
Двадцать лет назад Джоэл Спольски написал:
Не существует такой штуки, как «обычный текст».
Если имеется строка, но неизвестно, какую кодировку символов она использует — смысла в этой строке нет. Больше нельзя спрятать голову в песок и притвориться, что «обычный» текст имеет кодировку ASCII.
Многое изменилось за 20 лет. В 2003 году главный вопрос звучал так: «Что это за кодировка?». В 2023 году такой вопрос больше не стоит: с вероятностью в 98% это — UTF-8. Наконец то! Можно снова спрятать голову в песок!
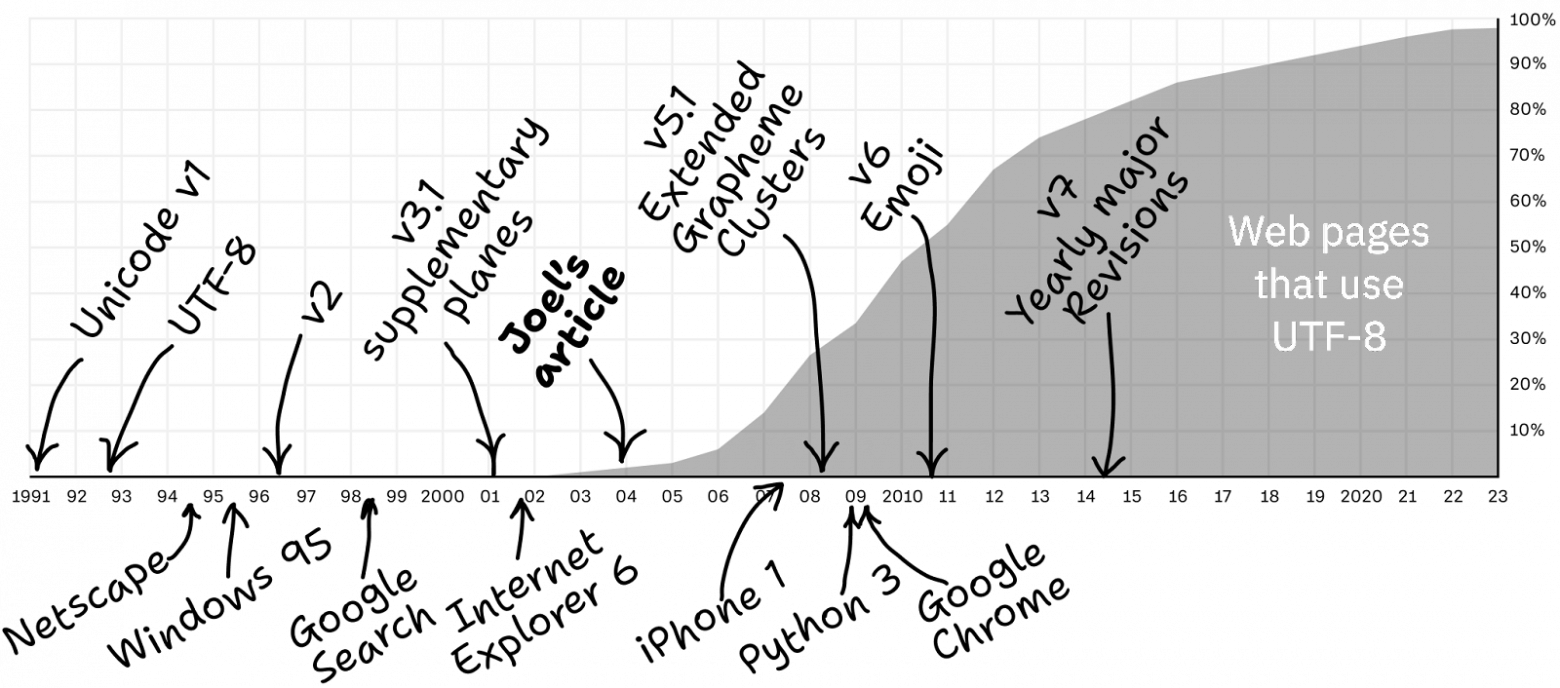
Теперь главный вопрос в том, как правильно пользоваться UTF-8. Давайте это выясним!
Что такое Unicode?
Unicode — это стандарт, цель которого — унифицировать все человеческие языки, и древние, и современные, и сделать так, чтобы ими можно было бы пользоваться в компьютерной среде.
С практической точки зрения Unicode — это таблица, которая назначает уникальные номера различным символам.
Например:
Латинской заглавной букве
Aназначено число65.Арабская буква син
س— это число1587.Буква цу из катаканы
ツ— это12484.Скрипичный ключ
𝄞—119070.💩 — это
128169.
В терминологии Unicode эти числа называются кодовыми точками.
Так как все в мире согласны с тем, какое число соответствует какому символу, и так как все мы согласны использовать Unicode, мы можем читать тексты друг друга.
Unicode == символ ⟷ кодовая точка.
Каковы размеры Unicode?
В настоящее время самая большая определённая кодовая точка имеет номер 0×10FFFF. Это даёт нам пространство из примерно 1,1 миллиона кодовых точек.
Около 170 000, или 15% кодовых точек уже определено. Дополнительные 11% зарезервированы для частного использования. Оставшимся кодовым точкам, которых около 800 000, пока ничего не назначено. Они могут стать символами в будущем.
Вот как, довольно грубо, всё это выглядит.

На этом рисунке большие квадраты (плоскости) представляют наборы из 65536 символов. Маленькие — наборы из 256 символов. Вся таблица ASCII умещается в половину маленького красного квадратика, находящегося в верхнем левом углу рисунка.
Что понимают под «частным использованием» кодовых точек?
Речь идёт о кодовых точках, зарезервированных для разработчиков приложений. Эти кодовые точки никогда не будут использоваться для нужд самого стандарта Unicode.
Например, в Unicode нет стандартного места для логотипа компании Apple. Поэтому Apple поместила соответствующий значок по адресу U+F8FF, который находится в блоке кодовых точек, выделенных для частного использования. При использовании шрифта, который поставляется с macOS, эта кодовая точка выведется как значок ![]() . А в тексте, оформленном шрифтом, который этот значок не поддерживает, вместо него будет выведен символ отсутствующего глифа —
. А в тексте, оформленном шрифтом, который этот значок не поддерживает, вместо него будет выведен символ отсутствующего глифа — .
.
Область Unicode, выделенная под частное использование, содержит, в основном, шрифты, состоящие из значков.
Что означает конструкция U+1F4A9?
Это — пример применения правила записи значений кодовых точек. Здесь U+ означает, как можно догадаться, Unicode, а 1F4A9 — это шестнадцатеричный номер кодовой точки.
И U+1F4A9 — это символ 💩.
А что же такое тогда UTF-8?
UTF-8 — это кодировка. Кодировка — это описание того, как кодовые точки хранятся в памяти.
Самая простая кодировка для Unicode — это UTF-32. При её использовании кодовые точки хранятся в виде 32-битных целых чисел. В результате U+1F4A9 становится 00 01 F4 A9, занимая четыре байта. Любая другая кодовая точка в кодировке UTF-32 тоже займёт четыре байта. Так как самая большая из определённых кодовых точек — это U+10FFFF, такой подход гарантирует то, что с его помощью можно записать любую кодовую точку.
Кодировки UTF-16 и UTF-8 устроены уже не так просто, но конечная цель их применения остаётся той же самой, что и в случае с UTF-32: взять кодовую точку и закодировать её неким набором байтов.
Кодировка символов — это как раз и есть то, с чем работают программисты.
Сколько байтов используется в UTF-8?
UTF-8 — это кодировка символов переменной длины. Кодовая точка может быть представлена в виде последовательности длиной от одного до четырёх байтов.
Вот как она устроена:
Кодовая точка | Байт 1 | Байт 2 | Байт 3 | Байт 4 |
U+0000..007F | 0xxxxxxx | |||
U+0080..07FF | 110xxxxx | 10xxxxxx | ||
U+0800..FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+10000..10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
Если скомбинировать это с таблицей Unicode — можно увидеть, что символы английского языка кодируются с помощью 1 байта. В кириллице и в латиноевропейских языках, в иврите и в арабском языке используются 2 байта. В китайском, японском, корейском и в других азиатских языках, а так же — для представления эмодзи, используются 3 или 4 байта.
Тут мне хотелось бы обратить ваше внимание на несколько важных моментов.
Во‑первых — кодировка UTF-8, на уровне байтов, совместима с ASCII. Кодовые точки 0..127, то есть — то, что изначально входило в ASCII, кодируются с помощью одного байта. И это — в точности тот же байт, что и в ASCII. Например, U+0041 (A, латинская заглавная буква A) — это просто шестнадцатеричное число 41, на хранение этого кода нужен один байт.
Любой обычный ASCII‑текст — это ещё и корректный UTF-8 текст, а любой UTF-8-текст, в котором используются только кодовые точки 0..127, может быть напрямую прочитан так, будто он закодирован в ASCII.
Во‑вторых — UTF-8 позволяет эффективно хранить простые тексты на языках, использующих латинские буквы. Это — одно из главных преимуществ UTF-8 перед UTF-16. Это может быть не так для текстов, написанных в разных уголках мира, но в этом есть смысл при работе со строками, использующимися в технических целях, вроде HTML‑тегов или JSON‑ключей.
В целом, UTF-8, как правило — это очень хороший выбор для компьютеров, на которых используются языки, отличающиеся от английского. А на компьютерах, где основной язык — английский, этой кодировке нет равных.
В‑третьих — в UTF-8 имеются встроенные механизмы обнаружения ошибок и борьбы со сбоями. Префикс первого байта всегда отличается от байтов 2–4. При таком подходе всегда можно определить, что именно перед нами — полная и корректная последовательность UTF-8 байтов, или код, в котором что‑то не так (например — если начать разбор текста с середины последовательности). Поняв, что что‑то не так, можно исправиться, двигаясь к концу или к началу некоего фрагмента кода до тех пор, пока не будет найдено начало корректной последовательности.
Вот несколько важных выводов из вышесказанного:
НЕ ПОЛУЧИТСЯ определить длину строки, подсчитывая байты.
НЕ ПОЛУЧИТСЯ перейти в случайную позицию строки и начать считывание корректных данных.
НЕ ПОЛУЧИТСЯ извлечь из строки подстроку, вырезав из неё произвольную последовательность байтов. Так можно отрезать от строки часть кода некоего символа.
Те, кто, всё же, нарушают эти правила, в итоге сталкиваются с вот такой штуковиной: �.
Что такое �?
U+FFFD — это так называемый «заменяющий символ», по сути — одна из кодовых точек в таблице Unicode. Приложения и библиотеки могут использовать его в случаях, когда они обнаруживают ошибки в Unicode.
Если разрезать кодовую точку пополам — с её куском особо ничего не сделаешь — останется только показать символ ошибки. Именно в таких ситуациях и используется знак �.
var bytes = "Аналитика".getBytes("UTF-8");
var partial = Arrays.copyOfRange(bytes, 0, 11);
new String(partial, "UTF-8"); // => "Анал�"Разве использование UTF-32 не облегчило бы всем жизнь?
Нет.
Кодировка UTF-32 хороша для выполнения различных операций над кодовыми точками. В самом деле: если каждая кодовая точка всегда представлена 4 байтами, тогда strlen(s) == sizeof(s) / 4, substring(0, 3) == bytes[0, 12] и так далее.
Проблема тут в том, что программистам не нужно работать с кодовыми точками. Кодовая точка — это не единица осмысленного текста; одна кодовая точка не всегда соответствует одному символу. Программистов, например, при переборе содержимого строк, интересуют так называемые «расширенные графемные кластеры», которые для краткости называют «графемами».
Графема — это минимально различимая единица письма в контексте конкретной системы письменности. ö — это одна графема. é — тоже одна. И 각 — тоже. Получается, что графема — это то, что пользователь воспринимает, как один символ.
Проблема тут в том, что в Unicode некоторые графемы кодируются с использованием нескольких кодовых точек.

Например, é (одна графема) кодируется в Unicode как e (U+0065 латинская маленькая буква E) + ´ (U+0301 комбинированный акут (лёгкое ударение)). Две кодовые точки!
Кодовых точек может быть и больше, чем две:
☹️ — это
U+2639 + U+FE0F.👨🏭 — это
U+1F468 + U+200D + U+1F3ED.🚵🏻♀️ — это
U+1F6B5 + U+1F3FB + U+200D + U+2640 + U+FE0F. — это
— это U+0079 + U+0316 + U+0320 + U+034D + U+0318 + U+0347 + U+0357 + U+030F + U+033D + U+030E + U+035E.
Насколько мне известно — предела нет.
Не забывайте — мы тут говорим о кодовых точках. Даже при использовании самой «широкой» кодировки, UTF-32, на представление 👨🏭 потребуется три 4-байтных блока. И это не отменяет того факта, что этот значок надо рассматривать как один символ.
Если прибегнуть к аналогии, то сам Unicode (без учёта наличия каких-либо кодировок) можно воспринимать как стандарт, в котором используются коды переменной длины.
Расширенный графемный кластер — это последовательность, состоящая из одной или нескольких кодовых точек Unicode, которую нужно рассматривать как самостоятельный, неделимый символ.
В результате мы сталкиваемся со всеми теми проблемами, которые характерны для работы с кодировками переменной длины, но теперь они проявляются на уровне кодовых точек. Нельзя работать лишь с частями последовательностей. Последовательности всегда надо выделять, копировать, редактировать как единое целое.
Несоблюдение правил по работе с графемными кластерами ведёт к багам, похожим на этот:

Или на этот:
Просто для ясности: это — НЕПРАВИЛЬНОЕ поведение
Использование UTF-32 вместо UTF-8 никак не облегчает долю программиста в плане обработки расширенных графемных кластеров. И именно расширенные графемные кластеры — это то, что должно заботить программиста.
Кодовые точки — 🥱. Графемы — 😍.
Сложность работы с Unicode связана только с эмодзи?
На самом деле — нет. Расширенные графемные кластеры актуальны и для представления символов, применяющихся в живых, активно используемых языках. Например:
ö (немецкий язык) — это один символ, но несколько кодовых точек (
U+006F U+0308).ą́ (литовский язык) — это
U+00E1 U+0328.각 (корейский язык) — это
U+1100 U+1161 U+11A8.
Так что сложность работы с Unicode связана не только с эмодзи.
Какова длина 🤦♂️?
На этот вопрос меня вдохновила эта замечательная статья. Разные языки программирования, нисколько не смущаясь, дадут на него разные ответы.
Python 3:
>>> len("🤦♂️")
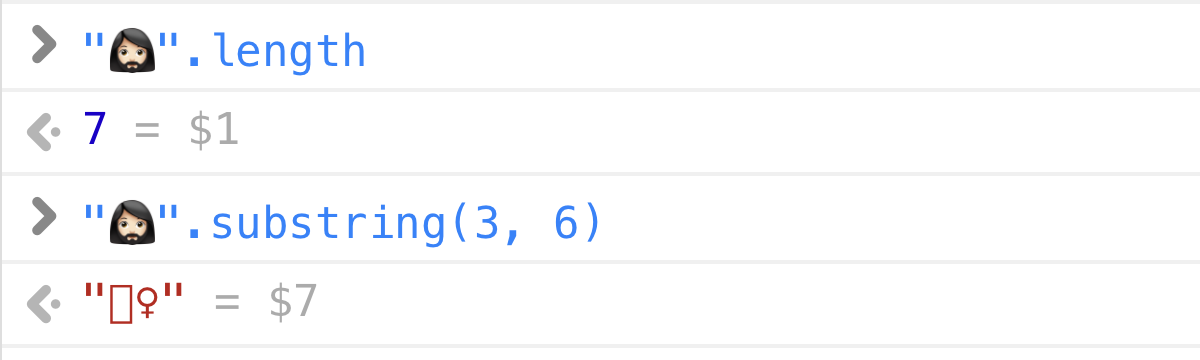
5JavaScript / Java / C#:
>> "🤦♂️".length
7Rust:
println!("{}", "🤦♂️".len());
// => 17Как можно догадаться, разные языки программирования используют различные внутренние представления строк (UTF-32, UTF-16, UTF-8) и выводят сведения о длине строки в тех единицах, в которых они хранят символы (целые числа, короткие целые числа, байты).
Но! Если спросить любого обычного человека, того, который не отягощён знаниями о внутреннем устройстве компьютерных систем, он даст прямой ответ: 1. Длина строки 🤦♂️ — 1.
Именно в этом — вся суть расширенных графемных кластеров: это — то, что люди воспринимают в виде одного символа. И в данном случае 🤦♂️ — это, без сомнения, один символ.
Тот факт, что символ 🤦♂️ состоит из 5 кодовых точек (U+1F926 U+1F3FB U+200D U+2642 U+FE0F) — лишь деталь реализации. Эту конструкцию не нужно разбивать на части, её не нужно считать состоящей из нескольких символов. Текстовый курсор не должен позиционироваться внутри неё, у пользователя не олжно быть возможности выделить часть этой конструкции и так далее…
Что бы ни двигало разработчиком, какие бы цели перед ним ни стояли, этот символ должен представлять собой неделимую единицу текста. В недрах программы он может быть закодирован как угодно, но для API, с которым взаимодействуют пользователи, он должен быть представлен в виде цельной, неделимой сущности.
Лишь два современных языка программирования правильно находят длину этого символа.
Первый — это Swift:
print("🤦♂️".count)
// => 1Второй — Elixir:
String.length("🤦♂️")
// => 1В целом, тут имеются два слоя абстракции:
Внутренний, ориентированный на компьютеры. Он рассчитан на такие задачи, как копирование строк, пересылка их по сети, сохранение на диск и так далее. Именно тут и нужны кодировки наподобие UTF-8. Внутри Swift используется UTF-8, но это может быть и UTF-16, и UTF-32. Важно то, чтобы на этом уровне знания о кодировках использовались бы лишь для копирования строк как единого целого, а не для анализа их содержимого.
Внешний, нацеленный на человека. Среди задач, решаемых с его помощью, можно выделить следующие: подсчёт символов в пользовательском интерфейсе, извлечение первых 10 символов текста для создания превью, поиск в тексте, реализация методов вроде
.countили.substring. Swift даёт программисту представление, которое создаёт ощущение того, что строка — это последовательность графемных кластеров. И это представление ведёт себя так, как может ожидать человек — а именно, выдаёт 1 при выполнении команды "🤦♂️".count.
Надеюсь, такой подход к работе со строками в ближайшее время будет реализован и в других языках программирования.
Теперь у меня вопрос к читателям. Как вы думаете — что должна выдать такая команда?

Как же тогда обнаруживать графемные кластеры?
К сожалению, создатели большинства языков программирования особо себя не утруждают и позволяют программистам перебирать строки блоками из 1–2–4 байтов, не принимая во внимание графемные кластеры.
В этом нет смысла. У «символов», полученных при такой обработке, может просто не быть никаких значений. Но так как это — поведение, реализуемое по умолчанию, программисты особо об этом не задумываются, что, в результате, приводит к появлению тут и там повреждённых строк:
Никто и никогда не говорит о том, что для выполнения команды strlen() будет использовать библиотеку.
А ведь поступать стоит именно так! Эти проблемы решает использование подходящей библиотеки для работы с Unicode. Повторюсь: для выполнения простейших команд вроде strlen, indexOf или substring нужна библиотека!
Например:
C/C++/Java: используйте ICU. Это — библиотека, созданная разработчиками Unicode. В ней реализованы все правила сегментации текста.
C#: используйте
TextElementEnumerator. Этот класс, насколько я знаю, поддерживается в актуальном состоянии, отражающем последние изменения в Unicode.Swift: используйте стандартную библиотеку. В Swift всё сделано как надо на уровне языка.
Обновление: Erlang/Elixir, похоже, тоже ведут себя правильно.
Для других языков, вероятно, можно найти подходящую библиотеку или привязку для ICU.
Создайте собственную библиотеку. Разработчики Unicode публикуют правила и таблицы в машиночитаемом формате. Все вышеперечисленные библиотеки основаны на этих материалах.
Но, что бы вы ни выбрали, проверьте, чтобы это было основано на достаточно свежей версии Unicode (15.1 в момент написания этой статьи), так как определения графем меняются от версии к версии. Исходя из этого соображения, например, не стоит пользоваться java.text.BreakIterator, так как этот класс основан на очень старой версии Unicode и не обновляется.
Пользуйтесь библиотекой.
По моему мнению, вся эта ситуация — позор для ИТ-индустрии. Поддержка Unicode должна, без всяких условий, присутствовать в стандартной библиотеке каждого языка. Ведь Unicode — это «лингва франка» интернета! И этот стандарт даже не относится к новым: мы живём с ним уже 20 лет!
Погодите, правила меняются?
Да! Разве это не прекрасно?
(Знаю — совсем не прекрасно).
Начиная примерно с 2014 года организация, ответственная за Unicode, выпускает старшие версии стандарта каждый год. Именно отсюда мы и добываем новые эмодзи — обновления Android и iOS, выходящие осенью, обычно включают в себя, кроме прочего, поддержку самого нового стандарта Unicode.
Нас с вами всё это печалит из‑за того, что каждый год меняются и правила определения графемных кластеров. То, что сегодня считается последовательностью из двух или трёх отдельных кодовых точек, завтра может стать графемным кластером. И узнать заранее об этом нельзя! Подготовиться к этому тоже не получится!
Но ситуация ещё хуже, так как разные версии вашего собственного приложения могут быть основаны на разных версиях стандарта Unicode и выдавать разные сведения о длинах одних и тех же строк!
Но это — та реальность, в которой мы живём. И тут у нас, на самом деле, нет выбора. Тот, кто хочет, чтобы его проект оставался бы актуальным и обеспечивал бы пользователям достойные впечатления от работы с ним, просто не может игнорировать стандарт Unicode или его обновления. Поэтому — пристёгиваем ремни, выезжаем навстречу новшествам с открытым забралом и обновляемся.
Ежегодно обновляйтесь.
Почему "Å" !== "Å" !== "Å"?

Скопируйте любое из этих сравнений в свою JavaScript-консоль.
"Å" === "Å"
"Å" === "Å"
"Å" === "Å"Что получилось? False? Это не ошибка. У вас и должно получиться False.
Помните, я рассказывал о том, что буква ö состоит из двух кодовых точек — U+006F U+0308? В общем случае Unicode предлагает несколько способов записи символов вроде ö или Å. А именно:
Можно собрать символ
Åиз обычного латинского A и комбинируемого символа.Или можно переложить решение этой задачи на создателей Unicode и воспользоваться предварительно составленным символом с кодовой точкой
U+00C5.
Получившиеся символы будут выглядеть одинаково (Å и Å), функционировать они тоже должны одинаково. И они, во всех отношениях, считаются в точности одинаковыми. Единственная разница между ними — их байтовое представление.
Именно поэтому нам и нужна нормализация Unicode. Существует четыре формы (алгоритма) такой нормализации:
NFD — пытается разбить всё на как можно более маленькие части, и, кроме того, отсортировать эти части в каноническом порядке в том случае, если их больше одной.
NFC, с другой стороны, пытается скомбинировать всё, что можно, сгруппировав это в виде предварительно составленных символов, если таковые существуют.
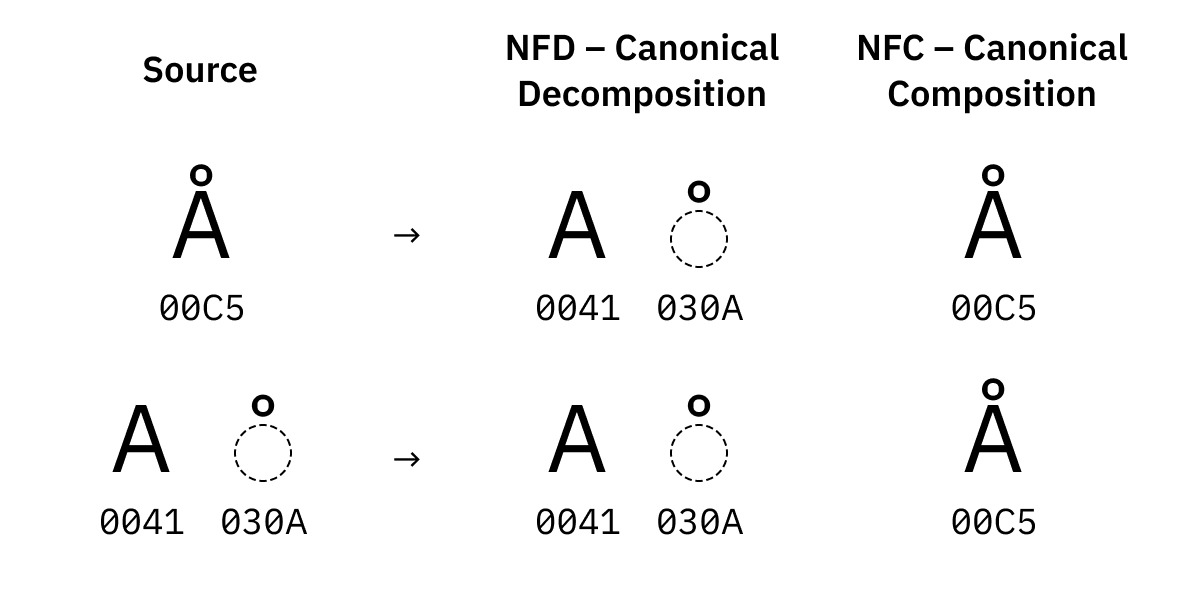
В Unicode есть символы, существующие в нескольких вариантах. Например, есть символ U+00C5 (латинская заглавная буква A с кружочком сверху) и U+212B (знак ангстрема), которые выглядят одинаково.
Такие символы тоже подвергаются замене в ходе нормализации:

NFD и NFC называют «канонической нормализацией». Две другие формы нормализации называют «совместимой нормализацией»:
NFKD — пытается разбить всё на части и заменить визуальные варианты на те, что применяются по умолчанию.
NFKC — пытается всё скомбинировать, заменяя при этом визуальные варианты на те, что применяются по умолчанию.

Визуальные варианты — это отдельные кодовые точки Unicode, которые представляют один и тот же символ, но должны выводиться по‑разному. Например — это ①, или ⁹, или 𝕏. Ведь нам хотелось бы иметь возможность найти в строке, вроде "𝕏²", и "x" и "2".

А почему у лигатуры fi имеется собственная кодовая точка? Не имею ни малейшего понятия. Многое может появиться в наборе из миллиона символов.
Нормализуйте строки, прежде чем сравнивать их друг с другом, или выполнять поиск подстрок!
Unicode чувствителен к региональным настройкам
Имя «Николай» на русском языке выглядит так:
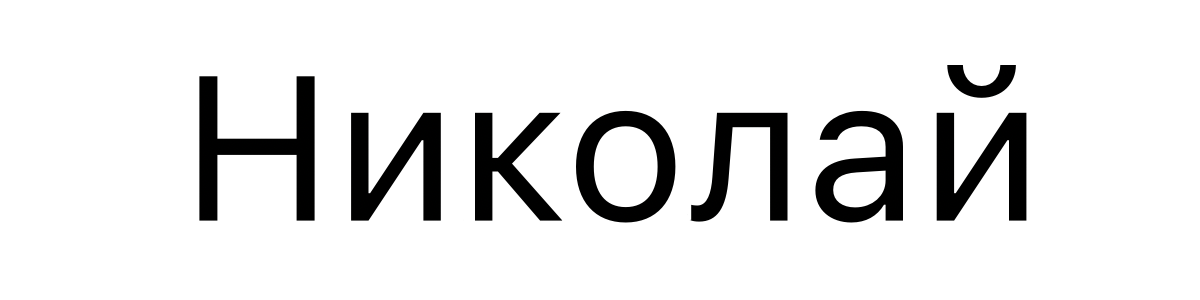
В Unicode оно кодируется следующим образом: U+041D 0438 043A 043E 043B 0430 0439.
А такое же имя на болгарском выглядит так:

Вот — его Unicode‑код: U+041D 0438 043A 043E 043B 0430 0439. Коды у этих строк абсолютно одинаковые!
А подождите‑ка! Откуда компьютер знает о том, когда ему выводить глифы в болгарском стиле, а когда — в русском?
Если коротко — то он об этом и не знает. К сожалению, Unicode — это не идеальная система. Она имеет множество изъянов. Среди них — назначение одних и тех же кодовых точек глифам, которые должны выглядеть по‑разному. Это, например, кириллическая строчная буква K и болгарская строчная буква К (обе представлены кодом U+043A).
Насколько я понимаю, у жителей Азии всё ещё хуже: многие китайские, японские и корейские логограммы, написание которых очень сильно различается, представлены одной и той же кодовой точкой:

Полагаю, это отражает стремление организации, которая занимается поддержкой Unicode, к экономии пространства кодовых точек. Информация о том, как визуализировать тот или иной символ, должна быть размещена вне строки, в виде метаданных о региональных настройках/языке.
[...] для представления любого символа на любом языке не требуется применять управляющие последовательности или управляющие коды.
На практике зависимость от региональных настроек несёт с собой множество проблем:
Так как региональные настройки — это метаданные, они часто теряются.
Люди не ограничены единственными региональными настройками. Например, я могу читать и писать тексты на английском (USA и UK), на немецком и на русском языках. Какие региональные настройки мне надо установить на компьютере?
Сложно сочетать и комбинировать символы. Например, это относится к русским именам в болгарском тексте или к болгарским именам в тексте русском. Почему нет? Это — интернет, тут присутствуют представители самых разных культур.
Не предусмотрено наличие стандартного механизма для указания региональных настроек. Даже для того чтобы сделать два скриншота, показанных ранее, мне пришлось постараться, так как в большинстве программ нет чего‑то вроде выпадающего списка или поля ввода для выбора региональных настроек.
Когда для вывода текста нужны сведения о региональных настройках, программы вынуждены о них догадываться. Например, Twitter пытается догадаться о том, какие региональные настройки применить, на основании самого текста твита (а откуда ещё их ему взять?), что иногда приводит к ошибкам.

Почему String::toLowerCase() принимает в качестве аргумента Locale?
Ещё один печальный пример зависимости Unicode от региональных настроек — обработка i без точки в турецком языке.
В отличие от английского, в турецком имеется два варианта I: с точкой и без точки. Создатели Unicode решили повторно использовать I и i из ASCII и добавили в таблицу всего две новых кодовых точки — İ и ı.
К сожалению, это привело к тому, что команды toLowerCase/toUpperCase по-разному ведут себя на одних и тех же входных данных:
var en_US = Locale.of("en", "US");
var tr = Locale.of("tr");
"I".toLowerCase(en_US); // => "i"
"I".toLowerCase(tr); // => "ı"
"i".toUpperCase(en_US); // => "I"
"i".toUpperCase(tr); // => "İ"Поэтому мы не можем преобразовать строку к нижнему регистру, не зная о том, на каком языке эта строка написана.
Я живу в US/UK. Надо ли мне вообще о таком задумываться?
Вообще‑то — надо. Даже в тексте, написанном на чистом английском языке, всё ещё используется множество «типографских знаков», которых нет в ASCII.

Например:
Кавычки “ ” ‘ ’,
Апостроф ’,
Тире – —,
Разные варианты пробелов (цифровой пробел, самый тонкий пробел, неразрывный пробел),
Маркеры абзацев • ■ ☞,
Символы валют, отличные от $ (это вроде как намекает на тех, кто изобрёл компьютеры, правда?): € ¢ £,
Математические знаки — «плюс» + и «равно» = — это часть ASCII, а знак «минус» − и знак умножения × — нет ¯\_(ツ)_/¯,
Разные другие знаки © ™ ¶ † §.
Да чёрт! Нельзя даже написать слова café, piñata или naïve без Unicode. Поэтому да — все мы в одной лодке, даже американцы.
Touché.
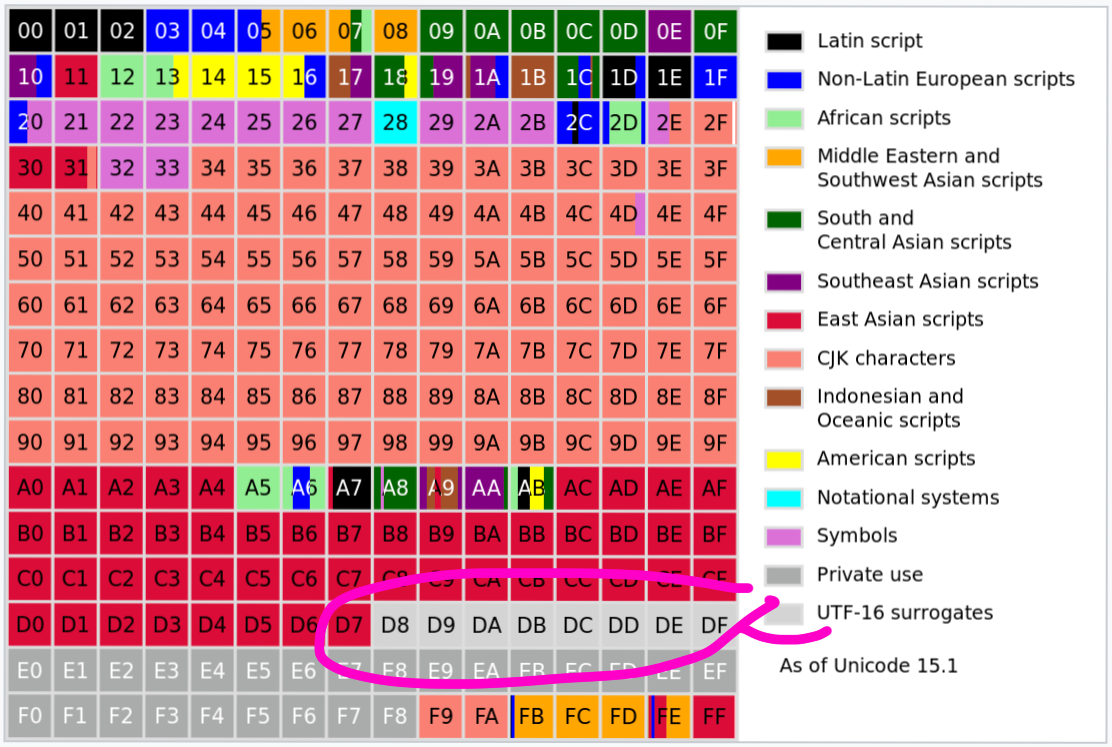
Что такое суррогатные пары?
Эта тема восходит к Unicode v1. Первая версия Unicode планировалась как система, содержащая коды фиксированной ширины. А если точнее, речь шла о фиксированной ширине кодов, равной 16 битам.

Создатели Unicode считали, что 65 536 символов будет достаточно для всех человеческих языков. И они были почти правы!
Когда стало понятно, что нужно больше кодовых точек, UCS-2 (исходная версия UTF-16 без суррогатов) уже использовалась во многих системах. 16 битов и фиксированная ширина поля дают только 65 536 символов. Что тут можно сделать?
Разработчики Unicode решили выделить некоторые из этих 65 536 символов для описания дополнительных кодовых точек, что, по сути, привело к преобразованию кода UCS-2 с фиксированной шириной в код с переменной шириной UTF-16.
Суррогатная пара — это два значения UTF-16, используемые для описания одной кодовой точки Unicode. Например, D83D DCA9 (два 16-битных значения) описывают одну кодовую точку — U+1F4A9.
Верхние 6 битов суррогатной пары используются в роли маски, оставляя 2×10 битов в запасе.
High Surrogate Low Surrogate
D800 ++ DC00
1101 10?? ???? ???? ++ 1101 11?? ???? ????С технической точки зрения обе половины суррогатной пары тоже могут рассматриваться как кодовые точки Unicode. На практике весь диапазон кодов от U+D800 до U+DFFF выделен «исключительно для суррогатных пар». Кодовые точки из этого диапазона даже не признаются корректными в любых других кодировках.
Кодировка UTF-16 всё ещё жива?
Да!
Перспектива существования кодировки с фиксированной шириной, в которую поместятся все человеческие языки, была столь привлекательной, что создатели многих систем загорелись желанием как можно быстрее её у себя внедрить. Среди этих систем — Microsoft Windows, Objective‑C, Java, JavaScript,.NET, Python 2, QT, SMS и CD‑ROM!
С тех пор Python пошёл дальше, CD‑ROM устарел, а вот остальные системы так и застряли на UTF-16, или даже на UCS-2. Поэтому кодировка UTF-16 всё ещё живёт рядом с нами в виде представления данных в памяти.
С практической точки зрения, в наши дни UTF-16 почти так же удобно пользоваться, как и UTF-8. Это — тоже кодировка переменной длины. Подсчёт единиц UTF-16 так же бесполезен, как подсчёт байтов или кодовых точек. Работа с графемными кластерами — тоже проблема. Этот список можно продолжать. Главное отличие UTF-16 от UTF-8 заключается в требованиях к памяти.
Единственный недостаток UTF-16 заключается в том, что всё, что окружает систему, использующую эту кодировку, применяет UTF-8. Поэтому каждый раз, когда строка читается из сети или с диска, нужно применять конверсию.
А вот — интересный факт: количество плоскостей, которое имеется в Unicode (17) выбрано на основе того количества символов, которое можно задать с помощью суррогатных пар в кодировке UTF-16.
Итоги
Стандарт Unicode завоевал мир.
UTF-8 — это самая популярная кодировка для передачи и хранения данных.
Кодировка UTF-16 всё ещё иногда используется для представления данных в памяти.
Два самых важных представления строк — это байтовое представление (выделение памяти, копирование, кодирование, декодирование) и представление в виде расширенных графемных кластеров (все операции, для выполнения которых нужно учитывать семантику строк).
Использование кодовых точек для перебора содержимого строк — это неправильно. Кодовые точки — это не основные единицы письменного текста. Одна графема может состоять из нескольких кодовых точек.
Для выявления границ графем нужны таблицы Unicode.
Используйте подходящую библиотеку для выполнения всех операций, связанных с Unicode, даже для таких тривиальных задач, как те, что решаются командами strlen, indexOf и substring.
Обновления Unicode выходят каждый год, правила иногда меняются.
Строки Unicode нужно подвергать нормализации прежде чем их можно будет сравнивать.
Unicode зависит от региональных настроек при выполнении некоторых операций и при выводе текстов на экран.
Всё это важно даже для текстов, написанных исключительно на английском языке.
В целом можно сказать, что стандарт Unicode далёк от совершенства. При этом надо понимать, что существование стандарта, отличающегося следующими свойствами — это что‑то, близкое к чуду:
Этот стандарт включает в себя сразу все символы всех существующих языков.
Весь мир пришёл к согласию по поводу применения этого стандарта.
Его использование позволяет полностью забыть о кодировках, о преобразованиях и о прочем подобном.
Отправьте эту статью своим коллегам‑программистам, чтобы они тоже смогли узнать кое‑что об Unicode.
Существует такая штука, как «обычный текст». Это — текст, закодированный с помощью UTF-8.
О, а приходите к нам работать? 🤗 💰
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
