

Привет, Хабр! На связи снова Антон, DevOps-инженер в отделе Data- и ML-продуктов Selectel. В предыдущей статье я рассказал о шеринге GPU и показал, как запустить несколько инстансов на одной видеокарте с помощью MIG. А в конце затронул тему с автомасштабированием инференс-серверов. Она оказалась актуальной, и я решил написать продолжение.
В этот раз посмотрим, как применять технологии шеринга в Kubernetes, а также разработаем прототип автомасштабируемой инференс-платформы за один вечер. Интересно? Тогда добро пожаловать под кат!
О чем поговорим:
→ Проблема шеринга ресурсов в Kubernetes
→ GPU-оператор
→ Подготовка рабочего окружения
→ Активируем MIG в Kubernetes
→ Автомасштабирование нашей платформы
→ Как обмануть GPU-ресурсы Kubernetes с помощью TimeSlicing
→ Заключение
Дисклеймер: для понимания данной статьи нужны навыки в работе с Helm-чартами и kubectl, а также знание Kubernetes. Если вы хотите погрузиться в эти технологии, изучайте курсы в Академии Selectel.
Проблема шеринга ресурсов в Kubernetes
Вспомним, что происходит, когда в Kubernetes мы хотим запустить под с приатаченной GPU.
Чтобы выделить GPU от Nvidia для конкретного пода, нужно использовать специальный ресурс —
nvidia.com/gpu = N, где N — количество доступных видеокарт. По умолчанию это число нельзя поделить на проценты: нельзя написать, что поду нужна, например, половина видеокарты. Соответственно, один под забирает все ресурсы GPU.Проблема заключается в том, что не всем подам нужна целая GPU. Например, если у вас A100, то выделять 40 ГБ на один инференс бывает излишне. Также не получится запустить несколько реплик одного сервиса, так как на каждую понадобится отдельный ресурс GPU — придется запастись партией видеокарт для такой имплементации.
Еще один кейс связан с обучением моделей на видеокартах. Допустим, у вас в команде несколько Data Science-специалистов, каждому из которых понадобилась GPU для обучения. При этом у вас дефицит видеокарт — если использовать нативный Kubernetes, то образуется очередь на использование ресурсов. Это связано с тем, что каждый инстанс JupyterLab захватывает ровно один ресурс GPU (если не указано больше).
Управлением ресурсами GPU занимается DaemonSet Nvidia Device Plugin. В целом, можно форкнуть этот проект и немного изменить логику присвоения ресурсов в специальном блоке кода. Но мы рассмотрим нативные решения от Nvidia.

GPU-оператор

Разбить GPU в Kubernetes можно вручную, но мы воспользуемся GPU-оператором. Это инструмент, который позволяет администраторам Kubernetes управлять узлами GPU точно так же, как узлами CPU в кластере. О том, как с ним работать, можно почитать в документации.
В нашем случае от оператора мы получаем возможность легко и просто делать разметку MIG в нодах с A100 и A30, а также дополнительно конфигурировать TimeSlicing, о котором я расскажу подробнее в конце статьи.
Принцип работы
Для нашей задачи рассмотрим основные демонсеты, которые используются оператором для работы с GPU в Kubernetes, — mig-manager и nvidia-device-plugin.

Mig-manager — это демонсет в Kubernetes, который следит за изменениями лейбла «nvidia.com/mig.config» на ноде, а затем применяет запрошенную пользователем конфигурацию MIG.
При изменении метки mig-manager сначала останавливает все модули графического процессора, включая плагин устройства, gfd и dcgm-экспортер. Затем останавливает все клиенты GPU на хосте, перечисленные в разделе client.yml (его можно расширять), если драйверы предварительно установлены. Наконец, mig-manager применяет реконфигурацию MIG и перезапускает модули GPU. Реконфигурация может включать перезагрузку узла, если это требуется для включения режима MIG.
Краткий алгоритм обработки запроса на деление GPU в K8S
1. Для конфигурирования MIG GPU-оператор использует два демонсета:
- mig-manager — следит за лейблом nvidia.com/mig.config. Если его значение изменилось, то применяет конфигурацию MIG с помощью nvidia-smi на ноде с GPU. Конфигурацию (например, количество партиций, на которые нужно разбить видеокарту) берет из configmap.
- nvidia-device-plugin — отвечает за ресурсы nvidia/gpu в Managed Kubernetes. Как только mig-manager применит новую конфигурацию MIG, а лейбл nvidia/mig.config.state станет success, nvidia-device-plugin изменит количество ресурсов на указанное в конфигурации.
Если стратегия single, то изменит ресурс nvidia.com/gpu. Если стратегия mixed — заменит nvidia.com/gpu на конкретную партицию.
2. Демонсеты следят за метками на нодах. При процессе миграции конфигурации MIG используется лейбл nvidia.com/mig.config.state для отслеживания статуса:
- pending — миграция в процессе, нужно подождать.
- succeed — миграция выполнена успешно.
- failed — миграция остановлена из-за ошибки.
Ошибка может быть из-за наличия работающих процессов в GPU. Поэтому миграцию необходимо проводить на не занятой GPU: оператор не может оставить «чужие процессы». Подробнее можно ознакомиться здесь.
Подготовка рабочего окружения
Для нашего исследования необходимо снова использовать определенную линейку GPU — A100 или A30. Selectel предоставляет почасовую аренду таких видеокарт, чем мы и воспользуемся. Развернем Managed Kubernetes:
1. Переходим в раздел Облачная платформа в панели управления.
2. Выбираем Kubernetes и нажимаем Создать кластер.
3. Выбираем пул ru-9a, базовый тип кластера и создаем группу нод:
- Выбираем flavor с GPU A100.
- Указываем размер диска.
- Сохраняем изменения.
4. Далее можно добавить свой SSH-ключ и указать необходимую сеть.
5. Ждем. Как только кластер задеплоиться, через панель можно будет достать kubeconfig.
Процесс создания кластера Managed Kubernetes.
Также необходимо позаботиться о том, где мы будем хранить наши модели. Kubernetes позволяет указывать для подов внешние хранилища, например, через протокол NFS. Для этого отлично подойдет файловое хранилище Selectel (Selectel File Storage, SFS). Теперь его можно создать прямо из панели управления.
- Переходим в раздел Облачная платформа внутри панели управления.
- Выбираем Файловое Хранилище и нажимаем Cоздать.
- Выбираем пул ru-9a, указываем размер диска, тип NFS.
- После создания можно скопировать команду для подключения к файловому хранилищу. Из этой команды нам понадобится IP-адрес и путь до файлового хранилища.
Процесс создания файлового хранилища.
Файловое хранилище
Для запуска нашего инференса нужно скачать обученные модели из общего репозитория Nvidia в наше файловое хранилище.
Почему мы вообще используем SFS, а не хранилище внутри ноды (например, монтирование PV в локальную папку на ноде)? Все просто: при создании масштабируемой системы, вероятно, понадобится горизонтально масштабировать наши ноды в кластере. При использовании сетевого хранилища инференсы на разных нодах получат доступ к нашим моделям и не будут дублировать данные внутри себя.
Подключимся к ноде Kubernetes по SSH, чтобы подцепить файловое хранилище по протоколу NFS и положить туда наши модели:
sudo mkdir -p /mnt/nfs && sudo mount -vt nfs "10.222.1.60:/shares/share-3010a65e-124c-4ac8-b08e-a7b2eae0b78c" /mnt/nfs
Далее перейдем в смонтированную папку и скачаем наши модели. Загрузим репозиторий на виртуальную машину и подтянем заготовленные модели. Также скачаем ONNX densenet (с этой моделью работали в предыдущей статье) с помощью скрипта fetch_models:
git clone -b r23.05 https://github.com/triton-inference-server/server.git
cd server/docs/examples
./fetch_models.sh
Убедимся, что в FX есть необходимые файлы для загрузки весов моделей в наш инференс-сервер:
ls /mnt/nfs/server/docs/examples/ -l
ls /mnt/nfs/server/docs/examples/model_repository/ -l

Отлично — файловое хранилище готово для монтирования подов.
Устанавливаем чарт GPU-оператора
GPU-оператор устанавливает несколько компонентов, в том числе nvidia-device-plugin. По умолчанию в Managed Kubernetes плагин уже установлен на нодах с GPU, поэтому сначала удаляем дефолтный плагин:
kubectl delete daemonset/nvidia-device-plugin-daemonset -n kube-system
Далее устанавливаем GPU-оператор с помощью Helm:
helm install --wait --generate-name \
-n kube-system --create-namespace \
nvidia/gpu-operator \
--set mig.strategy=single
Небольшие пояснения по поводу выбора стратегии Mig:
mig.strategy=single— используется только в случае, если на одной ноде подключены GPU с возможностью включения MIG. При этом доступны только конфигурации, которые делят видеокарты на равные части. Примеры конфигураций для GPU A100 и A30 можно посмотреть здесь (конфигурации для стратегии single начинаются с префикса all).mig.strategy=mixed— используется в случаях, когда на одной ноде хотя бы одна GPU поддерживает MIG. Притом доступны любые конфигурации, поддерживаемые видеокартой. Пример такой конфигурации показан здесь.
Доступные конфигурации MIG для видеокарт A100 и A30 можно изучить в предыдущей статье.
После установки оператора GPU посмотрим лейблы ноды, которые относятся к Nvidia:
kubectl get node <node name> -o json | jq '.metadata.labels' | grep nvidia
Нас интересуют следующие лейблы:
nvidia.com/gpu.count— количество ресурсов GPU (сейчас указано значение 1 — следовательно, поду достанется целая видеокарта),nvidia.com/gpu.product— убеждаемся что нода с GPU A100,nvidia.com/mig.config— текущая конфигурация MIG по умолчанию (all-disabled означает, что MIG выключен),nvidia.com/mig.config.state— статус разбиения MIG (устанавливается mig-manager),nvidia.com/mig.strategy— стратегия распределения партиций, single.
Следующим этапом рекомендую проверить, что при отключенном MIG действует правило «один под — одна GPU». Для этого напишем манифест для нашего triton server, который использовали в прошлой статье.
Также обязательно укажем монтирование файлового хранилища с моделями на удаленном SFS-сервере. Для этого запустим две реплики нашего инференс-сервера:
apiVersion: apps/v1
kind: Deployment
metadata:
name: tritonserver
labels:
app: tritonserver
spec:
replicas: 2
selector:
matchLabels:
app: tritonserver
template:
metadata:
labels:
app: tritonserver
spec:
volumes:
- name: models
nfs:
server: 10.222.1.60 # указываем ip адрес nfs сервера
path: /shares/share-3010a65e-124c-4ac8-b08e-a7b2eae0b78c/server/docs/examples/model_repository # указываем папку монтирования
readOnly: false
containers:
- name: tritonserver
ports:
- containerPort: 8000
name: http-triton
- containerPort: 8001
name: grpc-triton
- containerPort: 8002
name: metrics-triton
image: "nvcr.io/nvidia/tritonserver:23.05-py3"
volumeMounts:
- mountPath: /models
name: models
command: ["/bin/sh", "-c"]
args: ["/opt/tritonserver/bin/tritonserver --model-repository=/models --allow-gpu-metrics=false"]
resources:
limits:
nvidia.com/gpu: 1
Теперь можем убедиться, что один из контейнеров встал в очередь:

На нашей ноде доступен только один ресурс GPU. Соответственно, второй под будет ждать в очереди с сообщением:
0/1 nodes are available: 1 Insufficient nvidia.com/gpu. preemption: 0/1 nodes are available: 1 No preemption victims found for incoming pod.
Активируем MIG в Kubernetes
Пришло время активировать MIG в нашем кластере Kubernetes. На самом деле, в этом нет ничего сложного, так как мы используем GPU-оператор, который делает всю работу за нас. Для начала уберем мусор: удалим созданный triton server и перейдем к настройке MIG.
Подключимся к ноде по SSH и выведем nvidia-smi. Как видим, после установки оператора MIG выключен:

Каким образом можно включить MIG и сразу разделить видеокарту, согласно нужной конфигурацию? Все просто: необходимо в лейбл nvidia.com/mig.config прописать конфигурацию MIG, которую можно взять по ссылке.
Теперь попробуем разбить карту на семь равных частей:
kubectl label node <node name> nvidia.com/mig.config=all-1g.5gb --overwrite

Зайдем в логи mig-manager. Как видим, он зафиксировал изменение лейбла и начал свою работу. По сути, зашел на ноду и применил 19 конфигурацию MIG:

Далее повторно подключимся к ноде по SSH и выведем nvidia-smi:

Наша GPU успешно разбилась на семь партиций. Но что произошло с ресурсами в Kubernetes? Посмотрим, сколько стало доступно ресурсов GPU:
kubectl get node <node name> -o json | jq '.status.allocatable

Так как мы выбрали стратегию Single, в Kubernetes теперь доступно семь ресурсов GPU. Далее снова протестируем наш манифест с triton server. Попробуем запустить три реплики сразу и выведем их статус:

В логах пода видим, что сервисы успешно поднялись:

Посмотрим на занятые ресурсы GPU в ноде:
kubectl describe nodes/<node name>

Как видим, система использует три пода из семи. Убедимся, что видеопамять действительно занята на отдельных партициях MIG:

Все три процесса распределены по разным партициям MIG. Таким образом, можно запускать на одной GPU до 7 подов, если вы используете A100.
Так как мы создали deployment, теперь мы можем отскалировать triton server до семи подов:
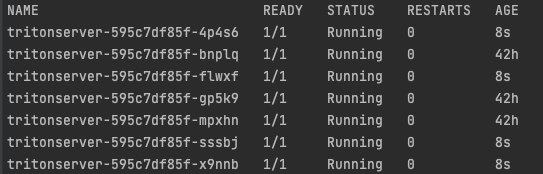
Следующим этапом попробуем повторить наш demo-стенд с балансировщиком нагрузки из прошлой статьи, добавив к нему функционал автомасштабирования.
Балансировка нагрузки
Необходимо создать сервис Kubernetes, чтобы клиенты могли отправлять запросы на triton server. За основу я взял статью от Nvidia, обновив манифесты до версий текущего года. Согласно схеме ниже, все запросы клиентов будут распределятся по нашим инференс-серверам через Load Balancer (балансировщик нагрузки):

Создадим сервис с типом Load Balancer. Также укажем порты, которые пробрасываем для протоколов HTTP и GRPC. Отдельно выделим порт для сбора метрик, показывающие насыщение наших сервисов (по ним мы сможем определить нагрузку на сервисы):
kubectl apply -f pod-sharing-example/service-triton.yaml
apiVersion: v1
kind: Service
metadata:
name: tritonserver
labels:
app: tritonserver
spec:
selector:
app: tritonserver
ports:
- protocol: TCP
port: 8000
name: http
targetPort: 8000
- protocol: TCP
port: 8001
name: grpc
targetPort: 8001
- protocol: TCP
port: 8002
name: metrics
targetPort: 8002
type: LoadBalancer
Проверим, что балансировщик поднялся (также балансировщик будет доступен в панели облака Selectel):
kubectl get svc

Супер — балансировщик запущен. Далее запустим контейнер-клиент из предыдущей статьи и проверим, что инференс развернут и доступен из интернета (внешний IP балансировщика доступен в поле external-ip). Для этого подключаемся внутрь контейнера и отправляем запрос на наш сервер. При этом выбираем модель для распознавания изображений — densenet_onnx.
docker run -it --rm nvcr.io/nvidia/tritonserver:23.05-py3-sdk
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION -i http -u 5.188.81.52:8000 /workspace/images/mug.jpg
В результате, как и в предыдущей статье, моделька распознает, что изображено на картинке. Отправили картинку с кружкой кофе — получили такой результат:
# Inference should return the following
Image '/workspace/images/mug.jpg':
15.346230 (504) = COFFEE MUG
13.224326 (968) = CUP
10.422965 (505) = COFFEEPOT
Мониторинг
Чтобы автоматически масштабировать количество инференс-серверов, необходимо опираться на обратную связь от сервисов — метрики нагрузки. Их можно собирать с помощью Prometheus.
Для начала установим инсталляцию Prometheus Operator, которая подробно описана в отдельной статье:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm search repo prometheus-community
kubectl create namespace monitoring
helm install kube-prom-stack prometheus-community/kube-prometheus-stack -n monitoring
Далее создадим PodMonitor, чтобы метрики из наших инференс-серверов triton попадали в Prometheus:
kubectl apply -f monitoring/pod-monitor-triton.yaml
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: kube-prometheus-stack-tritonmetrics
namespace: monitoring
labels:
release: kube-prom-stack
spec:
selector:
matchLabels:
app: tritonserver
namespaceSelector:
matchNames:
- default
podMetricsEndpoints:
- port: metrics-triton
interval: 10s
path: /metrics
Чтобы применить изменения, необходимо перезагрузить Prometheus:
kubectl rollout restart statefulset prometheus-kube-prom-stack-kube-prome-prometheus
В интерфейсе Prometheus (его можно пробросить через kubectl port forward) в таргетах можно увидеть все наши реплики инференс-сервера:

Отправим несколько тестовых запросов на наш инференс-сервер и посмотрим на метрику NVIDIA Triton — nv_inference_request_success. Количество успешных запросов должно отличаться от 0. При этом можно заметить, что на каждом поде указано разное количество запросов. Это связано с тем, что балансировщик нагрузки распределяет запросы по разным подам, чтобы уменьшить нагрузку на всю нашу платформу:

Также можем запросить агрегированную метрику по следующей формуле (в течение 30 секунд я отправлял запросы на сервер). Формула показывает среднее значение отношения длительности запросов и количества успешных запросов за последние 30 секунд. В дальнейшем по этому соотношению мы и будем управлять автомасштабированием:
avg(delta(nv_inference_queue_duration_us[30s])/(1+delta(nv_inference_request_success[30s])))
Готово — сбор метрик работает, балансировщик нагрузок настроен, MIG в Kubernetes активирован.
Другие полезные материалы:



Автомасштабирование нашей платформы
Prometheus Adapter
Теперь следует развернуть Prometheus Adapter, который умеет взаимодействовать с Kubernetes и самим Prometheus. Он поможет нам использовать собранные показатели для принятия решений о масштабировании. Адаптер собирает названия доступных метрик из Prometheus через регулярные промежутки времени, а затем предоставляет только те метрики, которые соответствуют определенным формам. Эти показатели предоставляются сервисом API и могут быть легко использованы HPA.

Для своего прототипа я выдал расширенный доступ к Kubernetes для Prometheus Adapter, что не советую делать в продакшен-системе. Я это сделал с помощью специальной команды:
kubectl create clusterrolebinding permissive-binding --clusterrole=cluster-admin --user=admin --user=kubelet --group=system:serviceaccounts
Для продакшен-системы вы можете настроить политику RBAC самостоятельно — наиболее подробно процесс описан в официальной документации Kubernetes и документации Selectel.
Определяем новую метрику, CustomMetric
Мы хотим мониторить агрегированную метрику наших сервисов, но для этого ее необходимо создать. Будем использовать среднее время запросов (
avg_time_queue_us) в микросекундах, которое опишем в ConfigMap, чтобы HPA масштабировал реплики по этому таргету.Составим формулу в нашем ConfigMap которая состоит из следующих метрик сервиса:
nv_inference_request_success[30]— число успешных запросов за последние 30 секунд,nv_inference_queue_duration_us— длительность запросов в микросекундах.
Пользовательская метрика
avg_time_queue_us, которую мы определим ниже, означает среднее время запроса за последние 30 секунд. На ее основе HPA решает, следует ли изменять количество реплик. В итоге наш ConfigMap выглядит следующим образом:apiVersion: v1
kind: ConfigMap
metadata:
name: adapter-config
namespace: monitoring
data:
triton-adapter-config.yml: |
rules:
- seriesQuery: 'nv_inference_queue_duration_us{namespace="default",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
name:
matches: "nv_inference_queue_duration_us"
as: "avg_time_queue_us"
metricsQuery: 'avg(delta(nv_inference_queue_duration_us{<<.LabelMatchers>>}[30s])/(1+delta(nv_inference_request_success{<<.LabelMatchers>>}[30s]))) by (<<.GroupBy>>)'
Деплоим Prometheus Adapter
Чтобы HPA мониторил кастомную метрику, мы должны создать Deployment, Service, и APIService для Prometheus Adapter. Далее будут представлены манифесты, которые необходимы для его работы. Ознакомимся сначала с каждым из них и далее задеплоим все вместе.
Ниже представлен код нашего Deployment, который ссылается на созданный ранее ConfigMap и Prometheus (укажите в нем правильный адрес
--prometheus-url и название config-файла, который мы готовили выше):apiVersion: apps/v1
kind: Deployment
metadata:
name: triton-custom-metrics-apiserver
namespace: monitoring
labels:
app: triton-custom-metris-apiserver
spec:
replicas: 1
selector:
matchLabels:
app: triton-custom-metrics-apiserver
template:
metadata:
labels:
app: triton-custom-metrics-apiserver
spec:
containers:
- name: custom-metrics-server
image: registry.k8s.io/prometheus-adapter/prometheus-adapter:v0.11.0
args:
- --cert-dir=/tmp
- --prometheus-url=http://kube-prom-stack-kube-prome-prometheus:9090/
- --metrics-relist-interval=30s
- --config=/etc/config/triton-adapter-config.yml
- --secure-port=6443
ports:
- name: main-port
containerPort: 6443
volumeMounts:
- name: config-volume
mountPath: /etc/config
readOnly: false
volumes:
- name: config-volume
configMap:
name: adapter-config
Теперь создадим новый Service для нашего Deployment:
apiVersion: v1
kind: Service
metadata:
name: triton-custom-metrics-api
namespace: monitoring
spec:
selector:
app: triton-custom-metrics-apiserver
ports:
- port: 443
targetPort: 6443
Далее создадим APIService, в котором определим API для доступа к новым метрикам. API будет доступно по адресу custom.metrics.k8s.io/v1beta1. Так HPA сможет достучаться до нашей кастомной метрики. Код ниже создаст сущность APIService, которую мы привяжем к нашему сервису:
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.custom.metrics.k8s.io
spec:
groupPriorityMinimum: 100
group: custom.metrics.k8s.io
insecureSkipTLSVerify: true
service:
name: triton-custom-metrics-api
namespace: monitoring
version: v1beta1
versionPriority: 5
Задеплоим наши сущности с помощью команды
kubectl apply -f — и можно проверить вывод нашего API:gpu-sharing-k8s git:(main) $ kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq
{
"kind": "APIResourceList",
"apiVersion": "v1",
"groupVersion": "custom.metrics.k8s.io/v1beta1",
"resources": [
{
"name": "pods/avg_time_queue_us",
"singularName": "",
"namespaced": true,
"kind": "MetricValueList",
"verbs": [
"get"
]
},
{
"name": "namespaces/avg_time_queue_us",
"singularName": "",
"namespaced": false,
"kind": "MetricValueList",
"verbs": [
"get"
]
}
]
}
Проверим, что наши поды действительно возвращают метрики:
gpu-sharing-k8s git:(main) $ kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/avg_time_queue_us | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "tritonserver-595c7df85f-bnplq",
"apiVersion": "/v1"
},
"metricName": "avg_time_queue_us",
"timestamp": "2023-08-17T15:21:53Z",
"value": "399300m",
"selector": null
},
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "tritonserver-595c7df85f-gp5k9",
"apiVersion": "/v1"
},
"metricName": "avg_time_queue_us",
"timestamp": "2023-08-17T15:21:53Z",
"value": "0",
"selector": null
},
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "tritonserver-595c7df85f-mpxhn",
"apiVersion": "/v1"
},
"metricName": "avg_time_queue_us",
"timestamp": "2023-08-17T15:21:53Z",
"value": "4275m",
"selector": null
}
]
}
Как видим, под tritonserver-595c7df85f-mpxhn вернул метрику, после того, как я в течение 30 секунд посылал тестовые запросы. По этим метрикам мы и будем масштабировать наши реплики.
Horizontal Pod Autoscaling
HPA масштабирует наши реплики по следующей формуле:

- R — необходимое количество реплик,
- CR — текущее количество реплик,
- CV — текущая метрика, среднее значение метрик со всех реплик,
- DV — порог метрики.
Когда R отличается от CR, HPA увеличивает или уменьшает количество реплик, воздействуя на развертывание подов Kubernetes. По сути, всякий раз, когда соотношение между текущим значением метрики и таргетом больше одного, могут быть развернуты новые реплики.
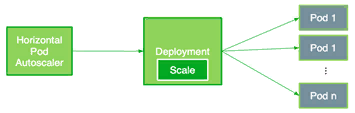
Работа HPA заключается в том, что он говорит Deployment сколько нужно реплик в текущий момент времени.
Ниже представлен манифест HPA, где мы указываем наш Deployment, а также название метрики и ее порог, по которому HPA будет принимать решение об изменении количества реплик. Применим изменения также через команду
kubectl apply -f.apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: tritonserver-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tritonserver
minReplicas: 1
maxReplicas: 7
metrics:
- type: Pods
pods:
metric:
name: avg_time_queue_us
target:
type: AverageValue
averageValue: 50
Если клиенты начнут спамить запросами на инференс-сервер, HPA развернет больше реплик, а балансировщик автоматически начнет перенаправлять запросы на новые реплики. Тем самым мы снизим нагрузку на существующие.
Теперь запустим тест на пропускную способность из прошлой статьи, начиная с 60 конкурентных клиентов:
perf_client -i http -u triton-server -m densenet_onnx --concurrency-range 60:100
Средний показатель вырос до достаточно больших значений, HPA начал масштабировать наши сервисы до максимального числа:
kubectl describe hpa tritonserver-hpa

Но с MIG мы ограничены только масштабированием в семь реплик, так как сейчас мы поделили нашу GPU A100 на максимальное количество партиций. При этом важно помнить, одна реплика — это один ресурс GPU.
Но каким образом мы можем запускать больше реплик в Kubernetes? Давайте посмотрим, как немного обмануть его с помощью TimeSlicing.
Как обмануть GPU-ресурсы Kubernetes с помощью TimeSlicing
Рассмотрим деплой нашего сервиса на ноду с GPU Tesla T4. Такая видеокарта не поддерживает MIG, то есть разделить ее на несколько кусочков так, как мы делали ранее, не получится. Но Nvidia предоставляет еще один способ шеринга GPU в Kubernetes — TimeSlicing. С этой технологией мы не ограничены только GPU A100 и A30.
Добавим через панель управления еще одну группу нод с GPU Tesla T4. Для этого достаточно выбрать необходимый flavor и указать размер хранилища:

Далее увидим, что в нашем кластере добавилась новая группа нод:

Новая группа нод доступна через kubectl:

Официальная документация по настройке TimeSlicing с помощью оператора GPU доступна по ссылке.
Теперь необходимо создать ConfigMap, в котором мы укажем количество партиций для разбиения GPU. Для каждой из них TimeSlicing выделит свой квант времени (то есть конкурентные процессы будут сменять друг друга на разных процессах), при этом будет использоваться общая память GPU. Если один из процессов превысить лимит по видеопамяти и случится OutOfMemory Error (OOM), ошибка затронет все сервисы на GPU.
Далее интегрируем конфигурацию в наш Helm-релиз. Для этого проверим, что на Tesla T4 доступен только один ресурс nvidia.com/gpu:
kubectl get node <node name> -o json | jq '.status.allocatable

Вторым этапом применим следующий ConfigMap, в котором укажем, что нужно поделить GPU на 14 частей:
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config-fine
namespace: kube-system
data:
tesla-t4: |-
version: v1
flags:
migStrategy: none
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 14
Теперь обновляем наш релиз GPU-оператора, указав новый параметр:
helm upgrade --install --wait \
-n kube-system <release-name> \
nvidia/gpu-operator \
-set devicePlugin.config.name=time-slicing-config-fine
Чтобы активировать TimeSlicing, необходимо добавить лейбл на ноду:
kubectl label node <node-name> nvidia.com/device-plugin.config=tesla-t4
В логах nvidia-device-plugin можно увидеть следующее:
"deviceListStrategy": [
"envvar"
],
"deviceIDStrategy": "uuid",
"cdiAnnotationPrefix": "cdi.k8s.io/",
"nvidiaCTKPath": "/usr/bin/nvidia-ctk",
"containerDriverRoot": "/host"
}
},
"resources": {
"gpus": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
],
"mig": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
]
},
"sharing": {
"timeSlicing": {
"resources": [
{
"name": "nvidia.com/gpu",
"devices": "all",
"replicas": 14
}
]
}
}
Как видим из логов, плагину выданы новые инструкции на изменение количества реплик (
sharing[‘timeslicing’]). Теперь можно проверить, сколько ресурсов nvidia.com/gpu стало доступно:
Супер — мы немного обманули Kubernetes. Теперь можно запускать до 14 инференсов на ноде с GPU Tesla T4. Однако мы все еще не застраховали себя от ошибки OOM.
Попробуем запустить наш Deployment на этой ноде с четырьмя репликами:
apiVersion: apps/v1
kind: Deployment
metadata:
name: tritonserver-teslat4
labels:
app: tritonserver-teslat4
spec:
replicas: 4
selector:
matchLabels:
app: tritonserver-teslat4
template:
metadata:
labels:
app: tritonserver-teslat4
spec:
volumes:
- name: models
nfs:
server: 10.222.1.60
path: /shares/share-3010a65e-124c-4ac8-b08e-a7b2eae0b78c/server/docs/examples/model_repository
readOnly: false
nodeSelector:
nvidia.com/gpu.product: Tesla-T4-SHARED
containers:
- name: tritonserver-teslat4
ports:
- containerPort: 8000
name: http-triton
- containerPort: 8001
name: grpc-triton
- containerPort: 8002
name: metrics-triton
image: "nvcr.io/nvidia/tritonserver:23.05-py3"
volumeMounts:
- mountPath: /models
name: models
command: ["/bin/sh", "-c"]
args: ["/opt/tritonserver/bin/tritonserver --model-repository=/models --allow-gpu-metrics=false"]
resources:
limits:
nvidia.com/gpu: 1
kubectl get deployments

Видим, что поды поднялись — заглянем в логи одного из них, чтобы убедиться, что сервер работает. А также посмотрим загрузку GPU через nvidia-smi на ноде:

Видно, что поднялись четыре разных процесса на одной GPU, но они используют общую память. Если мы начнем увеличивать количество подов, то в какой то момент превысим лимит и все наши сервисы получат OOM.
Как решить проблему OOM?
Думаю, этот вопрос достоин отдельной статьи. Но могу дать краткую пару вариантов по решению проблемы с OOM при использовании TimeSlicing:
1. Ограничьте потребление памяти на уровне приложения. Например, если вы работаете с Tensorflow, достаточно повторить действия из документации.
2. Ограничьте потребление памяти на уровне runtime. Можно конвертировать модели в onnx runtime. Подробности ищите по ссылке.
3. Используйте CUDA Multi-Process Service (MPS). Скажу сразу: нативной поддержки от Nvidia еще нет. Но можно использовать форк nvidia-device-plugin.
4. Используйте MIG, тогда OOM будет ограничена конкретной партицией. Да, у вас будет ограничение в семь частей GPU, но при желании его можно обойти. Давайте познакомимся с этим решением поближе.
Коллаборация века, или TimeSlicing в MIG

Сейчас мы посмотрим, каким образом можно «впихнуть» в шеринг GPU по MIG шеринг GPU по TimeSlicing.
Попробуем разбить нашу ноду A100 через mixed-стратегию. Например, возьмем десятую конфигурацию, в которой две части 1g.5gb и по одной 2g.10gb и 3g.20gb. И с помощью TimeSlicing увеличим количество ресурсов (
replicas) в каждой партиции.Для этого необходимо снова обратиться к ConfigMap, который мы использовали для TimeSlicing с Tesla T4. Суть точно такая же: мы вводим разбиение по количеству реплик на каждый ресурс, при этом явно указываем ресурсы для каждой партиции MIG.
apiVersion: v1
kind: ConfigMap
metadata:
name: time-slicing-config-mig
namespace: kube-system
data:
a100-40gb: |-
version: v1
flags:
migStrategy: mixed
sharing:
timeSlicing:
resources:
- name: nvidia.com/gpu
replicas: 3
- name: nvidia.com/mig-1g.5gb
replicas: 4
- name: nvidia.com/mig-2g.10gb
replicas: 3
- name: nvidia.com/mig-3g.20gb
replicas: 4
- name: nvidia.com/mig-7g.40gb
replicas: 7
Теперь обновим оператор GPU, настроив стратегию MIG и добавив новый ConfigMap:
helm upgrade --install --wait \
-n kube-system gpu-operator-1691669985 \
nvidia/gpu-operator \
--set mig.strategy=mixed --set devicePlugin.config.name=time-slicing-config-mig
Укажем для nvidia-device-plugin, что мы будем использовать config a100-40gb из нашего ConfigMap:
kubectl label node <node name> nvidia.com/device-plugin.config=a100-40gb --overwrite
Применим десятую конфигурацию MIG, разбив A100 на разные партиции, которые указывали выше:
kubectl label node <node name> nvidia.com/mig.config=all-balanced --overwrite
Далее выведем доступные ресурсы и посмотрим на результат:
kubectl get node <node name> -o json | jq '.status.allocatable
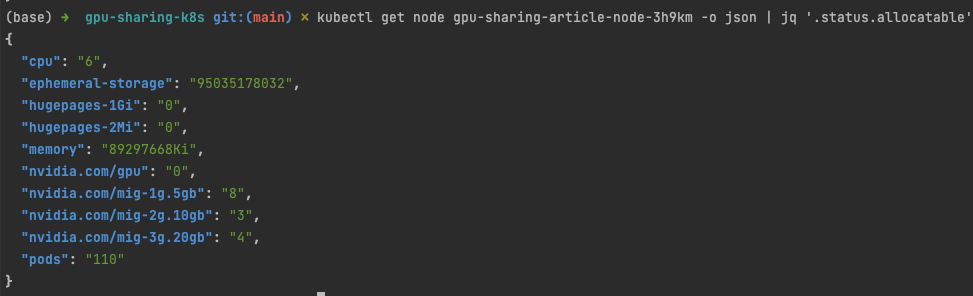
Как видим, нам стало доступно больше ресурсов, так как мы добавили к каждой партиции TimeSlicing. Удалось получить восемь реплик 1g.5gb, три 2g.10gb и четыре 3g.20gb.
Проверим, что теперь мы можем деплоить больше семи реплик нашего инференса на видеокарту A100 с включенным MIG. Задеплоим triton server, слегка модифицировав уже знакомый манифест Deployment. Обратите внимание на секцию с ресурсами, на партицию 1g.5gb:
apiVersion: apps/v1
kind: Deployment
metadata:
name: tritonserver-timeslicing-mig
labels:
app: tritonserver-timeslicing-mig
spec:
replicas: 8
selector:
matchLabels:
app: tritonserver-timeslicing-mig
template:
metadata:
labels:
app: tritonserver-timeslicing-mig
spec:
volumes:
- name: models
nfs:
server: 10.222.1.60
path: /shares/share-3010a65e-124c-4ac8-b08e-a7b2eae0b78c/server/docs/examples/model_repository
readOnly: false
containers:
- name: tritonserver-timeslicing-mig
ports:
- containerPort: 8000
name: http-triton
- containerPort: 8001
name: grpc-triton
- containerPort: 8002
name: metrics-triton
image: "nvcr.io/nvidia/tritonserver:23.05-py3"
volumeMounts:
- mountPath: /models
name: models
command: ["/bin/sh", "-c"]
args: ["/opt/tritonserver/bin/tritonserver --model-repository=/models --allow-gpu-metrics=false"]
resources:
limits:
nvidia.com/mig-1g.5gb: 1
Готово — на партиции nvidia.com/mig-1g.5gb запустилось ровно восемь реплик:

Таким образом, обойти ограничение в семь реплик можно. Однако важно помнить про OOM, потому что используя TimeSlicing мы рискуем превысить лимит, но в рамках уже одной партиции.
Заключение
В этой статье мы изучили, как можно использовать MIG и TimeSlicing в Kubernetes, а также показали реальный пример инференс-сервера с автомасштабированием. Мы познакомились с оператором GPU, который позволяет достаточно просто динамически управлять шерингом видеокарт в Kubernetes. И напоследок — разобрали варианты решения проблемы с OOM.
Готовая платформа с шерингом GPU
Недавно мы имплементировали автоматическую разметку MIG и TimeSlicing в нашей ML-платформе, что позволило запускать дополнительные параллельные Jupyter-инстансы на одной видеокарте, а также очереди экспериментов в ClearML. Но об этом уже в следующей статье — следите за обновлениями в нашем блоге на Хабре!
Все примеры из статьи есть в нашем GitHub-репозитории. Делайте форк и предлагайте свои улучшения!
