На WWDC’17 Apple представила новый фреймворк для работы с технологиями машинного обучения Core ML. На основе него в iOS реализованы собственные продукты Apple: Siri, Camera и QuickType. Core ML позволяет упростить интеграцию машинного обучения в приложения и создавать различные «умные» функции с помощью пары строчек кода.

Возможности Core ML
С помощью Core ML в приложении можно реализовать следующие функции:
- распознавание изображений в реальном времени;
- предиктивный ввод текста;
- распознавание образов;
- анализ тональности;
- распознавание рукописного текста;
- ранжирование поиска;
- стилизация изображений;
- распознавание лиц;
- идентификация голоса;
- определение музыки;
- реферирование текста;
- и не только.
Core ML позволяет легко импортировать в ваше приложение различные алгоритмы машинного обучения, такие как: tree ensembles, SVMs и generalized linear models. Он использует низкоуровневые технологии, такие как Metal, Accelerate и BNNS. Результаты вычислений происходят почти мгновенно.
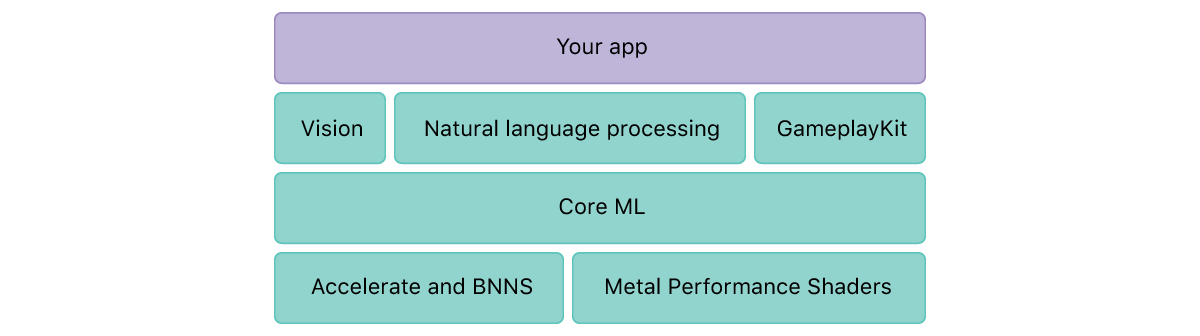
Vision
Фреймворк Vision работает на основе Core ML и помогает с отслеживанием и распознаванием лиц, текста, объектов, штрих-кодов. Также доступно определение горизонта и получение матрицы для выравнивания изображения.
NSLinguisticTagger
С iOS 5 Apple представила NSLinguisticTagger, который позволяет анализировать естественный язык, поддерживает множество языков и алфавитов. C выходом iOS 11 класс усовершенствовали, теперь ему можно скормить строку с текстом на разных языках и он вернет доминирующий язык в этой строке и еще много других улучшений. NSLinguisticTagger тоже использует машинное обучение для глубокого понимания текста и его анализа.
Core ML Model
На промо странице Core ML Apple предоставила 4 модели. Все они анализируют изображения. Модели Core ML работают локально и оптимизированы для работы на мобильных устройствах, сводя к минимуму объем используемой памяти и энергопотребление.
Вы можете сгенерировать собственные модели с помощью Core ML Tools.
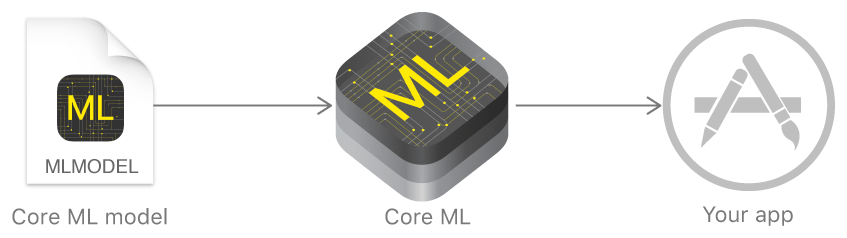
Рабочий способ загружать модели во время выполнения:
- Положить файл модели в таргет приложения.
- Скомпилировать новую модель из .mlmodel в .mlmodelc, не изменяя её интерфейс.
- Положить эти файлы на сервер.
- Скачать их внутри приложения.
- Инициализировать новую модель, например:
CoreMLModelClass.init(contentOf: URL)Работоспособность после выпуска приложения в App Store не протестирована.
Особенности Core ML
- Решение от Apple не может принимать данные и обучать модели. Только принимать некоторые типы обученных моделей, преобразовывать их в собственный формат и делать прогнозы.
- Модель не сжимается.
- Она никак не шифруется. Вам придется позаботиться о защите данных самому.
Тестируем Core ML
Я подготовил тестовый проект с использованием Core ML. Мы сделаем простой локатор котов, который позволит отличить все в этой вселенной от кота.

Создаем проект и выбираем Single View Application. Предварительно нужно скачать Core ML модель, которая и будет анализировать объекты с камеры. В этом проекте я использую Inception v3. Далее нужно перенести модель в Project Navigator, Xcode автоматически сгенерирует интерфейс для нее.
На сториборд добавляем на весь экран View, туда мы будем выводить изображение с камеры. Поверх добавляем Visual Effect View и Label. Прокидываем аутлеты в ViewController.
Не забудьте в plist добавить разрешение на использование камеры.

Нам нужно вывести изображение с камеры в реальном времени, для этого создадим AVCaptureSession и очередь для получения новых кадров DispatchQueue. Добавим на наш View слой AVCaptureVideoPreviewLayer, на него будет выводится изображение с камеры, также нужно создать массив VNRequest — это запросы к Vision. Сразу в viewDidLoad проверим доступность камеры.
import UIKit
import AVFoundation
import Vision
class ViewController: UIViewController {
@IBOutlet var resultLabel: UILabel!
@IBOutlet var resultView: UIView!
let session = AVCaptureSession()
var previewLayer: AVCaptureVideoPreviewLayer!
let captureQueue = DispatchQueue(label: "captureQueue")
var visionRequests = [VNRequest]()
override func viewDidLoad() {
super.viewDidLoad()
guard let camera = AVCaptureDevice.default(for: .video) else {
return
}
do {
previewLayer = AVCaptureVideoPreviewLayer(session: session)
resultView.layer.addSublayer(previewLayer)
} catch {
let alertController = UIAlertController(title: nil, message: error.localizedDescription, preferredStyle: .alert)
alertController.addAction(UIAlertAction(title: "Ok", style: .default, handler: nil))
present(alertController, animated: true, completion: nil)
}
}
}Далее настраиваем cameraInput и cameraOutput, добавляем их к сессии и стартуем ее для получения потока данных.
let cameraInput = try AVCaptureDeviceInput(device: camera)
let videoOutput = AVCaptureVideoDataOutput()
videoOutput.setSampleBufferDelegate(self, queue: captureQueue)
videoOutput.alwaysDiscardsLateVideoFrames = true
videoOutput.videoSettings = [kCVPixelBufferPixelFormatTypeKey as String: kCVPixelFormatType_32BGRA]
session.sessionPreset = .high
session.addInput(cameraInput)
session.addOutput(videoOutput)
let connection = videoOutput.connection(with: .video)
connection?.videoOrientation = .portrait
session.startRunning()Теперь нам нужно инициализировать Core ML модель для Vision и настроить запрос.
guard let visionModel = try? VNCoreMLModel(for: Inceptionv3().model) else {
fatalError("Could not load model")
}
let classificationRequest = VNCoreMLRequest(model: visionModel, completionHandler: handleClassifications)
classificationRequest.imageCropAndScaleOption = VNImageCropAndScaleOptionCenterCrop
visionRequests = [classificationRequest]Создаем метод, который будет обрабатывать полученные результаты. С учетом погрешности, берем 3 наиболее вероятных по мнению модели результата и ищем среди них слово cat.
private func handleClassifications(request: VNRequest, error: Error?) {
if let error = error {
print(error.localizedDescription)
return
}
guard let results = request.results as? [VNClassificationObservation] else {
print("No results")
return
}
var resultString = "Это не кот!"
results[0...3].forEach {
let identifer = $0.identifier.lowercased()
if identifer.range(of: "cat") != nil {
resultString = "Это кот!"
}
}
DispatchQueue.main.async {
self.resultLabel.text = resultString
}
}Последнее, что нам осталось сделать – добавить метод делагата AVCaptureVideoDataOutputSampleBufferDelegate, который вызывается при каждом новом кадре, полученном с камеры. В нем мы конфигурируем запрос и выполняем его.
extension ViewController: AVCaptureVideoDataOutputSampleBufferDelegate {
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
guard let pixelBuffer = CMSampleBufferGetImageBuffer(sampleBuffer) else {
return
}
var requestOptions: [VNImageOption: Any] = [:]
if let cameraIntrinsicData = CMGetAttachment(sampleBuffer, kCMSampleBufferAttachmentKey_CameraIntrinsicMatrix, nil) {
requestOptions = [.cameraIntrinsics: cameraIntrinsicData]
}
let imageRequestHandler = VNImageRequestHandler(cvPixelBuffer: pixelBuffer, orientation: 1, options: requestOptions)
do {
try imageRequestHandler.perform(visionRequests)
} catch {
print(error)
}
}
}Готово! Вы написали приложение, которое отличает котов от всех остальных объектов!
→ Ссылка на репозиторий.
Выводы
Несмотря на особенности, Core ML найдет свою аудиторию. Если вы не готовы мириться с ограничениями и небольшими возможностями, существуют много сторонних фреймворков. Например, YOLO или Swift-AI.
