Это перевод обзора статьи «Gorilla: A fast, scalable, in-memory time series database» Pelkonen et al. VLDB 2015
Чуваки из фейсбука сделали высокопроизводительный движок для мониторинговых данных. Мне понравился обзор этой статьи в блоге "The morning paper" — особенно про алгоритмы сжатия, и вот перевод.
Стиль — авторский.
Количество ошибок на одном из серверов Facebook зашкаливало. Проблему обнаружили через несколько минут после ее появления, когда сработало автоматическое оповещение в Gorilla — in-memory базе данных для временных рядов. Одна группа инженеров занялась решением инцидента, а другая намеревалась найти ее непосредственную причину. Они запустили движок поиска корреляций во временных рядах, написанный поверх Gorilla, и начали искать коррелирующие с ошибками метрики. Оказалось, что копирование релизного бинарника на веб-серверы Facebook (довольно рутинная операция) вызвало неестественное уменьшение использования памяти на сайте …
Рисунок 1. При поиске основной причины повышения частоты ошибок на сайте, механизм поиска корреляций временных рядов в Gorilla обнаружил аномальные события, которые по времени соответствовали появлению ошибок, а именно резкое уменьшение памяти, используемой при копировании релизного бинарника.
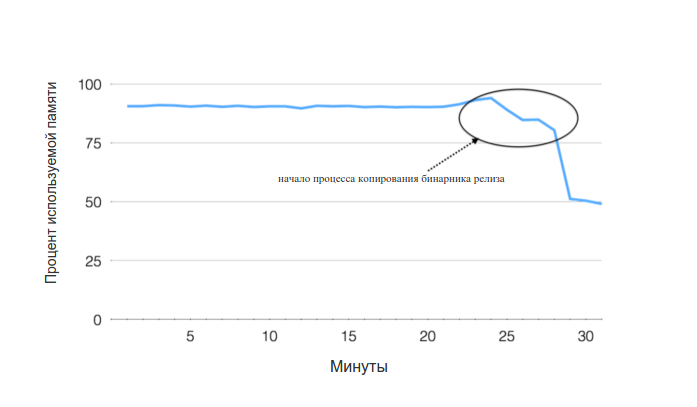
За 18 месяцев до публикации статьи, Gorilla помогла инженерам Facebook выявить и отладить несколько похожих проблем на продакшне.
«Важным требованием для эксплуатации таких высоконагруженных сервисов является точный мониторинг работоспособности и производительности базовой системы, а также быстрое выявление и диагностика проблем по мере их возникновения. Facebook использует базу данных временных рядов для хранения дата-поинтов измерений системы и предоставляет функциональность быстрых запросов к ним.»
С весны 2015 года системы мониторинга Facebook сгенерировали более 2 миллиардов уникальных измерений временных рядов (12 миллионов измерений в секунду, более 1 триллиона в день). С весны 2015 года системы мониторинга Facebook сгенерировали более 2 миллиардов уникальных метрик (12 миллионов измерений в секунду, т. е. более 1 триллиона в день). От Gorilla требовались такие характеристики:
- Хранение 2 миллиардов уникальных временных рядов, доступных по строковому ключу.
- Скорость вставки — 700 миллионов дата-поинтов (отметка времени и значение с плавающей точкой) в минуту.
- Данные за последние 26 часов, которые необходимо хранить в оперативной памяти и быстро выдавать по запросам.
- До 40 000 запросов в секунду на пике.
- Успешное чтение менее чем за одну миллисекунду.
- Поддержка временных рядов с детализацией до 15 секунд (4 дата-поинта в минуту).
- Две копии памяти (не совмещенные) для аварийного восстановления
- Продолжение выполнения чтение в случае, если сервер упал.
- Поддержка быстрого сканирования всех данных в памяти.
- Управление продолжительным ростом (до 2-х раз в год) данных временных рядов!
Для удовлетворения этих требований к производительности, Gorilla построена как TSDB полностью в оперативной памяти и работающая в качестве сквозного кэша при записи данных мониторинга в HBase. Чтобы храненить 26 часов данных в памяти, Gorilla использует новый алгоритм сжатия временных рядов, который дает компрессию в 12 раз. Структуры данных в памяти позволяют быстро и эффективно сканировать все данные при сохранении возможности получения данных отдельных временных рядов за константное время.
«Строковый ключ используется для идентификации уникальных временных рядов. Каждый набор временных данных привязан к отдельному хосту в Gorilla, путем шардирования всех данных мониторинга на основе этих уникальных строковых ключей. Таким образом, мы можем масштабировать Gorilla, просто добавляя новые хосты и настраивая шардирование, так, что новые данные попадают на расширенный набор хостов. Когда Gorilla была запущена в продакшн 18 месяцев назад, все наши данные мониторинга за последние 26 часов помещались в 1,3 ТБ ОЗУ и равномерно распределялилсь на 20 машинах. С тех пор, из-за роста данных, нам дважды пришлось увеличить размер кластеров в два раза, и теперь они запущены на 80 машинах в каждом кластере Gorilla. Этот процесс был несложным благодаря архитектуре независимых узлов и фокусе на горизонтальную масштабируемость.»
In-memory структура данных основана на структуре unordered map из стандартной библиотеки C++. Она доказала свою эффективность и это дало отсутствие проблем с блокировками. Gorilla сохраняет данные в GlusterFS, POSIX-совместимую распределенную файловую систему с тройной репликацией. «HDFS или другие распределенные файловые системы тоже подошли бы».
Подробнее о структурах данных и способах обработки ошибок в Gorilla, смотрите разделы 4.3 и 4.4 оригинальной статьи [pdf].
Здесь же я хочу сосредоточиться на тех приемах, которые используются в Gorilla для сжатия временных рядов, чтобы вместить все эти данные в память!
Сжатие временных рядов в Gorilla
«Gorilla сжимает дата-поинты внутри одного временного ряда без дополнительной компрессии между разными временными рядами. Каждый дата-поинт — это пара 64-битных величин, представляющих отметку времени, таймстамп, и соответствующее ей значение метрики. Таймстампы и значения сжимаются отдельно, используя информацию о предыдущих значениях.»
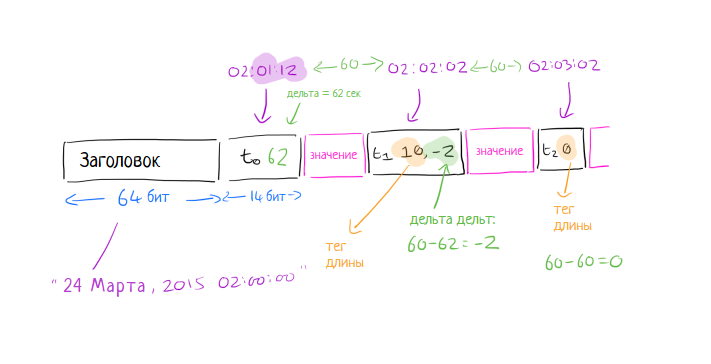
Что касается таймстампов, ключевое наблюдение состоит в том, что большинство источников записывают в логи дата-поинты, через фиксированные интервалы (например, одна отметка каждые 60 секунд). Время от времени дата-поинт может регистрироваться немного раньше или позже (например, на секунду или две), но этот промежуток обычно ограничен. В нашем случае каждый бит на счету, поэтому, если мы можем представлять последовательные таймстампы, занимая как можно меньше места, то это дает нам выигрыш по памяти… Каждый блок данных хранит 2 часа измерений. Заголовок блока содержит начальную отметку времени двухчасового окна. Первый таймстамп в блоке (после начала двухчасового окна) сохраняется как дельта с момента начала блока, используя 14 бит. 14 бит достаточно для вмещения чуть более 4-х часов, поэтому мы знаем, что нам точно не понадобится больше.

Для всех последующих временных меток мы сравниваем дельты. Предположим, что время начала блока в 02:00:00, а первый таймстамп на 62 секунды позже — 02:01:02. Следующая точка данных находится в 02:02:02, еще через 60 секунд. Если сравнить эти две дельты, то вторая дельта (60 секунд) на 2 секунды короче первой (62 секунды). Так что мы записываем минус 2. Сколько битов мы должны использовать для записи «-2»? Чем меньше, тем лучше! Мы можем использовать битовые теги, чтобы обозначить, сколькими битами закодировано уже само значение. Схема работает следующим образом:
Вычисление дельты дельт: D = (tn — tn-1) — (tn-1 — tn-2)
Расшифровка значения в соответствии с таблицей:
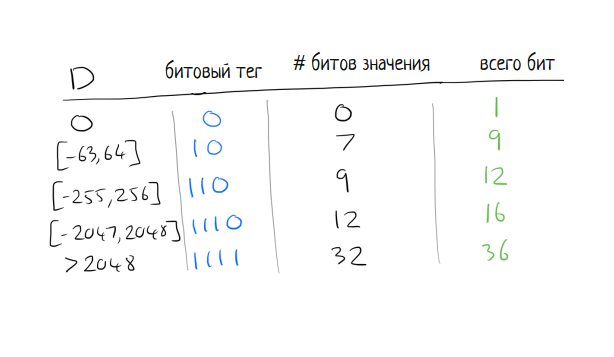
Конкретные значения временных отрезков были выбраны путем отбора наборов рядов в реальном времени из продакшн систем и выбора диапазонов, которые показали наилучшие коэффициенты сжатия.
Таким образом мы получаем следующий поток данных:
«Рисунок 3. показывает результат сжатия временных меток в Gorilla. Мы обнаружили, что 96% всех временных меток могут быть сжаты до 1 бита.»
(т.е. 96% всех временных меток возникают через регулярные интервалы, так, что дельта дельт равна нулю).

Рисунок 3. Распределение сжатых таймстампов по диапазонам. Взято из реальных данных — 440 000 меток из Gorilla.
Так долго обсуждаем таймстампы, а что насчет самих значений метрик?
«Мы обнаружили, что значение в большинстве временных рядов существенно не изменяется по сравнению с соседними точками данных. Кроме того, многие источники данных хранят только целые числа. Это позволило нам затюнить дорогостоящую схему прогнозирования [25] к более простой реализации, которая просто сравнивает текущее значение с предыдущим значением. Если значения близки друг к другу, то знак, экспонента и первые несколько бит мантиссы будут идентичны. Для этого вычисления мы используем XOR текущего и предыдущего значений вместо применения схемы дельта-кодирования.»

Рисунок 4. Наглядное представление того, как XOR с предыдущим значением часто имеет нули в начале и в конце, и для многих рядов ненулевые элементы группируются.
Затем значения кодируются следующим образом:
Первое значение сохраняется без сжатия. Для всех последующих значений применяется XOR с предыдущим значением. Если результат выполнения XOR равен нулю (т.е. то же самое значение), то сохраняется бит со значением «0». Если результат XOR не равен нулю, то, вероятно, будет иметься ряд нулей перед «значимыми битами» и после них. Подсчитаем количество ведущих нулей и число нулей в конце. Например, результат — 0×0003200000000000, тут есть 3 ведущих нуля и 11 нулей в конце, поэтому сохраняется бит со значением ’1′, далее ...
Если предыдущее сохраненное значение имеет такое же или меньшее количество нулей в начале и в конце, мы знаем, что все значимые биты значения, которые мы хотим сохранить, попадают в диапазон значимых битов предыдущего значения:
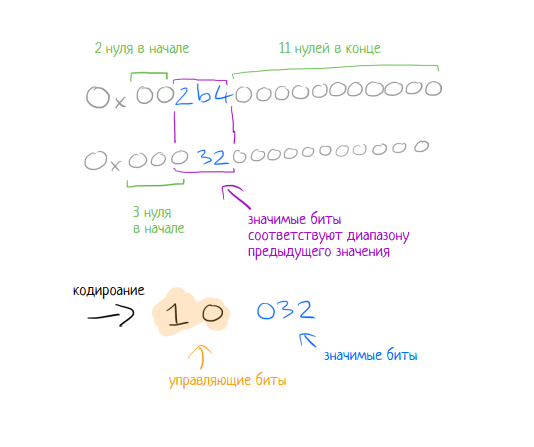
В примере выше сохраняется управляющий бит «0», а затем сохраняется значимое значение операции XOR (то есть 032).
Если значимые биты текущего значения не попадают в диапазон значимых битов предыдущего значения, тогда сохраняется управляющий бит со значением «1», за которым следует 5 бит указывающих число ведущих нулей, 6 бит с длиной значимой части результата XORи, наконец, значащие биты результата XOR.

«Примерно 51% всех значений сжимаются до одного бита, поскольку текущее и предыдущее значения идентичны. Около 30% значений сжимаются с управляющими битами ’10′ со средним размером сжатия 26,6 бит. Остальные 19% сжимаются с управляющими битами '11′ со средним размером 36,9 бита из-за дополнительного оверхеда, необходимого для кодирования длины ведущих нулевых битов и значимых битов.»
Системы, построенные поверх Gorilla
Малые задержки при чтении из Gorilla (быстрее более чем в 70 раз, чем предыдущая система, которую она заменила) позволила команде Facebook создать ряд инструментов поверх нее. К ним относятся «хорайзон» графики (horizon charts); аггрегированные ролапы, которые обновляются для всех завершенных блоков каждые два часа; и движок поиска корреляций, который, как мы видели в первом примере.
«Движок поиска корреляций вычисляет коэффициент корреляции Пирсона (PPMCC), который сравнивает тестовый временной ряд с большим набором временных рядов. Мы находим, что способность корреляции Пирсона находить соответствие между одинаково выглядящими временными рядами независимо от масштабов, помогает значительно автоматизировать анализ причинно-следственных связей и отвечать на вопрос „Что еще происходило, когда мой сервис сломался?“. Для нас этот подход дает удовлетворительные ответы на такой вопрос и его оказалось проще реализовать, чем аналогичные подходы, описанные в литературе [10, 18, 16]. Чтобы вычислить корреляцию Пирсона, тестовые временные ряды распределяются на каждый хост Gorilla вместе со всеми ключами временных рядов. Затем каждый хост независимо вычисляет N наиболее скоррелированных с тестовым временных рядов, упорядочивает их по абсолютной величине корреляции Пирсона и возвращает значения найденых временных рядов. В будущем, мы надеемся, что Gorilla позволит использовать более совершенные data-mining методы для наших мониторинг-данных, такие как описанные в литературе по кластеризации и обнаружению аномалий [10, 11, 16].»
Подводя итоги извлеченных уроков, авторы выделяют еще 3 дальнейших правила:
Берите в приоритет новые, недавние, а не старые данные. То почему что-то не работает сейчас — более насущный вопрос, чем почему оно не работало 2 дня назад. Низкая latency чтения мониторинг-данных очень важна — без этого более совершенные инструменты, построенные поверх Gorilla, были бы не практичны. Высокая доступность важнее эффективности использования ресурсов.
«Мы обнаружили, что построение надежной отказоустойчивой системы является наиболее трудоемкой частью проекта. Хотя команда создала прототип высокопроизводительной, сжатой in-memory базы данных временных рядов (TSDB) за очень короткий промежуток времени, потребовалось еще несколько месяцев напряженной работы, чтобы сделать ее отказоустойчивой. Однако преимущества отказоустойчивости были видны, когда система успешно пережила как реальные, так и имитированные сбои.»
