Одной из самых интересных и важных компонент современного оптимизирующего компилятора является межпроцедурный анализ и оптимизации. Хороший стиль программирования и необходимость разделения работы между разработчиками диктует необходимость разбиения большого проекта на отдельные модули, в которых основные утилиты реализованы как «черные ящики» для всех основных пользователей. Детали реализации, в лучшем случае, известны паре-тройке конкретных разработчиков, ну а иногда, за давностью лет, и вообще никому неизвестны. (А что поделаешь – специализация, глобализация). Ваш код, зачастую, содержит вызовы внешних функций, тела которых определены во внешних файлах или библиотеках и ваши знания о этих функциях минимальны. Ну и помимо этого при разработке больших проектов плодятся всякие глобальные переменные, с помощью которых компоненты большого проекта обмениваются ценной информацией, и для того, чтобы разобраться в работе вашей части кода в случае каких-то проблем, бывает необходимо перелопатить массу кода. Очевидно, что все это сильно осложняет и работу оптимизирующего компилятора. Какие негативные эффекты порождает модульность и есть ли в компиляторе специальные средства для их преодоления – тема для большого разговора. Сейчас я попытаюсь начать такой разговор. Я расскажу о некоторых интересных особенностях работы оптимизирующего компилятора на примере работы компилятора Intel. Ориентироваться буду на OS Windows, поэтому опции компилятора привожу характерные для этой платформы. Ну и чтобы облегчить себе жизнь, я иногда буду использовать аббревиатуры IPA для межпроцедурного анализа и IPO для межпроцедурных оптимизаций. А начну я с рассказа о моделях межпроцедурного анализа и графе вызовов.
Чтобы понять, в чем могут заключаться проблемы порождаемые модульностью, нужно посмотреть, какие существуют варианты работы компилятора, как компилятор пытается решать те или иные проблемы, какие есть ограничения на используемые компилятором методы анализа. Компилятор должен работать консервативно, т.е. с полным недоверием к программисту и программе и делать ту или иную оптимизацию только если полностью доказана ее корректность.
Самый простой вариант работы компилятора – это однопроходная компиляция. При таком варианте работы компилятор обрабатывает поочередно все функции из исходного файла плюс «держит в голове» все предшествующие декларации. Т.е. компилятор последовательно разбирает символы из исходного файла, заполняет таблицы с различными определениями функций, заводит описания определяемых типов и последовательно разбирает тела всех функций в обрабатываемом исходном файле. Сначала компилятор решает задачу проверки программы на соответствие требованиям стандарта языка, затем он может выполнять различные оптимизации – цикловые, скалярные, оптимизации графа потока управления и т.д. По окончании обработки результат сохраняется в объектный файл. При такой работе успешно (и как правило относительно быстро) решается задача – получить работающее приложение, но до оптимальной его работы очень далеко. Причиной этого является то, что компилятор имеет недостаточно информации о нелокальных для обрабатываемой функции объектах. Также компилятор имеет очень мало информации о вызываемых функциях. Влияет ли такое положение вещей на производительность приложения и какие существуют проблемы, связанные с использованием вызовов функций? За примерами далеко ходить не надо. Перечислю некоторые, наиболее, на мой взгляд, важные:
Наверное, этот список можно продолжать.
Возникает желание собрать различные свойства функций и затем использовать их при оптимизации и обработке каждой конкретной функции. Собственно, это и является основной идеей межпроцедурного анализа. Для проведения такого анализа необходимо учитывать взаимоотношения всех участвующих в расчетах функций друг с другом. Понятно, что для того, чтобы установить свойства некой функции, необходимо проанализировать все функции, которые она вызывает и т.д. Например, в некоторых языках есть «чистые» функции (pure function) и вы завели, используете и вычисляете подобный аттрибут для всех функций. Pure функция не изменяет своих аргументов и каких-либо глобальных переменных и не выводит никакой информации. Понятно, что этот аттрибут для функции можно установить только если все вызываемые внутри этой функции функции являются pure.
Для отражения этих взаимовлияний и взаимоотношений используется граф вызовов (call graph). Его вершинами являются существующие функции, а гранями являются вызовы. Если функция foo вызывает bar, то соответствующие этим функциям вершины соединяются ребром. Поскольку вызовов может быть несколько, то и количество ребер может быть разным, то есть граф вызовов является мультиграфом.
IPA анализ работает со статическим графом, т.е. графом отражающим все возможные пути, которые могут быть пройдены при выполнении программы. Иногда при анализе производительности необходимо анализировать динамический граф вызовов, т.е. реальный путь, по которому управление передавалось при выполнении программы с каким-то конкретным набором данных.
Для того, чтобы построить граф вызовов, необходимо сначала пройти по всем функциям и определить, какие вызовы осуществляются в каждой функции. Затем проанализировать построенный граф и определить какими свойсвами обладает каждая функция. Осуществить различные межпроцедурные оптимизации и только после этого обрабатывать каждую отдельную функцию. При таком порядке работы необходимо как минимум два раза обрабатывать тело каждой функции — такой метод компиляции называется двухпроходным.
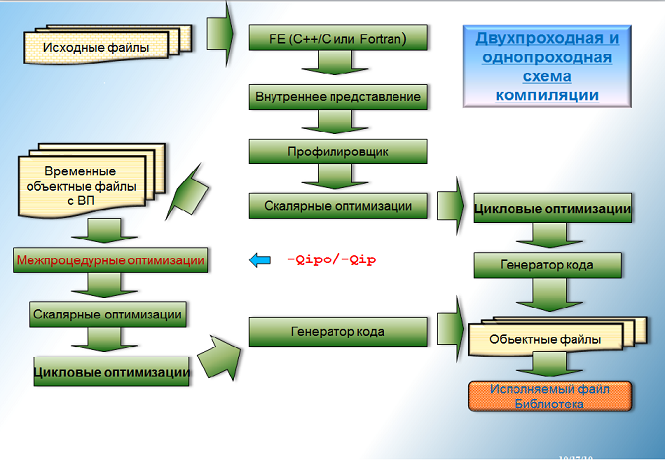
Можно нарисовать примерно такую схему для двухпроходной и однопроходной схемы компиляции.
В случае когда программист задает опцию для включения межпроцедурных оптимизаций, компилятор делает лексический и синтаксический анализ каждого файла с исходными текстами и, если файл соответствует стандарту языка, то компилятор создает внутреннее представление и упаковывает его в объектный файл. Когда все необходимые файлы с внутренним представлением созданы, компилятор повторно их все изучает, собирает информацию о каждой функции, находит все вызовы внутри функций и строит граф вызовов. Анализируя граф вызовов, компилятор «протягивает» по нему различные свойства функций, анализирует свойства различных объектов и т.п. После этого производятся межпроцедурные оптимизации, которые изменяют граф вызовов или свойства объектов. (Я надеюсь, что спустя какое-то время соберусь и расскажу о самых интересных на мой взгляд оптимизациях подробнее.) Многие оптимизации применимы только в случае, если компилятору удается доказать, что выполняется генерация исполняемого файла, и граф вызовов содержит все функции программы. Такие оптимизации называются оптимизациями всей программы (whole program optimization). Примерами таких оптимизаций является удаление из графа вызовов отдельных функций или частей графа вызовов, в которые нельзя попасть из main (dead code elimination). Другим известным примером является изменение структур данных. Большинство межпроцедурных оптимизаций могут выполняться как для полного, так и неполного графа вызовов. Самой известной межпроцедурной оптимизацией является подстановка тела функции (inlining), подставляющей тело функции вместо ее вызова.
После того, как все межпроцедурные оптимизации выполнены, все функции, входящие в итоговый граф вызовов поочередно обрабатываются оптимизирующей частью компилятора (backend). Различие с однопроходной компиляцией состоит в том, что о каждой вызываемой функции может быть известна какая-то дополнительная информация, например, изменяет ли функция тот или иной объект. Эта дополнительная информация и позволяет проводить оптимизации более эффективно.
На самом деле из моего описания видно, что термин двухпроходная оптимизация — это достаточно условный термин и на самом деле проходов по телу функции может быть больше.
Итак, если использовать компилятор для создания объектного файла, например с опцией –с, то в зависимости от наличия или отсутствия опции –Qipo будут создаваться разные сущности. С -Qipo объектный файл — это упакованное внутреннее представление, а не обычный объектный файл. Такие файлы не поймут линковщик link и утилита для созания библиотек lib. Для работы с такими объектными файлами нужно использовать их расширенные Intel аналоги xilink и xilib. Библиотека, созданная из объектных файлов с внутренним представлением будет содержать секции с внутренним представлением и это значит, что те утилиты, которые она содержит, смогут принять участие в межпрпоцедурном анализе в тот момент, когда такая библиотека будет прилинковываться к приложению.(Естественно только с использованием интеловского компилятора и опции -Qipo.) Отсюда следует, что для того, чтобы получить максимальную выгоду от использования компилятора Intel и межпроцедурного анализа, необходимо использовать библиотеки, созданные с помощью компилятора Intel с использованием –Qipo. Чтобы межпроцедурный анализ мог работать с системными функциями, в компиляторе есть информация об этих функциях.
Кстати говоря, если по какой-то причине вы смешаете мух и котлеты, т.е. обычные объектные файлы и файлы собранные с –Qipo и вызовете для их обработки интеловский компилятор (icl), то ничего страшного не произойдет. Компилятор заметит, что вы передаете ему внутреннее представление и включит межпроцедурный анализ/оптимизации автоматом. IPA и IPO будут выполняться для неполного графа вызовов (т.е. графа вызовов, в котором есть неизвестные функции), в который войдут все функции, для которых есть внутреннее представление. Компилятор создаст объектные файлы и затем вызовет линковщик, чтобы прилинковать к ним обычные объектные файлы. Но в общем случае, попавший в сборку программы с –Qipo «обычный» объектный файл может отключить целый пласт оптимизаций, оптимизации целой программы (whole program optimizations).
Понятно, что межпроцедурные оптимизации не даются даром. Работа с графом вызовов может быть достаточно сложной и ресурсоемкой и многое определяется размерами графа. Ради интереса я посмотрел на известный тест на производительность из сьюта для измерения производительности CPU2006 447.dealII (это c++ приложение) и вывел информацию о количестве вершин графа вызовов перед началом межпроцедурного анализа. Получилось, что перед межпроцедурным анализом существовало примерно 320 000 различных функций и примерно 380 000 различных дуг, их связывающих. Большие проекты могут испытывать проблемы с использованием двухпроходной компиляции и межпроцедурным анализом.
В компиляторе Intel реализованы две различные модели межпроцедурного анализа, а именно однофайловая и многофайловая модель. Однофайловая включается по умолчанию, если не задан режим многофайловой межпроцедурной оптимизации. В описании опций это выглядит как-то так:
Ну и плюс еще есть две дополнительные опции, о которых я упомяну чуть позже.
Тут я позволю себе привести схему некоего абстрактного графа вызовов, характерного для C-шного проекта, чтобыстатья смотрелась красивее работа компилятора с деревом вызовов для обоих методов выглядела более наглядно.
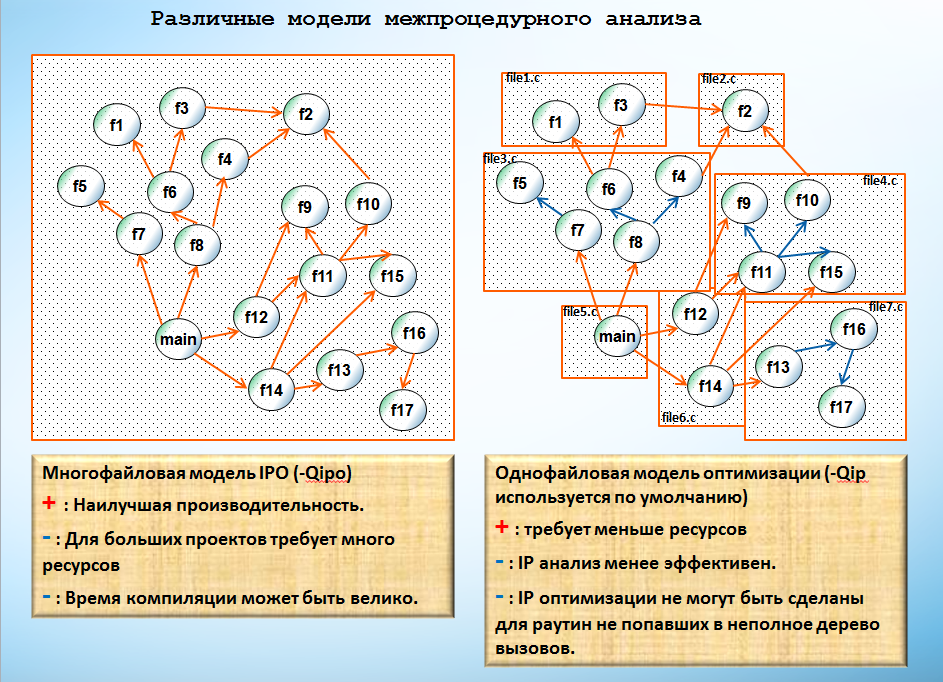
Формально можно сказать, что c –Qipo требуется больше ресурсов, а –Qip требует меньше ресурсов, но и обеспечивает худшее качество оптимизаций.
В реальности не все так однозначно, по крайней мере с ресурсами. Конечно, на самом деле графы вызовов для одного файла не являются подграфами графа вызовов для всего проекта. Например, графы для разных файлов могут содержать одни и те же функции, пришедшие из файлов описаний и являющиеся локальными для каждого файла. Особенно это актуально для больших C++ проектов. Такие функции могут быть продублированы в графах вызовов для некоторых файлов. На мой взгляд, условно можно считать, что эти функции являются неким аналогом weak функций. Поэтому, если просуммировать количество вершин для каждого отдельного графа при однофайловой модели оптимизации, то число вершин может получиться гораздо больше, чем число вершин в полном графе вызовов. При этом при однофайловой модели оптимизации все эти weak функции попадают в обработку и компилятор «возится» с каждой из них для того, чтобы затем линковщик оставил в исполняемом файле или библиотеке одну версию этой функции. Также количество работы при многофайловой обработке может быть уменьшено за счет удаления недостижимых из main подграфов и функций. Если функция была подставлена во все свои вызовы (и выполнены еще некоторые условия), то функция не будет обрабатываться оптимизирующей частью компилятора, т.е. итоговый исполняемый файл не будет содержать тела этой функции. Для однофайловой модели это верно только если функция имеет аттрибут static. Т.е при однофайловом IPA в обработку попадет какое-то количество «мертвых» функций.
Вообщем, может случиться, что в сумме компилятор выполнит гораздо больше работы с –Qip чем c –Qipo. При компиляции программы вместо одного большого графа вызовов придется обрабатывать много графов поменьше. В результате каждая однофайловая компиляция потребует гораздо меньше ресурсов, чем работа с полным графом вызовов, но количество истраченных ресурсов в сумме на компиляцию всех файлов может быть гораздо больше, чем при работе с полным графом вызовов.
Проиллюстрирую это уже упомянутым бенчмарком 447.dealII из CPU2006. Я уже написал, что в полном графе вызовов этого приложения приблизительно 320 000 вершин. В компиляции участвуют почти 120 файлов. Суммарное количество всех вершин в графах вызовов всех обрабатываемых файлов ~1500000 вершин (хотя в каждом файле вершин меньше 50000). Т.е. в 5 раз больше, чем количество всех вершин в полном графе вызовов. Я выключил все варианты параллельной компиляции и получил, что программа с –Qipo компилируется на моем Nehalemе приблизительно 160s, в то время как с –Qip время компиляции ~495s, т.е. в 3 раз больше. Если посчитать количество функций, которые обрабатываются в backendе с –Qipo, то получится ~19500 функций. Суммарное количество обработанных функций при компиляции проекта с –Qip равно ~55000. Ну и если посмотреть на размер выполняемого файла, то для этого приложения файл собранный с –Qipo почти на треть меньше файла собранного с –Qip.
Главным достоинством однофайловой оптимизации является то, что в этом случае при правке одного файла не нужно делать полного перестроения всего приложения, а перекомпилировать всего один файл и слинковать его с другими объектными файлами. Кроме того работу с –Qip легко распараллеливать, а вот создание приложения с –Qipo хуже поддается параллелизации. Хотя опция –Qipo может содержать числовой аргумент (например -Qipo2 подразумевает работу в двух потоках), но IPA выполняется на полном графе вызовов и пока еще не придуман хороший метод распараллеливания этого анализа, поэтому эта часть работы делается в один поток (или повторяется в каждом потоке) и кроме того каждый поток получает в нагрузку массу данных собранных IPA. Обработка всех функций в backendе может быть эффективно распределена между потоками, но из-за вышеперечисленных трудностей такая автоматическая параллелизация менее эффективна, чем в случае использования однофайловой модели.
Кстати говоря, хочется здесь упомянуть еще одну полезную опцию.
Если вы вдруг решили пойти простейшим путем и компилировать ваш проект с помощью одного вызова интеловского компилятора, передавая компилятору сразу все опции и список всех исходников, то по умолчанию компиляция будет осуществляться в один поток и нужно примнять специальную опцию для ускорения компиляции. Эта опция воздействует только на компиляцию без многофайлового IPA.
Если упомянутый 447.deallI компилировать с различными значениями в –Qipo, то время компиляции будет меняться так: -Qipo1: 160s, -Qipo2: 136s, -Qipo4: 150s. Т.е. очень скоро потоки начинают мешать друг другу.
Если в том же вызове icl заменить –Qipo на –Qip (или убрать вообще, -Qip будет работать по умолчанию) и добавить опцию /MP, то получится следующее: /MP1: 495s; /MP2: 259s; /MP4: 145s; /MP8: 117s; /MP16: 84s
Если говорить о производительности, то многофайловый IPA намного эффективнее. (Хотя всегда существует некоторая вероятность «горя от ума»). Легко придумать простой пример, который бы продемонстрировал преимущества многофайловой модели в плане возможности использовать различные оптимизации благодаря дополнительной информации от IPA.
test_main1.c:
test1.c:
test2.c:
Здесь используется опция –Qparallel, которая включает автопараллелизатор интеловского компилятора и –Qpar_report3 — опция, выдающая информацию о том, какие циклы были обработаны или отвергнуты автопараллелизатором и почему.
Вывод без –Qipo сообщает следующее:
Вывод с –Qipo:
Из вывода с –Qipo видно, что межпроцедурный анализ помог осуществить автопараллелизацию цикла.
Понятно, что в случае с –Qipo помогает еще и инлайнинг, но даже если инлайнинг запретить, то благодаря анализу функции calc у компилятора появляется возможность доказать правомерность автопараллелизации.
А что делать, если по какой-то причине многофайловая модель неприменима, например, для построения программы требуется много времени и это вас не устраивает? Можно повышать полезность работы однофайловой модели за счет размещения в файле совместно используемых функций. Очень полезен для функций атрибут static. Если функция имеет этот атрибут, значит IPA при однофайловой работе видит все вызовы этой функции и если у этих вызовов есть какие-то особенности, то они могут быть протянуты внутрь функции. Если все вызовы статической функции были подставлены, то само тело функции можно удалить. То же самое касается и статических объектов. Межпроцедурный анализ считает, что видит все примеры их использования и может выполнять с ними различные оптимизации. В общем, всякие ограничения области видимости объектов одним файлом могут помочь сделать более качественный однофайловый межпроцедурный анализ.
А что, если в рамках однофайловой нельзя решить какие-то проблемы, поскольку важная функциональность разнесена между несколькими файлами?
Опция –Qipo-c предоставляет возможность организовать некую промежуточную модель работы, т.е. строить граф вызовов не на основе функций из одного или всех файлов, а поделить все файлы на группы. Это удобно если ваш проект разбит на несколько тесно взаимосвязанных кусков. (Например, таким проектом является наш компилятор, в котором есть несколько компонент использующих общие утилиты и расположенные в отдельных директориях). –Qipo-c создает объектный файл с фиксированн��м именем ipo_out.obj и в этот файл попадают все функции из перечисленных в вызове компилятора файлов. В приведенном выше примере приложение можно было бы скомпилировать следующим образом:
Вывод при компиляции двух первых файлов показывает, что в данном случае будет и работать и автопараллелизация и инлайнинг, поскольку критически важные функции были объединены в одном графе вызовов, что и дало возможность сделать межпроцедурный анализ и оптимизации.
Вот такой вопрос, а использовал ли кто-либо из читателей такую схему компиляции или хотя бы слышал о ней? Есть такое мнение, что проблема производительности интересует только процентов 5% разработчиков. Зачастую желание предоставить пользователю какие-то дополнительные рычаги для управления работой компилятора упирается в простой вопрос: «А кому вообще это надо и кто это будет использовать?»
Кстати говоря, можно добавлять и удалять какие-то файлы из обработки межпроцедурным анализом используя метод «мух и котлет»: создавая объектные файлы с –Qipo и без. В этом случае межпроцедурный анализ будет проводится на неполном дереве, полученных из функций, которые описаны в файлах скомпилированных с –Qipo. В описанном мной примере это тоже работает.
Ну и наконец опция –Qipo-S полезна для тех, что хочет модернизировать или поизучать ассемблер после межпроцедурных оптимизаций.
На этом я закончу рассказ о графах вызовов как основе IPO и IPA. Надеюсь продолжить рассказ об межпроцедурных оптимизациях и постараюсь ответить на все вопросы.
Влияние модульности на производительность
Чтобы понять, в чем могут заключаться проблемы порождаемые модульностью, нужно посмотреть, какие существуют варианты работы компилятора, как компилятор пытается решать те или иные проблемы, какие есть ограничения на используемые компилятором методы анализа. Компилятор должен работать консервативно, т.е. с полным недоверием к программисту и программе и делать ту или иную оптимизацию только если полностью доказана ее корректность.
Самый простой вариант работы компилятора – это однопроходная компиляция. При таком варианте работы компилятор обрабатывает поочередно все функции из исходного файла плюс «держит в голове» все предшествующие декларации. Т.е. компилятор последовательно разбирает символы из исходного файла, заполняет таблицы с различными определениями функций, заводит описания определяемых типов и последовательно разбирает тела всех функций в обрабатываемом исходном файле. Сначала компилятор решает задачу проверки программы на соответствие требованиям стандарта языка, затем он может выполнять различные оптимизации – цикловые, скалярные, оптимизации графа потока управления и т.д. По окончании обработки результат сохраняется в объектный файл. При такой работе успешно (и как правило относительно быстро) решается задача – получить работающее приложение, но до оптимальной его работы очень далеко. Причиной этого является то, что компилятор имеет недостаточно информации о нелокальных для обрабатываемой функции объектах. Также компилятор имеет очень мало информации о вызываемых функциях. Влияет ли такое положение вещей на производительность приложения и какие существуют проблемы, связанные с использованием вызовов функций? За примерами далеко ходить не надо. Перечислю некоторые, наиболее, на мой взгляд, важные:
- Проблемы с разрешением неоднозначности при работе с памятью. Например, в предыдущих моих постах я обсуждал проблему распознавания циклов и сопутствующую ей проблему разрешения неоднозначности при работе с памятью (alias analysis). Т.е. если в программе есть аргументы указатели и/или используются глобальные переменные, то существует возможность того, что идет работа с одной и той же памятью через несколько различных объектов. Такая неопределенность мешает компилятору распознавать циклы, создает предполагаемые зависимости, мешающие выполнению цикловых оптимизаций, затрудняет анализ потока данных и т.д. Компилятор, зачастую, пытается решить такие проблемы, создавая многоверсионный код, т.е. вставляет в код проверки времени выполнения. Но это «утяжеляет» код и хорошо только для простых случаев, когда предполагаемых зависимостей мало, а что делать если неразрешенных вопросов много?
- При передаче в функцию теряются многие свойства актуальных аргументов, которые могли бы оказать влияние на качество оптимизации. Например, информация о расположении объектов в памяти влияет на выигрыш от векторизации. Если актуальный аргумент константа, то ее протяжка внутрь функции также может вызвать упрощение выполняемых расчетов. Ну и т.д.
- Вызов функции с неизвестными свойствами затрудняет анализ потока данных. Появляется необходимость считать, что этот неизвестный вызов может изменить все данные до которых, согласно стандарту языка, он может дотянуться. (Например, глобальные указатели и переменные, объекты, доступ к которым передается функции через аргументы). Это мешает таким оптимизациям, как протяжка констант, удаление общих подвыражений и многим другим.
- Циклы с вызовом неизвестных функций не могут быть корректно классифицированы (как циклы с определенным количеством итераций). Это происходит потому, что неизвестная функция может содержать выход из программы. В результате непременимы практически все цикловые оптимизации.
- Вызов функции сам по себе достаточно затратен. Необходимо подготовить аргументы, выделить место на стеке для хранения локальных переменных, загрузить на выполнение инструкции с нового адреса. Велика вероятность, что данные адреса не будут находится в кэше. Если тело функции невелико, то может так случиться что затраты на ее вызов огромны по сравнению со временем ее работы.
- При статической линковке программа будет содержать избыточный код – неиспользуемые функции из исходников и библиотек.
Наверное, этот список можно продолжать.
Возникает желание собрать различные свойства функций и затем использовать их при оптимизации и обработке каждой конкретной функции. Собственно, это и является основной идеей межпроцедурного анализа. Для проведения такого анализа необходимо учитывать взаимоотношения всех участвующих в расчетах функций друг с другом. Понятно, что для того, чтобы установить свойства некой функции, необходимо проанализировать все функции, которые она вызывает и т.д. Например, в некоторых языках есть «чистые» функции (pure function) и вы завели, используете и вычисляете подобный аттрибут для всех функций. Pure функция не изменяет своих аргументов и каких-либо глобальных переменных и не выводит никакой информации. Понятно, что этот аттрибут для функции можно установить только если все вызываемые внутри этой функции функции являются pure.
Для отражения этих взаимовлияний и взаимоотношений используется граф вызовов (call graph). Его вершинами являются существующие функции, а гранями являются вызовы. Если функция foo вызывает bar, то соответствующие этим функциям вершины соединяются ребром. Поскольку вызовов может быть несколько, то и количество ребер может быть разным, то есть граф вызовов является мультиграфом.
IPA анализ работает со статическим графом, т.е. графом отражающим все возможные пути, которые могут быть пройдены при выполнении программы. Иногда при анализе производительности необходимо анализировать динамический граф вызовов, т.е. реальный путь, по которому управление передавалось при выполнении программы с каким-то конкретным набором данных.
Для того, чтобы построить граф вызовов, необходимо сначала пройти по всем функциям и определить, какие вызовы осуществляются в каждой функции. Затем проанализировать построенный граф и определить какими свойсвами обладает каждая функция. Осуществить различные межпроцедурные оптимизации и только после этого обрабатывать каждую отдельную функцию. При таком порядке работы необходимо как минимум два раза обрабатывать тело каждой функции — такой метод компиляции называется двухпроходным.
Можно нарисовать примерно такую схему для двухпроходной и однопроходной схемы компиляции.
В случае когда программист задает опцию для включения межпроцедурных оптимизаций, компилятор делает лексический и синтаксический анализ каждого файла с исходными текстами и, если файл соответствует стандарту языка, то компилятор создает внутреннее представление и упаковывает его в объектный файл. Когда все необходимые файлы с внутренним представлением созданы, компилятор повторно их все изучает, собирает информацию о каждой функции, находит все вызовы внутри функций и строит граф вызовов. Анализируя граф вызовов, компилятор «протягивает» по нему различные свойства функций, анализирует свойства различных объектов и т.п. После этого производятся межпроцедурные оптимизации, которые изменяют граф вызовов или свойства объектов. (Я надеюсь, что спустя какое-то время соберусь и расскажу о самых интересных на мой взгляд оптимизациях подробнее.) Многие оптимизации применимы только в случае, если компилятору удается доказать, что выполняется генерация исполняемого файла, и граф вызовов содержит все функции программы. Такие оптимизации называются оптимизациями всей программы (whole program optimization). Примерами таких оптимизаций является удаление из графа вызовов отдельных функций или частей графа вызовов, в которые нельзя попасть из main (dead code elimination). Другим известным примером является изменение структур данных. Большинство межпроцедурных оптимизаций могут выполняться как для полного, так и неполного графа вызовов. Самой известной межпроцедурной оптимизацией является подстановка тела функции (inlining), подставляющей тело функции вместо ее вызова.
После того, как все межпроцедурные оптимизации выполнены, все функции, входящие в итоговый граф вызовов поочередно обрабатываются оптимизирующей частью компилятора (backend). Различие с однопроходной компиляцией состоит в том, что о каждой вызываемой функции может быть известна какая-то дополнительная информация, например, изменяет ли функция тот или иной объект. Эта дополнительная информация и позволяет проводить оптимизации более эффективно.
На самом деле из моего описания видно, что термин двухпроходная оптимизация — это достаточно условный термин и на самом деле проходов по телу функции может быть больше.
Итак, если использовать компилятор для создания объектного файла, например с опцией –с, то в зависимости от наличия или отсутствия опции –Qipo будут создаваться разные сущности. С -Qipo объектный файл — это упакованное внутреннее представление, а не обычный объектный файл. Такие файлы не поймут линковщик link и утилита для созания библиотек lib. Для работы с такими объектными файлами нужно использовать их расширенные Intel аналоги xilink и xilib. Библиотека, созданная из объектных файлов с внутренним представлением будет содержать секции с внутренним представлением и это значит, что те утилиты, которые она содержит, смогут принять участие в межпрпоцедурном анализе в тот момент, когда такая библиотека будет прилинковываться к приложению.(Естественно только с использованием интеловского компилятора и опции -Qipo.) Отсюда следует, что для того, чтобы получить максимальную выгоду от использования компилятора Intel и межпроцедурного анализа, необходимо использовать библиотеки, созданные с помощью компилятора Intel с использованием –Qipo. Чтобы межпроцедурный анализ мог работать с системными функциями, в компиляторе есть информация об этих функциях.
Кстати говоря, если по какой-то причине вы смешаете мух и котлеты, т.е. обычные объектные файлы и файлы собранные с –Qipo и вызовете для их обработки интеловский компилятор (icl), то ничего страшного не произойдет. Компилятор заметит, что вы передаете ему внутреннее представление и включит межпроцедурный анализ/оптимизации автоматом. IPA и IPO будут выполняться для неполного графа вызовов (т.е. графа вызовов, в котором есть неизвестные функции), в который войдут все функции, для которых есть внутреннее представление. Компилятор создаст объектные файлы и затем вызовет линковщик, чтобы прилинковать к ним обычные объектные файлы. Но в общем случае, попавший в сборку программы с –Qipo «обычный» объектный файл может отключить целый пласт оптимизаций, оптимизации целой программы (whole program optimizations).
Граф вызовов
Понятно, что межпроцедурные оптимизации не даются даром. Работа с графом вызовов может быть достаточно сложной и ресурсоемкой и многое определяется размерами графа. Ради интереса я посмотрел на известный тест на производительность из сьюта для измерения производительности CPU2006 447.dealII (это c++ приложение) и вывел информацию о количестве вершин графа вызовов перед началом межпроцедурного анализа. Получилось, что перед межпроцедурным анализом существовало примерно 320 000 различных функций и примерно 380 000 различных дуг, их связывающих. Большие проекты могут испытывать проблемы с использованием двухпроходной компиляции и межпроцедурным анализом.
В компиляторе Intel реализованы две различные модели межпроцедурного анализа, а именно однофайловая и многофайловая модель. Однофайловая включается по умолчанию, если не задан режим многофайловой межпроцедурной оптимизации. В описании опций это выглядит как-то так:
/Qip[-] enable(DEFAULT)/disable single-file IP optimization within files
/Qipo[n] enable multi-file IP optimization between files
Ну и плюс еще есть две дополнительные опции, о которых я упомяну чуть позже.
/Qipo-c generate a multi-file object file (ipo_out.obj)
/Qipo-S generate a multi-file assembly file (ipo_out.asm)
Тут я позволю себе привести схему некоего абстрактного графа вызовов, характерного для C-шного проекта, чтобы
Формально можно сказать, что c –Qipo требуется больше ресурсов, а –Qip требует меньше ресурсов, но и обеспечивает худшее качество оптимизаций.
В реальности не все так однозначно, по крайней мере с ресурсами. Конечно, на самом деле графы вызовов для одного файла не являются подграфами графа вызовов для всего проекта. Например, графы для разных файлов могут содержать одни и те же функции, пришедшие из файлов описаний и являющиеся локальными для каждого файла. Особенно это актуально для больших C++ проектов. Такие функции могут быть продублированы в графах вызовов для некоторых файлов. На мой взгляд, условно можно считать, что эти функции являются неким аналогом weak функций. Поэтому, если просуммировать количество вершин для каждого отдельного графа при однофайловой модели оптимизации, то число вершин может получиться гораздо больше, чем число вершин в полном графе вызовов. При этом при однофайловой модели оптимизации все эти weak функции попадают в обработку и компилятор «возится» с каждой из них для того, чтобы затем линковщик оставил в исполняемом файле или библиотеке одну версию этой функции. Также количество работы при многофайловой обработке может быть уменьшено за счет удаления недостижимых из main подграфов и функций. Если функция была подставлена во все свои вызовы (и выполнены еще некоторые условия), то функция не будет обрабатываться оптимизирующей частью компилятора, т.е. итоговый исполняемый файл не будет содержать тела этой функции. Для однофайловой модели это верно только если функция имеет аттрибут static. Т.е при однофайловом IPA в обработку попадет какое-то количество «мертвых» функций.
Вообщем, может случиться, что в сумме компилятор выполнит гораздо больше работы с –Qip чем c –Qipo. При компиляции программы вместо одного большого графа вызовов придется обрабатывать много графов поменьше. В результате каждая однофайловая компиляция потребует гораздо меньше ресурсов, чем работа с полным графом вызовов, но количество истраченных ресурсов в сумме на компиляцию всех файлов может быть гораздо больше, чем при работе с полным графом вызовов.
Проиллюстрирую это уже упомянутым бенчмарком 447.dealII из CPU2006. Я уже написал, что в полном графе вызовов этого приложения приблизительно 320 000 вершин. В компиляции участвуют почти 120 файлов. Суммарное количество всех вершин в графах вызовов всех обрабатываемых файлов ~1500000 вершин (хотя в каждом файле вершин меньше 50000). Т.е. в 5 раз больше, чем количество всех вершин в полном графе вызовов. Я выключил все варианты параллельной компиляции и получил, что программа с –Qipo компилируется на моем Nehalemе приблизительно 160s, в то время как с –Qip время компиляции ~495s, т.е. в 3 раз больше. Если посчитать количество функций, которые обрабатываются в backendе с –Qipo, то получится ~19500 функций. Суммарное количество обработанных функций при компиляции проекта с –Qip равно ~55000. Ну и если посмотреть на размер выполняемого файла, то для этого приложения файл собранный с –Qipo почти на треть меньше файла собранного с –Qip.
Главным достоинством однофайловой оптимизации является то, что в этом случае при правке одного файла не нужно делать полного перестроения всего приложения, а перекомпилировать всего один файл и слинковать его с другими объектными файлами. Кроме того работу с –Qip легко распараллеливать, а вот создание приложения с –Qipo хуже поддается параллелизации. Хотя опция –Qipo может содержать числовой аргумент (например -Qipo2 подразумевает работу в двух потоках), но IPA выполняется на полном графе вызовов и пока еще не придуман хороший метод распараллеливания этого анализа, поэтому эта часть работы делается в один поток (или повторяется в каждом потоке) и кроме того каждый поток получает в нагрузку массу данных собранных IPA. Обработка всех функций в backendе может быть эффективно распределена между потоками, но из-за вышеперечисленных трудностей такая автоматическая параллелизация менее эффективна, чем в случае использования однофайловой модели.
Кстати говоря, хочется здесь упомянуть еще одну полезную опцию.
Если вы вдруг решили пойти простейшим путем и компилировать ваш проект с помощью одного вызова интеловского компилятора, передавая компилятору сразу все опции и список всех исходников, то по умолчанию компиляция будет осуществляться в один поток и нужно примнять специальную опцию для ускорения компиляции. Эта опция воздействует только на компиляцию без многофайлового IPA.
/MP[<n>] create multiple processes that can be used to compile large numbers of source files at the same time
Если упомянутый 447.deallI компилировать с различными значениями в –Qipo, то время компиляции будет меняться так: -Qipo1: 160s, -Qipo2: 136s, -Qipo4: 150s. Т.е. очень скоро потоки начинают мешать друг другу.
Если в том же вызове icl заменить –Qipo на –Qip (или убрать вообще, -Qip будет работать по умолчанию) и добавить опцию /MP, то получится следующее: /MP1: 495s; /MP2: 259s; /MP4: 145s; /MP8: 117s; /MP16: 84s
Если говорить о производительности, то многофайловый IPA намного эффективнее. (Хотя всегда существует некоторая вероятность «горя от ума»). Легко придумать простой пример, который бы продемонстрировал преимущества многофайловой модели в плане возможности использовать различные оптимизации благодаря дополнительной информации от IPA.
test_main1.c:
#include <stdio.h>
#include <stdlib.h>
#define N 10000
extern float calculate(float *a, float *b);
int main() {
float *a,*b,res;
int i;
a = (float*)malloc(N*sizeof(float));
b = (float*)malloc(N*sizeof(float));
for(i=0;i<N;i++) {
a[i] = i;
b[i] = 1 - i;
}
res = calculate(a,b);
printf("res = %f", res);
}
test1.c:
#include <stdio.h>
#define N 10000
extern float calc(float a, float b);
float calculate(float * restrict a,float * restrict b) {
int i;
float res;
for(i=0;i<N;i++) {
res = calc(a[i],b[i]);
}
return res;
}
test2.c:
float calc(float a,float b) {
return(a+b);
}
icl -Feaaa.exe -Qparallel -Qpar_report3 test_main.c test1.c test2.c -Qstd=c99
icl -Feaaa.exe -Qipo -Qparallel -Qpar_report3 test_main.c test1.c test2.c -Qstd=c99
Здесь используется опция –Qparallel, которая включает автопараллелизатор интеловского компилятора и –Qpar_report3 — опция, выдающая информацию о том, какие циклы были обработаны или отвергнуты автопараллелизатором и почему.
Вывод без –Qipo сообщает следующее:
...
test_main.c
procedure: main
..\test_main.c(14): (col. 1) remark: LOOP WAS AUTO-PARALLELIZED
test1.c
procedure: calculate
..\test1.c(11): (col. 1) remark: loop was not parallelized: existence of parallel dependence
test2.c
procedure: calc
Вывод с –Qipo:
test_main.c
test1.c
test2.c
procedure: main
C:\iusers\aanufrie\for_habrahabr\7a\test_main.c(13): (col. 1) remark: LOOP WAS AUTO-PARALLELIZED
C:\iusers\aanufrie\for_habrahabr\7a\test_main.c(17): (col. 8) remark: LOOP WAS AUTO-PARALLELIZED
Из вывода с –Qipo видно, что межпроцедурный анализ помог осуществить автопараллелизацию цикла.
Понятно, что в случае с –Qipo помогает еще и инлайнинг, но даже если инлайнинг запретить, то благодаря анализу функции calc у компилятора появляется возможность доказать правомерность автопараллелизации.
А что делать, если по какой-то причине многофайловая модель неприменима, например, для построения программы требуется много времени и это вас не устраивает? Можно повышать полезность работы однофайловой модели за счет размещения в файле совместно используемых функций. Очень полезен для функций атрибут static. Если функция имеет этот атрибут, значит IPA при однофайловой работе видит все вызовы этой функции и если у этих вызовов есть какие-то особенности, то они могут быть протянуты внутрь функции. Если все вызовы статической функции были подставлены, то само тело функции можно удалить. То же самое касается и статических объектов. Межпроцедурный анализ считает, что видит все примеры их использования и может выполнять с ними различные оптимизации. В общем, всякие ограничения области видимости объектов одним файлом могут помочь сделать более качественный однофайловый межпроцедурный анализ.
А что, если в рамках однофайловой нельзя решить какие-то проблемы, поскольку важная функциональность разнесена между несколькими файлами?
Опция –Qipo-c предоставляет возможность организовать некую промежуточную модель работы, т.е. строить граф вызовов не на основе функций из одного или всех файлов, а поделить все файлы на группы. Это удобно если ваш проект разбит на несколько тесно взаимосвязанных кусков. (Например, таким проектом является наш компилятор, в котором есть несколько компонент использующих общие утилиты и расположенные в отдельных директориях). –Qipo-c создает объектный файл с фиксированн��м именем ipo_out.obj и в этот файл попадают все функции из перечисленных в вызове компилятора файлов. В приведенном выше примере приложение можно было бы скомпилировать следующим образом:
icl -Qipo-c -Qparallel -Qpar_report3 -Qstd=c99 test1.c test2.c
icl test_main.c ipo_out.obj
Вывод при компиляции двух первых файлов показывает, что в данном случае будет и работать и автопараллелизация и инлайнинг, поскольку критически важные функции были объединены в одном графе вызовов, что и дало возможность сделать межпроцедурный анализ и оптимизации.
Вот такой вопрос, а использовал ли кто-либо из читателей такую схему компиляции или хотя бы слышал о ней? Есть такое мнение, что проблема производительности интересует только процентов 5% разработчиков. Зачастую желание предоставить пользователю какие-то дополнительные рычаги для управления работой компилятора упирается в простой вопрос: «А кому вообще это надо и кто это будет использовать?»
Кстати говоря, можно добавлять и удалять какие-то файлы из обработки межпроцедурным анализом используя метод «мух и котлет»: создавая объектные файлы с –Qipo и без. В этом случае межпроцедурный анализ будет проводится на неполном дереве, полученных из функций, которые описаны в файлах скомпилированных с –Qipo. В описанном мной примере это тоже работает.
Ну и наконец опция –Qipo-S полезна для тех, что хочет модернизировать или поизучать ассемблер после межпроцедурных оптимизаций.
На этом я закончу рассказ о графах вызовов как основе IPO и IPA. Надеюсь продолжить рассказ об межпроцедурных оптимизациях и постараюсь ответить на все вопросы.

