

Привет! Меня зовут Василий Землянов, я занимаюсь разработкой ML-инфраструктуры. Несколько лет я проработал в команде, которая делает споттер — специальную маленькую нейросетевую модельку, которая живёт в умных колонках Яндекса и ждёт от пользователя слова «Алиса». Одной из моих задач в этой команде была квантизация моделей. На пользовательских устройствах мало ресурсов, и мы решили, что за счёт квантизации сможем их сэкономить — так в итоге и вышло.
Потом я перешёл в команду YandexGPT. Вместо маленьких моделей я стал работать с очень крупными. Мне стало интересно, как устроена квантизация больших языковых моделей (LLM). Ещё меня очень впечатляли истории, где люди берут гигантские нейросети, квантизируют в 4 бита и умудряются запускать их на ноутбуках. Я решил разобраться, как это делается, и собрал материал на доклад для коллег и друзей. А потом пришла мысль поделиться знаниями с более широкой аудиторией, оформив их в статью. Так я и оказался на Хабре :)
Надеюсь, погружение в тему квантизации будет интересно как специалистам, так и энтузиастам в сфере обучения нейросетей. Я постарался написать статью, которую хотел бы прочитать сам, когда только начинал изучать, как заставить модели работать эффективнее. В ней мы подробно разберём, зачем нужна квантизация и в какой момент лучше всего квантизовать модель, а ещё рассмотрим разные типы данных и современные методы квантизации.
Что такое квантизация и как она работает
Квантизация — это процесс преобразования значений из представления с большим объёмом информации (обычно непрерывного множества) в более компактное представление, обычно из дискретного множества. Наглядный пример квантизации — дискретизация аналогового сигнала, когда каждому значению непрерывного сигнала присваивается значение из заранее определённого дискретного множества.
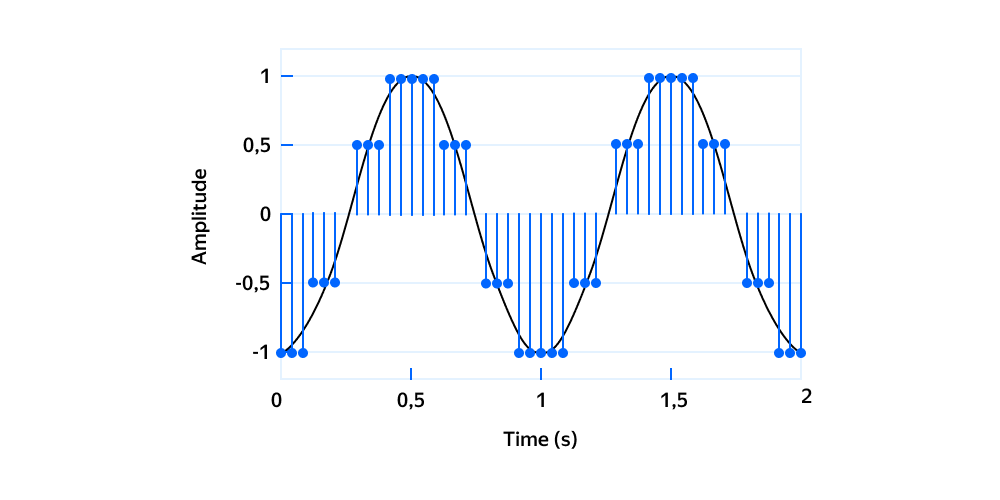
В контексте нейросетей квантизация означает переход от типа данных с большим числом битов, например float32, к типу с меньшим числом, такому как int8. В этой статье мы рассмотрим ключевые идеи квантизации нейросетевых моделей с прицелом на LLM.
Для чего вообще нужна квантизация? Она позволяет экономить. Квантизованные модели требуют меньше вычислительных ресурсов и работают быстрее. Как следствие, экономят деньги и улучшают пользовательский опыт.
У исследователей и энтузиастов без личного GPU-кластера появляется возможность экспериментировать с большими современными моделями. А это значит, что можно эффективно выполнять вычисления прямо на пользовательских устройствах.
Линейная квантизация
Существуют разные подходы к квантизации. Например, через кластеризацию или факторизацию матриц. В этой статье мы сосредоточимся на линейной квантизации как на самом популярном и доказавшем свою эффективность методе.
Аффинная квантизация
Аффинная, или несимметричная, квантизация отображает несимметричный диапазон в k-битный тип данных. Рассмотрим вещественный диапазон значений ![[R_{min}, R_{max}]](https://habrastorage.org/getpro/habr/formulas/2/24/246/246bdc999fa43c2d44c2bd4f880b72e6.svg) .
.

Раз уже есть квантизованный тензор, перейти к вещественному будет достаточно просто. Нужно вычесть zero-point и умножить результат на scale. Отсюда легко понять, как из вещественного тензора получить квантизованный.

 и
и  — это константы квантизации, то есть параметры, которые вычисляются в процессе. —
— это константы квантизации, то есть параметры, которые вычисляются в процессе. — scale, отвечает за масштаб преобразования.

Здесь нужна точность, поэтому для хранения используют исходный, вещественный тип данных.
— zero-point, соответствует нулевому значению, где  — округление.
— округление.

Нейронным сетям очень важно точное представление нуля. Округлять можно по-разному: вниз, к ближайшему целому, стохастически. , как правило, хранят в квантизованном типе.
Квантизация:

Деквантизация:

Аффинная квантизация хорошо подходит для несимметричных распределений, например для выхода ReLU.
Симметричная квантизация
Симметричная квантизация отображает симметричный относительно нуля диапазон.

Ноль вещественного типа переходит в ноль квантизованного. Границы квантизируемого диапазона определяют как максимальное по модулю квантизируемое значение  .
.
Чтобы тип получился симметричным, нужно отказаться от одного значения в квантизованном типе данных. Например, диапазон signed int8: [-128, 127] превратится в [-127, 127].
Константы:


Квантизация:

Деквантизация:

Отличие от формул аффинной квантизации состоит в отсутствии . Преимущества аффинной квантизации — она умеет точнее и лучше справляться с асимметричными распределениями, в то время как симметричная квантизация выигрывает за счёт простоты и скорости. При таком подходе не нужно думать о хранении zero-point, а для деквантизации достаточно умножить тензор на константу.
Как квантизовать вещественный тензор в int8
Нейросеть можно рассматривать как последовательность операций над тензорами чисел. Рассмотрим наглядный пример, как квантизовать вещественный тензор 32-битных вещественных чисел в 8-битные целочисленные.
Шаг 1. Берём вещественный тензор.
Шаг 2. Находим максимум.

Шаг 3. Вычисляем по формуле.
Шаг 4. Квантизуем.
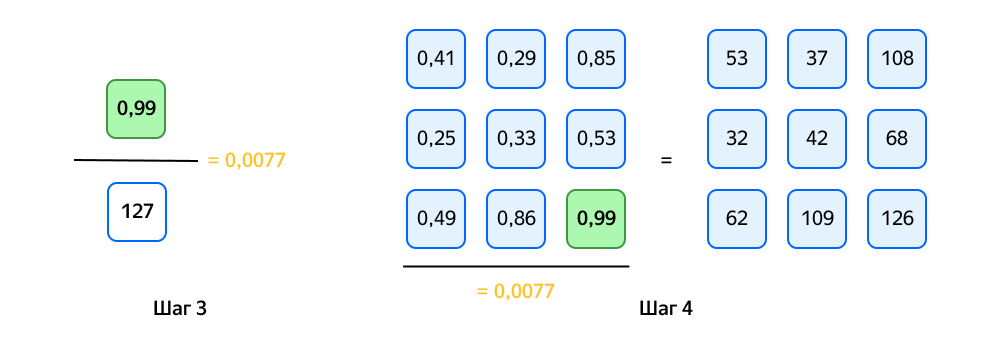
Готово. На выходе мы получили 8-битный целочисленный тензор и константу квантизации 0,0077. Теперь можно хранить меньший объём информации и при необходимости возвращаться к исходному 32-битному вещественному представлению с потерей точности.
Что квантизовать, чтобы улучшить эффективность модели
Стандартный подход — квантизовать веса модели. Никакие дополнительные манипуляции не нужны, просто воспользуйтесь формулами.
Также можно квантизовать выходы слоёв — активации. Для этого нужно оценить, какие значения встречаются в тензорах активаций. Как это сделать? Прогоняем через обученную нейросеть данные из обучающего датасета и собираем статистику. С помощью этой информации находим константы. Готово — вы великолепны! Кстати, такой подход называют статической квантизацией.
А при динамической квантизации активации квантизуются на inference. Этот подход может дать лучшее качество, но с ним возможны трудности: в процессе inference искать константы придётся динамически. Это делает метод более сложным и вычислительно затратным, зато константы всегда остаются актуальными.
В какой момент лучше квантизовать модель
Готовить сеть к квантизации можно в процессе обучения, такой подход называется Quantize-Aware. Для этого в нейросеть встраивают специальные блоки и в ходе обучения эмулируют квантизованный inference.
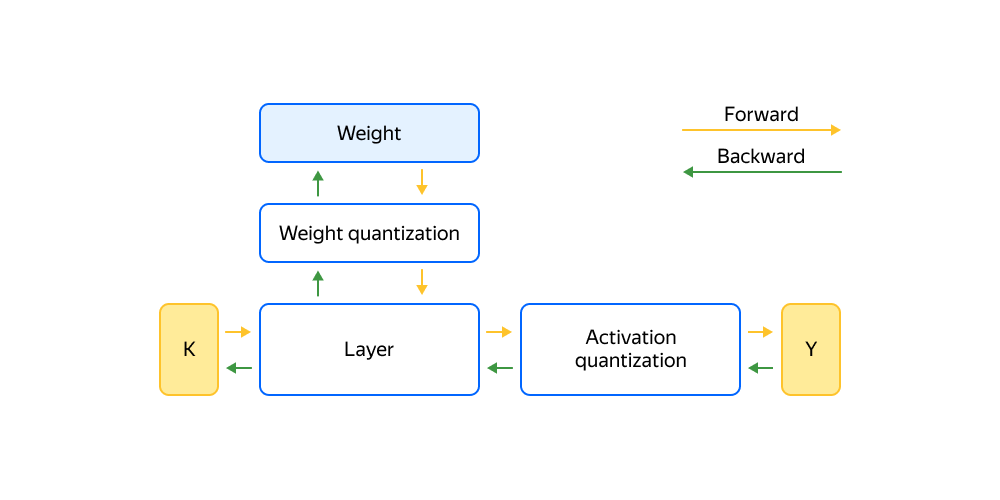
В слоях хранят исходные, вещественные веса. Перед выполнением forward-pass их заменяют квантизованными по формулам. Операция недифференцируемая, поэтому градиенты прокидывают напрямую в вещественный тензор. Аналогично для квантизации активаций используют специальные блоки.
Quantize-Aware-обучение сложное и требует больше вычислительных ресурсов, но на выходе получается модель, «приспособленная» к работе с квантизованными значениями и потенциально более точная.
В случае Post Training квантизуют уже обученную модель. Для квантизации активаций через обученную сеть дополнительно прогоняют данные из калибровочного датасета, собирают статистику по тензорам и потом квантизуют. Если квантизовать только веса, данные не нужны, так как вся информация уже есть в тензорах. Этот способ проще и быстрее, чем Quantize-Aware, но уступает ему в точности.
В поисках правильной гранулярности
Нейросеть можно квантизовать с разной гранулярностью. Самый плохой способ — квантизовать сразу всю сеть за раз. В этом случае у вас получится одна общая константа на всю модель. Результат таких манипуляций, скорее всего, окажется неудовлетворительным.
Можно квантизовать тензоры по отдельности — тогда каждый тензор получит свои константы. А можно пойти дальше и в каждом тензоре квантизовать строки или столбцы. Соответственно, у каждой строки (столбца) в этом случае будет своя константа. Их придётся где-то хранить, зато вычисления будут точнее.
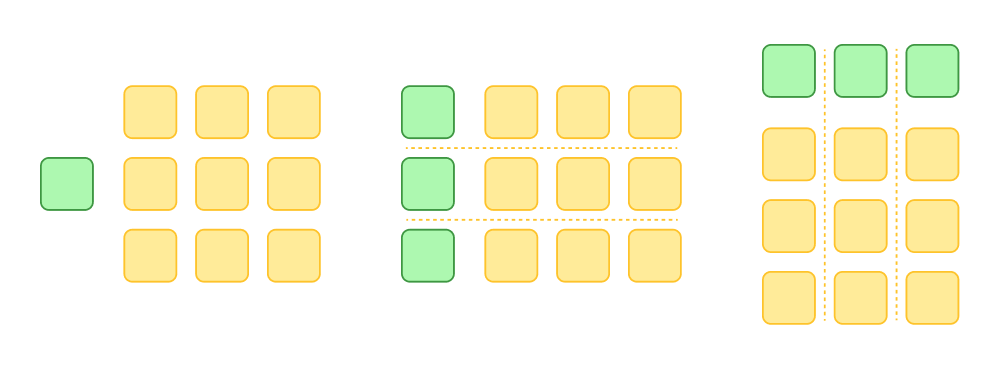
Также можно нарезать тензор на блоки небольшого размера — так получится ещё точнее. Этот подход позволяет бороться с выбросами в матрицах, о чём мы и поговорим дальше.
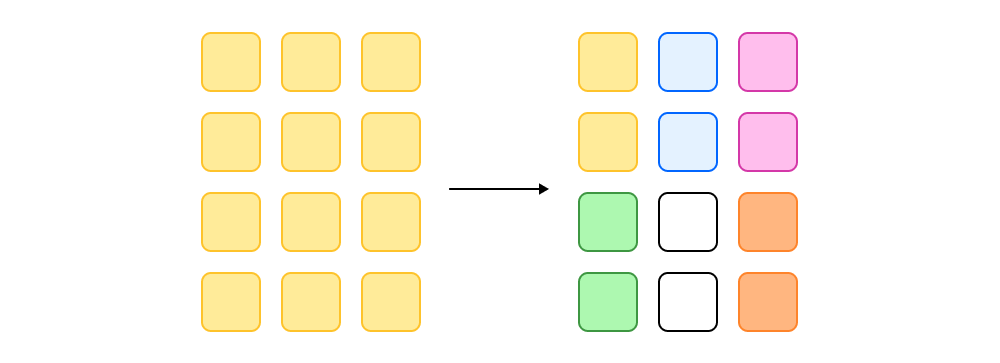
Итак, чем меньше гранулярность, тем меньше констант нужно хранить, и наоборот — чем выше гранулярность, тем ближе результаты квантизованных вычислений к исходным.
По каким размерностям квантизовать модели
Здравый смысл говорит, что любой тензор можно квантизовать как по столбцам, так и по строкам. Но тут в дело вступает физика вычислений. Оказывается, что если нужны эффективные вычисления, появляются жёсткие рамки.
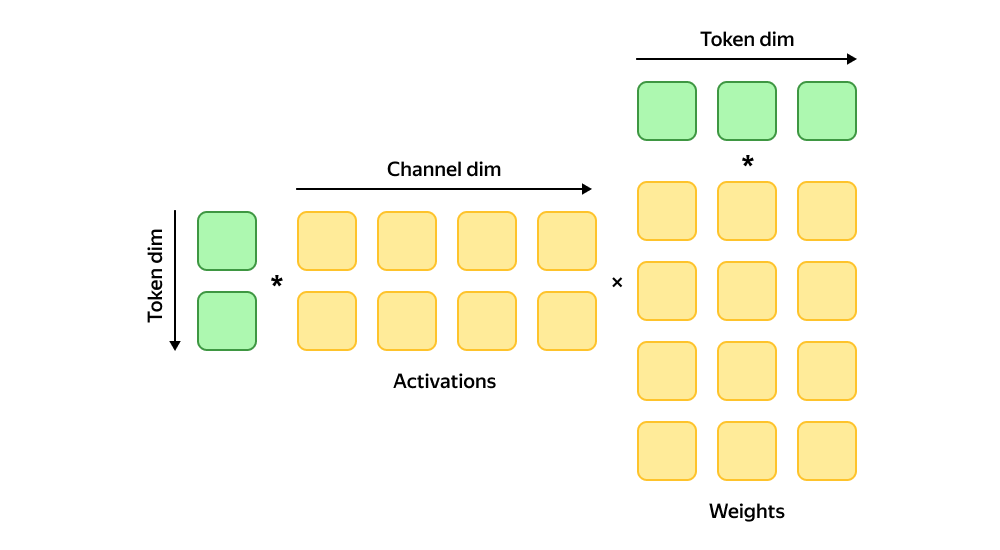
Современные эффективные GEMM-операции для квантизованных матриц ожидают, что константы квантизации относятся к внешним размерностям матриц. То есть они не той размерности, по которой происходит умножение.
Чтобы понять, почему всё работает именно так, нужно представить, как матрицы лежат в памяти. Для эффективного выполнения вычислений процессору нужно оперировать последовательными блоками памяти и эффективно утилизировать кеши. Например, так:

где — диагональные матрицы scale.
Типы данных
В квантизованных нейросетевых моделях обычно присутствуют два типа данных:
Quantized type — в этом типе хранят тензоры;
Computation type — в этом типе проводят вычисления.
К сожалению, эти два типа не всегда совпадают. Например, ваше железо может не поддерживать операции в хитром quantized type. Эффективных кернелов перемножения матриц под квантизованный тип может просто не существовать. В таких случаях перед вычислениями матрицу нужно конвертировать в computation type. Также computation type позволяет избежать проблем с переполнением в активациях, так как перемножение 8-битных чисел наверняка приведёт к выходу за границы типа.
Разберём устройство основных типов данных.
Int16/Int8/Int4
Самые обыкновенные целочисленные типы. Диапазон значений — ![[-2^{n-1}, 2^{n-1}-1]](https://habrastorage.org/getpro/habr/formulas/4/40/40b/40bbc24d49fd84a0a802b57735f48d58.svg) .
.
Схематично битовое представление Int16 можно показать так: 1 бит знака и 15 бит на значение.

Чем больше битов, тем точнее можно представить диапазон значений.
Float32
Вещественный тип float32 описан стандартом IEEE-754. Здесь битовое представление выглядит так: 1 бит знака, 8 — экспоненты, 23 — мантиссы.

Формула:
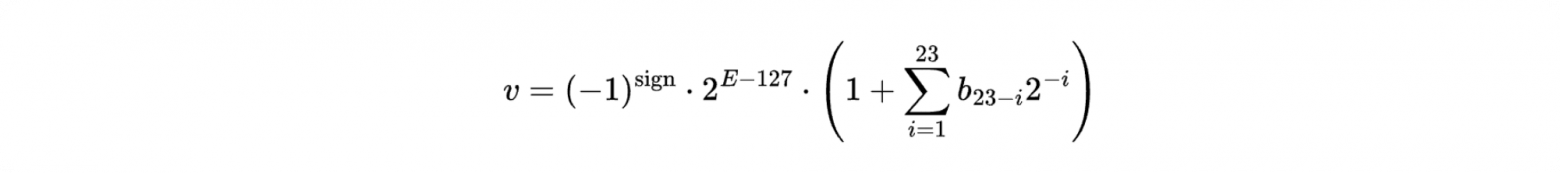
Ключевая идея вещественных типов: чем больше битов выделено под экспоненту, тем больший диапазон значений можно представить. Биты, оставшиеся для мантиссы, отвечают за точность, с которой представлены значения в диапазоне.
Float16
Описан тем же стандартом IEEE-754 в издании 2008 года. Битовое представление: 1 бит знака, 5 — экспоненты и 10 — мантиссы.

Главная проблема float16 — маленький диапазон значений. Максимальное значение равно 65504, из-за чего тензоры активаций легко переполняются.
Bfloat16, или brain float
Специальный формат данных, разработанный Google Brain. Можно рассматривать как аппроксимацию float32. Битовое представление такое: 1 бит знака, 8 — экспоненты и 7 — мантиссы.

Обратите внимание, что число битов под экспоненту совпадает с представлением float32. Значит, bfloat16 представляет тот же диапазон значений, пусть и менее точно. Зато можно меньше опасаться переполнений в активациях.
Другая приятная особенность bf16 — возможность быстро конвертировать значения во float32. Магия работает благодаря сходному битовому представлению. К сожалению, пока что не всё железо работает с этим типом (особенно мобильное).
TensorFloat32
Интересный 19-битный тип данных от NVidia. Поддерживается в архитектурах, начиная с NVidia Ampere (A-100). Битовое представление: 1 бит знака, 8 — экспоненты, 10 — мантиссы.

Ключевые особенности:
число битов экспоненты совпадает с bfloat16, а значит и с float32;
число битов мантиссы совпадает с float16.
Получился необычный, но точный и эффективный тип данных. Показывает отличные результаты по производительности вычислений и подходит для обучения моделей. Ложка дёгтя — существует только на современных видеокартах NVidia.
E4M3 и E5M2
Новые 8-битные float. Предложены NVidia, ARM и Intel в статье FP8 Formats for Deep Learning. Авторы предлагают два возможных 8-битных вещественных значения:
E4M3: 1 бит знака, 4 — экспоненты, 3 — мантиссы;
E5M2: 1 бит знака, 5 — экспоненты, 2 — мантиссы.
Эксперименты показывают, что современные LLM и «картиночные» сети можно успешно инферить и даже обучать (!) на таких типах данных. Ждём широкого распространения и поддержки в железе. Существуют и более радикальные идеи 4-битных вещественных значений: E2M1 и E3M0.
NormalFloat4
Normal Float 4 (NF4) — интересный пример построения 4-битного типа данных. Эмпирически мы знаем, что веса нейросетей распределены нормально и сконцентрированы около нуля. Авторы статьи утверждают, что NF4 теоретически оптимален для квантизации значений из нормального распределения  на отрезке
на отрезке ![[-1, 1]](https://habrastorage.org/getpro/habr/formulas/7/7d/7de/7dec1d46e68831c4eca28b020fcb1604.svg) . По поводу оптимальности есть и другое мнение, но сути это не меняет.
. По поводу оптимальности есть и другое мнение, но сути это не меняет.
Есть 4 бита — это 16 значений. Два значения уходят на -1 и 1 — остаётся 14. С их помощью представляют квантили в диапазоне .
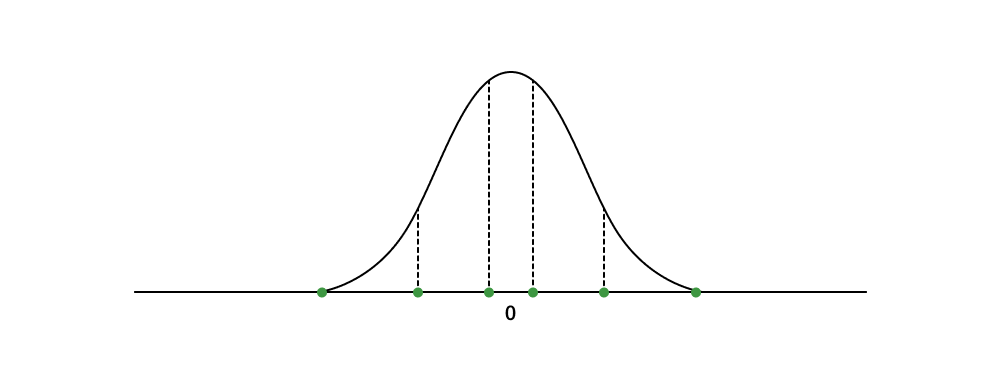
Каждый слой нейросети нормируют так, чтобы веса лежали в диапазоне . После этого каждый вес можно соотнести с ближайшим значением из предварительно рассчитанных квантилей.
Однако у описанной схемы есть недостаток — в ней нет точного представления для нуля. Нейросетям критически важно точное значение нуля, поэтому авторы предлагают красивое решение:
разбивают диапазон
на две части, положительную и отрицательную;находят
 квантилей слева;
квантилей слева;находят
 квантилей справа;
квантилей справа;склеивают полученные значения по нулю.


К этому типу данных мы ещё вернемся при обсуждении QLoRA.
Особенности квантизации больших языковых моделей
Современные LLM — авторегрессионные. Это значит, что они генерируют один токен за раз. Неудачная квантизация увеличивает вероятность генерации не того токена. Если в ходе генерации модель начинает нести не туда, на выходе получится совсем не тот ответ, который нужен пользователю. И метрики качества тоже, конечно, получатся не те.
Узкое место больших регрессионных моделей — процесс перекладывания крупных тензоров в памяти видеокарты. Но у современного железа достаточно вычислительных ресурсов, поэтому пока происходит перекладывание, мы можем успеть посчитать что-нибудь полезное.
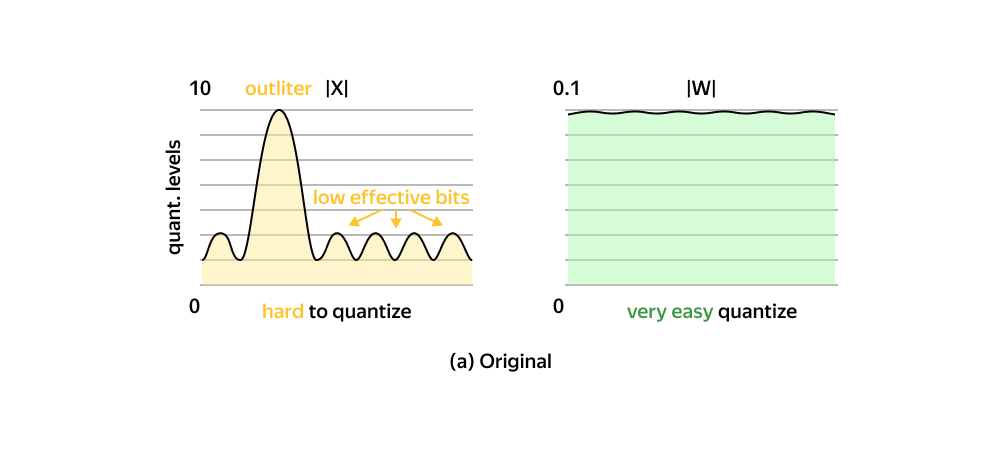
Однако из-за требований к памяти большим и ресурсоёмким моделям нужны эффективные техники квантизации. Quantize-aware-обучение, о котором я рассказывал выше, тут не подходит. И главное, когда число параметров становится больше и больше, стандартные техники квантизации перестают работать. При переходе границы в 6,7 миллиардов параметров квантизованные модели теряют всё качество. Происходит это из-за растущего числа выбросов в матрицах, о чём мы и поговорим дальше.
Суть проблемы выбросов
Ещё раз посмотрим на пример симметричной квантизации из начала статьи.

Что получится, если во входной тензор попадёт выброс?

Веса «склеились» в узкий диапазон и стали неотличимы. Качество модели потеряно. Так единственный выброс испортил всю матрицу.
Выбросы составляют всего 0,1–1% от всех значений. Первое, что приходит в голову — попробовать избавиться от выбросов, например, занулив их. Но это приводит к полной деградации модели, огромным потерям качества и росту перплексии.
Если провести эксперимент, занулив случайное подмножество весов того же объёма, качество пострадает незначительно. Значит, выбросы важны, и отказаться от них нельзя.
Природа выбросов и борьба с ними активно исследуются, иногда встречаются забавные статьи на эту тему.
Чтобы глубже понять проблему, рассмотрим матрицу активаций. По строкам расположены токены, по столбцам — каналы. Исследования показывают, что выбросы в матрицах распределены не случайно, у них есть своя структура:
выбросы преимущественно расположены в тензорах активаций;
выбросы сосредоточены в отдельных каналах (столбцах).
Как это представить? Есть тензор активаций на выходе очередного слоя:

Если в тензоре содержатся выбросы, то, скорее всего, они сгруппированы по определённым каналам.

В этот момент стоит вспомнить о различных способах квантизации тензоров: по строкам и по колонкам. Если бы можно было квантизовать матрицу активаций по колонкам, это бы решило проблему. Эмпирически, в столбце с выбросами лежат значения из схожего диапазона, значит, для них можно подобрать константы с удовлетворительным качеством.
Но, как мы уже обсудили, для эффективных вычислений в inference квантизовать тензоры активации нужно по строкам. Далее рассмотрим актуальные техники эффективной квантизации больших языковых моделей и борьбы с выбросами.
LLM.Int8
Авторы статьи, которую я рекомендую прочитать, научились квантизовать большие (175 миллиардов параметров) модели из привычных 16- или 32-битных вещественных весов в 8-битный целочисленный тип практически без потери качества. Также об этом есть большой и подробный пост в блоге Hugging Face. Идея состоит в том, что выбросы нужно обрабатывать отдельно, поскольку их совсем немного (0,1–1% от всех значений) и расположены они в отдельных каналах тензоров активаций.
Рассмотрим умножение матрицы активаций  на матрицу весов
на матрицу весов  . Столбцы делят на две группы: те, что содержат хотя бы один выброс, и те, что не содержат. В разных статьях значения-выбросы определяют по-разному. В статье, на которую я ссылаюсь, определение простое: выбросы — это значения, которые по модулю больше 6 (science!). Таким образом, из исходной матрицы весов получают две новых.
. Столбцы делят на две группы: те, что содержат хотя бы один выброс, и те, что не содержат. В разных статьях значения-выбросы определяют по-разному. В статье, на которую я ссылаюсь, определение простое: выбросы — это значения, которые по модулю больше 6 (science!). Таким образом, из исходной матрицы весов получают две новых.

Обратим внимание, что  -й столбец активаций взаимодействует только с -й строкой весов . Значит, матрицу тоже можно разбить на две части, отделив строки, соответствующие столбцам-выбросам .
-й столбец активаций взаимодействует только с -й строкой весов . Значит, матрицу тоже можно разбить на две части, отделив строки, соответствующие столбцам-выбросам .
Итак, мы получили две группы матриц: с выбросами и без. Теперь отдельно перемножим каждую группу и сложим результаты. Результат будет эквивалентен обычному матричному умножению.
Бóльшая часть значений попадёт в матрицы, не содержащие выбросов, которые можно легко квантизовать в 8 бит и использовать эффективные операции. Матрицы с выбросами оставляют в исходном 16-битном типе и проводят вычисления без потери точности.
Платить за выросшую точность квантизации придётся производительностью. Замеры авторов показывают ухудшение скорости inference на BLOOM-176B на 15–23% против 16-битного дефолта. Для маленьких моделей, таких как T5-3B, замедление ещё сильнее.
SmoothQuant
В статье, посвящённой SmoothQuant (с этим проектом также можно ознакомиться на GitHub), авторы рассказывают, как квантизовать и веса, и активации.
С весами всё просто: их распределение почти наверняка приближено к нормальному, сосредоточено около нуля и не содержит выбросов.
С активациями дело обстоит сложнее. Исследования показывают, что выбросы в основном сосредоточены в активациях. Они могут отличаться от других значений в 100 и более раз. Эффективность квантизации тензоров с выбросами очень низкая.

Попробуем переложить проблему с больной головы на здоровую. Снова замечаем, что произведение матриц можно без потери точности разложить на несколько произведений по соответствующим столбцам первой матрицы и строкам второй. Прогоним батчи через обученную модель тестового датасета и посмотрим на активации.

Пристально рассмотрим  -й столбец матрицы активаций
-й столбец матрицы активаций  и найдём максимальное по модулю значение
и найдём максимальное по модулю значение  . Разделим все значения в колонке на это значение.
. Разделим все значения в колонке на это значение.

Соответствующую строку матрицы весов  умножим на него же.
умножим на него же.

Так у нас получилось избавиться от выброса в матрице активаций, а произведение  при этом не изменилось! Однако проблема никуда не делась — она просто переместилась в матрицу весов. Распределим проблему между двумя матрицами. Введём коэффициент
при этом не изменилось! Однако проблема никуда не делась — она просто переместилась в матрицу весов. Распределим проблему между двумя матрицами. Введём коэффициент  как отношение максимумов соответствующих строки и столбца в матричном произведении.
как отношение максимумов соответствующих строки и столбца в матричном произведении.

Коэффициент  позволяет производить более тонкую настройку, в какую матрицу пойдет большая нагрузка. Авторы рекомендуют просто брать 0,5.
позволяет производить более тонкую настройку, в какую матрицу пойдет большая нагрузка. Авторы рекомендуют просто брать 0,5.

Теперь разделим -й столбец активаций и домножим -ю строчку весов на .

Если проделать эту манипуляцию для всех колонок , получатся сглаженные и готовые к квантизации матрицы.


Прелесть метода заключается в том, что все эти операции проходят в офлайне. Константы можно запечь в матрицы весов. Для матриц активаций — просто запекаем соответствующие константы в предыдущую матрицу весов. Таким образом, нет никаких накладных расходов во время inference. Здорово, не правда ли?
GPTQ: Quantization for Generative Pre-trained Transformers
Давайте задумаемся: а ту ли задачу мы вообще решаем? Возможно, округление к ближайшему целому — это неоптимальный подход. Ведь на самом деле мы хотим найти такую квантизованную матрицу весов  , чтобы после перемножения на матрицу активаций получить максимально близкий к исходному результат.
, чтобы после перемножения на матрицу активаций получить максимально близкий к исходному результат.

В такой постановке задача является NP-трудной, то есть непонятно, как эффективно найти точное решение. Можно попробовать найти подходящее решение специальными солверами.
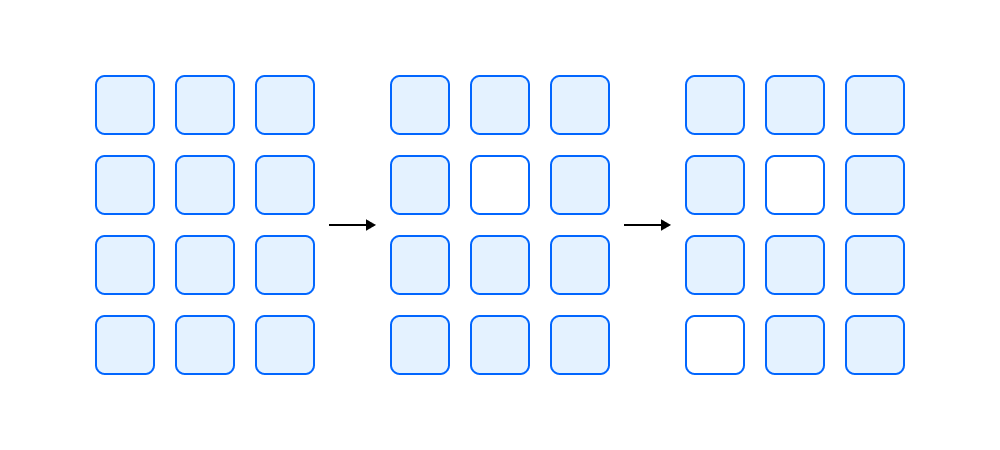
Ключевая идея алгоритма была описана в 1990 году в статье Optimal Brain Damage. Авторы решали задачу прунинга: какие веса модели можно занулить, не теряя в качестве. Для этого они предлагают оценивать «важность» элементов матрицы весов . Прунинг предполагает, что наименее важные веса можно удалить. Алгоритм такой:
Обучаем модель.
Оцениваем важность каждого веса в нейросети.
Зануляем наименее важные веса.
Переходим обратно к первому шагу и дообучаем оставшиеся веса.
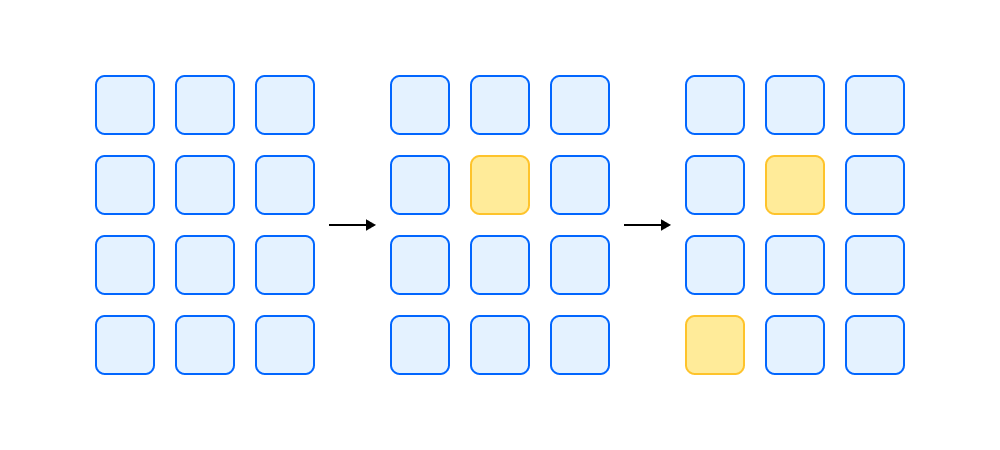
В том же 1990 году идея развивается дальше. Выходит статья Optimal Brain Surgeon, где авторы предлагают оценивать важность весов через инвертированный гессиан, чтобы получить качественный результат без дообучения сети в процессе квантизации.
Наши дни. Статья Optimal Brain Quantization расширяет OBS на решение задачи квантизации. Как? Нужно определить важность весов и квантизовать их в порядке от наименее важных к более важным. Кроме того, авторы нашли способ делать эту процедуру более эффективно. Производительности хватает на квантизацию ResNet или простых Bert. Но для LLM этот алгоритм всё равно слишком тяжёлый.
Авторы GPTQ научились решать задачу быстро. Модель на 176 миллиардов параметров квантизуют в 3–4 бита за несколько часов на одной A100. Математика потянет на отдельную статью, поэтому подробности лучше искать в оригинальных статьях или на GitHub.
Важно понимать, что веса квантизуют не по одному, как в OBS, а по столбцам — один столбец за раз. Если квантизовать модель по одному весу, то полученный набор констант будет сопоставим с оригинальными матрицами, что загубит всю идею.
Данные по скорости:
A100 — 3.25 speedup over FP16;
A6000 — 4.5 speedup over FP16.
SPQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression
SPQR — метод квантизации, разработанный исследователями из команды Yandex Research совместно с соавторами из других компаний. Это пример метода, который комбинирует все идеи, рассмотренные выше. Он позволяет сжимать веса LLM в 3- или 4-битный формат почти без потери качества.
SPQR опирается на две ключевые идеи: изоляцию выбросов и квантизацию маленькими блоками. С первой идеей мы уже встречались. Но в отличие от LLM.Int8, здесь предлагается не изолировать целые колонки, а отделить только выбросы и сохранить их в разреженной матрице.
Для квантизации маленькими блоками используется та же техника post-training-квантизации, что и в GPTQ, но константы подбирают для блоков по 16 элементов. Они дают большую точность, но закономерно приводят к росту числа констант. У этой проблемы есть красивое решение: все константы для матрицы собирают вместе и квантизуют повторно.
Выбросы хранят в разреженной матрице. Для этого их сначала сортируют по строкам, затем по колонкам и сохраняют в массиве. На каждый выброс уходит 32 бита: 16 бит на само значение и 16 бит на индекс колонки в матрице. Для каждой строки дополнительно хранят 32-битное целое значение — число выбросов в этой строке.
Во время inference веса деквантизуют в 16-битное вещественное представление. Авторы предлагают эффективную GPU-реализацию алгоритма декодирования SPQR-формата. Регрессионные LLM являются memory-bound, поэтому высокая степень сжатия компенсирует вычислительные расходы на декодирование.
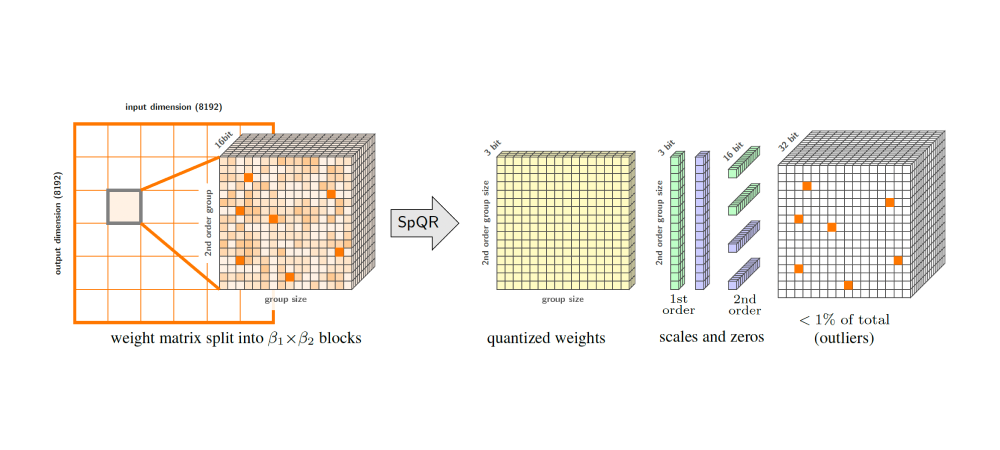
Подробнее об этом методе можно узнать в GitHub.
QLoRA
До этого мы рассматривали квантизацию для inference. Метод QLoRA предлагает применить её на этапе fine-tuning. По традиции, ссылка на GitHub прилагается.
Рассмотрим идею оригинальной LoRA. Это один из методов Parameter-Efficient Fine-Tuning. Представим, что у нас есть большая языковая модель и её нужно файнтюнить под задачу. Дообучать всю модель сложно и дорого. Вместо этого можно учить маленькие skip-connection блоки-адаптеры. Веса базовой модели замораживают, в то время как градиенты протекают через сеть до изменяемых адаптеров.
Авторы QLoRA предлагают учить факторизованные адаптеры и показывают эффективность этого метода. Вместо большой матрицы  можно использовать две матрицы:
можно использовать две матрицы:  и
и  , где
, где  меньше
меньше  . Типичное значение >= 768, а LoRA эффективно работает уже при = 20.
. Типичное значение >= 768, а LoRA эффективно работает уже при = 20.
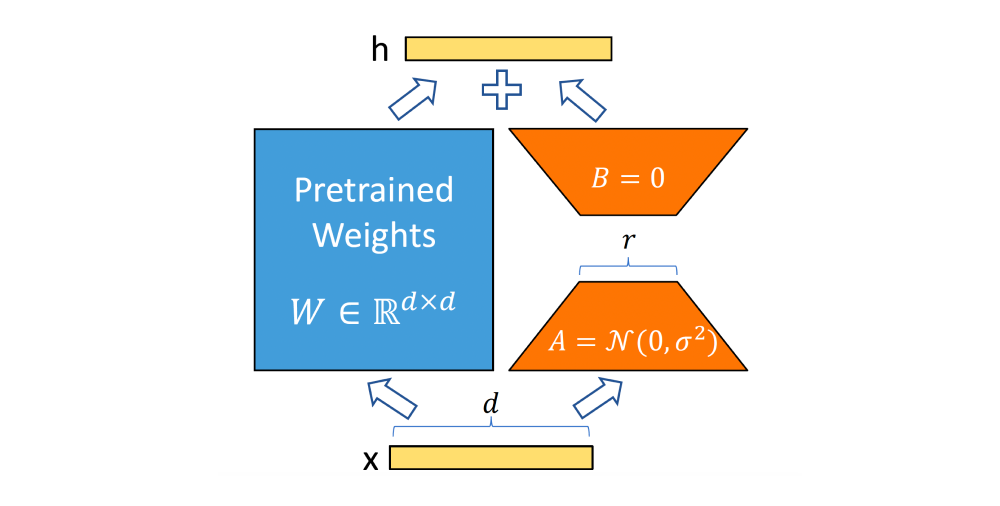
Авторы QLoRA предлагают перед обучением адаптеров квантизовать базовую модель. Веса модели квантизуют в NF4, который мы рассмотрели в разделе, посвящённом типам данных. Квантизацию выполняют малыми блоками по 64 элемента, константы квантизуют повторно блоками по 256. В адаптерах нужна большая точность, поэтому их хранят в формате BF16. Во время fine-tuning NF4-значения деквантизуют и применяют к ним матричные операции в BF16.

где

Вместо заключения
Вот, пожалуй, вся информация о способах квантизации больших моделей, которой я хотел поделиться. Надеюсь, этот экскурс оказался вам полезен. Сохраните его в закладках, чтобы ссылки на статьи и проекты на GitHub всегда были под рукой. Думаю, с этим маленьким справочником вам будет чуть проще выбрать наиболее подходящий метод квантизации. Помните, все подходы по-своему хороши, главное — правильно их «готовить» ;)
Под спойлером собрал много полезных материалов, которые помогут ещё глубже нырнуть в тему квантизации.
Делитесь своими мнениями и личным опытом в комментариях — буду рад подискутировать со всеми, кому тема квантизации интересна так же, как и мне!
