Компания CleverDATA занимается разработкой платформы для работы с большими данными. В частности, на нашей платформе есть возможность работать с информацией из чеков онлайн-покупок. Перед нами стояла задача научиться обрабатывать текстовые данные чеков и строить на них выводы о потребителях для создания соответствующих характеристик на бирже данных. Было естественно для решения этой задачи обратиться к машинному обучению. В этой статье мы хотим рассказать про проблемы, с которыми встретились при классификации текстов онлайн-чеков.
 Источник
Источник
Наша компания разрабатывает решения для монетизации данных. Одним из наших продуктов является биржа данных 1DMC, которая позволяет обогащать данные из внешних источников (более 9000 источников, ее суточная аудитория — около 100 млн профилей). Задачи, которые 1DMC помогает решать, хорошо знакомы маркетологам: построение look-alike-сегментов, медийных компаний широкого охвата, таргетинговых рекламных кампаний на узкоспециализированную аудиторию и т.д. Если ваше поведение близко к поведению целевой аудитории какого-либо магазина, то вы с высокой вероятностью попадете в look-alike сегмент. Если была зафиксирована информация о вашем пристрастии к какой-либо области интересов, то вы можете попасть в узкоспециализированную таргетированную рекламную кампанию. При этом выполняются все законы о персональных данных, вы получаете более релевантную вашим интересам рекламу, а компании эффективно используют свой бюджет на привлечение клиентов.
Информация о профилях хранится на бирже в виде различных интерпретируемых человеком атрибутов:

Это может быть информация о том, что человек владеет мототехникой, например, мотоциклом чоппером. Или о том, что у человека есть интерес к еде определенного типа, например, он вегетарианец.
Недавно 1DMC получила данные от одного из операторов фискальных данных. Для того, чтобы представить их в виде атрибутов профиля биржи, появилась необходимость работать с текстами чеков в сыром виде. Вот типичный текст чека одного из покупателей:

Таким образом, задачей является сопоставление чека с атрибутами. Привлекая машинное обучение для решения описанной задачи, в первую очередь возникает желание попробовать методы обучения без учителя (Unsupervised Learning). Учителем является информация о правильных ответах, а так как мы не обладаем этой информацией, то методы обучения без учителя могли бы хорошо подойти под решаемый случай. Типичным методом обучения без учителя является кластеризация, благодаря которому обучающая выборка разбивается на устойчивые группы или кластеры. В нашем случае после кластеризации текстов по словам далее придется сопоставлять полученные кластеры с атрибутами. Количество уникальных атрибутов достаточно велико, поэтому было желательно избежать ручной разметки. Другой подход обучения без учителя для текстов называется тематическим моделированием (topic modeling), позволяющим выявить в неразмеченных текстах основные тематики. После использования тематического моделирования потребуется сопоставить полученные тематики с атрибутами, чего также хотелось избежать. Кроме того, возможно использовать семантическую близость между текстом чека и текстовым описанием атрибута на основе какой-либо языковой модели. Однако проведенные эксперименты показали, что качество моделей на основе семантической близости для наших задач не подходит. С точки зрения бизнеса, нужно быть уверенным, что человек увлекается джиу-джитсу и именно для этого он покупает спортивные товары. Промежуточные, спорные и сомнительные выводы выгоднее не использовать. Таким образом, к сожалению, для выполнения поставленной задачи методы unsupervised learning не подходят.
Если отказываемся от методов unsupervised learning, то логично обратиться к методам обучения с учителем (supervised learning) и в частности к классификации. Учителем является информация о истинных классах, и типичный подход - провести многоклассовую классификацию, но в данном случае задача осложняется тем, что получается слишком большое количество классов (по количеству уникальных атрибутов). Есть и другая особенность: атрибуты могут срабатывать на одних и тех же текстах несколькими группами, т.е. классификация должна быть multilabel. Например, информация о том, что человек купил чехол для смартфона, может содержать такие атрибуты, как: человек — владелец устройства типа Samsung, с телефоном модели Galaxy, покупает атрибуты Deppa Sky Case, и вообще покупает аксессуары для телефонов. То есть в профиле должно быть зафиксировано сразу несколько атрибутов данного человека.
Для перевода задачи в категорию «обучение с учителем» необходимо получить разметку. Когда люди сталкиваются с такой проблемой, они нанимают асессоров и в обмен на деньги и время получают хорошую разметку и строят по разметке предсказательные модели. Потом нередко оказывается, что разметка была с ошибками, а асессоров необходимо подключать к работе регулярно, т.к. появляются новые атрибуты и новые поставщики данных. Альтернативный способ — использование «Яндекс. Толоки». Он позволяет снизить расходы на асессоров, однако не гарантирует качество.
Всегда есть вариант найти новый подход, и было принято решение пойти именно этим путём. Если бы существовал набор текстов для одного атрибута, тогда была бы возможность построить модель бинарной классификации. Тексты для каждого атрибута можно получить из поисковых запросов, а для поиска можно использовать текстовое описание атрибута, которое есть в таксономии. На этом этапе встречаем следующую особенность: тексты на выходе оказываются не настолько разнообразны, чтобы по ним построить сильную модель, и для получения разнообразных текстов имеет смысл прибегнуть к текстовой аугментации.
Для текстовой аугментации логично воспользоваться языковой моделью. Результатом работы языковой модели являются эмбеддинги — это отображение из пространства слов в пространство векторов конкретной фиксированной длины, причем векторы, соответствующие близким по смыслу словам, будут расположены в новом пространстве рядом, а далекие по смыслу — далеко. Для задачи текстовой аугментации это свойство является ключевым, ведь в данном случае необходимо искать синонимы. Для случайного множества слов в названии атрибута таксономии сэмплируем случайное подмножество похожих элементов из пространства представлений текста.

Давайте рассмотрим аугментацию на примере. У человека есть интерес к мистическому жанру кино. Сэмплируем выборку, получается разнообразный набор текстов, который можно отправлять в краулер и собирать поисковую выдачу. Это будет положительная выборка для обучения классификатора.

А отрицательную выборку подбираем проще, семплируем такое же количество атрибутов, не относящихся к теме кино:

При использовании TF-IDF (например, вот) подхода с фильтром по частотам и логистической регрессии уже можно получить прекрасные результаты: изначально в краулер отправлялись очень разные тексты, и модель прекрасно справляется. Безусловно, необходимо проверять работу модели на реальных данных, ниже приводим результат работы модели по атрибуту «интерес к покупке техники марки AEG».

В каждой строке есть слова AEG, модель справилась без ложных срабатываний. Однако если возьмём более сложный случай, например, автомобиль ГАЗ, то встретим проблему: модель ориентируется на ключевые слова и не использует контекст.
Построим на модель интереса к дополнительному образованию — курсам профессиональной переподготовки.

Курс уроков волшебства для обычного кота является также сложным случаем, который и человека может ввести в заблуждение.
Для фильтрации ложных срабатываний воспользуемся эмбедингами: вычислим центр положительной выборки в пространстве эмбеддингов и измерим расстояние до него для каждой строчки.

Разница в расстояниях для курсов уроков волшебства и приобретения конспектов видна невооруженным взглядом.
Другой пример: владельцы автомобилей марки Audi. Расстояние в пространстве эмбеддингов и в этом случае спасает от ложных срабатываний.

На текущий день биржа данных оперирует порядка 30 тыс. атрибутов, и регулярно появляются новые. Вполне очевидна потребность в автоматизации тренировки новых моделей и разметки по новым атрибутам. Последовательность действий для построения модели нового атрибута выглядит следующим образом:
В описанном выше алгоритме есть ряд слабых мест:
Важно понимать, что для контроля качества обученной модели не подходят классические метрики, т.к. отсутствует информация об истинных классах в текстах чеков. Обучение и предсказание происходят на разных данных, измерить качество модели можно на тренировочной выборке, а на корпусе основных текстов нет разметки, а значит нельзя привычными методами оценить качество.
Для оценки качества натренированной модели возьмем две популяции: одна относится к объектам ниже порога срабатывания модели, вторая относится к объектам, на которых модель дала оценку выше порога.
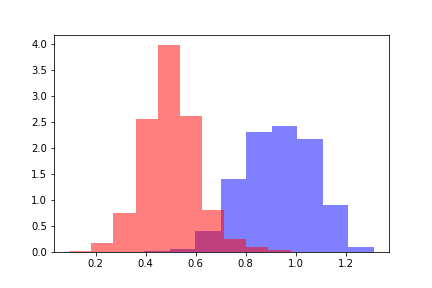
Для каждой из популяций рассчитаем word2vec расстояние до центра положительной обучающей выборки. Получим два распределения расстояний, которые выглядят следующим образом.
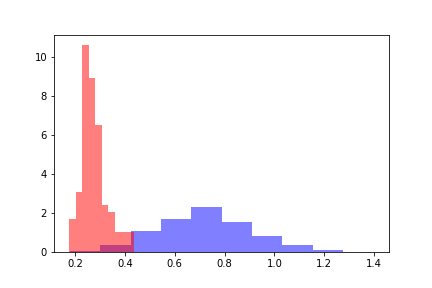
Красным цветом обозначено распределение дистанций для объектов, перешедших порог, а синим — объекты ниже порога по оценке модели. Распределения можно разделить, и для оценки расстояния между распределениями в первую очередь логично обратиться к Дивергенции Кульбака-Лейблера (ДКЛ). ДКЛ представляет из себя несимметричный функционал, на нем не выполняется неравенство треугольника. Это ограничение осложняет использование ДКЛ в качестве метрики, однако ею можно пользоваться, если она отражает необходимую зависимость. В нашем случае ДКЛ принимала константные значения на всех моделях вне зависимости от значений порогов, поэтому появилась необходимость искать другие методы.
Для оценки расстояний между распределениями вычислим разность между средними значениями распределений. Полученную разность измерим в средних квадратичных отклонениях исходного распределения расстояний. Обозначим полученную величину Z-метрикой по аналогии с Z-value, при этом величина Z-метрики будет функцией от порогового значения предсказательной модели. Для каждого фиксированного порога модели Z-метрика функция возвращает разницу между распределениями в сигмах исходного распределения расстояний.
Из множества опробованных подходов именно Z-метрика дала необходимую зависимость для определения качества построенной модели.
Рассмотрим поведение Z-метрики: чем больше Z-метрика, тем лучше справилась модель, потому что большее расстояние между распределениями характеризует качественную классификацию. Однако четко выраженного решающего правила для определения качественной классификации вывести не удалось. Например, модель с Z-метрикой в левом нижнем углу рисунка получает константное значение, равное 10. Эта модель определяет интерес к путешествию в Тайланд. В обучающую выборку попала преимущественно реклама различных спа-салонов, и модель была обучена на текстах, не имеющих прямого отношения к поездкам в Тайланд. Т. е. модель сработала хорошо, однако интерес к поездкам в Тайланд она не отражает.
 Z-метика для ряда предсказательных моделей. Модели в правой половине картинки — хорошие, а пять моделей в левой половине — плохие.
Z-метика для ряда предсказательных моделей. Модели в правой половине картинки — хорошие, а пять моделей в левой половине — плохие.
За время поисков и экспериментов накопилось 160 моделей с разметкой по критерию «хороший/плохой». По признакам z-метрики была построена мета-модель на основе градиентного бустинга, определяющая качество построенной модели. Таким образом была получена возможность настроить мониторинг качества моделей, строящихся в автоматическом режиме.
На данный момент последовательность действий выглядит следующим образом:
По оценке мета-модели в автоматическом режиме принимается решение о внедрении в продакшен либо о возвращении на доработку. Доработка возможна различными путями, которые были выведены для аналитика.
В первую очередь было желание для описанной задачи использовать нейронные сети. Например, можно было бы обучить Transformer на большом корпусе текстов, а затем сделать Learning Transfer на совокупности малых обучающих выборок от каждого атрибута. К сожалению, от использования подобной нейронной сети пришлось отказаться по следующим причинам.
Таким образом, ансамбль независимых небольших моделей для решения задачи оказался практичнее, чем большая и сложная модель. Кроме того, все же используется языковая модель и эмбеддинги для контроля качества и текстовой аугментации, поэтому полностью уйти от использования нейронных сетей не удалось, да и не было такой цели. Использование нейронных сетей ограничивается задачами, в которых они требуются.
Работа над проектом продолжается: необходимо организовать мониторинг, обновление моделей, работу с аномалиями и т.п. Одним из приоритетных направлений для дальнейшего развития является задача сбора и анализа тех случаев, которые не прошли классификацию ни одной моделью из ансамбля. Тем не менее, уже сейчас мы видим результаты наших трудов: порядка 60% чеков после применения моделей получают свои атрибуты. Очевидно, что есть существенная доля чеков, не несущих информации об интересах владельцев, поэтому стопроцентный уровень недостижим. Тем не менее, радует, что полученный на текущий момент результат уже превосходит наши ожидания и мы продолжаем работу в этом направлении.
Статья написана в соавторстве с samy1010.
Наша компания разрабатывает решения для монетизации данных. Одним из наших продуктов является биржа данных 1DMC, которая позволяет обогащать данные из внешних источников (более 9000 источников, ее суточная аудитория — около 100 млн профилей). Задачи, которые 1DMC помогает решать, хорошо знакомы маркетологам: построение look-alike-сегментов, медийных компаний широкого охвата, таргетинговых рекламных кампаний на узкоспециализированную аудиторию и т.д. Если ваше поведение близко к поведению целевой аудитории какого-либо магазина, то вы с высокой вероятностью попадете в look-alike сегмент. Если была зафиксирована информация о вашем пристрастии к какой-либо области интересов, то вы можете попасть в узкоспециализированную таргетированную рекламную кампанию. При этом выполняются все законы о персональных данных, вы получаете более релевантную вашим интересам рекламу, а компании эффективно используют свой бюджет на привлечение клиентов.
Информация о профилях хранится на бирже в виде различных интерпретируемых человеком атрибутов:
Это может быть информация о том, что человек владеет мототехникой, например, мотоциклом чоппером. Или о том, что у человека есть интерес к еде определенного типа, например, он вегетарианец.
Постановка задачи и пути её решения
Недавно 1DMC получила данные от одного из операторов фискальных данных. Для того, чтобы представить их в виде атрибутов профиля биржи, появилась необходимость работать с текстами чеков в сыром виде. Вот типичный текст чека одного из покупателей:
Таким образом, задачей является сопоставление чека с атрибутами. Привлекая машинное обучение для решения описанной задачи, в первую очередь возникает желание попробовать методы обучения без учителя (Unsupervised Learning). Учителем является информация о правильных ответах, а так как мы не обладаем этой информацией, то методы обучения без учителя могли бы хорошо подойти под решаемый случай. Типичным методом обучения без учителя является кластеризация, благодаря которому обучающая выборка разбивается на устойчивые группы или кластеры. В нашем случае после кластеризации текстов по словам далее придется сопоставлять полученные кластеры с атрибутами. Количество уникальных атрибутов достаточно велико, поэтому было желательно избежать ручной разметки. Другой подход обучения без учителя для текстов называется тематическим моделированием (topic modeling), позволяющим выявить в неразмеченных текстах основные тематики. После использования тематического моделирования потребуется сопоставить полученные тематики с атрибутами, чего также хотелось избежать. Кроме того, возможно использовать семантическую близость между текстом чека и текстовым описанием атрибута на основе какой-либо языковой модели. Однако проведенные эксперименты показали, что качество моделей на основе семантической близости для наших задач не подходит. С точки зрения бизнеса, нужно быть уверенным, что человек увлекается джиу-джитсу и именно для этого он покупает спортивные товары. Промежуточные, спорные и сомнительные выводы выгоднее не использовать. Таким образом, к сожалению, для выполнения поставленной задачи методы unsupervised learning не подходят.
Если отказываемся от методов unsupervised learning, то логично обратиться к методам обучения с учителем (supervised learning) и в частности к классификации. Учителем является информация о истинных классах, и типичный подход - провести многоклассовую классификацию, но в данном случае задача осложняется тем, что получается слишком большое количество классов (по количеству уникальных атрибутов). Есть и другая особенность: атрибуты могут срабатывать на одних и тех же текстах несколькими группами, т.е. классификация должна быть multilabel. Например, информация о том, что человек купил чехол для смартфона, может содержать такие атрибуты, как: человек — владелец устройства типа Samsung, с телефоном модели Galaxy, покупает атрибуты Deppa Sky Case, и вообще покупает аксессуары для телефонов. То есть в профиле должно быть зафиксировано сразу несколько атрибутов данного человека.
Для перевода задачи в категорию «обучение с учителем» необходимо получить разметку. Когда люди сталкиваются с такой проблемой, они нанимают асессоров и в обмен на деньги и время получают хорошую разметку и строят по разметке предсказательные модели. Потом нередко оказывается, что разметка была с ошибками, а асессоров необходимо подключать к работе регулярно, т.к. появляются новые атрибуты и новые поставщики данных. Альтернативный способ — использование «Яндекс. Толоки». Он позволяет снизить расходы на асессоров, однако не гарантирует качество.
Всегда есть вариант найти новый подход, и было принято решение пойти именно этим путём. Если бы существовал набор текстов для одного атрибута, тогда была бы возможность построить модель бинарной классификации. Тексты для каждого атрибута можно получить из поисковых запросов, а для поиска можно использовать текстовое описание атрибута, которое есть в таксономии. На этом этапе встречаем следующую особенность: тексты на выходе оказываются не настолько разнообразны, чтобы по ним построить сильную модель, и для получения разнообразных текстов имеет смысл прибегнуть к текстовой аугментации.
Текстовая аугментация
Для текстовой аугментации логично воспользоваться языковой моделью. Результатом работы языковой модели являются эмбеддинги — это отображение из пространства слов в пространство векторов конкретной фиксированной длины, причем векторы, соответствующие близким по смыслу словам, будут расположены в новом пространстве рядом, а далекие по смыслу — далеко. Для задачи текстовой аугментации это свойство является ключевым, ведь в данном случае необходимо искать синонимы. Для случайного множества слов в названии атрибута таксономии сэмплируем случайное подмножество похожих элементов из пространства представлений текста.
Давайте рассмотрим аугментацию на примере. У человека есть интерес к мистическому жанру кино. Сэмплируем выборку, получается разнообразный набор текстов, который можно отправлять в краулер и собирать поисковую выдачу. Это будет положительная выборка для обучения классификатора.
А отрицательную выборку подбираем проще, семплируем такое же количество атрибутов, не относящихся к теме кино:
Тренировка модели
При использовании TF-IDF (например, вот) подхода с фильтром по частотам и логистической регрессии уже можно получить прекрасные результаты: изначально в краулер отправлялись очень разные тексты, и модель прекрасно справляется. Безусловно, необходимо проверять работу модели на реальных данных, ниже приводим результат работы модели по атрибуту «интерес к покупке техники марки AEG».
В каждой строке есть слова AEG, модель справилась без ложных срабатываний. Однако если возьмём более сложный случай, например, автомобиль ГАЗ, то встретим проблему: модель ориентируется на ключевые слова и не использует контекст.
Работа с ошибками
Построим на модель интереса к дополнительному образованию — курсам профессиональной переподготовки.
Курс уроков волшебства для обычного кота является также сложным случаем, который и человека может ввести в заблуждение.
Для фильтрации ложных срабатываний воспользуемся эмбедингами: вычислим центр положительной выборки в пространстве эмбеддингов и измерим расстояние до него для каждой строчки.
Разница в расстояниях для курсов уроков волшебства и приобретения конспектов видна невооруженным взглядом.
Другой пример: владельцы автомобилей марки Audi. Расстояние в пространстве эмбеддингов и в этом случае спасает от ложных срабатываний.
Вопрос масштабируемости
На текущий день биржа данных оперирует порядка 30 тыс. атрибутов, и регулярно появляются новые. Вполне очевидна потребность в автоматизации тренировки новых моделей и разметки по новым атрибутам. Последовательность действий для построения модели нового атрибута выглядит следующим образом:
- берем название атрибута из таксономии;
- создаем список запросов в поисковую систему, пользуясь текстовой аугментацией;
- краулим текстовую выборку;
- обучаем модель классификации на полученной выборке;
- скорим обученной моделью сырые данные о покупках;
- фильтруем результат по word2vec расстоянию до центра положительного класса.
В описанном выше алгоритме есть ряд слабых мест:
- сложно контролировать корпус текстов, который краулится;
- затруднен контроль качества обучающей выборки;
- нет возможности определить, хорошо ли обученная модель справляется со своей задачей.
Важно понимать, что для контроля качества обученной модели не подходят классические метрики, т.к. отсутствует информация об истинных классах в текстах чеков. Обучение и предсказание происходят на разных данных, измерить качество модели можно на тренировочной выборке, а на корпусе основных текстов нет разметки, а значит нельзя привычными методами оценить качество.
Оценка качества модели
Для оценки качества натренированной модели возьмем две популяции: одна относится к объектам ниже порога срабатывания модели, вторая относится к объектам, на которых модель дала оценку выше порога.
Для каждой из популяций рассчитаем word2vec расстояние до центра положительной обучающей выборки. Получим два распределения расстояний, которые выглядят следующим образом.
Красным цветом обозначено распределение дистанций для объектов, перешедших порог, а синим — объекты ниже порога по оценке модели. Распределения можно разделить, и для оценки расстояния между распределениями в первую очередь логично обратиться к Дивергенции Кульбака-Лейблера (ДКЛ). ДКЛ представляет из себя несимметричный функционал, на нем не выполняется неравенство треугольника. Это ограничение осложняет использование ДКЛ в качестве метрики, однако ею можно пользоваться, если она отражает необходимую зависимость. В нашем случае ДКЛ принимала константные значения на всех моделях вне зависимости от значений порогов, поэтому появилась необходимость искать другие методы.
Для оценки расстояний между распределениями вычислим разность между средними значениями распределений. Полученную разность измерим в средних квадратичных отклонениях исходного распределения расстояний. Обозначим полученную величину Z-метрикой по аналогии с Z-value, при этом величина Z-метрики будет функцией от порогового значения предсказательной модели. Для каждого фиксированного порога модели Z-метрика функция возвращает разницу между распределениями в сигмах исходного распределения расстояний.
Из множества опробованных подходов именно Z-метрика дала необходимую зависимость для определения качества построенной модели.
Рассмотрим поведение Z-метрики: чем больше Z-метрика, тем лучше справилась модель, потому что большее расстояние между распределениями характеризует качественную классификацию. Однако четко выраженного решающего правила для определения качественной классификации вывести не удалось. Например, модель с Z-метрикой в левом нижнем углу рисунка получает константное значение, равное 10. Эта модель определяет интерес к путешествию в Тайланд. В обучающую выборку попала преимущественно реклама различных спа-салонов, и модель была обучена на текстах, не имеющих прямого отношения к поездкам в Тайланд. Т. е. модель сработала хорошо, однако интерес к поездкам в Тайланд она не отражает.
За время поисков и экспериментов накопилось 160 моделей с разметкой по критерию «хороший/плохой». По признакам z-метрики была построена мета-модель на основе градиентного бустинга, определяющая качество построенной модели. Таким образом была получена возможность настроить мониторинг качества моделей, строящихся в автоматическом режиме.
Итоги
На данный момент последовательность действий выглядит следующим образом:
- берем название атрибута из таксономии;
- создаем список запросов в поисковую систему, пользуясь текстовой аугментацией;
- краулим текстовую выборку;
- обучаем модель классификации на полученной выборке;
- скорим обученной моделью сырые данные о покупках;
- фильтруем результат по word2vec расстоянию до центра положительного класса;
- рассчитываем Z-метрику и строим признаки для мета-модели;
- используем мета-модель и оцениваем качество полученной модели;
- если модель оказывается приемлемого качества, то она добавляется в набор используемых моделей. Иначе, модель возвращается на доработку.
По оценке мета-модели в автоматическом режиме принимается решение о внедрении в продакшен либо о возвращении на доработку. Доработка возможна различными путями, которые были выведены для аналитика.
- Часто модели мешают определенные слова, имеющие несколько смыслов. «Черный список» обманчивых слов облегчает работу модели.
- Другой подход заключается в создании правила для исключения объектов из обучающей выборки. Этот подход помогает, если не работает первый способ.
- Для сложных текстов и многозначных атрибутов передается в модель конкретный словарь, что ограничивает модель, но позволяет контролировать ошибки.
А как же нейронные сети?
В первую очередь было желание для описанной задачи использовать нейронные сети. Например, можно было бы обучить Transformer на большом корпусе текстов, а затем сделать Learning Transfer на совокупности малых обучающих выборок от каждого атрибута. К сожалению, от использования подобной нейронной сети пришлось отказаться по следующим причинам.
- Если перестает правильно работать модель для одного атрибута, то необходимо иметь возможность её отключить без потерь для остальных атрибутов.
- Если модель работает плохо для одного атрибута, то необходимо подстраивать и тюнить модель изолированно, без риска испортить результат для других атрибутов.
- При появлении нового атрибута необходимо в кратчайшие сроки получить модель для него, без долговременной тренировки всех моделей (или одной большой модели).
- Решить задачу контроля качества для одного атрибута быстрее и проще, чем решать задачу контроля качества для всех атрибутов сразу. В случае, если большая модель не справляется с одним из атрибутов, придется тюнить и подстраивать всю большую модель, на что требует больше времени и внимания специалиста.
Таким образом, ансамбль независимых небольших моделей для решения задачи оказался практичнее, чем большая и сложная модель. Кроме того, все же используется языковая модель и эмбеддинги для контроля качества и текстовой аугментации, поэтому полностью уйти от использования нейронных сетей не удалось, да и не было такой цели. Использование нейронных сетей ограничивается задачами, в которых они требуются.
Продолжение следует
Работа над проектом продолжается: необходимо организовать мониторинг, обновление моделей, работу с аномалиями и т.п. Одним из приоритетных направлений для дальнейшего развития является задача сбора и анализа тех случаев, которые не прошли классификацию ни одной моделью из ансамбля. Тем не менее, уже сейчас мы видим результаты наших трудов: порядка 60% чеков после применения моделей получают свои атрибуты. Очевидно, что есть существенная доля чеков, не несущих информации об интересах владельцев, поэтому стопроцентный уровень недостижим. Тем не менее, радует, что полученный на текущий момент результат уже превосходит наши ожидания и мы продолжаем работу в этом направлении.
Статья написана в соавторстве с samy1010.
И традиционные вакансии!
