TiSpark – это подключаемый модуль Apache Spark, который работает с платформой TiDB и отвечает на запросы сложной интерактивной аналитической обработки (OLAP). Этот плагин Spark широко используется для пакетной обработки больших объёмов данных и для получения аналитических инсайтов. Я старший архитектор решений в PingCAP и бывший разработчик TiSpark. В этом посте я объясню, как он работает и почему TiSpark лучше традиционных решений для пакетной обработки.

Давайте сначала посмотрим на традиционную архитектуру пакетной обработки.
 Традиционная архитектура пакетной обработки
Традиционная архитектура пакетной обработки
Традиционная система пакетной обработки сначала получает необработанные данные, которые могут оказаться файлами CSV или данными из TiDB, MySQL и других разнородных баз данных. Затем необработанные данные делятся на небольшие пакеты подзадач. В каждом пакете данные обрабатываются отдельно, а затем фиксируются и записываются в TiDB. Однако у такой системы есть одна фатальная проблема: она не может гарантировать атомарность, согласованность, изолированность и стойкость (ACID) транзакций через базу данных.
Приложение должно представлять сложный механизм таблиц задач, чтобы отслеживать, успешно ли выполняются задачи и подзадачи. Если подзадача не выполнена, система может откатить её всю. В крайнем случае требуется вмешаться руками. И вот результат: этот механизм замедляет всю задачу обработки данных. Иногда задача замедляется настолько, что коммерческие банки не могут принять транзакцию. Так происходит потому, что пакетная обработка в банковском деле должна закончиться в течение дня; иначе она повлияет на открытие следующего дня. Но если говорить о TiSpark, тут происходит нечто иное.
 Пакетная обработка с помощью TiSpark
Пакетная обработка с помощью TiSpark
TiSpark обрабатывает загруженные необработанные данные как единое целое, не разбивая большой набор данных на небольшие подмножества.
После обработки данные конкурентно записываются на сервер TiKV с помощью протокола двухфазной фиксации [коммита, commit], не проходя через сервер TiDB. Подводя итог, можно сказать, что пакетная обработка с помощью TiSpark имеет следующиее преимущества:
Рисунок ниже показывает роль TiSpark во всём кластере TiDB:
 Компоненты кластера TiDB
Компоненты кластера TiDB
Компоненты на рисунке маркированы цветами:
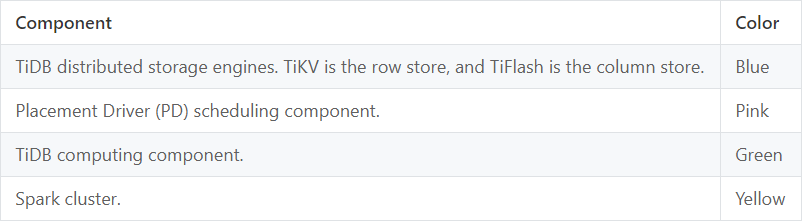
Когда TiSpark получает задачу и обрабатывает данные, перед записью данных он блокирует таблицы. Это предотвращает откат TiSpark его собственной транзакции из-за конфликтов с другими транзакциями. Нам не хочется никаких откатов вроде этого, потому что TiSpark обычно обрабатывает сотни миллионов строк данных и это отнимает много времени. Такое поведение блокировки таблицы применимо только к TiDB 3.0.14 и выше. В версии 4.0.x TiDB мы изменили протокол транзакций, и теперь он поддерживает крупные транзакции до 10 GB. Когда TiSpark совместим с модификацией протокола, нет необходимости блокировать таблицы. Далее TiSpark классифицирует, подсчитывает, сэмплирует и рассчитывает данные для записи и оценивает, сколько новых регионов должно генерироваться при пакетной записи. Затем он передаёт информацию в TiDB. TiDB взаимодействует с другими компонентами и предварительно разделяется на нужное количество регионов. Предварительное разделение регионов позволяет избежать таких проблем, как:
Записывая данные, TiSpark также взаимодействует с PD двумя способами:
Теперь, когда вы понимаете основы TiSpark, давайте погрузимся глубже, чтобы увидеть детали его реализации.
Во-первых, чтобы реализовать клиент TiKV в TiSpark, мы воспользовались Java. Этот клиент богат функциональностью и может отдельно использоваться Java-приложениями, чтобы взаимодействовать с TiKV.
Клиент TiKV позволяет TiSpark взаимодействовать с TiKV и TiFlash. Другая ключевая проблема – как сообщить Spark результат этого взаимодействия.
TiSpark использует Extensions Point в Spark как входную точку, что снижает стоимость поддержки полного набора кода Spark и позволяет настраивать оптимизатор Spark Catalyst. Например, в план выполнения Spark можно легко внедрить логику доступа к TiKV или TiFlash.
TiSpark гарантирует транзакциям ACID-свойства как для записи одной и нескольких таблиц. Для записи в одну таблицу TiSpark полностью совместим с Spark DataSource API, потому что фрейм данных Spark подобен одной таблице. Для записи нескольких таблиц вы можете использовать дополнительный интерфейс, поддерживаемый TiSpark, для сопоставления таблиц базы данных со Spark DataFrame. Например, вы можете сопоставить таблицу с фреймом данных через имя базы данных и имя таблицы, а затем поместить эту информацию в сопоставление. Предположим, вам нужно записать три таблицы, тогда в сопоставлении должно быть три элемента.
Мы хотим, чтобы этот интерфейс не изменился независимо от того, сколько версий TiSpark будет выпущено в будущем.
Если вы знакомы со Spark, вы можете задаться вопросом: DataFrames в Spark похожи на одну таблицу. Не сложно ли будет объединить их из-за несовместимой структуры таблиц? Что ж, не волнуйтесь. Формат данных TiKV – это пары «ключ – значение». Во время записи нескольких таблиц они объединяются только после преобразования DataFrames в пары «ключ – значение».
Как TiSpark сочетается с вашей существующей системой распределённых приложений?
Предположим, у вас есть распределённая система, состоящая из трёх частей:
Вы можете интегрировать TiSpark во фреймворк пакетного приложения, чтобы планировать и обрабатывать пакетные задачи.
TiSpark обрабатывает данные через интерфейсы DataFrame или Spark SQL.
Допустим, есть таблица пользователей, в которой хранятся кредиты и процентные ставки пользователей. На основе этих данных нам необходимо рассчитать проценты, которые пользователи должны заплатить в текущем месяце. В следующем блоке кода показано, как реализовать логику пакетной обработки с использованием интерфейсов DataFrame и Spark SQL отдельно:
Другой пример – система бонусных баллов для кредитных карт. Для расчёта бонусных баллов кредитной карты используются три таблицы:
Чтобы создать новый DataFrame, мы можем объединить три таблицы в Spark. Затем мы выполняем некоторые арифметические вычисления с использованием соответствующих имён столбцов DataFrame, например, умножая объем потребления на коэффициент в таблице правил. После этого выполняем пакетную задачу.
Когда выполнение завершено, мы можем обработать DataFrame в соответствии с различными структурами таблиц. Наконец, TiSpark быстро записывает обработанные данные в TiKV, а TiDB не участвует в записи.
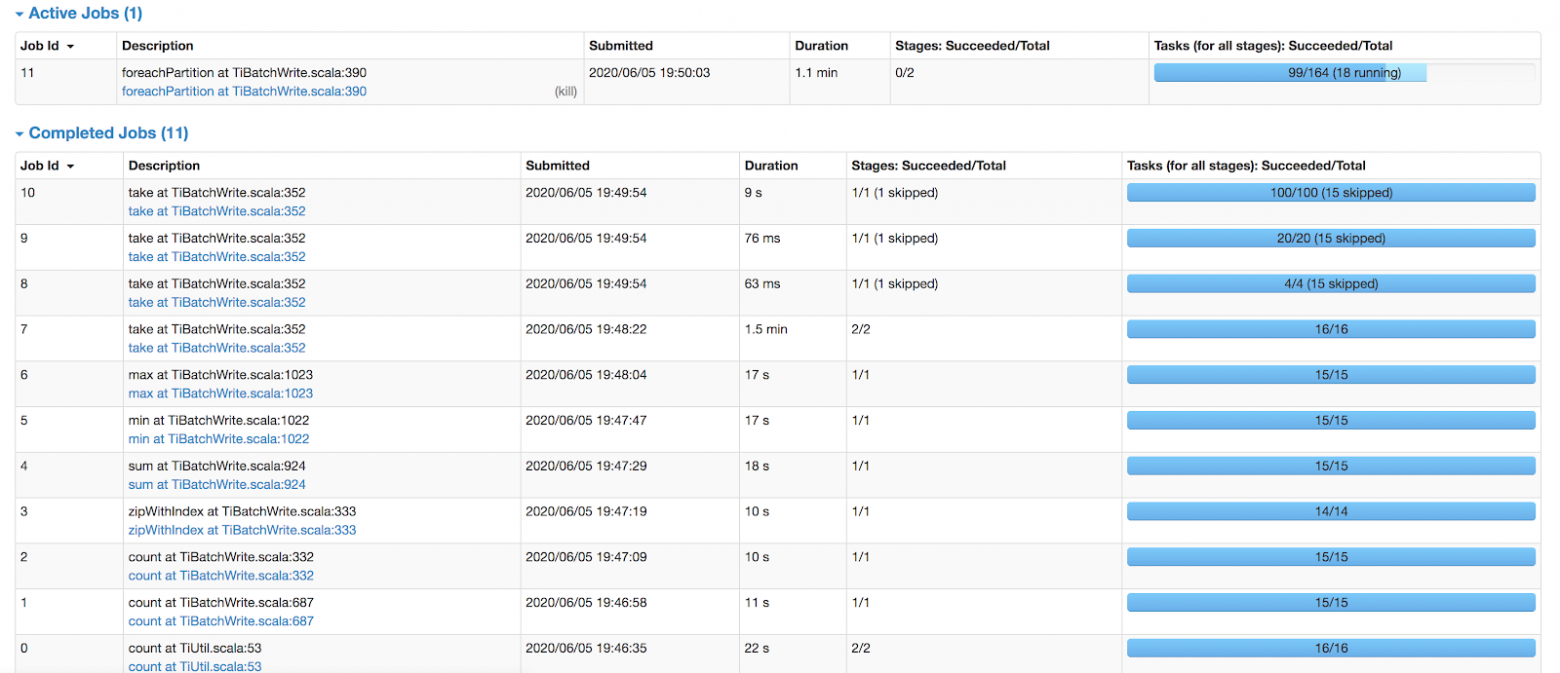
Отправляя задачу в TiSpark, вы можете следить за её выполнением. Рисунок ниже показывает пакетную обработку, которая записывает 4 миллиона строк данных:
 Мониторинг задач в TiSpark
Мониторинг задач в TiSpark
На странице монитора можно посмотреть, какая обрабатывается задача и что она должна быть выполнена примерно за 5 минут. В таблице приводятся сводные данные по каждому идентификатору задания и задаче:

Я надеюсь, что благодаря этому посту вы больше узнали о TiSpark. Если у вас есть вопросы о TiSpark или его решении для пакетной обработки, напишите мне. Я буду рад обсудить с вами, как интегрировать TiSpark в ваше приложение.

Пакетная обработка: традиции и TiSpark
Давайте сначала посмотрим на традиционную архитектуру пакетной обработки.
Традиционная система пакетной обработки сначала получает необработанные данные, которые могут оказаться файлами CSV или данными из TiDB, MySQL и других разнородных баз данных. Затем необработанные данные делятся на небольшие пакеты подзадач. В каждом пакете данные обрабатываются отдельно, а затем фиксируются и записываются в TiDB. Однако у такой системы есть одна фатальная проблема: она не может гарантировать атомарность, согласованность, изолированность и стойкость (ACID) транзакций через базу данных.
Приложение должно представлять сложный механизм таблиц задач, чтобы отслеживать, успешно ли выполняются задачи и подзадачи. Если подзадача не выполнена, система может откатить её всю. В крайнем случае требуется вмешаться руками. И вот результат: этот механизм замедляет всю задачу обработки данных. Иногда задача замедляется настолько, что коммерческие банки не могут принять транзакцию. Так происходит потому, что пакетная обработка в банковском деле должна закончиться в течение дня; иначе она повлияет на открытие следующего дня. Но если говорить о TiSpark, тут происходит нечто иное.
TiSpark обрабатывает загруженные необработанные данные как единое целое, не разбивая большой набор данных на небольшие подмножества.
После обработки данные конкурентно записываются на сервер TiKV с помощью протокола двухфазной фиксации [коммита, commit], не проходя через сервер TiDB. Подводя итог, можно сказать, что пакетная обработка с помощью TiSpark имеет следующиее преимущества:
- Он очень быстрый. TiSpark обходит TiDB и конкурентно записывает данные в TiKV в режиме «многие ко многим». Это даёт горизонтальную масштабируемость. Если узкое место – TiKV или Apache Spark, вы можете просто добавить ещё один узел TiKV или Spark, чтобы сделать хранилище больше или увеличить вычислительную мощность.
- Его легко конфигурировать. Единственное, что вы настраиваете, – указание Spark о том, как использовать TiSpark. Логика пакетной обработки в TiSpark в основном совместима с DataSource API в Spark, поэтому вы настроите TiSpark без труда, как только разберётесь с DataSource API и DataFrame API.
- Транзакции гарантируются. Запись данных будет успешной или неудачной. Реальный кейс показывает, что TiSpark может записать 60 миллионов строк данных TPC-H LINEITEM за 8 минут.
Что под капотом?
Архитектура
Рисунок ниже показывает роль TiSpark во всём кластере TiDB:
Компоненты на рисунке маркированы цветами:
Когда TiSpark получает задачу и обрабатывает данные, перед записью данных он блокирует таблицы. Это предотвращает откат TiSpark его собственной транзакции из-за конфликтов с другими транзакциями. Нам не хочется никаких откатов вроде этого, потому что TiSpark обычно обрабатывает сотни миллионов строк данных и это отнимает много времени. Такое поведение блокировки таблицы применимо только к TiDB 3.0.14 и выше. В версии 4.0.x TiDB мы изменили протокол транзакций, и теперь он поддерживает крупные транзакции до 10 GB. Когда TiSpark совместим с модификацией протокола, нет необходимости блокировать таблицы. Далее TiSpark классифицирует, подсчитывает, сэмплирует и рассчитывает данные для записи и оценивает, сколько новых регионов должно генерироваться при пакетной записи. Затем он передаёт информацию в TiDB. TiDB взаимодействует с другими компонентами и предварительно разделяется на нужное количество регионов. Предварительное разделение регионов позволяет избежать таких проблем, как:
- Горячие точки (hot spots).
- Деградация производительности TiSpark при записи, вызванная разбиением региона в то же самое время.
Записывая данные, TiSpark также взаимодействует с PD двумя способами:
- Получает мета-информацию. TiKV хранит пары «ключ – значение», поэтому перед записью TiSpark преобразует все строки данных в пары «ключ – значение». TiSpark должен знать, в какой регион записывать пары, то есть ему нужно получить соответствующий адрес региона.
- Запрашивает временную метку от PD для гарантии транзакций. Вы можете рассматривать эту временную метку как идентификатор транзакции. Чтобы конкурентно записывать сгенерированные пары в TiKV, TiSpark использует Spark Worker.
Реализация
Теперь, когда вы понимаете основы TiSpark, давайте погрузимся глубже, чтобы увидеть детали его реализации.
Во-первых, чтобы реализовать клиент TiKV в TiSpark, мы воспользовались Java. Этот клиент богат функциональностью и может отдельно использоваться Java-приложениями, чтобы взаимодействовать с TiKV.
- Клиент реализует интерфейс сопроцессора. Он может взаимодействовать с TiKV или TiFlash и выполнять некоторые вычисления, такие как вычисления лимита, порядка и агрегации. Клиент также обрабатывает некоторые предикаты, индексы и поля «ключ – значение». Например, он может оптимизировать запрос с индексом, чтобы не сканировалась вся таблица.
- Клиент реализует протокол двухфазной фиксации, гарантируя, что записи TiSpark соответствуют ACID. Клиент также поддерживает некоторую статистику и информацию об индексах, которые, когда создаётся план выполнения, помогают Spark выбрать лучший путь, чтобы выполнить запрос.
Клиент TiKV позволяет TiSpark взаимодействовать с TiKV и TiFlash. Другая ключевая проблема – как сообщить Spark результат этого взаимодействия.
TiSpark использует Extensions Point в Spark как входную точку, что снижает стоимость поддержки полного набора кода Spark и позволяет настраивать оптимизатор Spark Catalyst. Например, в план выполнения Spark можно легко внедрить логику доступа к TiKV или TiFlash.
TiSpark гарантирует транзакциям ACID-свойства как для записи одной и нескольких таблиц. Для записи в одну таблицу TiSpark полностью совместим с Spark DataSource API, потому что фрейм данных Spark подобен одной таблице. Для записи нескольких таблиц вы можете использовать дополнительный интерфейс, поддерживаемый TiSpark, для сопоставления таблиц базы данных со Spark DataFrame. Например, вы можете сопоставить таблицу с фреймом данных через имя базы данных и имя таблицы, а затем поместить эту информацию в сопоставление. Предположим, вам нужно записать три таблицы, тогда в сопоставлении должно быть три элемента.
Мы хотим, чтобы этот интерфейс не изменился независимо от того, сколько версий TiSpark будет выпущено в будущем.
Если вы знакомы со Spark, вы можете задаться вопросом: DataFrames в Spark похожи на одну таблицу. Не сложно ли будет объединить их из-за несовместимой структуры таблиц? Что ж, не волнуйтесь. Формат данных TiKV – это пары «ключ – значение». Во время записи нескольких таблиц они объединяются только после преобразования DataFrames в пары «ключ – значение».
Приложение
Как TiSpark сочетается с вашей существующей системой распределённых приложений?
Предположим, у вас есть распределённая система, состоящая из трёх частей:
- Фреймворк сервисного приложения принимает пакетные задачи, написанные разработчиками приложений.
- Фреймворк приложения для асинхронных задач планирует пакетные задачи.
- Фреймворк пакетного приложения выполняет пакетные задачи.
Вы можете интегрировать TiSpark во фреймворк пакетного приложения, чтобы планировать и обрабатывать пакетные задачи.
TiSpark обрабатывает данные через интерфейсы DataFrame или Spark SQL.
Допустим, есть таблица пользователей, в которой хранятся кредиты и процентные ставки пользователей. На основе этих данных нам необходимо рассчитать проценты, которые пользователи должны заплатить в текущем месяце. В следующем блоке кода показано, как реализовать логику пакетной обработки с использованием интерфейсов DataFrame и Spark SQL отдельно:
// DataFrame API implementation
val dfWithDeducted = df.withColumn("toBeDeducted",
df("loan") * df("interestRate"))
val finalDF = dfWithDeducted
.withColumn("balance",
dfWithDeducted("balance")
- dfWithDeducted("toBeDeducted"))
.drop("toBeDeducted")
// Spark SQL implementation
val df = spark.sql("select *, (balance - load * interestRate) as newBala from a").drop("balance")
val finalDF = df.withColumnRenamed("newBala", "balance")- Найти столбцы ссуды и процентной ставки с помощью интерфейса DataFrame.
- Воспользоваться простой арифметической операцией, чтобы вычислить проценты.
- Создать новый столбец с именем toBeDeducted при помощи интерфейса withColumn.
- Вычесть значение toBeDeducted из исходного баланса и получить новый баланс.
- Удалить столбец toBeDeducted.
Другой пример – система бонусных баллов для кредитных карт. Для расчёта бонусных баллов кредитной карты используются три таблицы:
- Таблица бонусных баллов: хранит текущие баллы пользователя.
- Таблица расходов: хранит ежемесячные расходы пользователя.
- Таблица правил: хранит правила скидок. У разных продавцов правила скидок различаются. Скидка в ювелирных магазинов – 1:2; то есть 1 доллар – это 2 балла.
Чтобы создать новый DataFrame, мы можем объединить три таблицы в Spark. Затем мы выполняем некоторые арифметические вычисления с использованием соответствующих имён столбцов DataFrame, например, умножая объем потребления на коэффициент в таблице правил. После этого выполняем пакетную задачу.
Когда выполнение завершено, мы можем обработать DataFrame в соответствии с различными структурами таблиц. Наконец, TiSpark быстро записывает обработанные данные в TiKV, а TiDB не участвует в записи.
Визуализация
Отправляя задачу в TiSpark, вы можете следить за её выполнением. Рисунок ниже показывает пакетную обработку, которая записывает 4 миллиона строк данных:
На странице монитора можно посмотреть, какая обрабатывается задача и что она должна быть выполнена примерно за 5 минут. В таблице приводятся сводные данные по каждому идентификатору задания и задаче:
Я надеюсь, что благодаря этому посту вы больше узнали о TiSpark. Если у вас есть вопросы о TiSpark или его решении для пакетной обработки, напишите мне. Я буду рад обсудить с вами, как интегрировать TiSpark в ваше приложение.
Другие профессии и курсы
ПРОФЕССИИ
КУРСЫ
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
КУРСЫ
- Курс по JavaScript
- Курс по Machine Learning
- Курс «Математика и Machine Learning для Data Science»
- Курс «Алгоритмы и структуры данных»
- Курс «Python для веб-разработки»
- Курс по аналитике данных
- Курс по DevOps
