

В современном мире информационных технологий у всех — и у крупных, и у небольших компаний — существует большое количество различных API. И отказоустойчивость, несмотря на многие best practices, чаще всего не позволяет гарантировать 100%-й возможности корректно обрабатывать запросы клиентов, а также восстанавливаться после сбоя и продолжать обработку запросов, утерянных из-за сбоя. Эта проблема возникает даже у больших игроков в интернете, не говоря уже о не очень крупных компаниях.
Я работаю в компании Calltouch, и наша основная цель — добиться отказоустойчивости сервисов и получить возможность управлять данными и запросами, которые клиенты совершали в API-сервис. Нам нужна возможность быстро восстанавливать сервис после сбоя и обрабатывать запросы к сервису, у которого возникли проблемы. Начинать обработку с момента отказа. Всё это позволит приблизиться к состоянию, когда почти невозможно потерять запросы клиентов на нашей стороне.
Разбирая предложенные на рынке решения, мы открыли для себя превосходную производительность и практически безграничные возможности по управлению данными и их обработке — с очень незначительными требованиями к техническим и финансовым ресурсам.
Предыстория
В Calltouch существует сервис API, куда поступают запросы клиентов с данными на построение отчётов в веб-интерфейсе. Эти данные очень важны: они используются в маркетинге, и их потеря может повлечь за собой непредвиденную работу сервиса. Как и у всех, иногда после выкладки или добавления новых возможностей у сервиса возникают проблемы, на некоторое время может произойти отказ в работе. Поэтому нужна возможность очень быстро взять и обработать те запросы с данными, что не были доставлены в сервис API в момент сбоя. Одной лишь балансировкой с бэкапом не обойтись по ряду причин:
- Объём памяти, необходимый для сервиса, может требовать нового оборудования.
- Стоимость оборудования сейчас высока.
- От ошибки с killer request никто не застрахован.
Довольно простая задача (хранение запросов и быстрый доступ к ним) порождает высокие издержки для бюджета. В связи с этим мы решили провести исследование, каким образом сейчас можно сохранить все входящие запросы с очень быстрым доступом к ним.
Исследование
Было несколько вариантов, как хранить входящие данные.
Первый вариант
Сохранять запросы с данными, используя логи nginx, и складывать в какое-то место. Если возникнут проблемы, сервис API обратится к данным, которые где-то сохранены, и после сделает необходимую обработку.
Второй вариант
Сделать дублирование запросов HTTP в несколько мест. Плюс написать дополнительный сервис, который будет куда-то складывать данные.
Конфигурирование веб-сервера для сохранения данных через логи для последующей обработки имеет свои минусы. Такое решение не очень дешёвое, а скорость доступа к данным будет крайне небыстрой. Понадобятся дополнительные сервисы для работы с файлами логов, агрегации и хранения данных. Плюс потребуется большой объём финансовых затрат — на внедрение новых сервисов, обучение сотрудников эксплуатации, вероятную закупку нового оборудования. И самое главное, если такого решения ранее не было, то придётся найти и время на внедрение. По этим причинам мы почти сразу отказались от первого варианта и начали исследовать возможности реализовать второй вариант.
Реализация
Мы выбирали между nginx, goreplay и lwan.
Первым отпал lwan, так как goreplay умеет сразу всё, что нам надо. Осталось лишь выбрать nginx с @post_action или goreplay. Goreplay был эталоном для этой схемы, но мы решили остановиться и поразмыслить о запросах: где и как их лучше хранить.
О хранении можно было особо не задумываться до определённого момента. Нам потребовалась обратная связь между уже обработанными и ещё не обработанными данными. В API, для которого мы делаем дублирование запросов, не предусматривались ID в запросах с клиентской стороны. И возникла такая ситуация: понадобилась возможность подставлять дополнительные данные во входящий запрос. Это позволило бы получить обратную связь между обработанными и необработанными данными, ведь в базу попадут все данные, а не только необработанные. Затем каким-то образом нужно разбираться со всеми входящими данными.
Чтобы разделаться с ID запросов, мы решили добавлять на стороне веб-сервера заголовок с UUID и проксировать такие запросы к API — чтобы сервис API после обработки изменял/удалял те запросы, которые мы дублируем в базе данных. На этом моменте мы отказываемся и от goreplay в пользу nginx, так как nginx поддерживает множество модулей, включая возможность записи в различные базы данных. Это позволит упростить схему обработки данных и уменьшить количество вспомогательных сервисов при решении данной технической задачи. Не придётся тратить время на изучение дополнительных языков и дорабатывать goreplay для соответствия требованиям.
Наиболее простым вариантом было бы взять модуль для nginx, который может писать в какую-нибудь базу данных всё содержимое входящих запросов. Дополнительного кода и программирования в конфигах не очень бы хотелось. Самым гибким и подходящим для нас оказался модуль для Tarantool, им можно проксировать все данные в Tarantool без каких-либо дополнительных действий.
В качестве примера приведём простейшую конфигурацию и небольшой скрипт на Lua для Tarantool, в котором будут логироваться все тела входящих запросов. Взаимодействие сервисов отображено на схеме ниже.
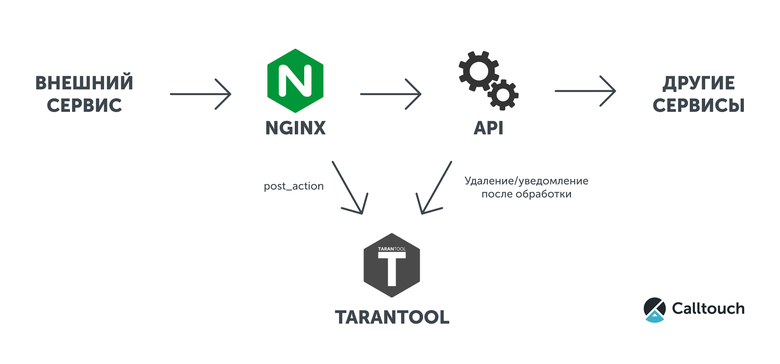
Для этого нам требуется nginx с набором модулей и Tarantool.
Дополнительные модули к nginx:
Пример конфигурации апстрима в nginx для работы с Tarantool:
upstream tnt {
server 127.0.0.1:3301 max_fails=1 fail_timeout=1s;
keepalive 10;
}Конфигурация проксирования данных в Tarantool с использованием post_action:
location @send_to_tnt {
tnt_method http_handler;
tnt_http_rest_methods all;
tnt_pass_http_request on pass_body parse_args pass_headers_out;
tnt_pass tnt;
}
location / {
uuid4 $req_uuid;
proxy_set_header x-request-uuid $req_uuid;
add_header x-request-uuid $req_uuid always;
proxy_pass http://127.0.0.1:8080/;
post_action @send_to_tnt;
}Пример процедуры в Tarantool, которая принимает входящие данные из nginx:
box.cfg {
log_level = 5;
listen = 3301;
}
log = require('log')
box.once('grant', function()
box.schema.user.grant('guest', 'read,write,execute', 'universe')
box.schema.create_space('example')
end)
function http_handler(req)
local headers = req.headers
local body = req.body
if not body then
log.error('no data')
return false
end
if not headers['x-request-uuid'] then
log.error('header x-request-uuid not found')
return false
end
local s, e = pcall(box.space.example.insert,
box.space.example, {headers['x-request-uuid'], body})
if not s then
log.error('can not insert error:\n%s', e)
return false
end
return true
endРешением можно считать небольшой размер кода на Lua и довольно простую конфигурацию nginx. Часть с API здесь учитывать нет смысла, именно её необходимо делать в любом варианте реализации. Можно легко расширить эту схему master-master репликацией в Tarantool и сделать балансировку нагрузки на несколько нод, используя nginx или twemproxy.
Поскольку post_action отправляет данные в Tarantool на несколько миллисекунд позже, чем запрос приходит в API и обрабатывается, в схеме есть один нюанс. Если API работает так же быстро, как Calltouch, то придётся сделать несколько запросов на удаление или тайм-аут перед запросом в Tarantool. Мы выбрали несколько запросов вместо тайм-аутов, чтобы наши сервисы работали без задержек, так же быстро, как и ранее.
Заключение
В заключение можно добавить тот факт, что всего лишь nginx и модуль nginx_upstream_module совместно с Tarantool позволяют достичь невероятной гибкости и простоты в работе с http-запросами, высокой скорости доступа к данным без нарушения работы основных сервисов, значительных перемен при внедрении в существующую инфраструктуру. Охват задач — от создания сложных статистик до обычного сохранения запросов. Не говоря о том, что можно использовать как обычный веб-сервис и реализовать API на базе данного модуля для nginx и Tarantool.
Как развитие на будущее в Calltouch отмечу возможность создания интерфейса, в котором можно почти мгновенно получить доступ по каким-то фильтрам к различным данным. Использовать реальные запросы на тестах вместо синтетической нагрузки. Производить отладку приложений при возникновении проблем — и для повышения качества, и для устранения ошибок. При возможности иметь столь высокую доступность данных и гибкость в работе можно повышать количество сервисов и их качество незначительной суммой расходов на внедрение Tarantool в различных продуктах.
