О чем статья: трассировка и анализ ошибок в микросервисной архитектуре без средств централизации логирования обычно причиняет неудобства, поскольку для понимания "что и на каком микросервисе умерло" приходится обходить микросервисы по очереди, сверять и сопоставлять данные в логах. В данной статье рассматривается централизация логирования с помощью Graylog, с примерами кода на Python.
Для кого: статья будет полезна в качестве пошаговой инструкции для разработчиков, столкнувшихся с трудностями сбора логов от нескольких микросервисов.
Введение
Конечно, проблема, обозначенная выше, может возникать независимо от архитектуры, и используемых паттернов. Одним из ключевых пожеланий к средству сбора и просмотра логов является возможность отследить последовательность обработки запроса на разных микросервисах (или частях монолита).
Для иллюстрирования задачи, представим небольшой инстанс из оркестратора и двух микросервисов.
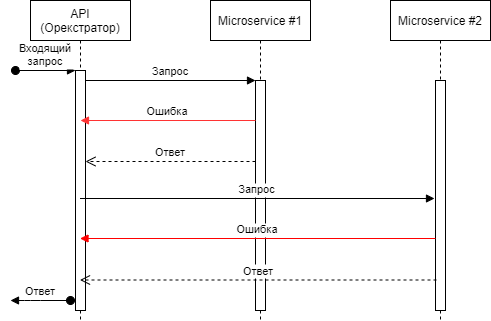
Запрос, приходящий на оркестратор, передается на первый микросервис, который может либо вернуть ошибку, либо результат выполнения. Затем (если обработка прошла успешно) запрос передается на второй микросервис. Он, также как и первый, может обработать запрос успешно, либо упасть в ошибку. В любом случае, запросившему возвращается какой-то результат.
Итак, проблема понятна, теперь расскажу об инструменте, который поможет ее решить.
Немного о Graylog
Graylog — это платформа управления логами, с открытым исходным кодом. Graylog, помимо прочего, использует Elasticsearch для хранения самих логов, и MongoDB для хранения метаданных и конфигурации.
Graylog интересен по двум причинам:
Поддержка различных способов отправки
Graylog поддерживает специальный формат логов - GELF (Graylog extended log format), отлично подходящий для логирования из приложений (с произвольными данными). Логи в GELF-формате могут быть отправлены по TCP, UDP, HTTP и даже AMQP.
Интеграционные возможности
Пакеты для отправки данных в Graylog, существуют, как минимум для Python, PHP, Golang, JavaScript, C#.
По сути, Graylog применим в различных вариациях, особенно интересует расширяемый формат записей, поскольку для связи логов из различных источников нужен некоторый ключ, уникальный для каждого запроса на протяжении всего времени обработки. Теперь займемся установкой и первоначальной настройкой.
Установка и настройка Graylog
Проще и быстрее всего запустить Graylog через docker-compose, благо на github есть соответствующий репозиторий. В репозитории есть три варианта: cluster, enterprise и open-core. Для развертывания выберем последний.
Боромир во Властелине колец говорил: "Нельзя просто так взять и войти в Мордор". Но он не попробовал запустить Graylog из клонированного репозитория, а так добавил бы новую фразу в копилку. В процессе запуска я столкнулся с некоторыми трудностями:
Образ elasticserach качаться с docker.elastic.co не пожелал, ввиду 403-й ошибки
MongoDB версии 5.0.0 для запуска потребовался процессор с поддержкой AVX
Лечение этих болезней (с которыми вы, как мне видится, обязательно столкнетесь) достаточно простое:
Для elasticsearch находим образ, максимально похожий на тот, что указан в оригинальном docker-compose. Мне повезло, и для версии 7.10.2 на hub.docker.com я нашел нужный образ.
MongoDB можно просто понизить версию до 4.4.6
Итоговый docker-compose.yml выглядит следующим образом:
version: "3.8"
services:
mongodb:
image: "mongo:4.4.6"
volumes:
- "mongodb_data:/data/db"
restart: "on-failure"
elasticsearch:
environment:
ES_JAVA_OPTS: "-Xms1g -Xmx1g -Dlog4j2.formatMsgNoLookups=true"
bootstrap.memory_lock: "true"
discovery.type: "single-node"
http.host: "0.0.0.0"
action.auto_create_index: "false"
image: "domonapapp/elasticsearch-oss"
ulimits:
memlock:
hard: -1
soft: -1
volumes:
- "es_data:/usr/share/elasticsearch/data"
restart: "on-failure"
graylog:
image: "${GRAYLOG_IMAGE:-graylog/graylog:4.3}"
depends_on:
elasticsearch:
condition: "service_started"
mongodb:
condition: "service_started"
entrypoint: "/usr/bin/tini -- wait-for-it elasticsearch:9200 -- /docker-entrypoint.sh"
environment:
GRAYLOG_NODE_ID_FILE: "/usr/share/graylog/data/config/node-id"
GRAYLOG_PASSWORD_SECRET: ${GRAYLOG_PASSWORD_SECRET:?Please configure GRAYLOG_PASSWORD_SECRET in the .env file}
GRAYLOG_ROOT_PASSWORD_SHA2: ${GRAYLOG_ROOT_PASSWORD_SHA2:?Please configure GRAYLOG_ROOT_PASSWORD_SHA2 in the .env file}
GRAYLOG_HTTP_BIND_ADDRESS: "0.0.0.0:9000"
GRAYLOG_HTTP_EXTERNAL_URI: "http://localhost:9000/"
GRAYLOG_ELASTICSEARCH_HOSTS: "http://elasticsearch:9200"
GRAYLOG_MONGODB_URI: "mongodb://mongodb:27017/graylog"
ports:
- "5044:5044/tcp" # Beats
- "5140:5140/udp" # Syslog
- "5140:5140/tcp" # Syslog
- "5555:5555/tcp" # RAW TCP
- "5555:5555/udp" # RAW TCP
- "9000:9000/tcp" # Server API
- "12201:12201/tcp" # GELF TCP
- "12201:12201/udp" # GELF UDP
#- "10000:10000/tcp" # Custom TCP port
#- "10000:10000/udp" # Custom UDP port
- "13301:13301/tcp" # Forwarder data
- "13302:13302/tcp" # Forwarder config
volumes:
- "graylog_data:/usr/share/graylog/data/data"
- "graylog_journal:/usr/share/graylog/data/journal"
restart: "on-failure"
volumes:
mongodb_data:
es_data:
graylog_data:
graylog_journal:Перед запуском необходимо создать .env-файл (образец с подробными пояснениями лежит в той же папке), и заполнить два параметра — секрет, и хеш пароля администратора.
После запуска стека с измененным docker-compose.yml можно проверить работоспособность, зайдя на http://localhost:9000/.
Пользователь по-умолчанию: admin
Пароль: тот, что хешировали для .env-файла
Теперь нужно создать Input. Для этого, в заголовке интерфейса переходим в меню System / Inputs — Inputs, выбираем GELF TCP (в этом примере будем использовать именно его), нажимаем “Launch new input”. В окне настроек достаточно указать название (Title), остальные параметры можно не менять. О настройках Graylog можно написать отдельную статью (и, наверное, даже не одну), но сейчас сосредоточимся на реализации отправки логов из сервисов на Python.
Отправка данных в Graylog
Для Python существует несколько пакетов, имплементирующих упаковку записи в GELF, и передачу по выбранному каналу. Однако, среди нескольких, опробованных мной, самым адекватным оказался pygelf. Его-то и будем использовать.
Для начала попробуем отправить простое сообщение:
from pygelf import GelfTcpHandler
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("api")
# Все, что нужно для отправки логов - добавить обработчик в логгер
logger.addHandler(GelfTcpHandler(host='127.0.0.1', port=12201, include_extra_fields=True))
logger.info('hello gelf')После запуска этого кода в интерфейсе Graylog (вкладка Search в верхнем меню) можно увидеть сообщение.

Это уже неплохо, однако, данных в сообщении недостаточно. Добавим сюда параметр request_id — это будет “ключ”, связывающий между собой операции по одному запросу на разных микросервисах. Чтобы добавить новое поле в сообщение, воспользуемся фильтром.
import uuid
from pygelf import GelfTcpHandler
import logging
# Создадим класс с методом filter, который будет подставлять reuqest_id в каждую запись
class ContextFilter(logging.Filter):
def filter(self, record):
record.request_id = str(uuid.uuid4())
return True
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("api")
logger.addHandler(GelfTcpHandler(host='127.0.0.1', port=12201, include_extra_fields=True))
logger.addFilter(ContextFilter())
logger.info('hello gelf')После отправки мы видим, что graylog распознал поле, и вывел его значение.

Для полноты картины можно посмотреть еще и на обработку исключений.
")
Стектрейс пишется в лог, что не может не радовать.
Сам request_id можно хранить в контекстной переменной (контекстные переменные хорошо ложатся на асинхронный код, и в частности для FastAPI), генерируя его на оркестраторе при поступлении запроса от пользователя, на микросервисы же его придется передавать в теле сообщения (если коммуникация осуществляется через RabbitMQ), либо иным способом, но, так или иначе, передавать необходимо, в силу того, что мы сохраняем для каждой записи уникальную метку, связывающую распределенные операции в единый контекст.
Кроме request_id можно добавить в запись имя сервиса, сгенерировавшего запись, так будет удобнее в потоке сообщений понимать кто и что делал.
Теперь, понимая как отправить логи в graylog, для реализации в конкретном случае надо сделать три вещи:
Сгенерировать\получить
request_id, записать в контекстную переменнуюДополнить класс фильтра заполнением требуемых параметров
Добавить логирование во все нужные точки сервисов
Не буду расписывать весь путь от и до, тем более что исходный код примеров выложен на github:
Лучше посмотрим на финальный результат.

Теперь, зная только request_id, возможно получить по нему все записи, восстановив последовательность обработки запроса.
В заключение рекомендую посетить открытый урок «RESTful API паттерны», на котором планируется поговорить о REST, рассмотреть уровни зрелости REST, затронуть HATEOAS, рассмотреть паттерны REST и сгенерить клиент к сервису по openapi idl.
