В первом посте этой серии я рассмотрел, как Kubernetes использует комбинацию виртуальных сетевых устройств и правил маршрутизации. Если отправитель знает IP-адрес пода, комбинация разрешает обмен информацией между подами, запускающимися на разных кластерах. Если вы не знаете, как поды обмениваются информацией, стоит прочитать об этом, перед тем как продолжить чтение статьи.
Сеть подов в кластере – аккуратный материал, но сам по себе он недостаточен для создания долгосрочных систем, поскольку поды в Kubernetes эфемерны. В качестве конечной точки можно использовать IP-адрес пода, но нет гарантии, что при следующем воссоздании пода адрес останется прежним. Его смена может произойти по любой причине.
Вероятно, вы знаете, что это старая проблема, и у нее есть стандартное решение: направить трафик через обратный прокси-сервер/балансировщик нагрузки. Клиенты подключаются к прокси, а прокси отвечает за ведение списка здоровых серверов для пересылки запросов.
Существует несколько требований к прокси-серверу:
- долговечность и устойчивость к сбоям;
- наличие списка серверов, которые прокси-сервер может направлять;
- возможность определять, здоров ли сервер и может ли он отвечать на запросы.
Инженеры Kubernetes решили эту проблему элегантным способом. Он основывается на возможностях платформы для доставки по трем приведенным требованиям и начинается с типа ресурса, называемого сервисом.
Сервисы
В первом посте я показал гипотетический кластер с двумя серверными подами и описал, как они могут общаться через узлы. Я хочу привести пример, чтобы описать, как сервис Kubernetes позволяет балансировать нагрузку на множестве серверных подов, позволяя клиентским модулям работать независимо и долговременно. Чтобы создать серверные поды, можно использовать такой deployment:
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: service-test
spec:
replicas: 2
selector:
matchLabels:
app: service_test_pod
template:
metadata:
labels:
app: service_test_pod
spec:
containers:
- name: simple-http
image: python:2.7
imagePullPolicy: IfNotPresent
command: ["/bin/bash"]
args: ["-c", "echo \"<p>Hello from $(hostname)</p>\" > index.html; python -m SimpleHTTPServer 8080"]
ports:
- name: http
containerPort: 8080Этот deployment создает два очень простых HTTP-сервера, отвечающих на порт 8080 с именем хоста, с которым они работают. После создания развертывания с использованием приложения kubectl мы можем видеть, что поды запущены в кластере, и узнать их сетевые адреса:
$ kubectl apply -f test-deployment.yaml
deployment "service-test" created
$ kubectl get pods
service-test-6ffd9ddbbf-kf4j2 1/1 Running 0 15s
service-test-6ffd9ddbbf-qs2j6 1/1 Running 0 15s
$ kubectl get pods --selector=app=service_test_pod -o jsonpath='{.items[*].status.podIP}'
10.0.1.2 10.0.2.2Мы можем продемонстрировать, что сеть пода работает, создавая простой клиентский под для выполнения запроса, а затем просматривая вывод.
apiVersion: v1
kind: Pod
metadata:
name: service-test-client1
spec:
restartPolicy: Never
containers:
- name: test-client1
image: alpine
command: ["/bin/sh"]
args: ["-c", "echo 'GET / HTTP/1.1\r\n\r\n' | nc 10.0.2.2 8080"]После того как под будет создан, будет запущена команда до завершения, под войдет в «завершенное» состояние, и результат можно будет получить с помощью kubectl logs:
$ kubectl logs service-test-client1
HTTP/1.0 200 OK
<!-- blah -->
<p>Hello from service-test-6ffd9ddbbf-kf4j2</p>В этом примере не видно, на каком узле был создан клиентский под. Но независимо от размещения в кластере он сможет достичь серверного пода и получить ответ через сеть пода. Однако, если серверный под должен был умереть и перезапуститься или он перенесен на другой узел, его IP-адрес почти наверняка изменится, и клиент сломается. Мы избегаем этого, создавая сервис.
kind: Service
apiVersion: v1
metadata:
name: service-test
spec:
selector:
app: service_test_pod
ports:
- port: 80
targetPort: httpСервис – тип ресурса Kubernetes, который заставляет прокси настраиваться для пересылки запросов на набор контейнеров. Набор контейнеров, которые будут получать трафик, определяется селектором соответствующим присвоенным при создании контейнеров меткам. После создания сервиса мы видим, что ему был присвоен IP-адрес, и он будет принимать запросы на порт 80.
$ kubectl get service service-test
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service-test 10.3.241.152 <none> 80/TCP 11sЗапросы могут быть отправлены непосредственно на IP-адрес сервиса, но было бы лучше использовать имя хоста, которое разрешает IP-адрес. К счастью, Kubernetes предоставляет внутренний DNS-кластер, который разрешает имя сервиса. Мы можем использовать его с небольшим изменением на клиентский под:
apiVersion: v1
kind: Pod
metadata:
name: service-test-client2
spec:
restartPolicy: Never
containers:
- name: test-client2
image: alpine
command: ["/bin/sh"]
args: ["-c", "echo 'GET / HTTP/1.1\r\n\r\n' | nc service-test 80"]После того как этот под завершится, вывод покажет, что сервис перенаправил запрос на один из серверных подов.
$ kubectl logs service-test-client1
HTTP/1.0 200 OK
<!-- blah -->
<p>Hello from service-test-6ffd9ddbbf-kf4j2</p>Вы можете продолжить запуск клиентского пода и увидите ответы от обоих серверных подов, каждый из которых получит примерно 50% запросов. Если ваша цель – понять принцип работы сервиса, хорошее место для старта – IP-адрес, который был назначен нашей службе.
Сеть сервисов
IP-адрес, который был назначен сервисом тестирования, представляет адрес в сети. Обратите внимание: сеть не совпадает с той, на которой установлены контейнеры.
thing IP network
----- -- -------
pod1 10.0.1.2 10.0.0.0/14
pod2 10.0.2.2 10.0.0.0/14
service 10.3.241.152 10.3.240.0/20Это не то же самое, что и частная сеть с узлами. В первом посте я отметил, что диапазон сетевых адресов пода через kubectl не предоставляется, поэтому для получения этого свойства кластера нужно использовать команду поставщика. То же относится и к диапазону сетевых адресов сервиса. Если вы работаете с Google Container Engine, можете сделать это:
$ gcloud container clusters describe test | grep servicesIpv4Cidr servicesIpv4Cidr: 10.3.240.0/20
Сеть, заданная адресным пространством, называется сервисной. Каждому сервису, который имеет тип ClusterIP”в этой сети будет назначен IP-адрес. Есть и другие типы сервисов, о которых я расскажу в следующем посте про ingress. ClusterIP используется по умолчанию, и это означает, что «сервису будет назначен IP-адрес, доступный из любого пода в кластере». Тип сервиса можно узнать, запустив kubectl describe services с именем сервиса.
$ kubectl describe services service-test
Name: service-test
Namespace: default
Labels: <none>
Selector: app=service_test_pod
Type: ClusterIP
IP: 10.3.241.152
Port: http 80/TCP
Endpoints: 10.0.1.2:8080,10.0.2.2:8080
Session Affinity: None
Events: <none>Сеть сервисов, как и сеть подов, виртуальна, но она отличается от сети подов. Рассмотрим диапазон сетевых адресов подов 10.0.0.0/14. Если посмотреть на хосты, которые составляют узлы в кластере, перечисляя мосты и интерфейсы, можно увидеть фактические устройства, настроенные с адресами в этой сети. Это виртуальные интерфейсы ethernet для каждого пода и мостов, которые соединяют их друг с другом и внешним миром.
Рассмотрим сервисную сеть 10.3.240.0/20. Вы можете выполнить ifconfig и не найдете устройств, настроенных с адресами в этой сети. Вы можете проверить правила маршрутизации на шлюзе, который соединяет все узлы, и не найдете маршрутов для этой сети. Сервисная сеть не существует. Однако выше, когда мы направили запрос на IP-адрес в этой сети, каким-то образом запрос выдал IP-адрес в сервере подов, запущенном в сети подов. Как это произошло? Давайте посмотрим.
Представьте, что команды, выполненные выше, создали следующие поды в тестовом кластере:

Здесь мы имеем два узла: соединяющий шлюз (который также имеет правила маршрутизации для сети пода) и три пода: клиентский под на узле 1, серверный под – также на узле 1 и другой серверный под на узле 2. Клиент делает http-запрос к службе, используя DNS name service-test. Система DNS-кластера разрешает это имя в кластере служб IP 10.3.241.152, а клиентский под заканчивает создание http-запроса, в результате которого некоторые пакеты отправляются с этим IP-адресом в поле назначения.
Основная особенность IP-сети состоит в следующем: когда интерфейс не может доставить пакет к месту назначения, потому что никакое устройство с этим адресом не существует локально, он пересылает пакет к восходящему шлюзу. Таким образом, первый интерфейс, который видит пакеты в этом примере, представляет собой виртуальный интерфейс ethernet внутри клиентского пода. Этот интерфейс находится в сети под 10.0.0.0/14 и не знает никаких устройств с адресом 10.3.241.152, поэтому он перенаправляет пакет на свой шлюз, который является мостом cbr0. Мосты просто передают трафик туда и обратно, поэтому мост отправляет пакет на хост/интерфейс ethernet-узла.
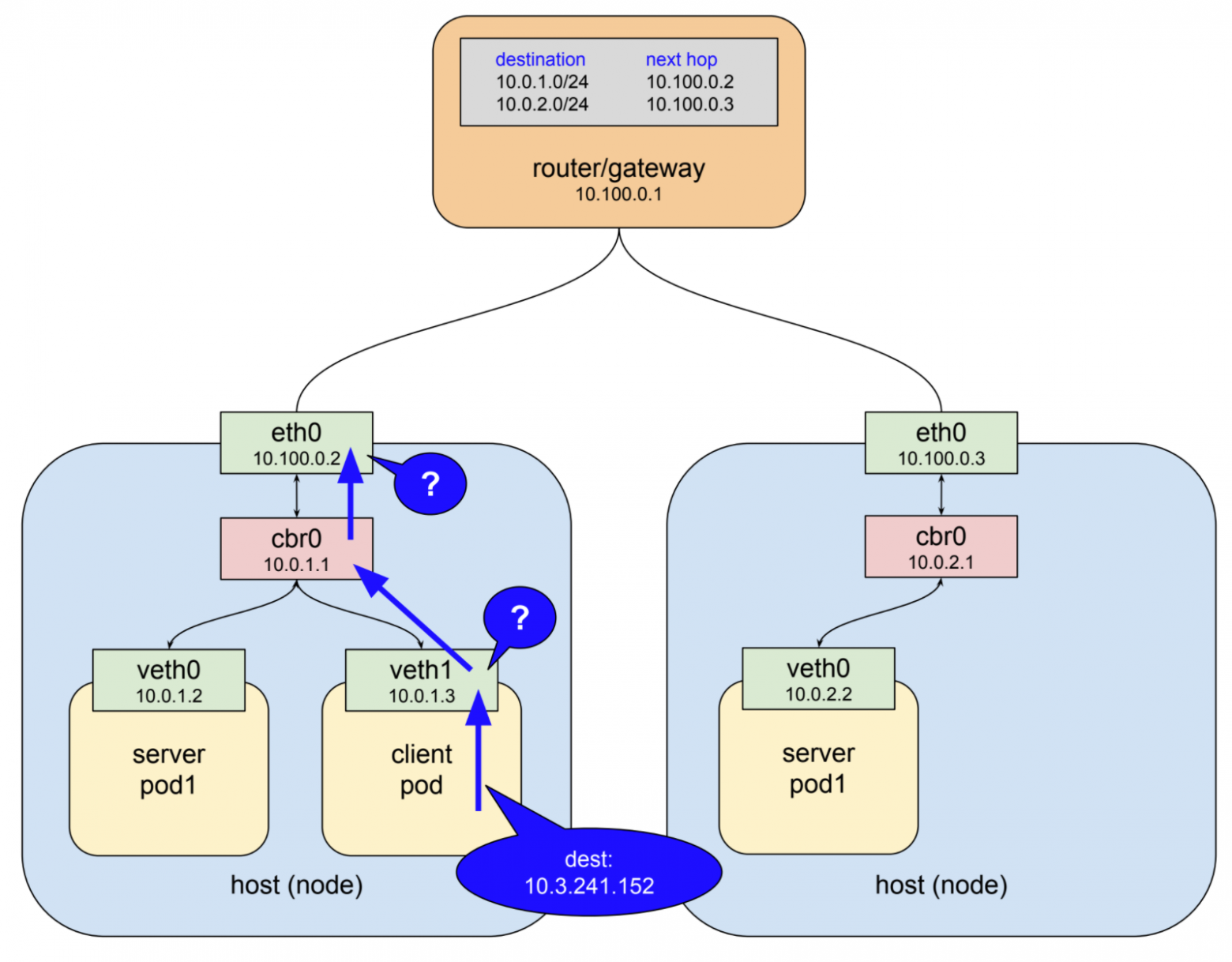
Хост/интерфейс ethernet-узла в этом примере находится в сети 10.100.0.0/24, и он не знает никаких устройств с адресом 10.3.241.152, поэтому пакет должен быть перенаправлен на интерфейс шлюза. Маршрутизатор верхнего уровня показан на чертеже. Вместо этого пакет застревает в полете и перенаправляется на один из живых серверных подов.
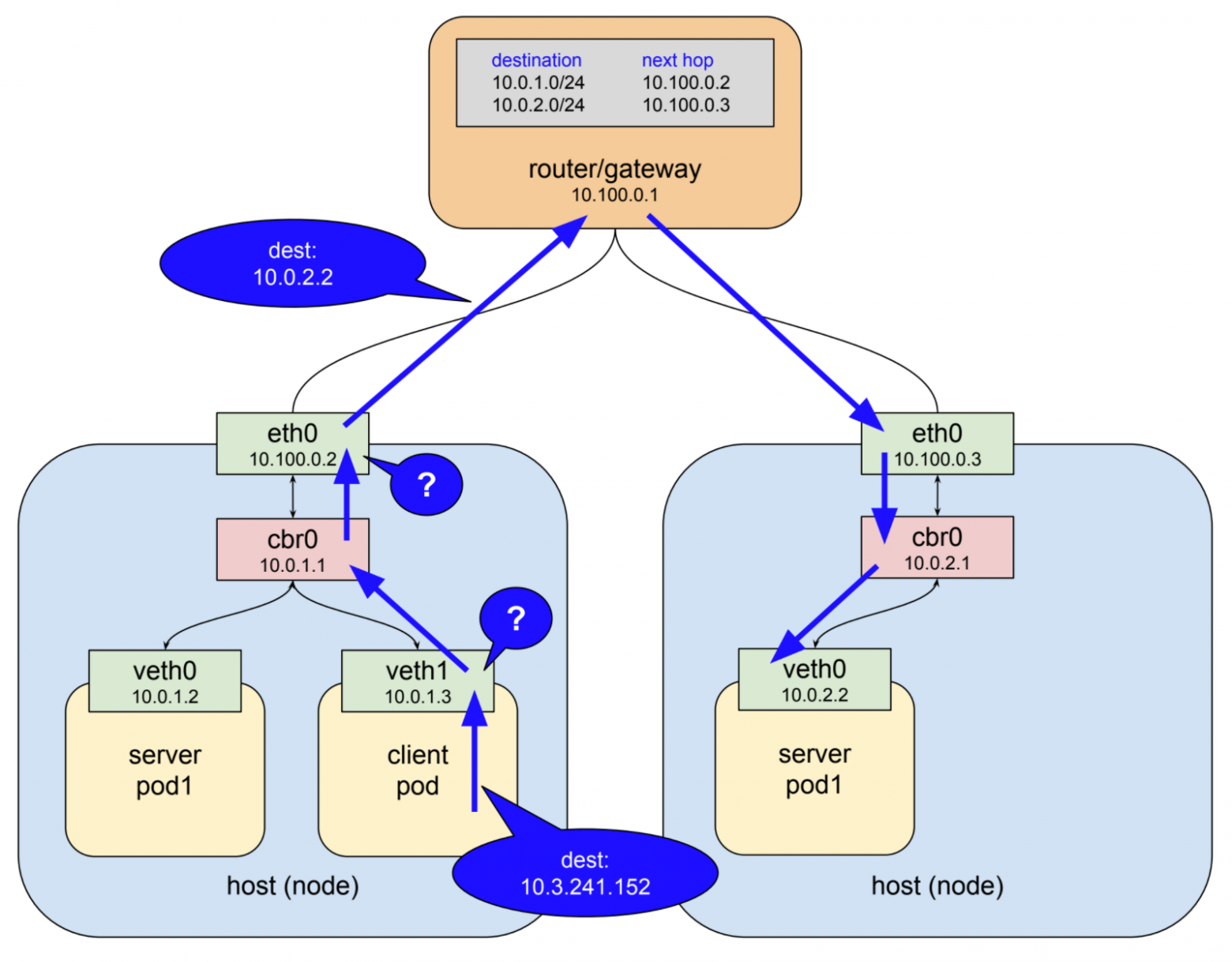
Три года назад, когда я начинал работать с Kubernetes, то, что изображено на диаграмме, казалось волшебством. Каким-то образом мои клиенты смогли подключиться к адресу без связанного с ним интерфейса, и эти пакеты выскочили в нужном месте в кластере. Позже я узнал ответ – это часть программного обеспечения под названием kube-proxy.
kube-proxy
В Kubernetes служба – просто ресурс, запись в центральной базе данных, которая показывает, как настроить программное обеспечение. Служба влияет на конфигурацию и поведение нескольких компонентов в кластере, но важно здесь то, что совершает магические действия, – kube-proxy. Многие из вас будут иметь общее представление о том, что этот компонент делает на основе имени. Но есть некоторые особенности kube-proxy, которые делают его отличным от обычного обратного прокси-сервера, такого как haproxy или linkerd.
Общее поведение прокси-сервера заключается в передаче трафика между клиентами и серверами через два открытых соединения. Поскольку все прокси-серверы такого типа работают в пользовательском пространстве, это означает, что пакеты маршрутизируются в пространство пользователя и обратно в пространство ядра при каждом проходе через прокси. Первоначально kube-proxy реализовывался как прокси-сервер пространства пользователя. Прокси-серверу нужен интерфейс как для прослушивания клиентских подключений, так и для подключения к бэкенд-серверам. Единственные доступные на узле интерфейсы – интерфейс ethernet хоста или виртуальные интерфейсы ethernet в сети пода.
Почему бы не использовать адрес в одной из этих сетей? У меня нет глубоких познаний, но в начале работы проекта стало ясно, что это осложнит правила маршрутизации для сетей, предназначенных для удовлетворения потребностей подов и узлов, которые являются эфемерными объектами в кластере. Сервисам явно необходимо собственное, стабильное, не конфликтующее сетевое адресное пространство, и применение системы виртуальных IP-адресов здесь наиболее логично. Однако, как мы уже отмечали, в этой сети нет реальных устройств. Вы можете использовать сеть в правилах маршрутизации, фильтры брандмауэра и т.д., но не сможете прослушивать порт или открывать соединение через интерфейс, который не существует.
Kubernetes обошел это, используя функцию ядра linux, называемую netfilter, и интерфейс пользовательского пространства для него, называемый iptables. В этом посте недостаточно места, чтобы понять, как это работает. Если вы хотите узнать больше, страница netfilter – хорошее место для старта.
tl;dr;: netfilter – механизм обработки пакетов на основе правил. Он работает в пространстве ядра и просматривает каждый пакет в разных точках жизненного цикла. Он сопоставляет пакеты с правилами, и когда находит правило, которое соответствует ему, применяет указанное действие. Среди многих действий, которые он может предпринять, перенаправление пакета в другой пункт назначения. netfilter – это прокси-сервер ядра. Ниже проиллюстрирована роль netfilter, когда kube-proxy работает как прокси-сервер пользователя.
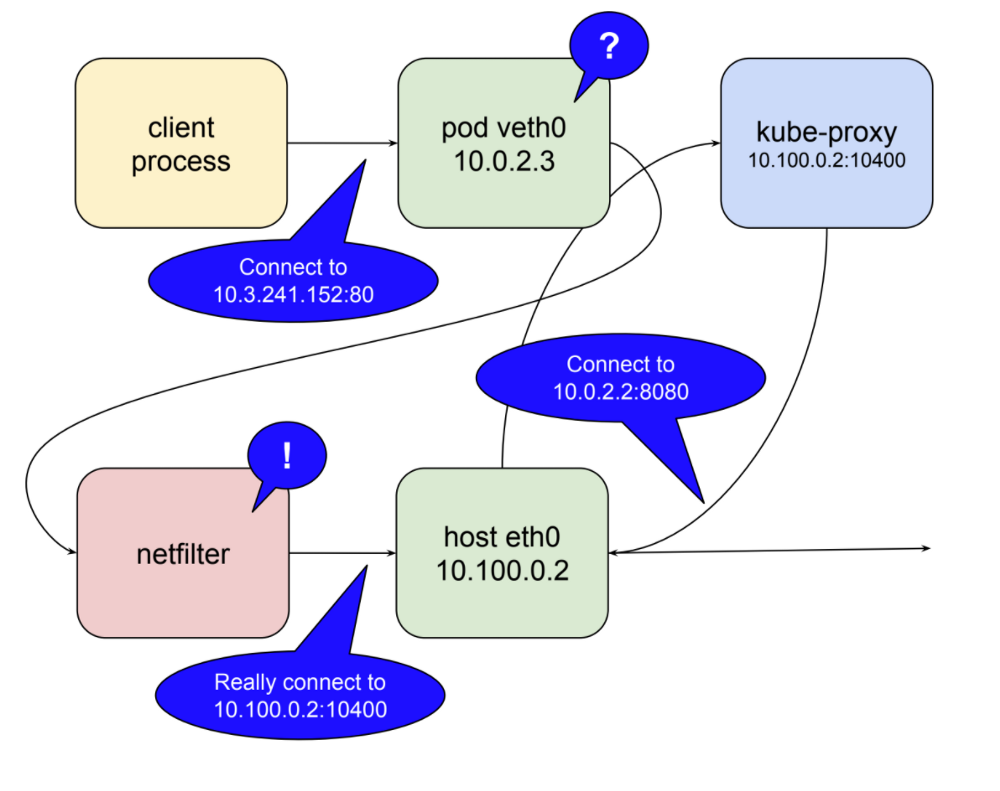
В этом режиме kube-proxy открывает порт (10400 в приведенном выше примере) на локальном хост-интерфейсе для прослушивания запросов к тестовому сервису, вставляет правила netfilter для перенаправления пакетов, предназначенных для IP-адреса службы, на собственный порт и пересылает их запросы на порт 8080. Таким образом, запрос 10.3.241.152:80 магически становится запросом к 10.0.2.2:8080. Учитывая возможности netfilter, все, что требуется для работы с любой службой, – открыть порт kube-proxy и вставить правильные правила netfilter для этого сервиса, что kube-proxy и делает в ответ на уведомления от главного сервера api об изменениях в кластер.
В статье есть еще один поворот. Выше я упомянул, что проксирование на уровне пользовательского пространства является дорогостоящим. Это связано с маршалингом пакетов. В kubernetes 1.2 kube-proxy получил возможность работать в режиме iptables. В этом режиме kube-proxy в большинстве случаев перестает быть прокси-сервером для межкластерных соединений и вместо этого делегирует netfilter работу по обнаружению пакетов, привязанных к IP-адресам сервиса, и перенаправлению их на поды. Теперь все действия происходят в пространстве ядра. В этом режиме задача kube-proxy – поддерживать правила netfilter в актуальном состоянии.
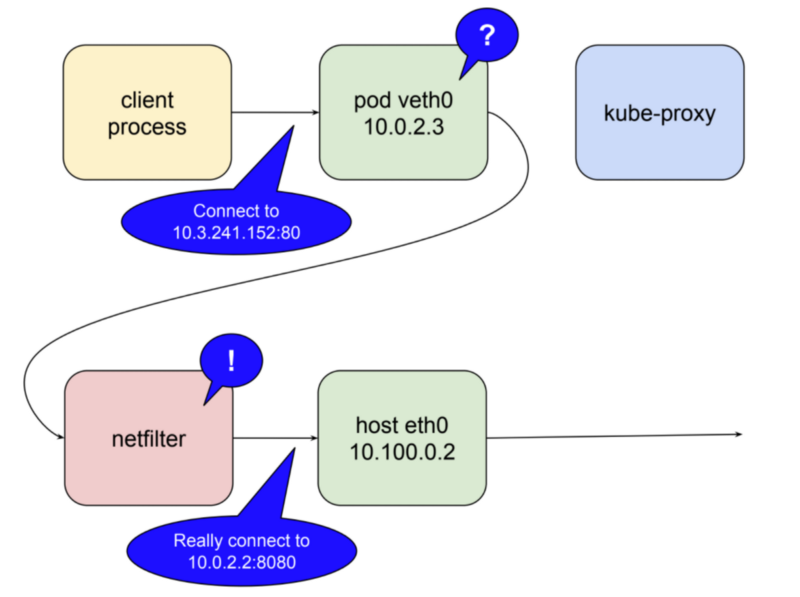
В заключение сравним все вышеописанное с требованиями к надежному прокси, изложенным в начале поста. Является ли прокси-система сервиса долговечной? По умолчанию kube-proxy работает как unitd, поэтому он будет перезагружен, если он не сработает. В Google Container Engine он работает как блок управления, контролируемый daemonset. Это будет значением по умолчанию, возможно, с версией 1.9. В качестве прокси-сервера пользователя kube-proxy по-прежнему представляет собой единственную точку отказа подключения. При запуске в режиме itables система очень долговечна с точки зрения локальных подов, пытающихся соединиться.
Осведомлены ли прокси-сервисы о полезных серверных подах, которые могут обрабатывать запросы? Как упоминалось выше, kube-proxy прослушивает мастер-сервер api для изменений в кластере, который включает в себя изменения в сервисах и конечных точках. Когда он получает обновления, использует iptables для сохранения правил netfilter. Когда создается новый сервис и заполняются его конечные точки, kube-proxy получает уведомление и создает необходимые правила. Аналогично он удаляет правила при удалении сервисов. Проверки работоспособности с конечными точками выполняются с помощью kubelet. Это еще один компонент, который выполняется на каждом узле. Когда найдены нездоровые конечные точки, kubelet уведомляет kube-proxy через сервер api, а правила netfilter редактируются, чтобы удалить эту конечную точку, пока она не станет здоровой снова.
Все это добавляется к высокодоступному кластерному средству для проксирования запросов между контейнерами, позволяя самим контейнерам приходить и уходить, как только меняются потребности кластера. Однако система не лишена своих недостатков. Основной заключается в том, что kube-proxy работает только так, как описано для запросов внутри кластера, т. е. запросов от одного пода к другому. Другой недостаток – следствие того, как работают правила netfilter: для запросов, поступающих извне кластера, правила сбивают исходный IP-адрес. Это стало источником дискуссий, и решения находятся на активном рассмотрении. Более пристально мы рассмотрим оба этих вопроса, когда обсудим ingress в заключительном посте серии.
Часть 3 опубликована (на английском): Понимание сети Kubernetes: ingress.
