Отвечая на вопросы, которые я получил после этой публикации, сегодня хотел бы разрешить бесконечный спор о структуре репозитория, а так же затронуть некоторые проблемы и их решения. Здесь я буду пользоваться своим IaC, основанным на Terraform, но по большей части всё будет применимо и к другим технологиям.
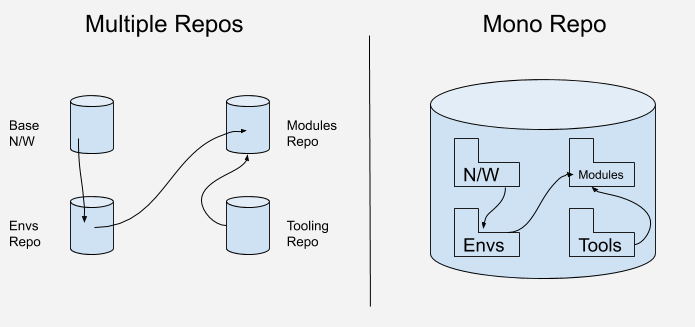
Если говорить о репозиториях инфраструктуры — есть два устоявшихся варианта:
- Monorepo. Один репозиторий для управления всем. Содержит всю вашу IaC, модули и любую вспомогательную автоматизацию;
- Распределенные, «автономные» репозитории. Содержат компоненты, необходимые для решения, которое вы предоставляете. Они могут ссылаться на другие репозитории для повторно используемых компонентов или переменных данных.
В рамках этих решений есть широкий спектр подкатегорий для управления жизненным циклом вашего IaC в различных окружениях. В моей практике я видел, как простые, так и реально ужасные реализации. Постараюсь обсудить причины, по которым люди могут делать тот или иной выбор, а также чего следует, по возможности, избегать.
Прежде чем мы продолжим, полезно вспомнить, что лучшее решение — это подходящее потребностям вашей команды и вашему рабочему процессу. Так что принимайте вещи как есть, то есть полагайтесь также на анализ профессионального опыта.
Jaana Dogan лучше всего отразила проблему в этой цитате. Простое решение чаще всего является сложным и дорогим (такой вот каламбур получается), а также требует обработки огромного числа информации, прежде чем будет реализовано. Это требования, процессы, ограничения и потребности людей, но список можно сильно расширить. Понимая это, давайте разберем требования, обычно предъявляемые к репозиториям infra-as-code (этот список не претендует на роль абсолютно исчерпывающего, либо строго упорядоченного, но в него включены те вещи, которые я обычно встречаю в моих рабочих процессах):
- Возможность ссылаться на общий «стек» или «базовые настройки». Обычно такое получается, если у вас есть рабочее пространство terraform или отдельный файл состояния для вашего основного VPC или сети, обеспечивающих вашим подсетям основное подключение. Обычно они идут в виде выходных данных, вместо использования ресурсов позже в других частях кода.
- Простота продвижения изменений из окружения А в окружение А + 1. Нужно наличие возможности быстрого сравнения окружений и безопасного продвижения изменений, сохранив при этом читаемость кодовой базы. В растущем окружении вы возможно захотите быстро найти «что изменилось» или «в чем разница».
- Гармония программных продуктов. Никто не использует отдельно Terraform, точно так же как не используется Ansible, Puppet или Kubernetes для запуска всего в вашей компании. Структура репозитория должна включать в себя различные, используемые вами инструменты, и предлагать инженерам интуитивное или, по крайней мере, хорошо задокументированное руководство по использованию или внесению изменений.
- Оставаться простым, но не слишком простым. Согласно твиту от Jaana, «простота» не всегда легка, или достижима в большинстве случаев. Чрезмерное упрощение или оптимизация приведут к положению, препятствующему любой значимой скорости. Проектируйте, обеспечивая скорость изменений и простоту тестирования изменений. Сохраняйте гибкость, поскольку новые требования и запросы всегда — а я в этом уже уверен — придут оттуда, где их не ждешь.
- Гладкая кривая обучения. Не все будут с одинаковым опытом и уровнем навыков. Нужно проектировать и документировать для интуитивного использования и простого вовлечения новых инженеров. Чрезмерно сложное решение, «красивое» на первый взгляд, потребует много времени вашей команды по вовлечению, обучению и устранению неполадок.
«Простое» решение.
Начиналось вроде как просто X vs Y, но теперь выглядит примерно так:
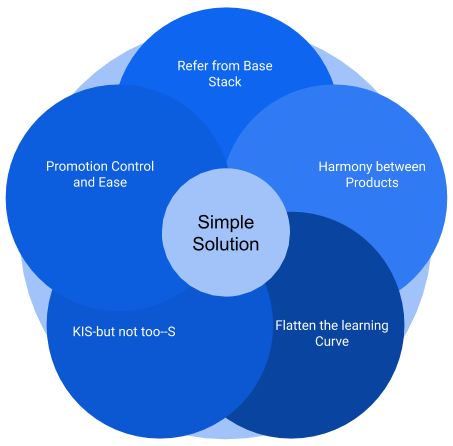
Какой лепесток не дернете — придете к компромиссу, поскольку в его основе — инженерное дело.
Чего не надо делать
В поиске верного пути я также перечислю то, чего и почему, по моему мнению, надо избегать.
Избегайте (слишком большой) вложенности модулей
Сложить матрешкой git submodules или модули terraform — заманчиво, но можно легко попасть впросак, пытаясь найти комбинацию репозитория\ветки\каталога, где размещен модуль, а также молиться, чтобы не было другого модуля где-нибудь еще, на который этот ссылается. Модуль вне кодовой базы редко обновляется. А когда все-таки обновится — в лучшем случае вы потратите время, а в худшем — что-то отломается.
Избегайте симлинков
Я как-то видел реализацию, модули которой были в виде каталогов — символических ссылок в окружении, где они запускались. Если от такого заранее не трясутся поджилки — попытка найти модуль по ссылке может стать ужасом, особенно зная, что ваши изменения обязательно к этому приведут. В конце концов эта реализация была прошита файлами provider-module.tf, связанными с многими экземплярами модулей\окружений. Если не хотите слететь с катушек — просто используйте инструменты Terragrunt и подобные.
Займите «полосу»
Выберите стратегию контроля версий и держитесь ее.
Желаете использовать ветки, чтобы разделять стабильные модули и находящиеся «в разработке»? Действуйте! Хотите применять метки git для проверки, что версии модуля уже пригодна к тестированию и предварительному внедрению? Шикарно! Захотелось использовать папки в репозитории, чтобы собрать все модули в одном репозитории вместо того, чтобы каждый модуль держать в отдельном репозитории? Так тому и быть, раз оно работает в вашем конкретном случае, если оно соотвествует вашей операционной модели.
Чтобы вы ни делали — выберите один вариант и добавьте его в свое руководство по разработке. Хотите перестроиться — делайте это решительно, перестраивайтесь четко и ровно. И что бы вы ни делали — не используйте разные стратегии в разных областях вашей инфраструктуры, покрываемых одной кодовой базой. Делая так вы гарантированно запутаете каждого нового участника, он по факту гарантированно уничтожит или испортит что-то — а это в свою очередь испортит ваш выходной день, ну или ночь. Держите все в стандартизованном виде, а также хорошо документируйте.
Что же делать?
Работайте командой, с вашими пользователями, для ваших заказчиков
Неважно, руководите вы платформой в ветке\канале\организационном подразделении или отделом DevOps\SRE\платформы\инфраструктуры\сети\<подставьте свое имя здесь>, обслуживающим боооольшое предприятие, ваши пользователи (читай разработчики, тестировщики, бизнес-аналитики, ...) это те, кто будет использовать вашу платформу для обеспечения ценности ваших клиентов. И то, что они запрашивают — будет прямо или косвенно способствовать счастью ваших клиентов. Слушайте их, собирайте требования (Я хочу легко и непринужденно настраивать этот «неломаемый» параметр в среде для проверки производительности, не проходя каждый раз эти десять шагов) и адаптироваться к ним или вместе с ними. Счастливые пользователи, соотвественно, будут лучше работать и делать ваших клиентов счастливее.
Помечайте со смыслом
Если используете метки git для своих модулей, убедитесь, что у вас они адекватно стандартизированы. Всякий раз, как вы видите метку вида 1.0.234, полностью несовместимую с предыдущими версиями — поправьте ее и сделайте лучше.
Не раздавайте бездумно права на ветки и PR
Добавьте контроль там, где он будет наиболее уместен. Не забывайте, что люди с инженерным складом ума всегда будут искать более простой и удобный способ выполнения своей работы. А если вы поставите слишком много препятствий перед ними — они найдут способы обхода. Защитите ключевые части вашей инфраструктуры, добавьте мосты в виде review и approval там, где, по вашему мнению, расположены точки принятия решений по продвижению.
Оптимизируйте репозитории
Клонирование занимает слишком много времени? Теряете кучу времени, пролистывая и заходя в каталоги в одном и том же репозитории, чтобы найти то, что, как вы знаете, где-то там лежит? Значит, крайне вероятно пришло время разбить репозиторий на части, сделать их более полезными и простыми в использовании.
Не раздувайте модули сверх нужного
Не стоит создавать модуль-обертку для terraform, что закроет все варианты применения ELB, которые могут вам понадобиться. Это то, что может сделать для вас провайдер. Вместо этого стоит написать значимые для вашей инфраструктуры блоки, которыми вы будете повторно пользоваться. Вот хорошие примеры: бастионы, определения внутренних и публично доступных сервисов, настройки базы данных, ну и многие другие.
На практике это звучит так: если вы тратите больше времени, чтобы понять, что делает модуль, чем обычно вам нужно для прочтения документации по ресурсам в Terraform Docs — этот модуль вам скорее всего не нужен.
Что мне нравится делать
Мне приходилось работать как на большие компании, так и на небольшие, горизонтальные команды, поэтому я большой сторонник ответа «зависит от обстоятельств». Если смотреть на размер проблемы, зрелость команд, их процессов и инструментов, я обычно выбираю одно из двух решений с небольшими изменениями.
Решение 1: Инфраструктурный репозиторий + репозитории модулей на каждое организационное подразделение

Это обычно работает на средних-крупных предприятиях с разными продуктами или функциональными подразделениями, у каждого из которых есть отдельные команды и продукты для поддержки. В больших компаниях это все сопровождается наличием кучи своих инструментов и технологий. Делая такую разбивку с соотвествующими правами на управление версиями и запросами на слияние, вы можете управлять продвижением изменений, сохраняя при этом «типовые» блоки, которые можно использовать повторно.
Каждому «базовому» стеку будет файл или каталог с переменными, представляющими целевое окружение. Ну, а поскольку автоматизация настраивается с использованием заранее известного списка окружений — все получается достаточно стабильным. И позволит вам настроить конвейеры так, чтобы они всегда соответствовали правильному окружению на правильном этапе жизненного цикла.
Чтобы сослаться на определенную версию модуля, можно использовать, например, следующий код:
module "ecr_<repo_name>" {
source = "git::ssh://<repository/terraform-modules.git//ecr?ref=stable"
environment = var.environment
name = "<repo_name>"
}Это позволит вам перебирать версии модуля безопасно, не запрещая иметь множественные изменения со стороны как инфраструктурного репозитория, так и репозитория с модулями. Минусом этого подхода является наличие двойной работы с запросами на слияние и сессиями review, поскольку вам надо обработать запрос в основной ветке в репозитории с модулями, а затем такой же запрос в основном инфраструктурном репозитории. Но это очень надежный вариант работы, защищающий от поспешных коммитов.
Решение 2: Monorepo с «логическими» компонентами
Для мелких подразделений\компаний\проектов мне больше нравится подход с ветками master и develop, которыми разделены prod и non-prod окружения. При таком подходе, совмещенном с рядом расположенными модулями, права на ветки и автоматические применения предоставляют более быстрое внесение изменений и упрощение работы за счет некоторого разделения обязанностей.

Этот подход позволяет вам упростить процессы разработки и продвижения. Но он даже сильнее зависит от автоматизации распространения изменений каждой пары «клиент»-«окружение». А экспертная оценка и структура модулей имеют первостепенное значение — в отличие от предыдущего решения. Как вы понимаете, модули в этом случае ориентированы больше на «функциональные компоненты», чем на абстракцию реальных ресурсов. Внимание сосредоточено на повторном использовании целых стеков вместо балансировщиков нагрузки или групп безопасности.
Я предпочитаю этот подход, если нужно разворачивать одни и те же стеки в нескольких окружениях, отличающихся только базовой сетью или другими второстепенными факторами.
Ну, и что бы вы ни выбрали — не забывайте о «что делать» и «что не делать», упомянутых выше, чтобы избежать кошмарных упражнений в рефакторинге.
