

В октябре прошлого года состоялась первая облачная конференция Яндекса Yandex Scale. На ней было объявлено о запуске множества новых сервисов, в том числе Yandex IoT Core, который позволяет обмениваться данными с миллионами устройств Интернета вещей.
В этой статье я расскажу о том, зачем нужен и как устроен Yandex IoT Core, а также каким образом он может взаимодействовать с другими сервисами Яндекс.Облака. Вы узнаете об архитектуре, тонкостях взаимодействия компонентов и особенностях реализации функциональности — всё это поможет вам оптимизировать использование этих сервисов.
Для начала вспомним основные преимущества публичных облаков и PaaS — сокращение времени и затрат на разработку, а также затрат на поддержку и инфраструктуру, что актуально и для проектов Интернета вещей. Но есть и несколько менее очевидных полезных особенностей, которые вы можете получить в облаке. Это эффективное масштабирование и отказоустойчивость — важные аспекты при работе с устройствами, особенно в проектах для критической информационной инфраструктуры.
Эффективное масштабирование — это возможность свободно как увеличивать, так и уменьшать количество устройств, не испытывая технических проблем и видя предсказуемое изменение стоимости системы после изменений.
Отказоустойчивость — это уверенность в том, что сервисы спроектированы и развёрнуты таким образом, чтобы обеспечивать максимально возможную работоспособность даже в случае отказа части ресурсов.
А теперь давайте разберёмся в деталях.
Архитектура IoT-сценария
Прежде всего посмотрим, как выглядит общая архитектура IoT-сценария.
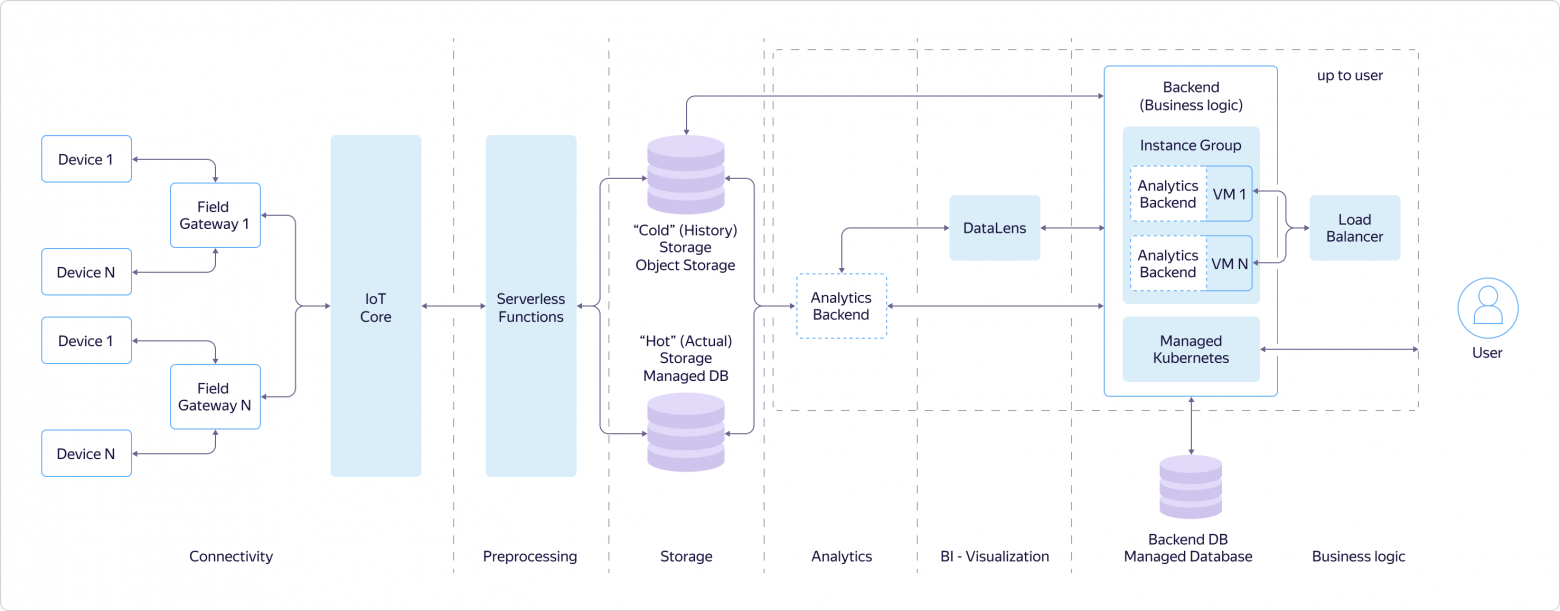
В ней можно выделить две большие части:
- Первая — доставка данных в хранилище и доставка команд к устройствам. Когда вы строите IoT-систему, эту задачу необходимо решить в любом случае, какой бы проект вы не делали.
- Вторая — работа с принятыми данными. Тут всё похоже на любой другой проект, основанный на анализе и визуализации наборов данных. У вас есть хранилище с исходным массивом информации, работа с которым и позволит реализовать вашу задачу.
Первая часть примерно одинакова во всех IoT-системах: строится по общим принципам и ложится в общий сценарий, пригодный для большинства систем Интернета вещей.
Вторая часть практически всегда уникальна с точки зрения выполняемых функций, хотя и строится на стандартных компонентах. При этом без качественной, отказоустойчивой и масштабируемой системы взаимодействия с «железом» эффективность аналитической части архитектуры сводится практически к нулю, так как просто нечего будет анализировать.
Именно поэтому команда Яндекс.Облака приняла решение в первую очередь сосредоточить усилия на построении удобной экосистемы сервисов, позволяющих быстро, эффективно и надёжно доставлять данные от устройств в хранилища, и наоборот — отправлять команды в устройства.
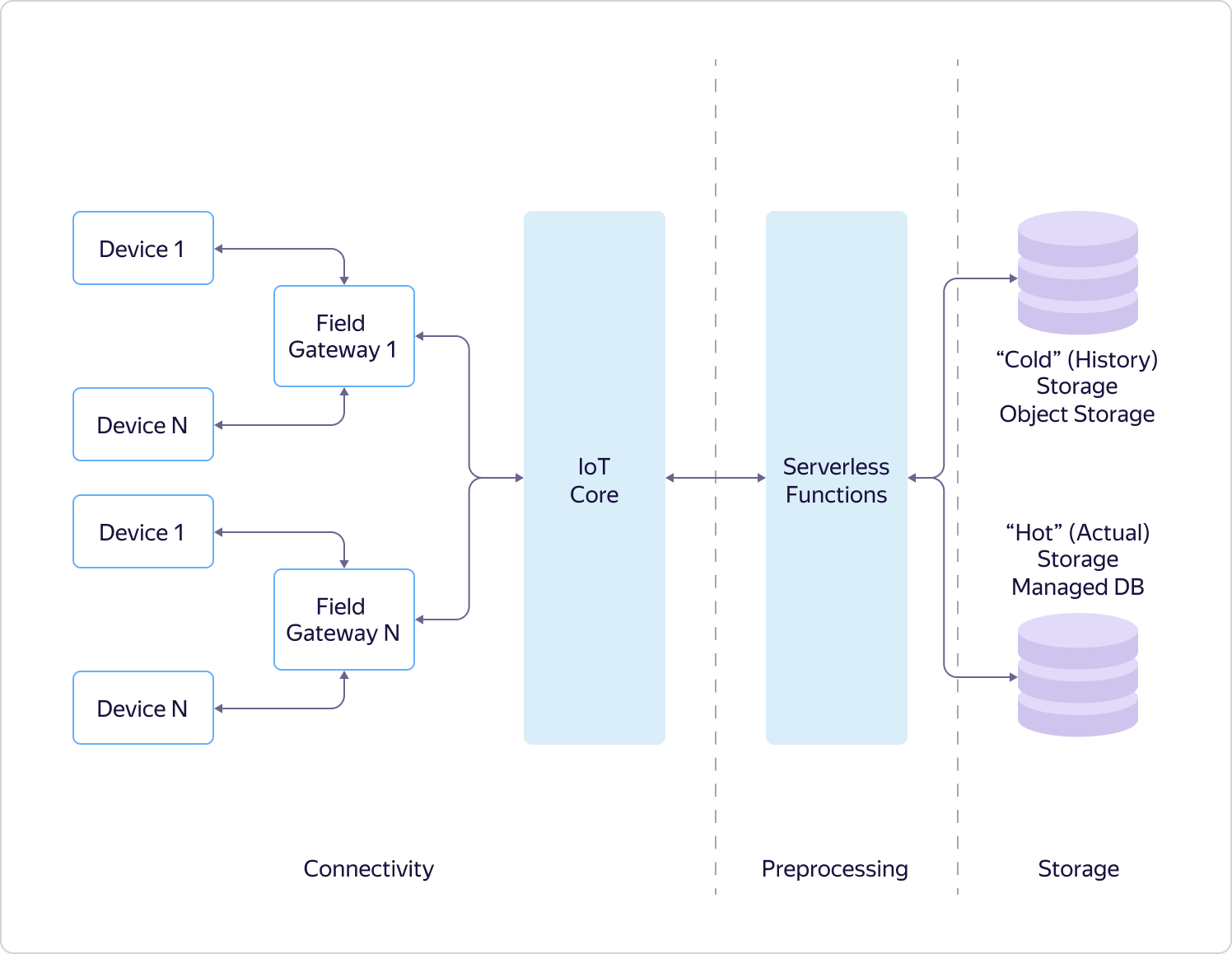
Для решения этих задач мы работаем над функциональностью и интеграцией сервисов Yandex IoT Core, Yandex Functions и хранилищ данных в Облаке:
- Сервис Yandex IoT Core представляет собой мультитенантный отказоустойчивый масштабируемой MQTT-брокер с набором дополнительных полезных функций.
- Сервис Yandex Cloud Functions является представителем перспективного направления serverless и позволяет запускать ваш код в виде функции в безопасном, отказоустойчивом и автоматически масштабируемом окружении без создания и обслуживания виртуальных машин.
- Yandex Object Storage — это эффективное хранилище больших массивов данных и очень хорошо подходит для «исторических» архивных записей.
- В Облаке существует целое семейство сервисов для хранения и анализа данных, практически на любой вкус, но я хочу отметить сервис Yandex Managed Service for ClickHouse, как один из примеров «управляемых» баз данных. Это сервис для развёртывания и управления «колоночной» базой данных с открытым исходным кодом, имеющим встроенную функциональность работы с временными рядами, что актуально для оперативных данных, на базе которых обычно и нужно проводить большую часть анализа и строить отчёты.
Если сервисы хранения и анализа данных являются сервисами «общего назначения», о которых уже много написано, то Yandex IoT Core и его взаимодействие с Yandex Cloud Functions обычно вызывают много вопросов, особенно у людей, только начинающих разбираться с системами Интернета вещей и облачными технологиями. А так как именно эти сервисы обеспечивают отказоустойчивость и масштабирование работы с устройствами, посмотрим сначала, что у них «под капотом».
Как устроен Yandex IoT Core
Yandex IoT Core — это специализированный платформенный сервис для двустороннего обмена данными между облаком и устройствами, работающими по протоколу MQTT. Фактически этот протокол стал стандартом передачи данных в IoT. Он использует понятие поименованных очередей (топиков), куда, с одной стороны, вы можете записывать данные, а с другой стороны — асинхронно их получать, подписавшись на события этой очереди.
Сервис Yandex IoT Core является мультитенантным, что означает одну-единственную сущность, доступную для всех пользователей. То есть все устройства и все пользователи взаимодействуют с одним и тем же экземпляром сервиса.
Это позволяет, с одной стороны, обеспечить единообразие работы для всех пользователей, с другой — эффективное масштабирование и отказоустойчивость, чтобы поддерживать соединение с неограниченным количеством устройств и обрабатывать неограниченное как по объёму, так и по скорости количество данных.
Из этого следует, что у сервиса должны быть как механизмы резервирования, так и возможность гибкого управления используемыми ресурсами — чтобы реагировать на изменение нагрузки.
Кроме того, мультитенантность требует специальной логики разделения прав доступа к MQTT-топикам.
Давайте посмотрим, каким образом это реализовано.
Как и многие другие сервисы Яндекс.Облака, Yandex IoT Core логически поделён на две части — Control Plane и Data Plane:
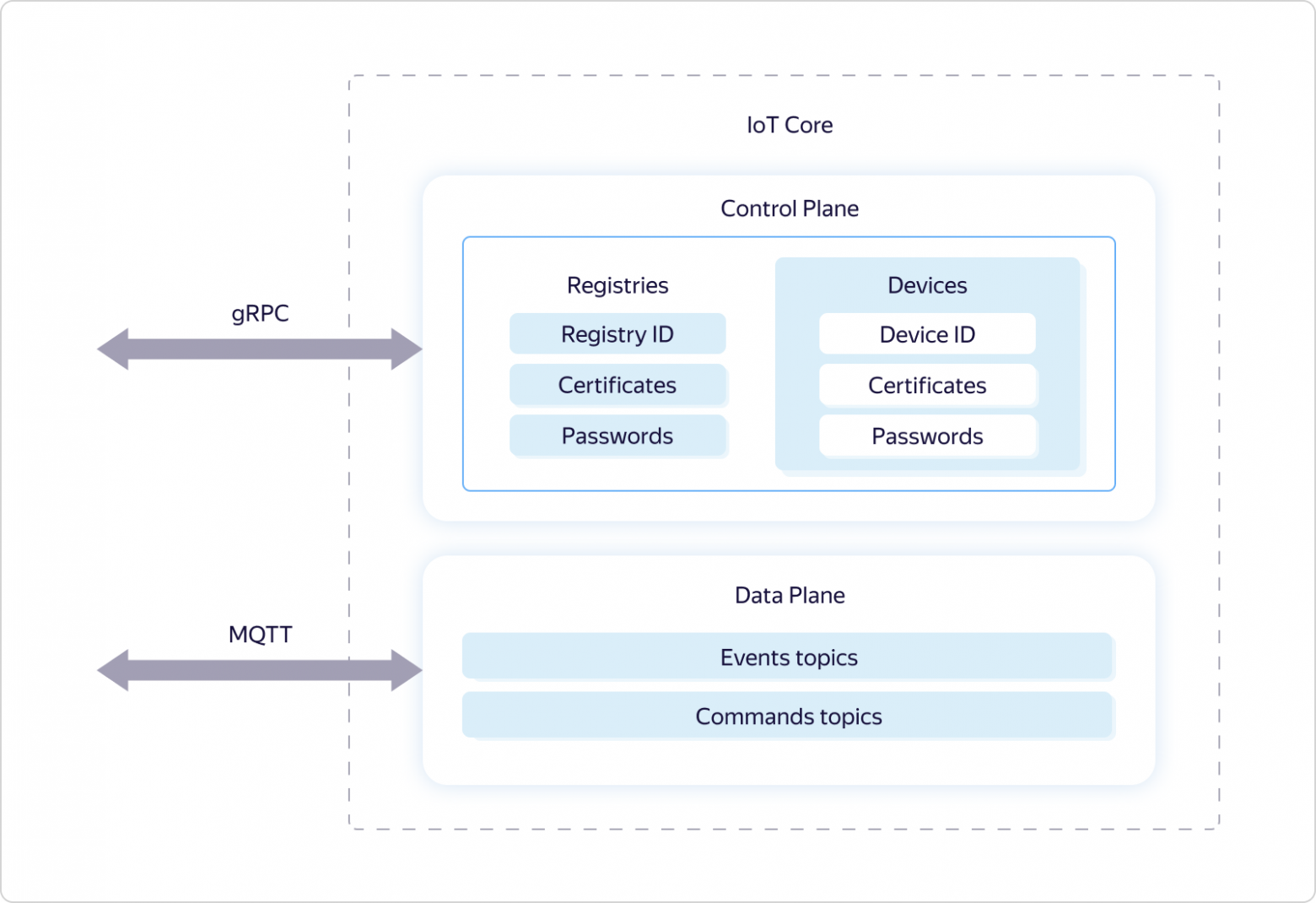
Data Plane отвечает за логику работы по протоколу MQTT, а Control Plane отвечает за разграничение прав доступа к тем или иным топикам и использует для этого логические сущности Реестр (Registry) и Устройство (Device).
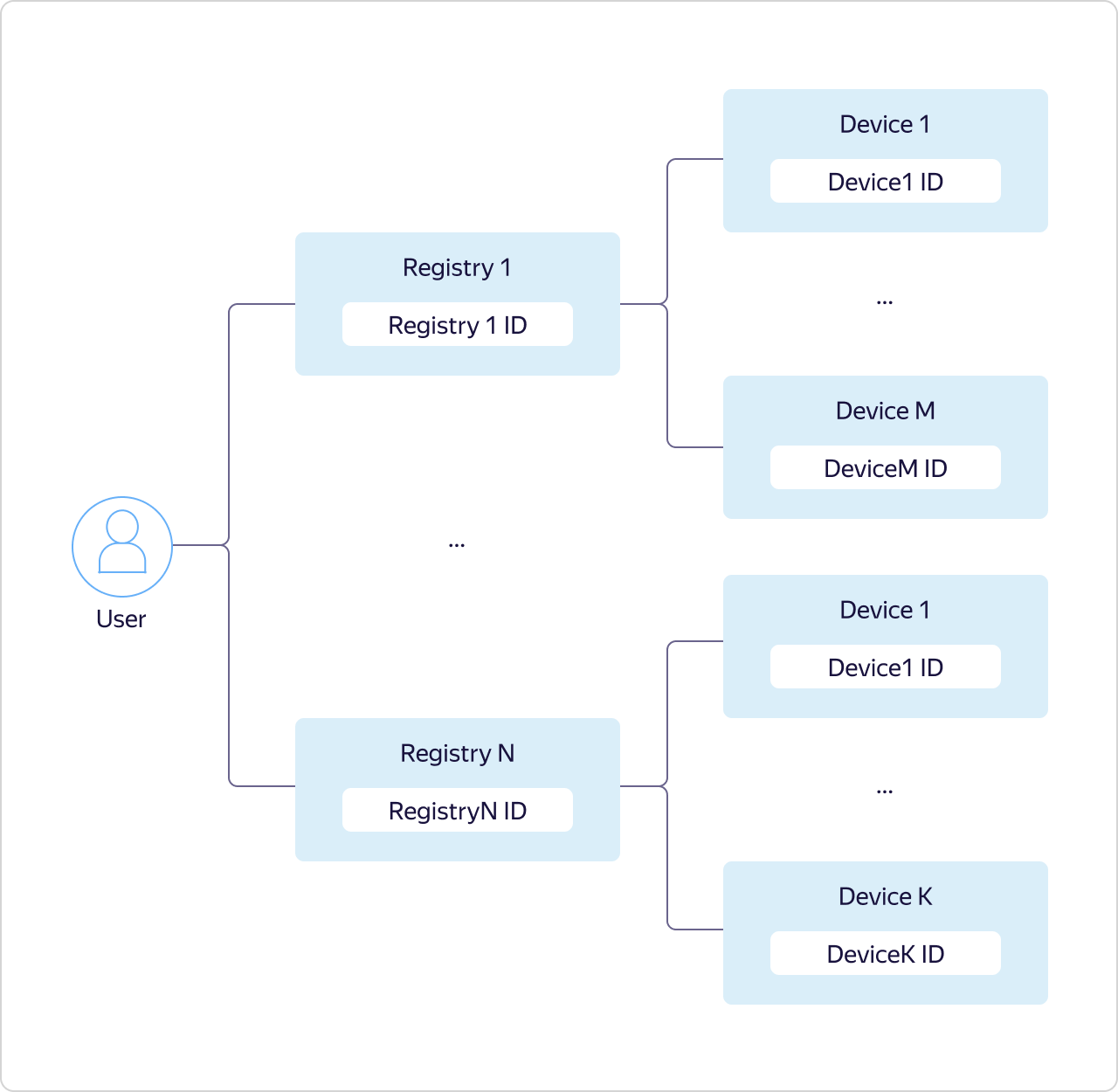
У каждого пользователя Яндекс.Облака может быть несколько реестров, каждый из которых может содержать собственное подмножество устройств.
Доступ к топикам предоставляется следующим образом:
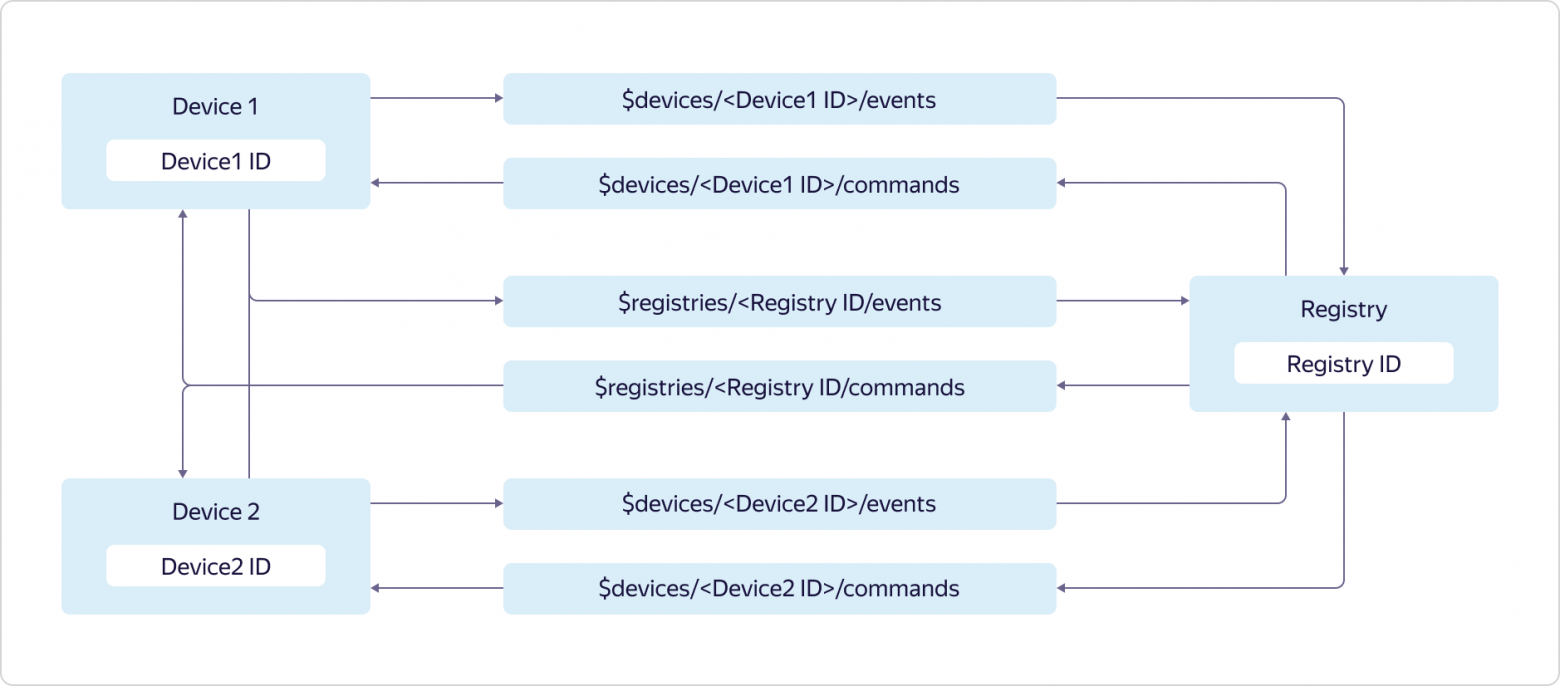
Устройства могут отправлять данные только в свой топик событий и топик событий реестра:
$devices/<Device1 ID>/events
$registries/<Registry ID>/eventsи подписываться на сообщения только из своего топика команд и топика команд реестра:
$devices/<Device1 ID>/commands
$registries/<Registry ID>/commandsРеестр может отправлять данные во все топики команд устройств и в топик команд реестра:
$devices/<Device1 ID>/commands
$devices/<Device2 ID>/commands
$registries/<Registry ID>/commandsи подписываться на сообщения из всех топиков событий устройств и топика событий реестра:
$devices/<Device1 ID>/events
$devices/<Device2 ID>/events
$registries/<Registry ID>/eventsЧтобы работать со всеми описанными выше сущностями, у Data Plane есть gRPC-протокол и REST-протокол, на базе которых реализован доступ через GUI-консоли Яндекс.Облака и интерфейс командной строки CLI.
Что касается Data Plane, то он поддерживает протокол MQTT версии 3.1.1. Однако есть несколько особенностей:
- При подключении нужно обязательно использовать TLS.
- Поддерживается только TCP-соединение. WebSocket пока недоступен.
- Доступна авторизация как по логину и паролю (где логин — это ID устройства или реестра, а пароли задаются пользователем), так и с помощью сертификатов.
- Не поддерживается флаг Retain, при использовании которого MQTT-брокер сохраняет отмеченное флагом сообщение и отправляет его при следующей подписке на топик.
- Не поддерживается постоянный сеанс (Persistent Session), при котором MQTT-брокер сохраняет информацию о клиенте (устройстве или реестре) для упрощения повторного подключения.
- При subscribe и publish поддерживаются только первые два уровня обслуживания:
- QoS0 — At most once. Нет гарантии доставки, но нет и повторной доставки одного и того же сообщения.
- QoS1 — At least once. Доставка гарантирована, но есть вероятность повторного получения одного и того же сообщения.
Чтобы упростить подключение к Yandex IoT Core, мы регулярно добавляем новые примеры для разных платформ и языков в наш репозиторий на GitHub, а также описываем сценарии работы в документации.
Архитектура сервиса выглядит так:
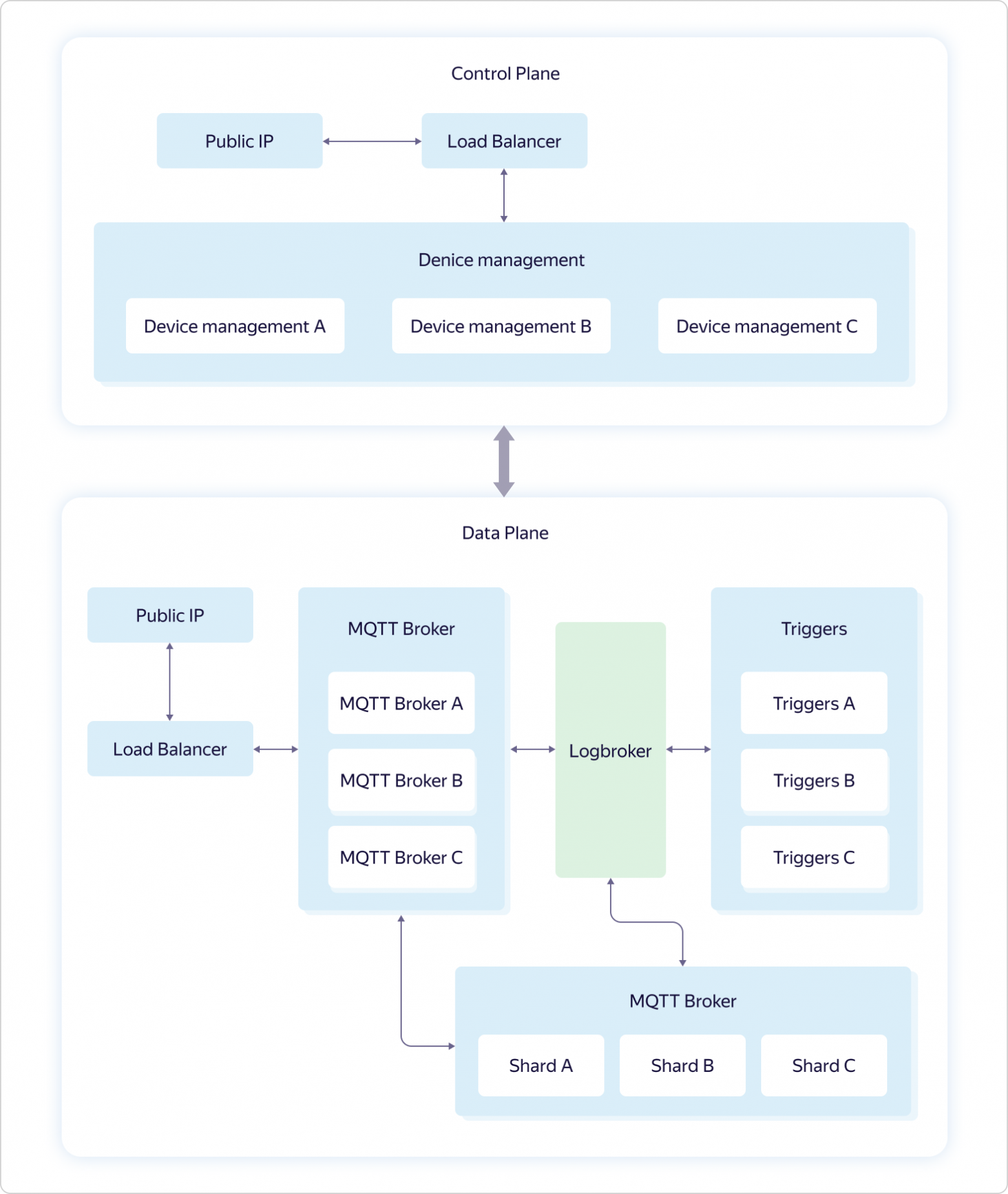
Бизнес-логика сервиса включает четыре части:
- Device management — реализация управления доступом к топикам. Является частью Control Plane.
- MQTT Broker — реализация MQTT-протокола. Часть Data Plane.
- Triggers — реализация интеграции с сервисом Yandex Cloud Functions. Часть Data Plane.
- Shards — реализация специальной логики работы с MQTT-брокером в условиях балансировки трафика. Часть Data Plane.
Всё взаимодействие с «внешним миром» идёт через балансировщики нагрузки. Причём, в соответствии с философией dogfooding, используется Yandex Load Balancer, доступный всем пользователям Яндекс.Облака.
Каждая часть бизнес-логики состоит из нескольких наборов по три виртуальные машины — по одной в каждой зоне доступности (на схеме А, B и C). Виртуальные машины точно такие же, как у всех пользователей Яндекс.Облака. При увеличении нагрузки масштабирование происходит при помощи всего набора — добавляются сразу три машины в рамках одной части бизнес-логики. Это значит, что если один набор из трёх машин MQTT Broker не будет справляться с нагрузкой, то добавится ещё один набор из трёх машин MQTT Broker, при этом конфигурация других частей бизнес-логики останется прежней.
И только Logbroker не доступен публично. Он представляет собой сервис для эффективной отказоустойчивой работы с потоками данных. В его основе лежит Apache Kafka, однако он имеет множество других полезных функций: реализует процессы восстановления после сбоев (в том числе семантику exactly once, когда у вас есть гарантия доставки сообщения без дупликации) и сервисные процессы (такие как междатацентровая репликация, раздача данных на кластеры расчёта), а также обладает механизмом равномерного не дублирующегося распределения данных между подписчиками потока — своего рода балансировщик нагрузки.
Функции Device management в Control Plane мы рассмотрели выше. А вот с Data Plane всё намного интереснее.
Каждый экземпляр MQTT Broker работает независимо и ничего не знает о других экземплярах. Все пришедшие данные (publish от клиентов) брокеры отправляют в Logbroker, откуда их забирают шарды (Shards) и триггеры (Triggers). И именно в шардах происходит синхронизация между экземплярами брокеров. Шарды знают обо всех MQTT-клиентах и распределении их подписок (subscribe) по экземплярам MQTT-брокеров и определяют, куда отправить пришедшие данные.
Например, MQTT-клиент А подписан на топик у брокера А, а MQTT-клиент B подписан на тот же топик у брокера B. Если MQTT-клиент C сделает publish в тот же топик, но в брокер C, то именно шард транслирует данные из брокера C в брокеры A и B, в результате чего данные получат и MQTT-клиент А и MQTT-клиент B.
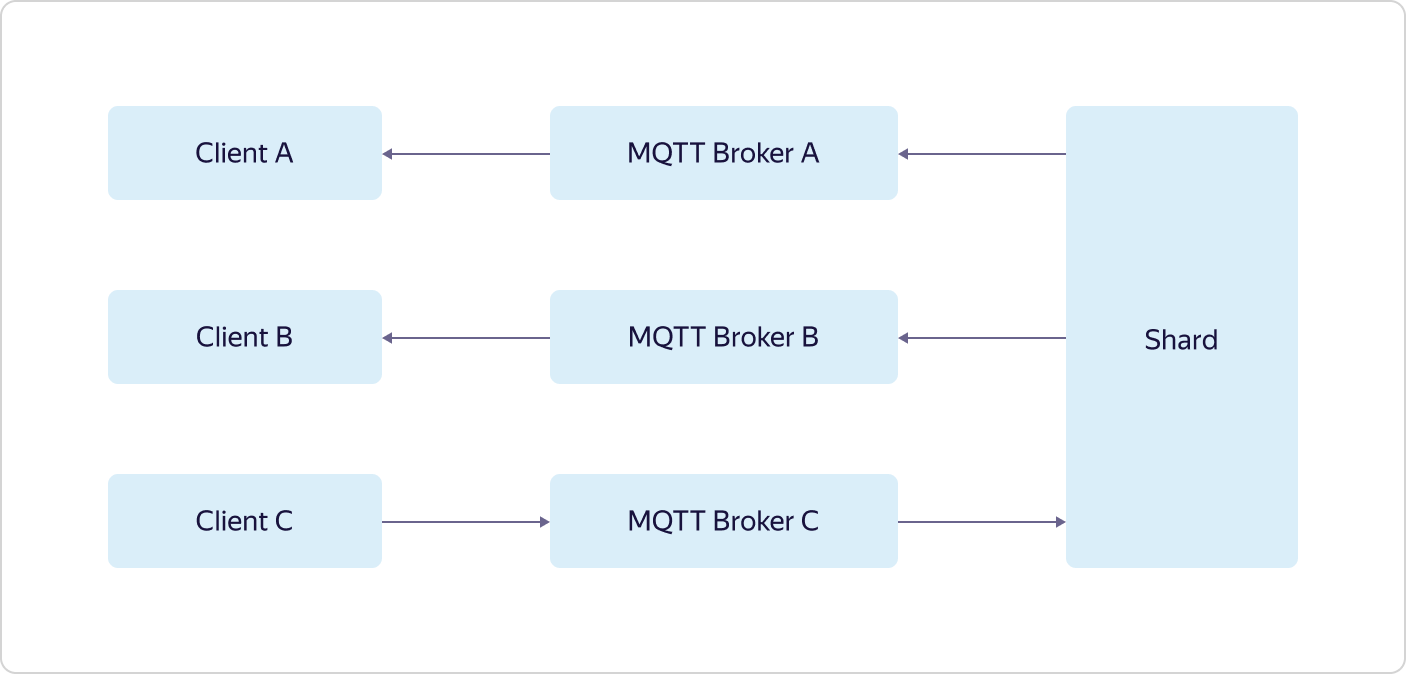
Последняя часть бизнес-логики, триггеры (Triggers), также получает все пришедшие от MQTT-клиентов данные и, если это настроено пользователем, передаёт их триггерам сервиса Yandex Cloud Functions.
Как видите, Yandex IoT Core имеет достаточно сложную архитектуру и логику работы, которую трудно повторить на локальных инсталляциях. Это позволяет ему как выдерживать потерю даже двух из трёх зон доступности, так и отрабатывать неограниченное количество подключений и неограниченные объёмы данных.
Причём вся эта логика скрыта от пользователя «под капотом», а снаружи всё выглядит очень просто — так, как будто вы работаете с одним-единственным MQTT-брокером.
Триггеры и сервис Yandex Cloud Functions
Yandex Cloud Functions — представитель так называемых «бессерверных» (serverless) сервисов в Яндекс.Облаке. Основная суть таких сервисов в том, чтобы пользователь не тратил своё время на настройку, развёртывание и масштабирование окружения для выполнения кода, а занимался только самым ценным для него — написанием самого кода, выполняющего нужную задачу. В случае с функциями это так называемый атомарный stateless-код, который может быть запущен по некоторому событию. «Атомарный» и «stateless» означают, что этот код должен выполнять некоторую относительно небольшую, но целостную задачу, при этом в коде не должно использоваться никаких переменных для того, чтобы сохранять значения между вызовами.
Существует несколько способов вызывать функции: прямой HTTP-вызов, вызов по таймеру (cron) или подписка на какое-либо событие. В качестве последнего сервисом уже поддерживается подписка на очереди сообщений (Yandex Message Queue), на события, генерируемые сервисом Object Storage, и (самое ценное для IoT-сценария) подписка на сообщения в Yandex IoT Core.
Несмотря на то, что с Yandex IoT Core можно работать с помощью любого MQTT-совместимого клиента, Yandex Cloud Functions является одним из наиболее оптимальных и удобных способов принимать и обрабатывать данные. Причина этого очень проста. Функция может вызываться на каждое пришедшее сообщение от любого устройства, причём функции будут выполняться параллельно друг другу (за счёт атомарности и stateless-подхода), а количество их вызовов будет естественным образов изменяться по мере изменения количества пришедших сообщений от устройств. Таким образом, пользователь может полностью абстрагироваться от вопросов настройки инфраструктуры и, более того, в отличие от тех же виртуальных машин, оплата будет происходить только за фактически выполненную работу. Это позволит существенно сэкономить при низкой нагрузке и получать понятную и предсказуемую стоимость при росте.
Механизм вызова функций по событиям (подписка на события) называется триггер (Trigger). Суть его изображена на схеме:
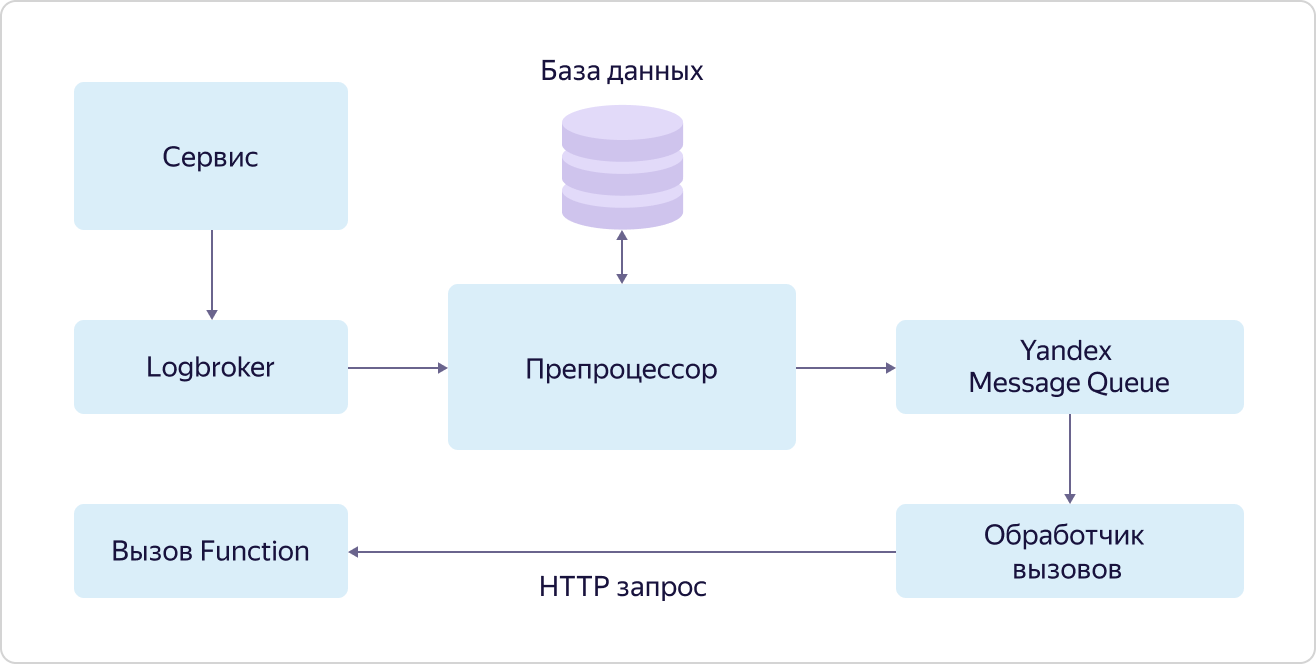
Сервис, генерирующий события для вызова функций, складывает их в очередь в Logbroker. В случае с Yandex IoT Core этим занимаются Triggers из Data Plane. Далее эти события забирает препроцессор, который ищет в базе данных запись для этого события с указанием функции, которую нужно вызвать. Если такая запись нашлась, то препроцессор кладёт информацию о вызове функции (ID функции и параметры вызова) в очередь в сервис Yandex Message Queue, откуда её забирает обработчик вызовов. Обработчик в свою очередь отправляет HTTP-запрос на вызов функции в сервис Yandex Cloud Functions.
При этом, опять-таки в соответствии с философией dogfooding, используется доступный всем пользователям сервис Yandex Message Queue, а вызов функций осуществляется точно таким же способом, которым могут вызывать свои функции любые другие пользователи.
Скажем несколько слов про Yandex Message Queue. Несмотря на то, что это, как и Logbroker, сервис очередей, между ними есть одно существенное отличие. При обработке сообщений из очередей обработчик сообщает очереди о том, что он закончил и сообщение можно удалять. Это важный механизм надёжности в таких сервисах, однако он усложняет логику работы с сообщениями.
Yandex Message Queue позволяет «распараллеливать» обработку каждого сообщения внутри очереди. Иначе говоря, сообщение из очереди, которое обрабатывается в данный момент, не блокирует возможность другому «потоку» забрать следующее событие из очереди на обработку. Это называется параллелизм на уровне сообщений.
А LogBroker оперирует группами сообщений, и пока группа не будет обработана вся, следующую группу на обработку забрать нельзя. Этот подход называется параллелизм на уровне партиций.
И именно использование Yandex Message Queue позволяет быстро и эффективно обрабатывать параллельно множество запросов на вызов функции по событиям от того или иного сервиса.
Несмотря на то, что триггеры представляют собой отдельный самостоятельный блок, они являются частью сервиса Yandex Cloud Functions. Нам осталось только разобраться с тем, как именно вызываются функции.
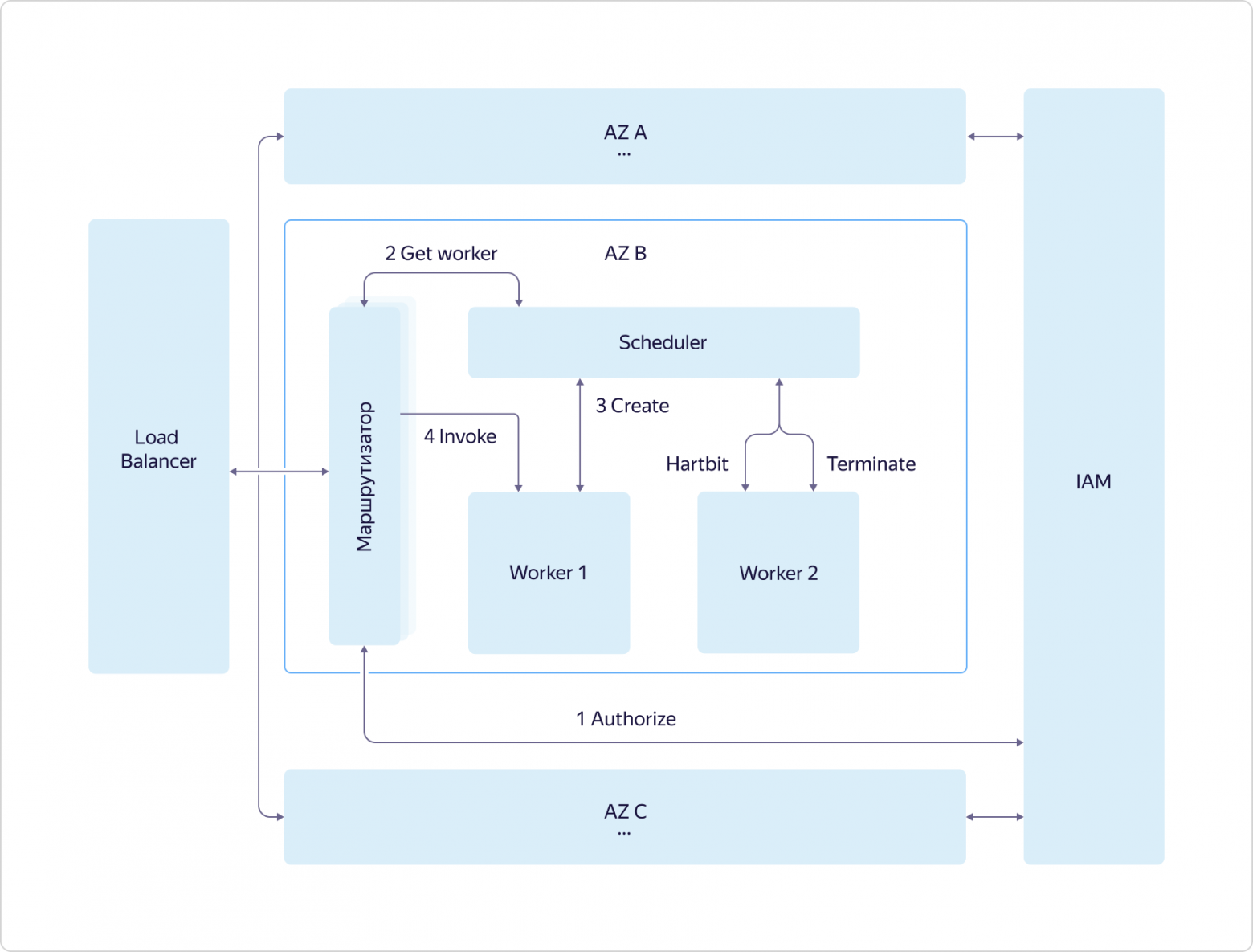
Все запросы на вызов функций (как внешние, так и внутренние) попадают в балансировщик нагрузки, который распределяет их по маршрутизаторам в разных зонах доступности (AZ), в каждой зоне развёрнуто несколько штук. Маршрутизатор при получении запроса первым делом идёт на сервис Identity and Access manager (IAM), чтобы удостовериться, что у источника запроса есть права на вызов данной функции. Далее он обращается к scheduler и спрашивает, на каком worker запустить функцию. Worker представляет собой виртуальную машину с настроенной средой выполнения изолированных друг от друга функций. Далее маршрутизатор, получив от scheduler адрес worker, на котором нужно выполнить функцию, отправляет на этот worker команду на запуск функции с определёнными параметрами.
Откуда берутся worker? Тут как раз и происходит вся магия serverless. Schedulers, анализируя нагрузку (количество и время работы функций), управляют (запускают и останавливают) виртуальными машинами с той или иной средой исполнения. Сейчас поддерживается NodeJS и Python. И здесь крайне важен один параметр — скорость запуска функций. Команда разработки сервиса проделала огромную работу, и сейчас виртуальная машина стартует максимум за 250 мс, при этом используется максимально безопасная среда изоляции функций друг от друга — виртуализация QEMU, на которой работает всё Яндекс.Облако. При этом, если для пришедшего запроса уже есть работающий worker, функция запускается практически мгновенно.
И, в соответствии всё с тем же подходом dogfooding, в качестве Load Balancer используется публичный сервис, доступный всем пользователям, а worker, scheduler и маршрутизатор — это обычные виртуальные машины, такие же, как у всех пользователей.
Таким образом, отказоустойчивость сервиса реализовывается на уровне балансировщика нагрузки и резервирования ключевых компонентов системы (маршрутизатор и scheduler), а масштабирование происходит за счёт развёртывания или сокращения количества worker. При этом каждая зона доступности работает независимо, что позволяет пережить потерю даже двух из трёх зон.
Полезные ссылки
В заключении хочу дать несколько ссылок, которые позволят изучить сервисы более детально:
- Yandex IoT Core: cloud.yandex.ru/services/iot-core
- Yandex Cloud Functions: cloud.yandex.ru/services/functions
- Yandex Message Queue: cloud.yandex.ru/services/message-queue
- Yandex Managed Service for ClickHouse: cloud.yandex.ru/services/managed-clickhouse
- Yandex Load Balancer: cloud.yandex.ru/services/load-balancer
- Yandex Object Storage: cloud.yandex.ru/services/storage
