
Вступление
Приветствую тебя, %username%! Меня зовут Владимир Жуков, и я не хочу впаривать тебе очередную историю успешного успеха про Kubernetes. Я хочу рассказать о наших кластерах Kubernetes с необычной архитектурой. «Что же там необычного?» спросишь ты. Самая сложная и непонятная часть кластера - это сеть. Я знаю, что идея плоской сети не новая и применяется много у кого, но, кажется, об этом еще никто тут не писал.
Как выглядел Dev контур
Как можно жить с микросервисной архитектурой, но при этом не использовать контейнеры?! В недрах Иви была разработана собственная система оркестрации виртуальных машин под названием Notkube. Такое название система получила после тщетных попыток поднять маленькую копию Иви в Kubernetes. Это был 2015 год, Kubernetes-у было всего год от роду. Система выглядела так: Openstack для виртуализации + самописный скрипт, который на вход принимал аргументы и через API Openstack поднимал набор виртуальных машин. Но скрипт не жил сам по себе. К нему еще шёл в комплекте Jenkins, который давал Web-интерфейс с множеством форм для ввода параметров, для того чтобы копии Иви могли быть разной конфигурации под соответствующие задачи. Виртуальные машины далее настраивались при помощи SaltStack. Его задача была настроить операционную систему, притащить код приложения (через git pull, конечно же) и собрать виртуальное окружение.
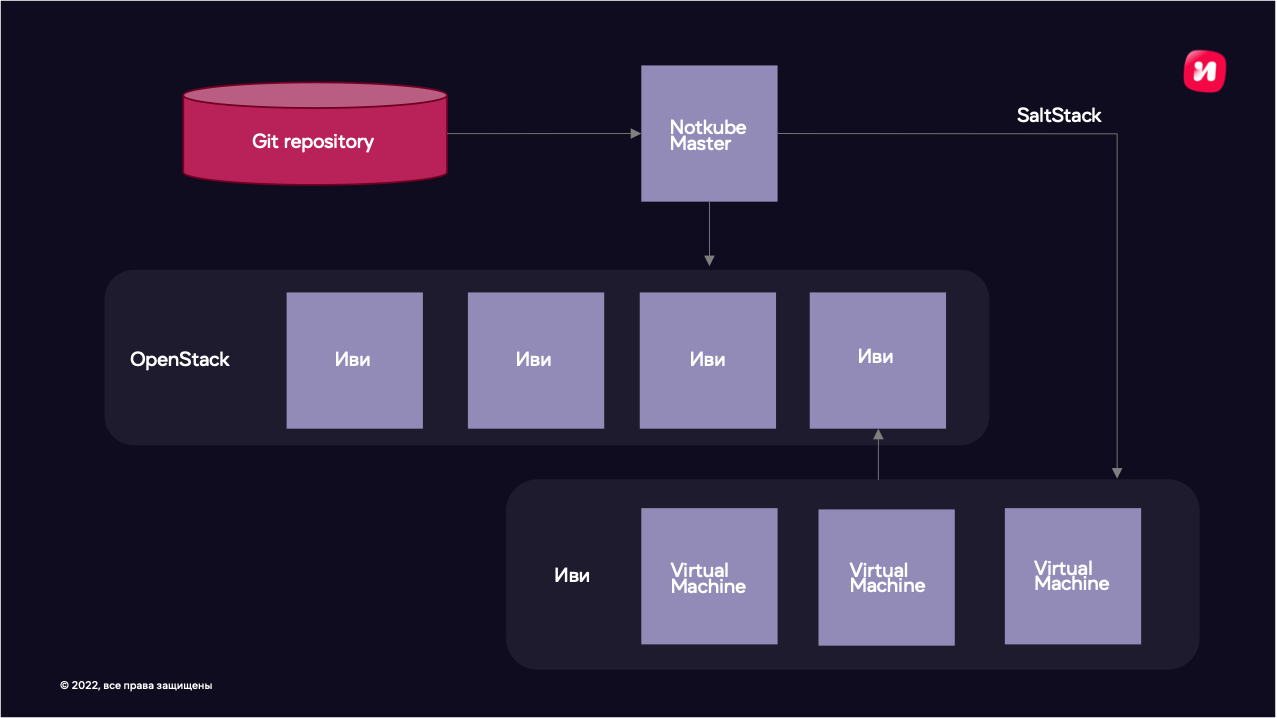
Как оказалось, Dev среда самая сложная и капризная. Во-первых, надо просчитать вместимость этого окружения. Что такое вместимость? Под этим понятием я подразумеваю как размер сети, так и количество CPU, Mem, и, конечно же, дисковое пространство.
Например, у нас 100 микросервисов и 200 разработчиков (берем с хорошим запасом). И каждому разработчику необходимо разворачивать маленькую копию Иви. На такой кластер надо заложить сеть с маской не меньше 255.255.128.0. А это:
32 768 адресов (1 IP адрес на одну VM),
2000 ядер CPU (10 на одну копию Иви),
MEM 4Tb (20 Gi на одну копию Иви),
Disk 20 Tb (100 Gi на одну копию Иви).
Получается очень немало только по ресурсам. А это еще надо развернуть, настроить, замониторить, ну и не обойдется без индивидуальных доработок для некоторых микросервисов.
Как выглядел Prod контур
Давайте расскажу, как было до прихода контейнеров и оркестраторов. Сервисов было немного, и такой подход казался нам хорошим. Мы готовили виртуальную машину, наливали на нее OS и приносили нужное окружение вместе с настройками под конкретное приложение при помощи puppet. Потом готовилось СI/CD. Её задача была скопировать код приложения, собрать venv или выполнить другой vendoring для проекта и запаковать все, что получилось, в архив. Релиз осуществлялся путем доставки собранных ранее артефактов на заранее подготовленную машину при помощи rsync.
Какие тут минусы? Для каждого приложения надо готовить:
Role SaltStack (делается силами админа);
Доработка Notkube («старая система с виртуалками», делается силами админа);
Role puppet (делается силами админа);
Pipeline CI/CD (делается силами админа);
Конфиг на nginx, чтобы пустить трафик (делается силами админа).
Чем не устраивал текущий подход?
Мы получаем большой объем работ даже для маленького микросервиса, который лежит на плечах системного администратора/DevOps. На практике такие доработки могли готовиться от двух недель до месяца, что, конечно же, никого не устраивало. Выходов из этой ситуации не так много - можно нанять еще 100500 админов или часть работ отдать в команды разработки. Но нельзя же заставить разработчиков писать профили puppet? Тут нам на помощь приходит Docker+Kubernetes. Эта связка позволяет описывать окружение для приложения при помощи простых манифестов, которые можно хранить в репозитории рядом с кодом.
Вот что получается с новым подходом:
Role SaltStack (становится не нужен, заменяется манифестом Kubernetes, Dockerfile);
Доработка Notkube («старая система с виртуалками», становится не нужна, заменяется манифестом Kubernetes, Dockerfile);
Role puppet (становится не нужен, заменяется манифестом Kubernetes);
Pipeline CI/CD (переезжает в Gitlab-ci и сводится к подключению типовых shared pipelines);
Конфиг на nginx, чтобы пустить трафик (остается за админами).
Получается, что огромную часть работ можно отдать команде разработки (ранее этим занималась команда системных администраторов), за админами остается только поддержка и расширение кластера. Значит, решено - будем делать Kubernetes!
Приступаем к планированию кластера для dev окружения - посчитали наши микросервисы и количество контуров (копий Иви). Получилось, что маска сетки 255.255.0.0 - это 65 536 адресов для сервисных адресов. Должно хватить. Дальше начали подбирать компоненты кластера - сетевой плагин взяли kube-router + IPVS (IPVS дает расширенные возможности по балансировке). С ним выяснилась одна интересная особенность, но о ней позже. Также от команды разработки было особое требование к сети - они хотели иметь возможность подключать код, который разрабатывают на локальной машине к сервисам кластера. Так родилась идея "плоской сети", которую мы реализовали при помощи BGP. Тут суть в следующем: мы устанавливаем BGP-сессии с ядром нашей сети и получаем маршрутизацию из сети Иви прямо в Kubernetes. Причем не важно - это сервисный адрес или адрес pod. В качестве DNS мы взяли привычный всем CoreDNS. Kube-proxy оказался не нужен - его работу выполняет kube-router. Все остальные компоненты остаются как из коробки.
Про «плоскую сеть» и IPVS
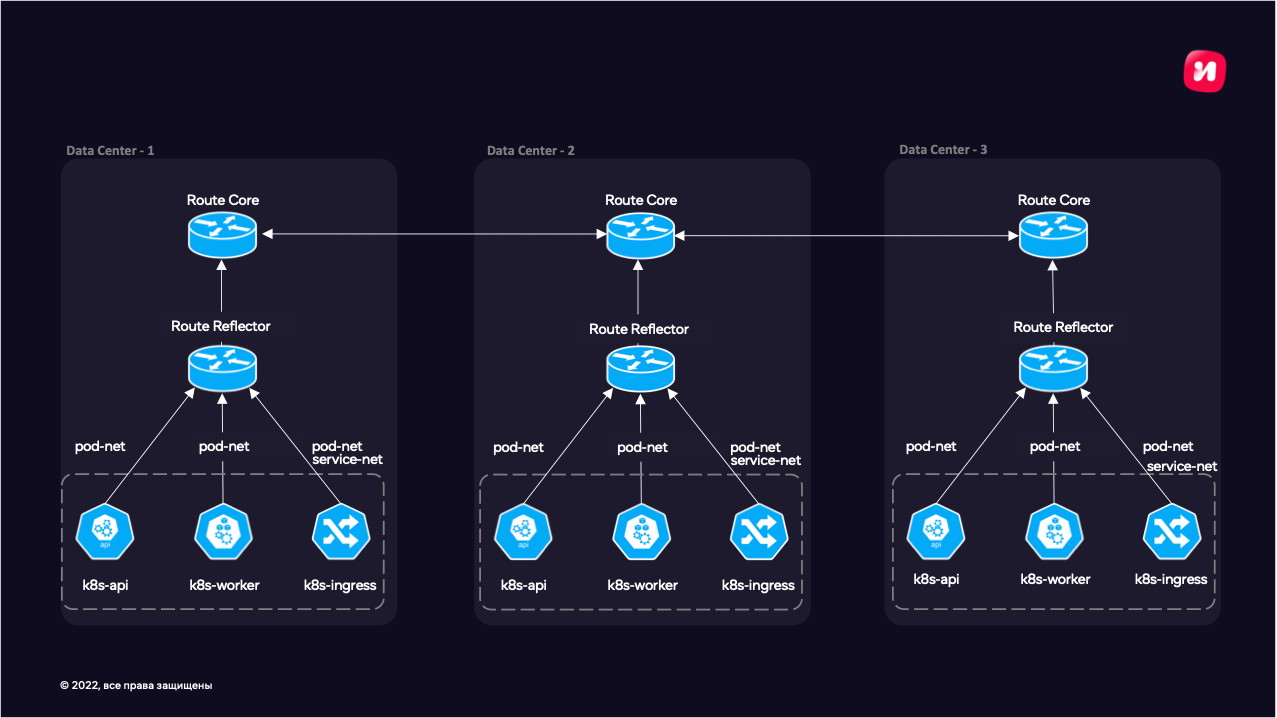
Довольно быстро столкнулись с проблемой. Оказалось, для каждого нового узла кластера надо было настраивать ядро сети. Количество таких узлов росло, не получалось оперативно добавлять мощности в кластер. Эту проблему решили при помощи route reflector. Для route reflector не требуется много ресурсов и сложное ПО, ведь сам трафик через него не идет. Достаточно одного bird, пары ядер CPU и пары гигабайт памяти. При помощи bird удалось настроить автоматическую установку BGB-сессий с новыми k8s машинами, прописав там сети, которым мы доверяем. Получается, что всю агрегацию маршрутов и BGP-сессий берет на себя route reflector и одной сессией отдает все маршруты ядру сети.
Плюсы «плоской сетки» заключаются в следующем: правила iptables в разы проще, а значит поиск аномалий и неисправностей тоже проще. Был показательный случай с postgres -разработчики заметили, что есть проблема при работе через psql-консоль. Суть проблемы в том, что консоль просто зависала и не реагировала на команды при определенных обстоятельствах.
Если сделать SELECT pg_sleep(900);, то консоль гарантированно зависает.
Если SELECT pg_sleep(800);, то не зависает.
Разобрались очень просто - запустили tcpdump на узле с Pod и увидели, что во время pg_sleep() от базы к клиенту не летают никакие пакеты, а по прошествию 900 секунд соединение между клиентом и сервером просто рвется. Оказалось, что у IPVS есть собственный tcp keepalive, который совершенно не зависит от настроек sysctl в системе, а задается так: ipvsadm --set 300 60 60. И, конечно же, это можно настроить через kubernetes аннотации сервиса. С этим удалось разобраться благодаря относительно несложному устройству сети. Доступность Pod напрямую без сервисов также является плюсом. Это позволило нам использовать Prometheus, который работает вне кластера. Так же стало возможным делегировать DNS-зону в CoreDNS и получить DNS Discovery по имени Service в кластере. Наши серверы стали доступны из сетей Иви по удобным адресам типа appname.namespace.svc.dev.cluster.local. И так с любым сервисом в кластере.
Как мы меняли Notkube («старая система с виртуалками») на Kubernetes
Когда мы определились с размером и конфигурацией будущего кластера, пришло время планировать, как туда переезжать. Тут было несколько проблем:
Во-первых, большинство сервисов даже не в docker.
Во-вторых, этих сервисов очень много.
И, в-третьих, вокруг существующего кластера сформировалось workflow, люди привыкли к его особенностям.
Получается, что нам надо перевести 100 микросервисов в docker и примерно 200 человек научить пользоваться новым кластером, ведь там больше нет привычного всем ssh. Вместо него есть kubectl logs, exec... И эта проблема даже посерьезней, чем запихнуть все в docker. Посовещавшись, выбрали стратегию, следуя которой надо построить новый кластер рядом с возможностью плавного переезда сервисов туда. Начали мы с Docker. Долго и нудно запихивали наши приложения в контейнеры, попутно совершенствуя практики CI. Когда основные сервисы оказались в контейнерах, мы решили запустить их в Kubernetes и погонять на них автотесты. И тут мы столкнулись с тем, что наши приложения надо запускать в разных namespace, с разными конфигами и количеством ресурсов. Тут нам помог Helm. С его помощью удалось относительно легко во время деплоя менять namespace и любые конфиги.
Следующим этапом стал выбор инструмента для управления контуром (маленькие копии Иви). Требования такие: для конечного пользователя должен быть интерфейс, в котором он сможет выбрать конфигурацию контура (не всем для работы требуется полная копия Иви) и быстро развернуть его. Тут нам на помощь пришёл старый добрый jenkins. К нему уже все привыкли. Также мы уже точно знали, как его готовить точно не надо. Была уверенность в том, что если следовать лучшим практикам, то jenkins не превратится в монстра из bash-скриптов. Собранный прототип из Kubernetes+Jenkins+helm и десятка микросервисов показал работоспособность идеи. Далее мы составили список оставшихся микросервисов, наделали задач вида «запихнуть в контейнер», «сделать helm chart», сдобрили это «How to» документацией, примерами и раскидали задачи по командам. Стали ждать, пока задачи вернутся на ревью. На удивление, команды хорошо справлялись с докерезацией и кубернетизацией. Примерно через полгода все наши сервисы оказались в dev контуре kubernetes, а наш jenkins все еще не превратился в легаси.
А что там с Production?
Мы решили не менять подход построения архитектуры и сделать как в Dev контуре, только с одним отличием - нужно по одному независимому кластеру на каждый Data Centre. У этого подхода есть плюсы и минусы. Разберем их по очереди.
Плюс у нас один, но очень жирный - у нас будет независимая копия Иви в каждом Data Centre, можно будет обновлять Kubernetes.
Минусы: просто так использовать CronJob уже не получится. Перед кластерами нужно ставить L7 балансировщик. В случае обновления кластера работы больше - кластера надо обновлять по очереди, накладные расходы на поднятия компонентов Kubernetes control plane больше.
Но выбор был сделан в пользу надежности, и мы решили поднимать по отдельному кластеру в каждом Data Centre c такой же «плоской сеткой» как на dev.
Параллелизация тестов
Суть проблемы, с которой мы столкнулись, была в том, что для некоторых сервисов достаточно много автотестов. Их полный прогон занимал несколько часов (до 7,5 часов без учета построения отчета). Постепенно мы пробовали разные способы параллелизации. Все эти попытки сводились к тому, что использовать фиксированную тестовую среду, в которую нацелены тесты, неэффективно.
Kubernetes дал дополнительную возможность распараллелить тесты! На помощь нам приходит Hierarchical Namespaces - фича Kubernetes, которая позволяет создавать вложенные Namespaces. Они наследуют некоторые параметры от родителя, например, Role, RoleBinding. Использование требует установки дополнительного контроллера https://github.com/kubernetes-sigs/hierarchical-namespaces.
Такие Namespaces можно создавать динамически (из кода тестов) и запускать в них независимые копии приложений, для того чтобы в дальнейшем запустить тесты параллельно в несколько потоков. Таким образом, мы делаем для каждого потока свое независимое пространство, где тесты не будут конкурировать между собой, например, в настройках приложения.
Плюсы такого подхода очевидны. Мы используем все преимущества однопоточной работы с приложением (внутри одного потока), имея независимый Namespace для каждого потока. После прохождения тестов все созданное (Namespace и поднятые сущности в нем) удаляется. Таким образом, мы не держим ресурсы под тесты, когда они не задействованы. Большим бонусом является и то, что можно запускать множество сборок автотестов на разных окружениях. Эти сборки не мешают друг другу, так как идут в независимых пространствах.
Что в итоге
Удалось без отрыва от бизнес-процессов заменить одну очень важную часть инфраструктуры на другую, которая соответствует современным промышленным стандартам - ее можно безболезненно обновлять, расширять. Ушло у нас на это около двух лет. Люди с радостью берутся за новую модную игрушку, ведь по ней полно документации и примеров. Благодаря тому, что копию Иви можно поднять в разы быстрей, стало возможно поднимать их много и распаралеливать тесты. Тестировщики вне себя от счастья!
