 Недавняя статья про новую систему сборки для Qt напомнила мне ситуацию, которая была в нашем проекте несколько лет назад — тогда мы тоже искали подходящую систему сборки. Проект довольно комплексный и ему необходимо иметь гибкую систему конфигурирования. В результате сейчас мы используем и развиваем собственную систему сборки Mybuild.
Недавняя статья про новую систему сборки для Qt напомнила мне ситуацию, которая была в нашем проекте несколько лет назад — тогда мы тоже искали подходящую систему сборки. Проект довольно комплексный и ему необходимо иметь гибкую систему конфигурирования. В результате сейчас мы используем и развиваем собственную систему сборки Mybuild.Кому интересно узнать, что у нас получилось, и что это за проект такой, которому понадобилась собственная система сборки, добро пожаловать под кат.
О проекте
 Проект наш называется Embox. Это модульная и конфигурируемая ОС для встроенных систем. Как видите, конфигурируемость изначально заложена в идею проекта, отсюда вытекает и желание иметь гибкую систему сборки.
Проект наш называется Embox. Это модульная и конфигурируемая ОС для встроенных систем. Как видите, конфигурируемость изначально заложена в идею проекта, отсюда вытекает и желание иметь гибкую систему сборки.Изначально проект был маленький (хотя он и сейчас не шибко большой), и нам вполне хватало самописных makefile’ов, в них же мы задавали и все опции конфигурации. С развитием же проекта появились идеи, как бы нам описывать не просто исходники для сборки, а модули, да еще иметь возможность задавать для них параметры, прописывать зависимости и так далее.
Еще одна система сборки
Как это часто бывает, аппетит приходит во время еды. Функциональность (а заодно с ней и костыли) нарастала как снежный ком, поддерживать получившуюся инфраструктуру сборки стало довольно накладно, да и попросту неудобно, и в один прекрасный момент мы решили остановиться и посмотреть сперва на уже готовые решения.
Критику Make и его производных можно посмотреть в статье mapron, о ней я уже упоминал в начале. Добавлю, что в нашем случае рассматривалась еще система сборки Kbuild, используемая в ядре Linux. Позволю себе немного критики в ее адрес.
- Файлы сборки и конфигурации разделены. Поэтому описывать приходится в нескольких местах (Makefile + Kconfig).
- Параметры конфигурации задаются директивами #define, что иногда приводит к "#ifdef nightmare" в коде.
- Отсутствуют пространства имен для опций.
Конечно, есть и преимущества:
- Kbuild поддерживает указание зависимостей между опциям.
- Есть несколько графических (и псевдо-графических) средств конфигурирования.
- Стабильное развитие и поддержка со стороны сообщества.
Так или иначе, на тот момент нам казалось, что такая система слишком сложна для сравнительно небольшого проекта. К тому же, у нас уже были небольшие наработки, и поэтому было принято решение сформулировать требования и попытаться реализовать свою систему сборки.
Итак, хотим, чтобы:
- Модули приложения описывались на простом, интуитивно понятном языке, желательно вместе с доступными опциями конфигурации.
- Описание модуля, по возможности, содержало всю необходимую информацию для его дальнейшего использования, включая пользовательскую документацию, доступные unit-тесты и так далее.
- Система сборки не тянула за собой уйму зависимостей вроде интерпретатора Python или Java-машины.
Так как мы начинали с обычных makefile’ов, то и получившаяся в итоге система сборки написана на чистом GNU Make.
Немного о реализации
Сказав «на чистом GNU Make», я немного слукавил. Если вы хоть раз пробовали написать что-нибудь сложнее примеров из мануала, то наверняка тоже обратили внимание на бедность встроенного языка. Поэтому первое, с чего мы начали, это борьба с убогостью языка. Вообще эта тема заслуживает отдельной статьи в хабе «Ненормальное программирование», здесь я затрону лишь основные моменты (авось кому-нибудь пригодится в своих проектах).
Улучшаем синтаксис Make
Язык Make является line-based, поэтому при написании сложных функций в несколько строк используется обратный слэш. Помимо того, что это просто неудобно, это препятствует использованию комментариев внутри функции, поскольку в Make есть только однострочные комментарии (начинающиеся с решетки и действующие до конца строки).
Исправив это ограничение, теперь мы можем писать многострочные функции без обратных слэшей, используя комментарии внутри функций и индентацию кода (табами или пробелами). Помимо этого мы добавили в язык такие возможности как лямбда-выражения, inline простых функций и другие. Вот как можно теперь переписать, например, функцию переворачивания списка:
Было |
Стало |
|---|---|
|
|
Добавляем ООП
Теперь, когда можно писать более или менее читаемый код, добавим еще одну плюшку. В Make нет типизации, любые данные представляются строкой. Однако в любом приложении имеется потребность структурировать данные, так что мы реализовали набор макросов, позволяющий определять классы, а также функции для создания объектов, вызова методов и т.д. К примеру, следующий код при вызове функции greet выводит «Privet, Habrahabr».
define class-Greeter
$(field greeting,
$(or $(value 1),Hello))
# Arg 1: who to greet.
$(method sayHello,
$(info $(get-field greeting), $1!))
endef
define greet
$(for greeter <- $(new Greeter,Privet),
$(invoke greeter->sayHello,Habrahabr)
$(greeter))# <- Return the instance.
endef
После этих двух улучшений разработка пошла куда быстрее, позволив нам заняться логикой непосредственно системы сборки.
Думаем над синтаксисом
Для начала нужно определиться с языком для описания модулей и конфигураций. Как правило, для нового языка используют внутренний или внешний DSL. Внутренний DSL — это подмножество какого-нибудь языка общего назначения, обычно того, который планируется использовать для интерпретации. В случае GNU Make и его корявого языка это совсем не вариант, и остается только внешний DSL, то есть самостоятельный язык для описания сборки.
Не буду ходить вокруг да около и сразу скажу, что получившийся в итоге язык сильно напоминает Java. Лично мне нравится синтаксис Java, он хоть и многословный, зато во многом простой и понятный. Как и в Java, в Mybuild DSL есть пакеты и импорты, а описание модуля похоже на описание класса. Файлы, написанные на этом языке, мы называем my-файлами (по их расширению).
/* Our first example */
module HelloWorld {
source "hello.c"
}
Строим парсер языка
Теперь нужно реализовать парсер этого языка. Тут тоже множество вариантов, начиная от самописного парсера, использующего, к примеру, метод рекурсивного спуска или какую-нибудь библиотеку комбинаторов, и заканчивая различными генераторами парсеров. В результате нескольких экспериментов мы остановились на последнем варианте, как на наиболее общем, а следовательно, удобном для разработки, особенно на этапе активного развития языка. В качестве генератора мы взяли GOLD Parser Builder (http://goldparser.org/), он использует простой язык описания грамматики, имеет встроенный отладчик, а главное, в нем есть возможность гибко настраивать генерируемый парсер (в нашем случае он тоже реализован на Make).
Результат работы парсера — дерево разбора.

Строим объектную модель
Итак, хочется извлекать из my-файлов как можно больше информации, а также иметь к ней простой доступ на всех этапах сборки. Ясно, что нужно иметь какое-то внутреннее представление. То есть теперь нужно превратить дерево разбора в семантическую модель.
Примерно на этой же стадии мы параллельно задумались о поддержке языка со стороны какой-либо IDE. В нашем случае это Eclipse, поскольку более половины разработчиков в проекте использует именно эту среду. Для разработки плагина мы использовали фреймворк Xtext, который по грамматике умеет генерировать полноценный редактор с подсветкой синтаксиса, автодополнением и прочими радостями современной IDE. Здесь стоит сказать, что сам Xtext базируется на EMF — известном фреймворке для моделирования. Это натолкнуло на мысль использовать технологию EMF и для разработки самой системы сборки.
Таким образом, мы получаем EMF модель, описывающую структуру нашего DSL, (ее нам любезно сгенерировал Xtext). Теперь нужно модель превратить в классы на Make. Тут нам на помощь приходит проект Xpand (его разрабатывает та же компания, что и Xtext), который позволяет по шаблону генерировать из модели текст.
Последним шагом является написание glue-кода, создающего объекты модели для необходимых узлов дерева разбора.
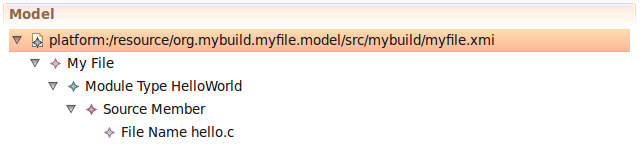
Вернемся к требованиям
Зависимости
Одним из первых пунктов в наших требованиях была возможность определения межмодульных зависимостей. В первую очередь это необходимо для упрощения конфигурирования конечного приложения пользователем.
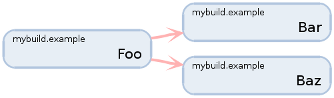
В my-файле обозначение зависимости производится следующим образом.
module Foo {
depends Bar, Baz
}
Теперь, когда у нас есть полный граф всех описанных в проекте модулей, построение замыкания подграфа требуемых модулей реализуется довольно просто.
Для удобства разработки Mybuild умеет визуализировать граф модулей, используя Graphviz. И как пример, вот визуализация графа модулей для одной из простых конфигураций Embox.

Порядок загрузки в runtime
Имея полное представление о модулях системы и зависимостях между ними, почему бы не использовать эти знания для чего-нибудь помимо собственно сборки проекта? К примеру, на основе этой информации можно определить порядок загрузки модулей во время исполнения системы. Действительно, ведь как правило загружать модуль имеет смысл только после загрузки всех его зависимостей.
Для этого в сборку включается специально сгенерированный исходник на Си, в котором статически задаются узлы и ребра графа зависимостей. При компиляции самих модулей имеется возможность ассоциировать с модулем функцию его инициализации, которая будет вызвана диспетчером загрузчики после разрешения всех зависимостей.
Параметры и опции сборки
Следующей задачей, которую мы решили, стало указание параметров для конкретных модулей. Для описания параметра используется конструкция
option, a доступ к значению параметра можно получить по время компиляции, используя специальный макрос. |
|
configuration Main {
include HelloWorld(greeting = "Hello, Habrahabr!")
}
Обработка линкер-скриптов
Следующей проблемой, несколько специфичной для проекта, было то, что мы хотели обрабатывать не только исходные коды (на языках Си и ассемблера) и заголовочные файлы, но и другие ресурсы, в нашем случае это, например, специальные скрипты компоновщика. Makefile для препроцессинга и включения в сборку дополнительного линкер-скрипта в предыдущей версии системы сборки представлял из себя следующее (причем такой код нужно было написать для каждого специального линкер-скрипта).
$(IMAGE): $($_heap_lds)
$($_heap_lds): $($_SELFDIR)/heap.lds.S $(AUTOCONF_DIR)/config.lds.h
@$(MKDIR) $(@D) \
&& $(CPP) -P -undef $(CPPFLAGS) \
-imacros $(AUTOCONF_DIR)/config.lds.h \
-MMD -MT $@ -MF $@.d -o $@ $<
-include $($_heap_lds).d
Сейчас это выглядит вот так, а система сборки сама решает, что делать с файлом «heap.lds.S»:
module HeapAlloc {
source "heap.lds.S"
}
Обработка прочих ресурсов
В предыдущем примере определение типа файла, указанного в source, происходило по его расширению (.lds.S). Иногда же требуется пометить определенные файлы, чтобы они обрабатывались особым образом. К примеру, в нашем проекте это файлы, содержимое которых должно быть доступно во время исполнения.
Тут мы использовали механизм аннотаций, позаимствованный опять же из Java. Первое, что мы реализовали с их помощью, это возможность помечать ресурс как требующий копирования в папку с корневой файловой системой, то есть:
module Httpd {
@ InitFS source "index.html"
}
Аннотации можно задавать для любого типа объектов в нашем системе, будь то модули, их зависимости, файлы с исходным кодом или параметры, а также другие аннотации. Таким образом, мы надеемся, что заложили в язык хорошие возможности для его расширения.
Наследование и абстрактные модули
И наконец, я опишу одну очень интересную, на мой взгляд, фичу, которую мы не встречали в других подобных проектах, а именно возможность задания интерфейсов и их реализаций.
Поскольку у нас сильно конфигурируемая ОС, то нам нужна простая возможность изменять такие системную алгоритмы как, например, стратегия планирования. Не политика планирования, которая задается для каждого процесса с помощью флагов
SCHED_FIFO или SCHED_OTHER, а именно алгоритм, по которому планировщик управляет всеми потоками (возможно, учитывая политику). К примеру, сейчас в проекте реализовано три стратегии планирования. Для самых простых систем можно использовать примитивный планировщик, который не учитывает ни приоритеты, ни другие атрибуты потока. А есть стратегия, которая использует приоритеты и учитывает, сколько уже времени исполнялся поток.Это было маленькое лирическое отступление. Так вот, появилась потребность хотя бы простого наследования, чтобы можно было описывать требования к системе с помощью интерфейсов, а конкретные ее свойства определять с помощью их реализаций. Ну а раз появилась потребность, мы ее и решили таким вот образом:
@ DefaultImpl(TrivialSchedStrategy)
abstract module SchedStrategy { }
module TrivialSchedStrategy extends SchedStrategy {
source "trivial.c", "trivial.h"
}
module PriorityBasedSchedStrategy extends SchedStrategy {
source "priority_based.c", "priority_based.h"
}
Как видите, здесь тоже не обошлось без аннотации (
@DefaultImpl), в данном случае, если в конфигурации нет явного указания модуля, реализующего SchedStrategy, то по умолчанию используется модуль TrivialSchedStrategy.Заключение
Это конечно не все возможности нашей системы, например, еще можно указывать для модуля специфичные флаги компиляции, ассоциировать с ним набор unit-тестов и так далее. Но боюсь, что статья и так получилась перегруженной, поэтому, кому интересно узнать о Mybuild подробнее, возможно, пощупать руками или даже заглянуть в код, тот может найти больше информации на вики проекта.
Конечно, много еще предстоит реализовать и отшлифовать. Как минимум, мы пока не пробовали отвязать Mybuild от родительского проекта Embox, по некоторым кускам не хватает документации и так далее.
Ссылки
Спасибо, что дочитали до конца, буду рад ответить на ваши вопросы и предложения в комментариях.
