
Tarantool — это платформа in-memory вычислений с гибкой схемой данных. На её основе можно создать распределённое хранилище, веб-сервер, высоконагруженное приложение или, в конце концов, сервис, включающий в себя всё вышеперечисленное. Но какой бы ни была ваша промышленная задача, однажды настанет момент, когда её решение придётся мониторить. В этой статье я хочу дать обзор существующих средств для мониторинга приложения на базе Tarantool и пройтись по основным кейсам работы с ними.

Я работаю в команде, которая занимается разработкой, внедрением и поддержкой готовых решений на основе Tarantool. Для вывода наших приложений в эксплуатацию на контуре заказчика было необходимо не только разобраться в текущих возможностях мониторинга, но и доработать их. Большая часть доработок в результате вошла в те или иные стандартные пакеты. Данный материал является текстовой выжимкой этого опыта, и может пригодиться тем, кто решит пройти по той же тропе.
Настройка логов в Tarantool
Базовое конфигурирование и использование логов
Для работы с логами в приложениях на базе Tarantool существует пакет log. Это встроенный модуль, который присутствует в каждой инсталляции Tarantool. Процесс по умолчанию заполняет лог сообщениями о своём состоянии и состоянии используемых пакетов.
Каждое сообщение лога имеет свой уровень детализации. Уровень логирования Tarantool характеризуется значением параметра log_level (целое число от 1 до 7):
SYSERROR.ERROR— сообщенияlog.error(...).CRITICAL.WARNING— сообщенияlog.warn(...).INFO— сообщенияlog.info(...).VERBOSE— сообщенияlog.verbose(...).DEBUG— сообщенияlog.debug(...).
Значение параметра log_level N соответствует логу, в который попадают сообщения уровня детализации N и всех предыдущих уровней детализации < N. По умолчанию log_level имеет значение 5 (INFO). Чтобы настроить этот параметр при использовании Cartridge, можно воспользоваться cartridge.cfg:
cartridge.cfg( { ... }, { log_level = 6, ... } )Для отдельных процессов настройка производится при помощи вызова box.cfg:
box.cfg{ log_level = 6 }Менять значение параметра можно непосредственно во время работы программы.
Стандартная стратегия логирования: писать об ошибках в log.error() или log.warn() в зависимости от их критичности, отмечать в log.info() основные этапы работы приложения, а в log.verbose() писать более подробные сообщения о предпринимаемых действиях для отладки. Не стоит использовать log.debug() для отладки приложения, этот уровень диагностики в первую очередь предназначен для отладки самого Tarantool. Не рекомендуется также использовать уровень детализации ниже 5 (INFO), поскольку в случае возникновения ошибок отсутствие информационных сообщений затруднит диагностику. Таким образом, в режиме отладки приложения рекомендуется работать при log_level 6 (VERBOSE), в режиме штатной работы — при log_level 5 (INFO).
local log = require('log')
log.info('Hello world')
log.verbose('Hello from app %s ver %d', app_name, app_ver) -- https://www.lua.org/pil/20.html
log.verbose(app_metainfo) -- type(app_metainfo) == 'table'В качестве аргументов функции отправки сообщения в лог (log.error/log.warn/log.info/log.verbose/log.debug) можно передать обычную строку, строку с плейсхолдерами и аргументы для их заполнения (аналогично string.format()) или таблицу (она будет неявно преобразована в строку методом json.encode()). Функции лога также работают с нестроковыми данными (например числами), приводя их к строке c помощью tostring().
Tarantool поддерживает два формата логов: plain и json:
2020-12-15 11:56:14.923 [11479] main/101/interactive C> Tarantool 1.10.8-0-g2f18757b7
2020-12-15 11:56:14.923 [11479] main/101/interactive C> log level 5
2020-12-15 11:56:14.924 [11479] main/101/interactive I> mapping 268435456 bytes for memtx tuple arena...{"time": "2020-12-15T11:56:14.923+0300", "level": "CRIT", "message": "Tarantool 1.10.8-0-g2f18757b7", "pid": 5675 , "cord_name": "main", "fiber_id": 101, "fiber_name": "interactive", "file": "\/tarantool\/src\/main.cc", "line": 514}
{"time": "2020-12-15T11:56:14.923+0300", "level": "CRIT", "message": "log level 5", "pid": 5675 , "cord_name": "main", "fiber_id": 101, "fiber_name": "interactive", "file": "\/tarantool\/src\/main.cc", "line": 515}
{"time": "2020-12-15T11:56:14.924+0300", "level": "INFO", "message": "mapping 268435456 bytes for memtx tuple arena...", "pid": 5675 , "cord_name": "main", "fiber_id": 101, "fiber_name": "interactive", "file": "\/tarantool\/src\/box\/tuple.c", "line": 261}Настройка формата происходит через параметр log_format так же, как для параметра log_level. Подробнее о форматах можно прочитать в соответствующем разделе документации.
Tarantool позволяет выводить логи в поток stderr, в файл, в конвейер или в системный журнал syslog. Настройка производится с помощью параметра log. О том, как конфигурировать вывод, можно прочитать в документации.
Обёртка логов
Язык Lua предоставляет широкие возможности для замены на ходу практически любого исполняемого кода. Здесь я хотел бы поделиться способом помещения стандартных методов логирования в функцию-обёртку, который мы использовали при реализации сквозного логирования в своих приложениях. Стоит отметить, что способ этот расположен в "серой" зоне легальности, так что прибегать к нему стоит только при отсутствии возможностей решить проблему более элегантно.
local log = require('log')
local context = require('app.context')
local function init()
if rawget(_G, "_log_is_patched") then
return
end
rawset(_G, "_log_is_patched", true)
local wrapper = function(level)
local old_func = log[level]
return function(fmt, ...)
local req_id = context.id_from_context()
if select('#', ...) ~= 0 then
local stat
stat, fmt = pcall(string.format, fmt, ...)
if not stat then
error(fmt, 3)
end
end
local wrapped_message
if type(fmt) == 'string' then
wrapped_message = {
message = fmt,
request_id = req_id
}
elseif type(fmt) == 'table' then
wrapped_message = table.copy(fmt)
wrapped_message.request_id = req_id
else
wrapped_message = {
message = tostring(fmt),
request_id = req_id
}
end
return old_func(wrapped_message)
end
end
package.loaded['log'].error = wrapper('error')
package.loaded['log'].warn = wrapper('warn')
package.loaded['log'].info = wrapper('info')
package.loaded['log'].verbose = wrapper('verbose')
package.loaded['log'].debug = wrapper('debug')
return true
endДанный код обогащает информацию, переданную в лог в любом поддерживаемом формате, идентификатором запроса request_id.
Настройка метрик в Tarantool
Подключение метрик
Для работы с метриками в приложениях Tarantool существует пакет metrics. Это модуль для создания коллекторов метрик и взаимодействия с ними в разнообразных сценариях, включая экспорт метрик в различные базы данных (InfluxDB, Prometheus, Graphite). Материал основан на функционале версии 0.6.0.
Чтобы установить metrics в текущую директорию, воспользуйтесь стандартной командой:
tarantoolctl rocks install metrics 0.6.0Чтобы добавить пакет в список зависимостей вашего приложения, включите его в соответствующий пункт rockspec-файла:
dependencies = {
...,
'metrics == 0.6.0-1',
}Для приложений, использующих фреймворк Cartridge, пакет metrics предоставляет специальную роль cartridge.roles.metrics. Включение этой роли на всех процессах кластера упрощает работу с метриками и позволяет использовать конфигурацию Cartridge для настройки пакета.
Встроенные метрики
Сбор встроенных метрик уже включён в состав роли cartridge.roles.metrics.
Для включения сбора встроенных метрик в приложениях, не использующих фреймворк Cartridge, необходимо выполнить следующую команду:
local metrics = require('metrics')
metrics.enable_default_metrics()Достаточно выполнить её единожды на старте приложения, например поместив в файл init.lua.
В список метрик по умолчанию входят:
- информация о потребляемой Lua-кодом RAM;
- информация о текущем состоянии файберов;
- информация о количестве сетевых подключений и объёме сетевого трафика, принятого и отправленного процессом;
- информация об использовании RAM на хранение данных и индексов (в том числе метрики slab-аллокатора);
- информация об объёме операций на спейсах;
- характеристики репликации спейсов Tarantool;
- информация о текущем времени работы процесса и другие метрики.
Подробнее узнать о метриках и их значении можно в соответствующем разделе документации.
Для пользователей Cartridge также существует специальный набор встроенных метрик для мониторинга состояния кластера. На данный момент он включает в себя метрику о количестве проблем в кластере, разбитых по уровням критичности (аналогична Issues в WebUI Cartridge).
Плагины для экспорта метрик
Пакет metrics поддерживает три формата экспорта метрик: prometheus, graphite и json. Последний можно использовать, например, в связке Telegraf + InfluxDB.
Чтобы настроить экспорт метрик в формате json или prometheus для процессов с ролью cartridge.roles.metrics, добавьте соответствующую секцию в конфигурацию кластера:
metrics:
export:
- path: '/metrics/json'
format: json
- path: '/metrics/prometheus'
format: prometheusЭкспорт метрик в формате json или prometheus без использования кластерной конфигурации настраивается средствами модуля http так же, как любой другой маршрут.
local json_metrics = require('metrics.plugins.json')
local prometheus = require('metrics.plugins.prometheus')
local httpd = require('http.server').new(...)
httpd:route(
{ path = '/metrics/json' },
function(req)
return req:render({
text = json_metrics.export()
})
end
)
httpd:route( { path = '/metrics/prometheus' }, prometheus.collect_http)Для настройки graphite необходимо добавить в код приложения следующую секцию:
local graphite = require('metrics.plugins.graphite')
graphite.init{
host = '127.0.0.1',
port = 2003,
send_interval = 60,
}Параметры host и port соответствуют конфигурации вашего сервера Graphite, send_interval — периодичность отправки данных в секундах.
При необходимости на основе инструментов пакета metrics можно создать собственный плагин для экспорта. Советы по написанию плагина можно найти в соответствующем разделе документации.
Добавление пользовательских метрик
Ядро пакета metrics составляют коллекторы метрик, созданные на основе примитивов Prometheus:
counterпредназначен для хранения одного неубывающего значения;gaugeпредназначен для хранения одного произвольного численного значения;summaryхранит сумму значений нескольких наблюдений и их количество, а также позволяет вычислять перцентили по последним наблюдениям;histogramагрегирует несколько наблюдений в гистограмму.
Cоздать экземпляр коллектора можно следующей командой:
local gauge = metrics.gauge('balloons')В дальнейшем получить доступ к объекту в любой части кода можно этой же командой.
Каждый объект коллектора способен хранить сразу несколько значений метрики с разными лейблами. Например, в результате кода
local gauge = metrics.gauge('balloons')
gauge:set(1, { color = 'blue' })
gauge:set(2, { color = 'red' })внутри коллектора возникнет два различных значения метрики. Для того чтобы каким-либо образом изменить значение конкретной метрики в коллекторе, необходимо указать соответствующие ей лейблы:
gauge:inc(11, { color = 'blue' }) -- increase 1 by 11Лейблы — концепт, который также был вдохновлён Prometheus — используются для различения измеряемых характеристик в рамках одной метрики. Кроме этого, они могут быть использованы для агрегирования значений на стороне базы данных. Рассмотрим рекомендации по их использованию на примере.
В программе есть модуль server, который принимает запросы и способен сам их отправлять. Вместо того, чтобы использовать две различных метрики server_requests_sent и server_requests_received для хранения данных о количестве отправленных и полученных запросов, следует использовать общую метрику server_requests с лейблом type, который может принимать значения sent и received.
Подробнее о коллекторах и их методах можно прочитать в документации пакета.
Заполнение значений пользовательских метрик
Пакет metrics содержит полезный инструмент для заполнения коллекторов метрик — коллбэки. Рассмотрим принцип его работы на простом примере.
В вашем приложении есть буфер, и вы хотите добавить в метрики информацию о текущем количестве записей в нём. Функция, которая заполняет соответствующий коллектор, задаётся следующим образом:
local metrics = require('metrics')
local buffer = require('app.buffer')
metrics.register_callback(function()
local gauge = metrics.gauge('buffer_count')
gauge.set(buffer.count())
end)Вызов всех зарегистрированных коллбэков производится непосредственно перед сбором метрик в плагине экспорта. С таким подходом метрики, отправляемые наружу, всегда будут иметь наиболее актуальное значение.
Мониторинг HTTP-трафика
Пакет metrics содержит набор инструментов для подсчёта количества входящих HTTP-запросов и измерения времени их обработки. Они предназначены для работы со встроенным пакетом http, и подход будет отличаться в зависимости от того, какую версию вы используете.
Чтобы добавить HTTP-метрики для конкретного маршрута при использовании пакета http 1.x.x, вам необходимо обернуть функцию-обработчик запроса в функцию http_middleware.v1:
local metrics = require('metrics')
local http_middleware = metrics.http_middleware
http_middleware.build_default_collector('summary', 'http_latency')
local route = { path = '/path', method = 'POST' }
local handler = function() ... end
httpd:route(route, http_middleware.v1(handler))Для хранения метрик можно использовать коллекторы histogram и summary.
Чтобы добавить HTTP-метрики для маршрутов роутера при использовании пакета http 2.x.x, необходимо воспользоваться следующим подходом:
local metrics = require('metrics')
local http_middleware = metrics.http_middleware
http_middleware.build_default_collector('histogram', 'http_latency')
router:use(http_middleware.v2(), { name = 'latency_instrumentation' })Рекомендуется использовать один и тот же коллектор для хранения всей информации об обработке HTTP-запросов (например, выставив в начале коллектор по умолчанию функцией build_default_collector или set_default_collector). Прочитать больше о возможностях http_middleware можно в документации.
Глобальные лейблы
В пункте "Добавление пользовательских метрик" вводится понятие лейблов, предназначенных для различения измеряемых характеристик в рамках одной метрики. Их выставление происходит непосредственно при измерении наблюдения в рамках одного коллектора. Однако это не единственный тип лейблов, которые поддерживает пакет metrics.
Для того чтобы прибавить к каждой метрике какой-то общий для процесса или группы процессов Tarantool (например, имя машины или название приложения) лейбл, необходимо воспользоваться механизмом глобальных лейблов:
local metrics = require('metrics')
local global_labels = {}
-- постоянное значение
global_labels.app = 'MyTarantoolApp'
-- переменные конфигурации кластера (https://www.tarantool.io/ru/doc/latest/book/cartridge/cartridge_api/modules/cartridge.argparse/)
local argparse = require('cartridge.argparse')
local params, err = argparse.parse()
assert(params, err)
global_labels.alias = params.alias
-- переменные окружения процесса
local host = os.getenv('HOST')
assert(host)
global_labels.host = host
metrics.set_global_labels(global_labels)Обратите внимание, что метод set_global_labels полностью перезаписывает таблицу глобальных лейблов при каждом вызове.
Роль cartridge.roles.metrics по умолчанию выставляет alias процесса Tarantool в качестве глобального лейбла.
Важно иметь в виду, что глобальные лейблы добавляются в метрики непосредственно в процессе сбора и не влияют на структуру хранения метрик в коллекторах. Во избежание проблем не стоит использовать один и тот же лейбл и как глобальный, и как локальный, т.е. непосредственно передаваемый коллектору при измерении наблюдения.
Мониторинг внешних параметров
Tarantool не только позволяет организовывать сбор внутренних метрик о работе приложения, но и способен выступать как агент мониторинга внешних параметров. Подмодуль psutils пакета metrics является примером реализации такого поведения.
С помощью psutils можно настроить сбор метрик об использовании CPU процессами Tarantool. Его информация основывается на данных /proc/stat и /proc/self/task. Подключить сбор метрик можно с помощью следующего кода:
local metrics = require('metrics')
metrics.register_callback(function()
local cpu_metrics = require('metrics.psutils.cpu')
cpu_metrics.update()
end)Возможность писать код на Lua делает Tarantool гибким инструментом, позволяющим обходить различные препятствия. Например, psutils возник из необходимости следить за использованием CPU вопреки отказу администраторов со стороны заказчика "подружить" в правах файлы /proc/* процессов Tarantool и плагин inputs.procstat Telegraf, который использовался на местных машинах в качестве основного агента.
Пакет metrics сам по себе способен решить многие прикладные проблемы, но, конечно же, далеко не все, особенно если речь идёт о внешнем мониторинге. Но стоит иметь в виду, что возможность обогатить его с помощью кода всегда остаётся в распоряжении разработчика, и, если возникает необходимость, этой возможностью уж точно не стоит пренебрегать.
Визуализация метрик
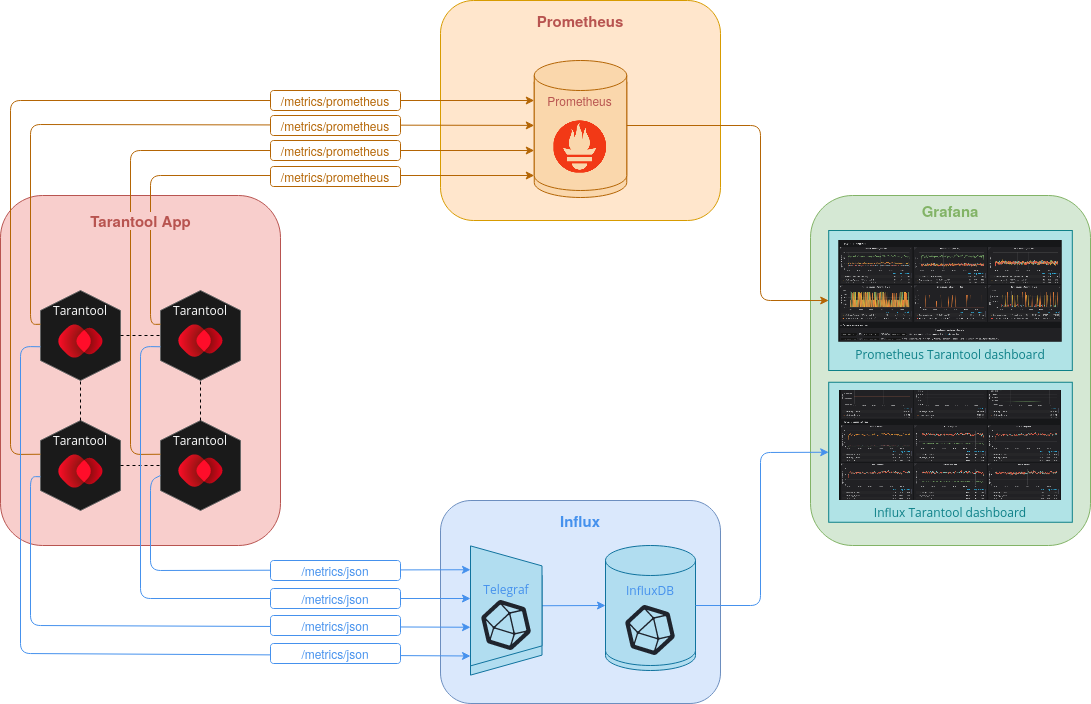
Хранение метрик в Prometheus
Настройка пути для экспорта метрик Tarantool в формате Prometheus описана в пункте "Плагины для экспорта метрик". Ответ запроса по такому маршруту выглядит следующим образом:
...
# HELP tnt_stats_op_total Total amount of operations
# TYPE tnt_stats_op_total gauge
tnt_stats_op_total{alias="tnt_router",operation="replace"} 1
tnt_stats_op_total{alias="tnt_router",operation="select"} 57
tnt_stats_op_total{alias="tnt_router",operation="update"} 43
tnt_stats_op_total{alias="tnt_router",operation="insert"} 40
tnt_stats_op_total{alias="tnt_router",operation="call"} 4
...Чтобы настроить сбор метрик в Prometheus, необходимо добавить элемент в массив scrape_configs. Этот элемент должен содержать поле static_configs с перечисленными в targets URI всех интересующих процессов Tarantool и поле metrics_path, в котором указан путь для экспорта метрик Tarantool в формате Prometheus.
scrape_configs:
- job_name: "tarantool_app"
static_configs:
- targets:
- "tarantool_app:8081"
- "tarantool_app:8082"
- "tarantool_app:8083"
- "tarantool_app:8084"
- "tarantool_app:8085"
metrics_path: "/metrics/prometheus"В дальнейшем найти метрики в Grafana вы сможете, указав в качестве job соответствующий job_name из конфигурации.
Пример готового docker-кластера Tarantool App + Prometheus + Grafana можно найти в репозитории tarantool/grafana-dashboard.
Хранение метрик в InfluxDB
Чтобы организовать хранение метрик Tarantool в InfluxDB, необходимо воспользоваться стеком Telegraf + InfluxDB и настроить на процессах Tarantool экспорт метрик в формате json (см. пункт "Плагины для экспорта метрик"). Ответ формируется следующим образом:
{
...
{
"label_pairs": {
"operation": "select",
"alias": "tnt_router"
},
"timestamp": 1606202705935266,
"metric_name": "tnt_stats_op_total",
"value": 57
},
{
"label_pairs": {
"operation": "update",
"alias": "tnt_router"
},
"timestamp": 1606202705935266,
"metric_name": "tnt_stats_op_total",
"value": 43
},
...
}HTTP-плагин Telegraf требует заранее указать список возможных тегов для метрики. Конфигурация, учитывающая все стандартные лейблы, будет выглядеть следующим образом:
[[inputs.http]]
urls = [
"http://tarantool_app:8081/metrics/json",
"http://tarantool_app:8082/metrics/json",
"http://tarantool_app:8083/metrics/json",
"http://tarantool_app:8084/metrics/json",
"http://tarantool_app:8085/metrics/json"
]
timeout = "30s"
tag_keys = [
"metric_name",
"label_pairs_alias",
"label_pairs_quantile",
"label_pairs_path",
"label_pairs_method",
"label_pairs_status",
"label_pairs_operation"
]
insecure_skip_verify = true
interval = "10s"
data_format = "json"
name_prefix = "tarantool_app_"
fieldpass = ["value"]Список urls должен содержать URL всех интересующих процессов Tarantool, настроенные для экспорта метрик в формате json. Обратите внимание, что лейблы метрик попадают в Telegraf и, соответственно, InfluxDB как теги, название которых состоит из префикса label_pairs_ и названия лейбла. Таким образом, если ваша метрика имеет лейбл с ключом mylbl, то для работы с ним в Telegraf и InfluxDB необходимо указать в пункте tag_keys соответствующего раздела [[inputs.http]] конфигурации Telegraf значение ключа label_pairs_mylbl, и при запросах в InfluxDB ставить условия на значения лейбла, обращаясь к тегу с ключом label_pairs_mylbl.
В дальнейшем найти метрики в Grafana вы сможете, указав measurement в формате <name_prefix>http (например, для указанной выше конфигурации значение measurement — tarantool_app_http).
Пример готового docker-кластера Tarantool App + Telegraf + InfluxDB + Grafana можно найти в репозитории tarantool/grafana-dashboard.
Стандартный дашборд Grafana
Для визуализации метрик Tarantool с помощью Grafana на Official & community built dashboards опубликованы стандартные дашборды. Шаблон состоит из панелей для мониторинга HTTP, памяти для хранения данных вместе с индексами и операций над спейсами Tarantool. Версию для использования с Prometheus можно найти здесь, а для InfluxDB — здесь. Версия для Prometheus также содержит набор панелей для мониторинга состояния кластера, агрегированной нагрузки и потребления памяти.
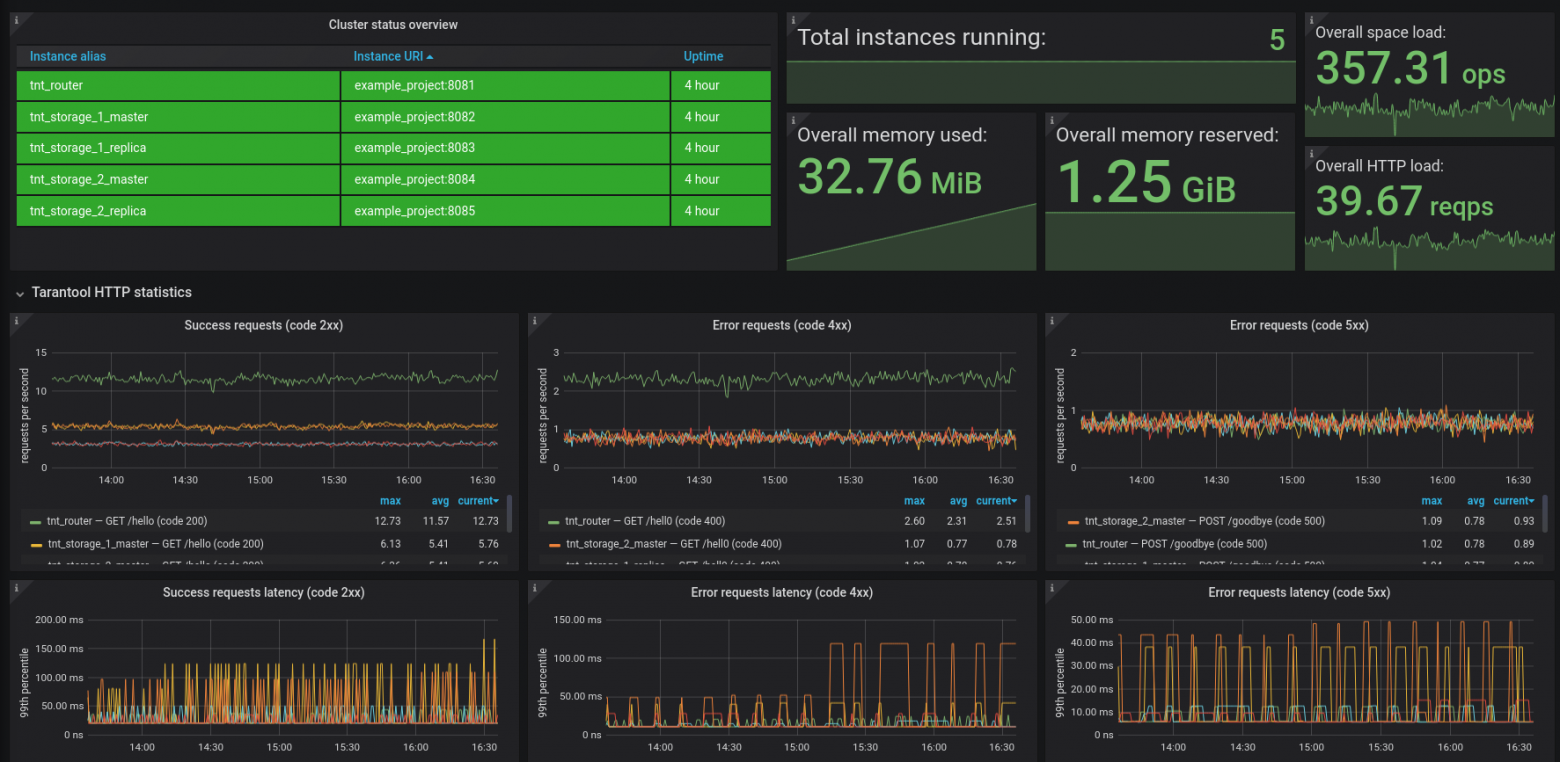
Чтобы импортировать шаблон дашборды, достаточно вставить необходимый id или ссылку в меню Import на сервере Grafana. Для завершения процесса импорта необходимо задать переменные, определяющие место хранения метрик Tarantool в соответствующей базе данных.
Генерация дашбордов Grafana с grafonnet
Стандартные дашборды Grafana были созданы с помощью инструмента под названием grafonnet. Что это за заморский зверь и как мы к нему пришли?
С самого начала перед нами стояла задача поддерживать не одну, а четыре дашборды: два похожих проекта, экземпляр каждого из которых находился в двух разных зонах. Изменения, такие как переименование метрик и лейблов или добавление/удаление панелей, происходили чуть ли не ежедневно, но после творческой работы по проектированию улучшений и решению возникающих проблем непременно следовало механическое накликивание изменений мышью, умножавшееся в своём объёме на четыре. Стало ясно, что такой подход следует переработать.
Одним из первых способов решить большинство возникающих проблем было использование механизма динамических переменных (Variables) в Grafana. Например, он позволяет объединить дашборды с метриками из разных зон в одну с удобным переключателем. К сожалению, мы слишком быстро столкнулись с проблемой: использование механизма оповещений (Alert) не совместимо с запросами, использующими динамические переменные.
Любой дашборд в Grafana по сути представляет собой некоторый json. Более того, платформа позволяет без каких-либо затруднений экспортировать в таком формате существующие дашборды. Работать с ним в ручном режиме несколько затруднительно: размер даже небольшого дашборда составляет несколько тысяч строк. Первым способом решения проблемы был скрипт на Python, который заменял необходимые поля в json, по сути превращая один готовый дашборд в другой. Когда разработка библиотеки скриптов пришла к задаче добавления и удаления конкретных панелей, мы начали осознавать, что пытаемся создать генератор дашбордов. И что эту задачу уже кто-то до нас решал.
В открытом доступе можно найти несколько проектов, посвящённых данной теме. К счастью или несчастью, проблема выбора решилась быстро: на контуре заказчика для хранения метрик мы безальтернативно пользовались InfluxDB, а поддержка запросов к InfluxDB хоть в какой-то форме присутствовала только в grafonnet.
grafonnet — opensource-проект под эгидой Grafana, предназначенный для программной генерации дашбордов. Он основан на языке программирования jsonnet — языке для генерации json. Сам grafonnet представляет собой набор шаблонов для примитивов Grafana (панели и запросы разных типов, различные переменные) с методами для объединения их в цельный дашборд.
Основным преимуществом grafonnet является используемый в нём язык jsonnet. Он прост и минималистичен, и всегда имеет дело с json-объектами (точнее, с их местной расширенной версией, которая может включать в себя функции и скрытые поля). Благодаря этому на любом этапе работы выходной объект можно допилить под себя, добавив или убрав какое-либо вложенное поле, не внося при этом изменений в исходный код.
Начав с форка проекта и сборки нашей дашборды на основе этого форка, впоследствии мы оформили несколько Pull Request-ов в grafonnet на основе наших изменений. Например, один из них добавил поддержку запросов в InfluxDB на основе визуального редактора.

Код наших стандартных дашбордов расположен в репозитории tarantool/grafana-dashboard. Здесь же находится готовый docker-кластер, состоящий из стеков Tarantool App + Telegraf + InfluxDB + Grafana, Tarantool App + Prometheus + Grafana. Его можно использовать для локальной отладки сбора и обработки метрик в вашем собственном приложении.
При желании из стандартных панелей можно собрать дашборд, расширенный панелями для отображения собственных метрик приложения.
На что смотреть?
В первую очередь, стоит следить за состоянием самих процессов Tarantool. Для этого подойдёт, например, стандартный up Prometheus. Можно соорудить простейший healthcheck самостоятельно:
httpd:route(
{ path = '/health' },
function(req)
local body = { app = app, alias = alias, status = 'OK' }
local resp = req:render({ json = body })
resp.status = 200
return resp
end
)Рекомендации по мониторингу внешних параметров ничем принципиально не отличаются от ситуации любого другого приложения. Необходимо следить за потреблением памяти на хранение логов и служебных файлов на диске. Заметьте, что файлы с данными .snap и .xlog возникают даже при использовании движка memtx (в зависимости от настроек). При нормальной работе нагрузка на CPU не должна быть чересчур большой. Исключение составляет момент восстановления данных после рестарта процесса: построение индексов может загрузить все доступные потоки процессора на 100 % на несколько минут.
Потребление RAM удобно разделить на два пункта: Lua-память и память, потребляемая на хранение данных и индексов. Память, доступная для выполнения кода на Lua, имеет ограничение в 2 Gb на уровне Luajit. Обычно приближение метрики к этой границе сигнализирует о наличии какого-то серьёзного изъяна в коде. Более того, зачастую такие изъяны приводят к нелинейному росту используемой памяти, поэтому начинать волноваться стоит уже при переходе границы в 512 Mb на процесс. Например, при высокой нагрузке в наших приложениях показатели редко выходили за предел 200-300 Mb Lua-памяти.
При использовании движка memtx потреблением памяти в рамках заданного лимита memtx_memory (он же — метрика quota_size) заведует slab-аллокатор. Процесс происходит двухуровнево: аллокатор выделяет в памяти ячейки, которые после занимают сами данные или индексы спейсов. Зарезервированная под занятые или ещё не занятые ячейки память отображена в quota_used, занятая на хранение данных и индексов — arena_used (только данных — items_used). Приближение к порогу arena_used_ratio или items_used_ratio свидетельствует об окончании свободных зарезервированных ячеек slab, приближение к порогу quota_used_ratio — об окончании доступного места для резервирования ячеек. Таким образом, об окончании свободного места для хранения данных свидетельствует приближение к порогу одновременно метрик quota_used_ratio и arena_used_ratio. В качестве порога обычно используют значение 90 %. В редких случаях в логах могут появляться сообщения о невозможности выделить память под ячейки или данные даже тогда, когда quota_used_ratio, arena_used_ratio или items_used_ratio далеки от порогового значения. Это может сигнализировать о дефрагментации данных в RAM, неудачном выборе схем спейсов или неудачной конфигурации slab-аллокатора. В такой ситуации необходима консультация специалиста.
Рекомендации по мониторингу HTTP-нагрузки и операций на спейсах также являются скорее общими, нежели специфичными для Tarantool. Необходимо следить за количеством ошибок и временем обработки запроса в зависимости от кода ответа, а также за резким возрастанием нагрузки. Неравномерность нагрузки по операциям на спейсы может свидетельствовать о неудачном выборе ключа шардирования.
Заключение
Как этот материал, так и пакет metrics назвать "всеохватными" и "универсальными" на данный момент нельзя. Открытыми или находящимися на данный момент в разработке являются вопросы метрик репликации, мониторинга движка vinyl, метрики event loop и полная документация по уже существующим методам metrics.
Не стоит забывать о том, что metrics и grafana-dashboard являются opensource-разработками. Если при работе над своим проектом вы наткнулись на ситуацию, которая не покрывается текущими возможностями пакетов, не стесняйтесь внести предложение в Issues или поделиться вашим решением в Pull Requests.
Надеюсь, что данный материал помог закрыть некоторые вопросы, которые могли возникнуть при решении задачи мониторинга приложения на базе Tarantool. А если какие-то из них так и не получили ответа, всегда можно обратиться напрямую в наш чат в Telegram.
Полезные ссылки:
- документация log: ссылка;
- конфигурация параметров log: ссылка;
- модуль tarantool/metrics: ссылка;
- документация по мониторигу: ссылка;
- документация стандратного дашборда Grafana: ссылка;
- проект tarantool/grafana-dashboard: ссылка;
- стандартные дашборды Tarantool для Grafana: InfluxDB, Prometheus;
- проект grafonnet: ссылка;
- скачать Tarantool можно на официальном сайте;
- получить помощь можно в Telegram-чате.
