в Cloudera Dataviz или Grafana.
Что ещё новенького и полезного есть в CSA 1.5?
Импорт Change Data Capture - мы добавили поддержку импорта с Change Data Capture из реляционных баз данных на основе open source проекта Debezium, который оборачивает Flink как среду выполнения вокруг логики, импортированной из Debezium. Этот подход не требует внесения изменений в таблицы репликации базы данных, вместо этого он напрямую подключается к потоку репликации базы данных.
Например, следующая таблица может быть определена для подключения к потоку CDC из СУБД Oracle:

Java UDF - в SQL Stream Builder уже была поддержка UDF на Javascript, определенных в графическом интерфейсе. Теперь мы добавили возможность использовать Flink SQL Java UDF-функции , добавляя их в classpath.
Например, следующая простая функция инкремента реализована как Flink Java Function:
package com.cloudera;
import org.apache.flink.table.functions.ScalarFunction;
public class FlinkTestJavaUDF extends ScalarFunction {
public Integer eval(Integer i) {
return i + 1;
}
}RESTful API для SQL Stream Builder - в этом релизе мы представляем RESTful API для всех операций SQL Stream Builder. Это обеспечивает программный доступ и автоматизацию заданий в SQL Stream Builder. Сопровождающая страница Swagger доступна как часть нашей документации. Например, следующий вызов создает самостоятельное новое задание:
curl --location --request POST '<streaming_sql_engine_host>:<streaming_sql_engine_port>/api/v1/ssb/sql/execute' \
--header 'Content-Type: application/json' \
--data-raw '{
"sql": "CREATE TABLE IF NOT EXISTS datagen_sample (col_int INT, col_ts TIMESTAMP(3), WATERMARK FOR col_ts AS col_ts - INTERVAL '\''5'\'' SECOND) WITH ('\''connector'\'' = '\''datagen'\'');\nSELECT * FROM datagen_sample;",
"job_parameters": {
"job_name": "production_job"
}
}'Как я могу попробовать этот инструмент?
Попробовать самостоятельно CSA очень легко и просто - недавно мы выпустили Community Edition этого продукта, который вы можете скачать и поднять на докере за считанные минуты!
Документация по установке тут!
Статья об этом релизе на Medium
Мы надеемся, что вы так же воодушевлены будущим потоковой передачи данных, как и мы. Наши инженеры неустанно работали над тем, чтобы вывести на рынок Cloudera Streaming Analytics и раскрыть новые возможности, сочетающие пакетную обработку и потоковую передачу данных. Возможно, именно поэтому по результатам последнего исследования Forrester Wave, Streaming Analytics (2 квартал 2021 года) Cloudera была отмечена как «сильный игрок» (Strong Performer).
