
Бывает, что системы глючат, тормозят, ломаются. Чем больше система, тем сложнее найти причину. Чтобы узнать, почему что-то работает не так, как ожидалось, исправить или предотвратить будущие проблемы, нужно посмотреть внутрь. Для этого системы должны обладать свойством наблюдаемости, которая достигается инструментацией в широком смысле этого слова.
На HighLoad++ Пётр Зайцев (Percona) сделал обзор доступной инфраструктуры для трейсинга в Linux и рассказал о bpfTrace, который (как видно из названия) дает много преимуществ. Мы сделали текстовую версию доклада, чтобы вам было удобно пересмотреть детали и дополнительные материалы всегда были под рукой.
Инструментацию можно разделить на два больших блока:
Другой вариант классификации основан на подходе к регистрации данных:
Статическая инструментация существует многие годы и есть практически во всем. В Linux её используют многие стандартные инструменты типа Vmstat или top. Они читают данные из procfs, куда, грубо говоря, записываются разные таймеры и счётчики из кода ядра.
Но слишком много таких счётчиков не вставишь, всё на свете ими не покроешь. Поэтому бывает полезна динамическая инструментация, которая позволяет смотреть именно то, что нужно. Например, если есть какие-то проблемы с TCP/IP стеком, то можно идти очень глубоко и инструментировать конкретные детали.

DTrace — один из первых известных фреймворков для динамического трейсинга, созданный компанией Sun Microsystems. Его начали делать еще в 2001 году, и впервые он вышел в Solaris 10 в 2005 году. Подход оказался весьма популярным и в дальнейшем вошел во многие другие дистрибутивы.
Интересно, что DTrace позволяет инструментировать как kernel space, так и user space. Можно ставить трейсы на любые вызовы функции и специально инструментировать программы: ввести специальные DTrace tracepoints, которые для пользователей могут быть более понятны, чем служебные названия функций.
Особенно важно это было для Solaris, потому что это не открытая операционная система. Не было возможности просто посмотреть в код и понять, что tracepoint нужно поставить на такую-то функцию, как сейчас можно сделать в новом открытом программном обеспечении Linux.
Одна из уникальных, особенно на тот момент, особенностей DTrace в том, что пока трейсинг не включен, он ничего не стоит. Он работает таким образом, что просто заменяет некоторые CPU-инструкции на вызов DTrace, который при возврате эти инструкции выполняет.
В DTrace инструментация записывается на специальном языке D, похожим на C и Awk.
В дальнейшем DTrace появился практически везде, кроме Linux: в MacOS в 2007, во FreeBSD в 2008, в NetBSD в 2010. Oracle в 2011 включил DTrace в Oracle Unbreakable Linux. Но Oracle Linux используют мало людей, а в основной Linux DTrace так и не вошел.
Интересно, что в 2017 году Oracle наконец лицензировал DTrace под GPLv2, что в принципе сделало возможным включение его в mainline Linux без лицензионных сложностей, но было уже слишком поздно. На тот момент в Linux был хороший BPF, который в основном и использовался для стандартизации.
DTrace даже собираются включить в Windows, сейчас он доступен в некоторых тестовых версиях.
Что же есть в Linux вместо DTrace? На самом деле в Linux в лучшем (или худшем) проявлении духа open source есть много всего, куча разных tracing frameworks накопилась за это время. Поэтому разобраться, что там к чему, не так просто.
Если вы хотите познакомиться с этим многообразием и вам интересна история, посмотрите статью с картинками и подробным описанием подходов для трейсинга в Linux.
Если говорить про инфраструктуру для трейсинга в Linux в общем, можно выделить три ее уровня:
Со всеми этими фреймворками в последние годы eBPF становится стандартом в Linux. Это более продвинутый, весьма гибкий и эффективный инструмент, который позволяет практически всё.
Что же такое eBPF и откуда он взялся? На самом деле, eBPF — это Extended Berkeley Packet Filter, а BPF был разработан в 1992 году как виртуальная машина для эффективной фильтрации пакетов файрволлом. Никакого отношения к мониторингу, наблюдаемости, трейсингу он изначально не имел.
В более современных версиях eBPF был расширен (отсюда слово extended), как общий фреймворк для обработки событий. Текущие версии интегрированы с JIT-компилятором для большей эффективности.
Отличия eBPF от классического BPF:
Сейчас люди чаще всего забывают, что был старый BPF, и называют eBPF просто BPF. В большинстве современных выражений eBPF и BPF — это одно и то же. Поэтому же и инструмент называется bpfTrace, а не eBpfTrace.
eBPF включен в mainline Linux начиная с 2014 года и постепенно входит в многий инструментарий около Linux, в том числе Perf, SystemTap, SysDig. Происходит стандартизация.
Интересно, что по-прежнему идет разработка. Современные ядра поддерживают eBPF все лучше и лучше.

Посмотреть, что в каких современных версиях ядра появилось, можно здесь.
Итак, что такое eBPF и чем он интересен?
eBPF — это программа в своем специальном байт-коде, которая включается непосредственно в ядро и выполняет обработку трейс-эвентов. Причем то, что она сделана в специальном байт-коде, позволяет ядру провести определенную верификацию, что код достаточно безопасный. Например, проверить, что в нём не используются циклы, потому что цикл в critical-секции в ядре может повесить всю систему.
Но полностью обезопаситься это не позволяет. Например, если написать очень сложную eBPF-программу, всунуть ее в эвент в ядре, который происходит 10 млн раз в секунду, то все может очень сильно затормозиться. Но при этом eBPF куда более безопасен, чем старый подход, когда просто какие-то Kernel Modules вставлялись через insmod, и в этих модулях могло быть все что угодно. Если кто-то допустил ошибку, или просто из-за бинарной несовместимости все ядро могло упасть.
eBPF-код можно скомпилировать LLVM Clang, то есть по большому счету использовать подмножество C для создания eBPF-программ, что, конечно, достаточно сложно. И важно, что компиляция зависит от ядра: используются хэдеры, чтобы понимать, какие структуры и для чего используются и т.д. Это не очень удобно в том плане, что всегда поставляются либо какие-то модули, связанные с конкретным ядром, либо нужно перекомпилировать.
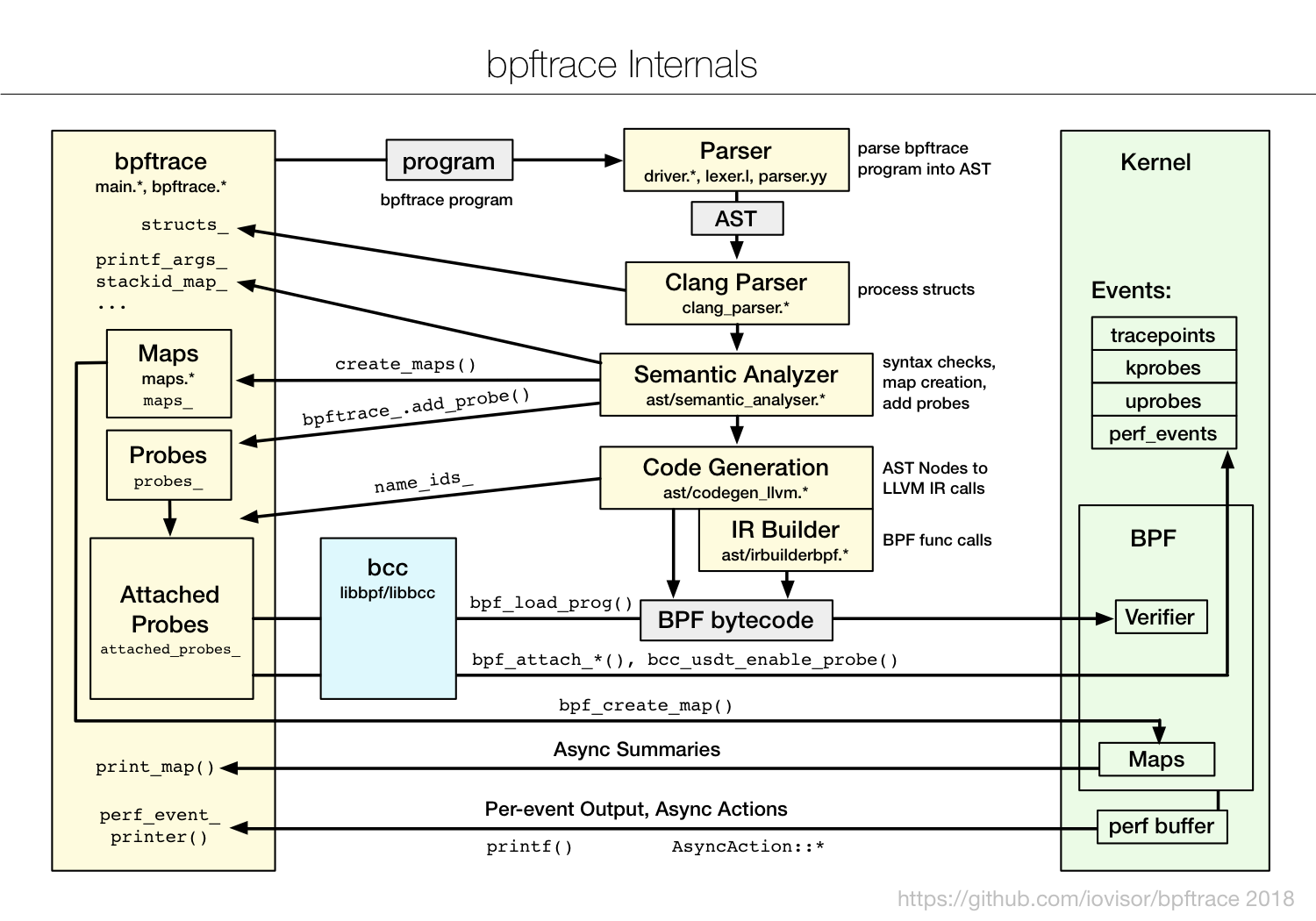
На схеме представлено, как работает eBPF.
http://www.brendangregg.com/ebpf.html
Пользователь создает eBPF-программу. Дальше ядро со своей стороны ее проверяет и загружает. После этого eBPF может подключиться к разным инструментам для трейсов, обрабатывать информацию, сохранять ее в maps (структуру данных для временного хранения). Потом user program может читать статистику, получать perf-эвенты и т.д.
Здесь показано, какие функции eBPF в каких версиях ядрах Linux есть.
Видно, что покрываются практически все подсистемы ядра Linux, плюс есть хорошая интеграция с hardware-данными, у eBPF есть доступ ко всяким cache miss или branch miss prediction и т.д.
Если вам интересен eBPF, обратите внимание на проект IO Visor, в нём собрано большинство инструментов. Компания IO Visor занимается их разработкой, у них вы найдете последние версии и очень хорошую документацию. В дистрибутивах Linux появляется все больше и больше eBPF-инструментов, поэтому я бы рекомендовал всегда использовать последние доступные версии.
По производительности eBPF достаточно эффективный. Чтобы понять, насколько и есть ли overhead, можно добавить probe, который дергается несколько раз в секунду, и проверить, сколько требуется времени на его выполнение.

Ребята из Cloudflare сделали бенчмарк. Простой eBPF probe занимал у них около 100 нс, более сложный — 300 нс. Это означает, что даже сложный probe может вызываться на одном ядре около 3 млн раз в секунду. Если probe дергается 100 тысяч или миллион раз в секунду на многоядерном процессоре, то это не слишком скажется на производительности.
Если вы интересуетесь eBPF и темой Observability вообще, то наверняка слышали о Брендане Грегге (Brendan Gregg). Он много об этом пишет и рассказывает и сделал такую красивую картинку, на которой представлены инструменты для eBPF.

Здесь видно, что, например, можно использовать Raw BPF — просто писать байт-код — это даст полный набор возможностей, но работать с этим будет очень тяжело. Raw BPF это примерно как писать веб-приложение на ассемблере — в принципе можно, но без необходимости делать этого не стоит.
Интересно, что bpfTrace, с одной стороны, по возможностям позволяет получить практически всё, что и BCC, и сырой BPF, но при этом значительно проще в использовании.
На мой взгляд, наиболее полезны два инструмента:
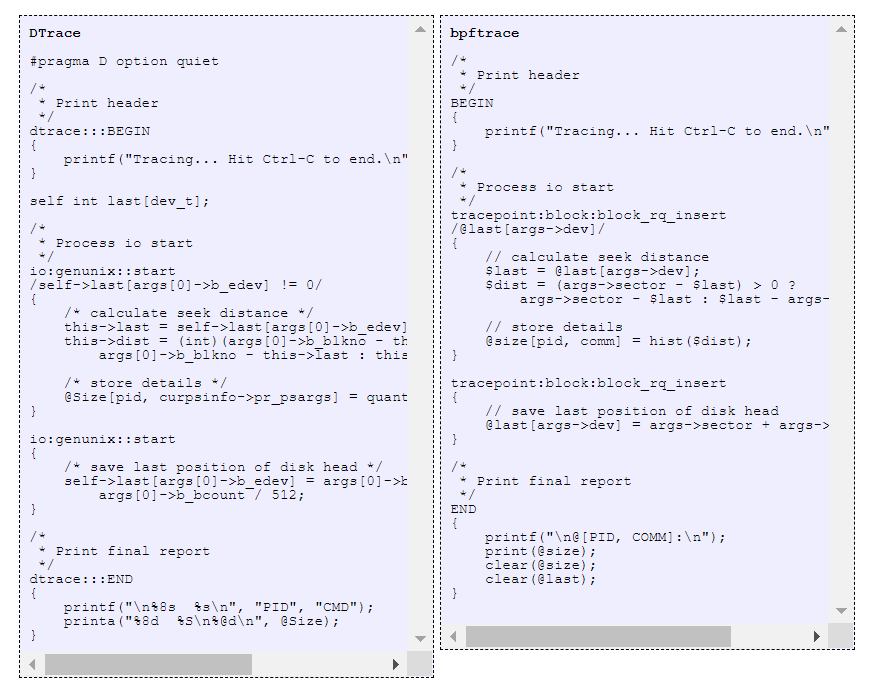
Насколько проще писать на bpfTrace можно представить, если посмотреть на код одного и того же инструмента в двух вариантах.

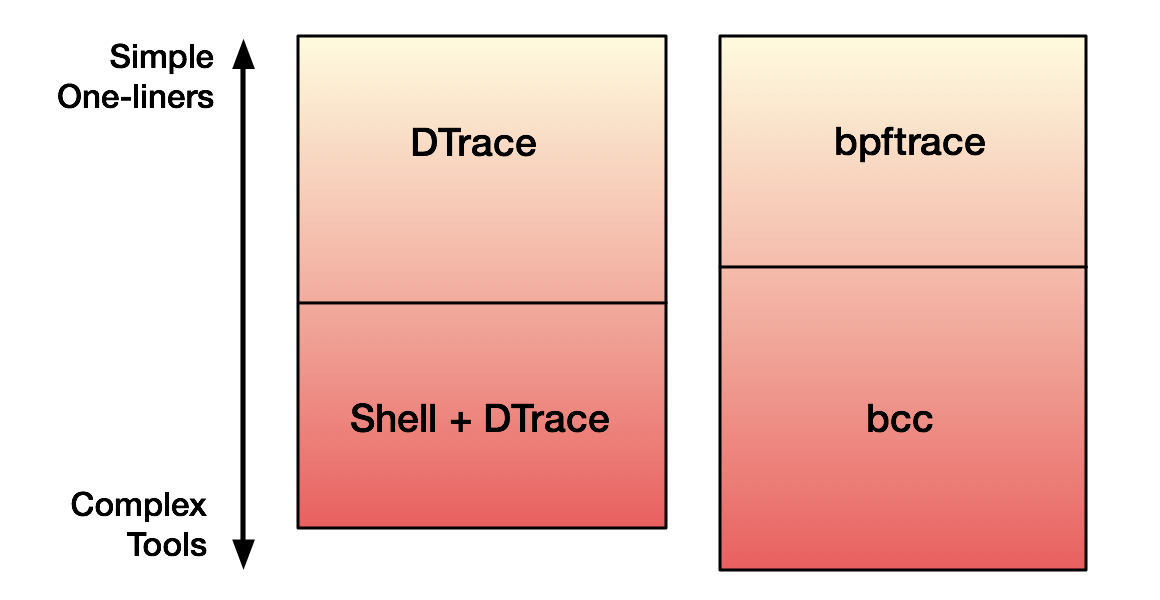
В общем и целом DTrace и bpfTrace используется для одного и того же.
http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html
Разница в том, что в BPF-экосистеме есть еще и BCC, который можно использовать для сложных инструментов. В DTrace эквивалента BCC нет, поэтому, чтобы делать сложный инструментарий, обычно используют связку Shell + DTrace.
Когда создавали bpfTrace, не было задачи полностью эмулировать DTrace. То есть нельзя взять DTrace-скрипт и запустить его на bpfTrace. Но в этом и нет особого смысла, потому что в инструментарии нижнего уровня логика достаточно простая. Обычно важнее понять, к каким tracepoints нужно подсоединиться, а названия системных вызовов и то, что они непосредственно делают на низком уровне, отличаются в Linux, Solaris, FreeBSD. Именно в этом возникает разница.
При этом bpfTrace сделан через 15 лет после DTrace. В нём есть некоторые дополнительные возможности, которых в DTrace нет. Например, он может делать стек-трейсы.
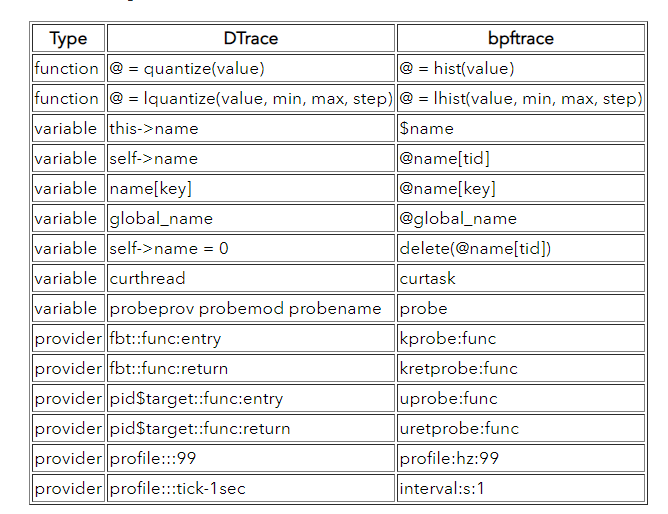
Но, конечно, многое унаследовано от DTrace. Например, названия функций и синтаксис похожи, хотя не полностью эквивалентны.
Скрипты DTrace и bpfTrace близки по объему кода и похожи по сложности и возможностям языка.
Посмотрим подробнее, что есть в bpfTrace, как его можно использовать и что для этого нужно.
Требования к Linux для использования bpfTrace:

Чтобы использовать все фичи, нужна версия, как минимум, 4.9. BpfTrace позволяет делать очень много разных probes, начиная с uprobe для инструментирования вызова функции в user-приложении, kernel-probes и т.д.
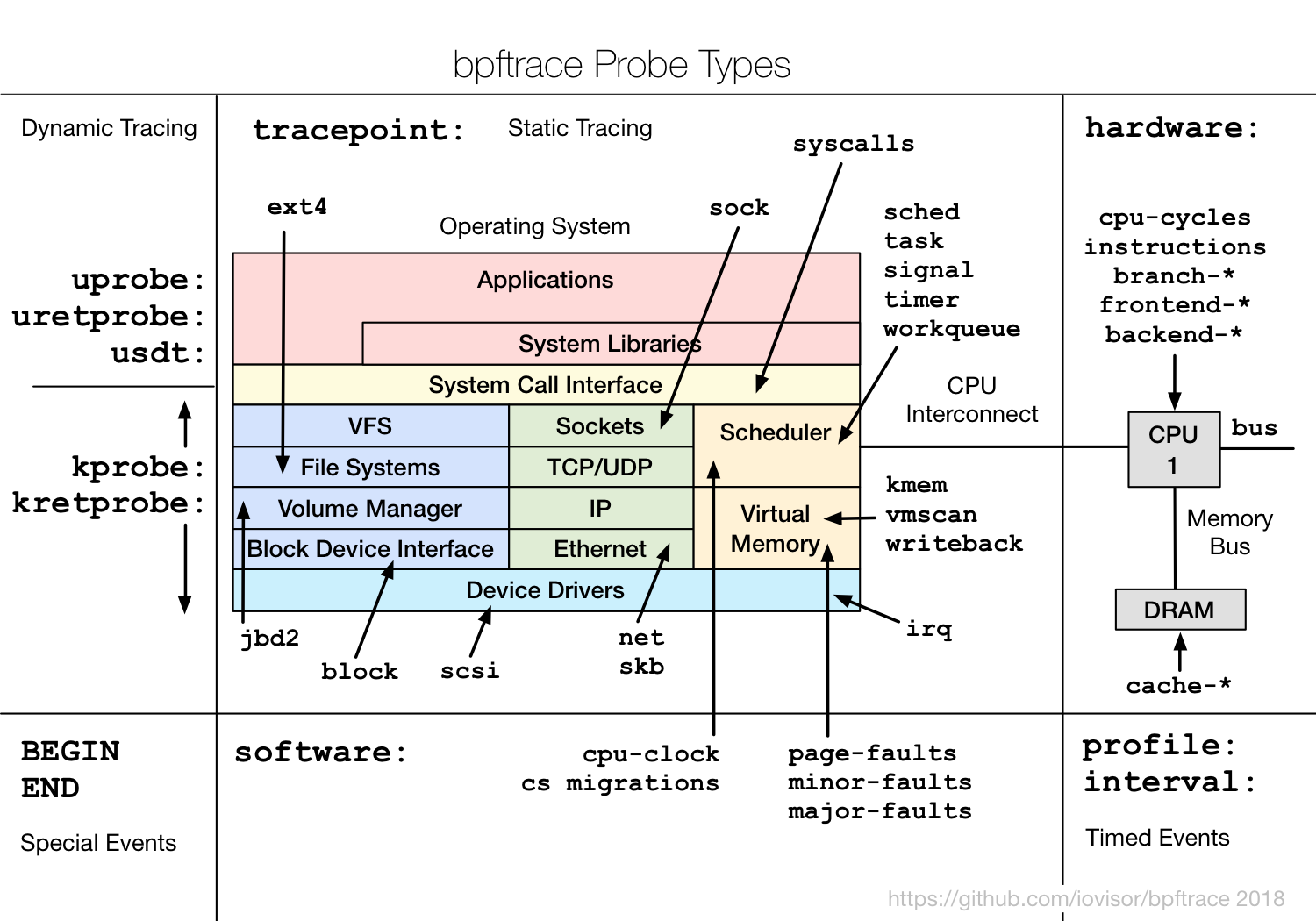
Интересно, что для пользовательской функции uprobe есть эквивалент uretprobe. Для kernel то же самое — есть kprobe и kretprobe. Это означает, что на самом деле в трейсинг-фреймворке можно генерировать события по вызову функции и по завершению этой функции — это часто используется для тайминга. Или можно анализировать значения, которые функция вернула, и группировать их по параметрам, с которыми функция была вызвана. Если ловить и вызов функции, и возврат из нее, можно делать много классных вещей.
Внутри bpfTrace работает так: пишем bpf-программу, которая парсится, конвертируется в C, потом обрабатывается через Clang, который генерирует bpf-байт-код, после этого программа загружается.
Процесс достаточно тяжелый, поэтому есть ограничения. На мощных серверах bpfTrace работает хорошо. Но тащить Clang на маленький embedded-девайс, чтобы разобраться, что там происходит, не лучшая идея. Для этого подойдет Ply. У него, конечно, нет всех возможностей bpfTrace, но он генерирует байт-код напрямую.
Стабильная версия bpfTrace вышла около года назад, поэтому в старых дистрибутивах Linux его нет. Лучше всего брать пакеты или компилировать последнюю версию, которую распространяет IO Visor.
Интересно, что в последнем Ubuntu LTS 18.04 нет bpfTrace, но его можно поставить с помощью snap-пакета. С одной стороны это удобно, но с другой стороны из-за того, как сделаны и изолируются snap-пакеты, будут работать не все функции. Для kernel-трейсинга пакет со snap работает хорошо, для user-трейсинга — может работать неправильно.

Рассмотрим простейший пример, который позволяет получить статистику IO-запросов:
Здесь мы подключаемся к функции
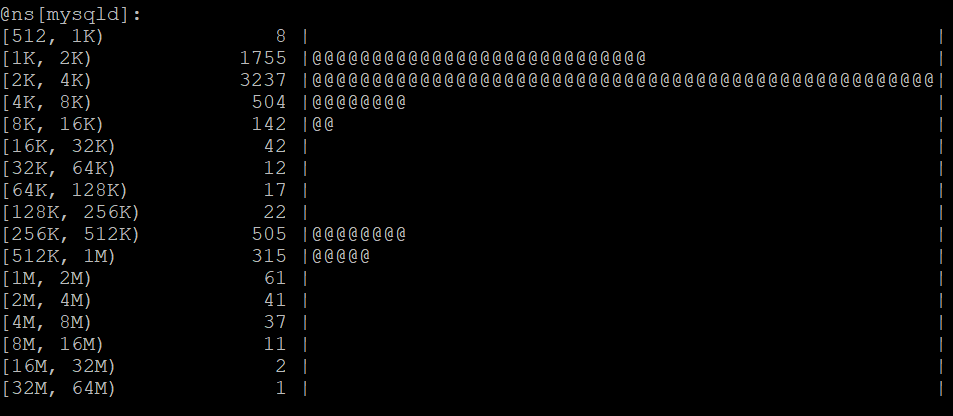
Видно классическое бимодальное распределение ввода/вывода. Большое число быстрых запросов — это данные, которые читаются из кэша. Второй пик — чтение данных с диска, где latency значительно выше.
Можно сохранить это как скрипт (обычно используется bt-расширение), написать комментарии, отформатировать и просто дальше использовать
Общий концепт языка достаточно простой.
Более детально можно познакомиться здесь.
В bpfTrace тоже есть набор инструментов. Многие достаточно простые инструменты на BCC сейчас реализуются на bpfTrace.

Коллекция пока небольшая, но там есть кое-что, чего нет в BCC. Например, killsnoop позволяет отслеживать сигналы, вызванные kill().
Если интересно посмотреть bpf-код, то в bpfTrace можно через
Покажу на примере MySQL, как это работает. В MySQL есть функция
Я хотел просто подсоединить uprobe, чтобы распечатать текст запросов, которые приходят к MySQL — примитивная задача. Получил проблему — говорит, что нет такого файла. Как нет, когда вот он:
Это как раз сюрпризы со snap. Если ставить через snap, то могут быть проблемы трейсинга на уровне приложений.
Тогда поставил через apt-версию, более новую Ubuntu, запустил снова:
«Нет такого символа», — как нет?! Смотрю через
Такой символ есть, но поскольку MySQL скомпилирован из C++, там используется mangling. На самом деле настоящее имя функции, которое используется в этой команде, такое:
Еще обратите внимание на флаг
На HighLoad++ Пётр Зайцев (Percona) сделал обзор доступной инфраструктуры для трейсинга в Linux и рассказал о bpfTrace, который (как видно из названия) дает много преимуществ. Мы сделали текстовую версию доклада, чтобы вам было удобно пересмотреть детали и дополнительные материалы всегда были под рукой.
Инструментацию можно разделить на два больших блока:
- Статическая, когда сбор информации зашит в код: запись логов, счетчиков, времени и т.д.
- Динамическая, когда код не инструментируется сам по себе, но есть возможность сделать это, когда понадобится.
Другой вариант классификации основан на подходе к регистрации данных:
- Tracing — события генерируются, если сработал определенный код.
- Sampling — статус системы проверяется, например, 100 раз в секунду и по нему определяется, что в ней происходит.
Статическая инструментация существует многие годы и есть практически во всем. В Linux её используют многие стандартные инструменты типа Vmstat или top. Они читают данные из procfs, куда, грубо говоря, записываются разные таймеры и счётчики из кода ядра.
Но слишком много таких счётчиков не вставишь, всё на свете ими не покроешь. Поэтому бывает полезна динамическая инструментация, которая позволяет смотреть именно то, что нужно. Например, если есть какие-то проблемы с TCP/IP стеком, то можно идти очень глубоко и инструментировать конкретные детали.
DTrace
DTrace — один из первых известных фреймворков для динамического трейсинга, созданный компанией Sun Microsystems. Его начали делать еще в 2001 году, и впервые он вышел в Solaris 10 в 2005 году. Подход оказался весьма популярным и в дальнейшем вошел во многие другие дистрибутивы.
Интересно, что DTrace позволяет инструментировать как kernel space, так и user space. Можно ставить трейсы на любые вызовы функции и специально инструментировать программы: ввести специальные DTrace tracepoints, которые для пользователей могут быть более понятны, чем служебные названия функций.
Особенно важно это было для Solaris, потому что это не открытая операционная система. Не было возможности просто посмотреть в код и понять, что tracepoint нужно поставить на такую-то функцию, как сейчас можно сделать в новом открытом программном обеспечении Linux.
Одна из уникальных, особенно на тот момент, особенностей DTrace в том, что пока трейсинг не включен, он ничего не стоит. Он работает таким образом, что просто заменяет некоторые CPU-инструкции на вызов DTrace, который при возврате эти инструкции выполняет.
В DTrace инструментация записывается на специальном языке D, похожим на C и Awk.
В дальнейшем DTrace появился практически везде, кроме Linux: в MacOS в 2007, во FreeBSD в 2008, в NetBSD в 2010. Oracle в 2011 включил DTrace в Oracle Unbreakable Linux. Но Oracle Linux используют мало людей, а в основной Linux DTrace так и не вошел.
Интересно, что в 2017 году Oracle наконец лицензировал DTrace под GPLv2, что в принципе сделало возможным включение его в mainline Linux без лицензионных сложностей, но было уже слишком поздно. На тот момент в Linux был хороший BPF, который в основном и использовался для стандартизации.
DTrace даже собираются включить в Windows, сейчас он доступен в некоторых тестовых версиях.
Трейсинг в Linux
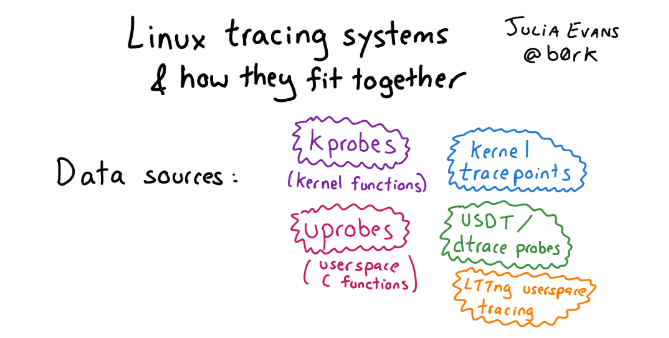
Что же есть в Linux вместо DTrace? На самом деле в Linux в лучшем (или худшем) проявлении духа open source есть много всего, куча разных tracing frameworks накопилась за это время. Поэтому разобраться, что там к чему, не так просто.
Если вы хотите познакомиться с этим многообразием и вам интересна история, посмотрите статью с картинками и подробным описанием подходов для трейсинга в Linux.
Если говорить про инфраструктуру для трейсинга в Linux в общем, можно выделить три ее уровня:
- Интерфейс для инструментации ядра: Kprobe, Uprobe, Dtrace probe и т.д.
- «Программа», работающая с этим интерфейсом. События, создаваемые probe, могут происходить миллионы раз в секунду, записывать их все в файл или просто гнать в user space обычно слишком дорого. Для обработки таких событий есть разные подходы: буферизировать в ядре, чтобы потом читать из user space, использовать Kernel Module, чтобы их как-то обрабатывать, и eBPF.
- Фронтенд-инструменты, чтобы работать с данными, полученными на предыдущих уровнях: Perf, SystemTap, SysDig, BCC и т.д. bpfTtrace на самом деле один из так фреймворков, если разобраться, что к чему.
eBPF — новый стандарт Linux
Со всеми этими фреймворками в последние годы eBPF становится стандартом в Linux. Это более продвинутый, весьма гибкий и эффективный инструмент, который позволяет практически всё.
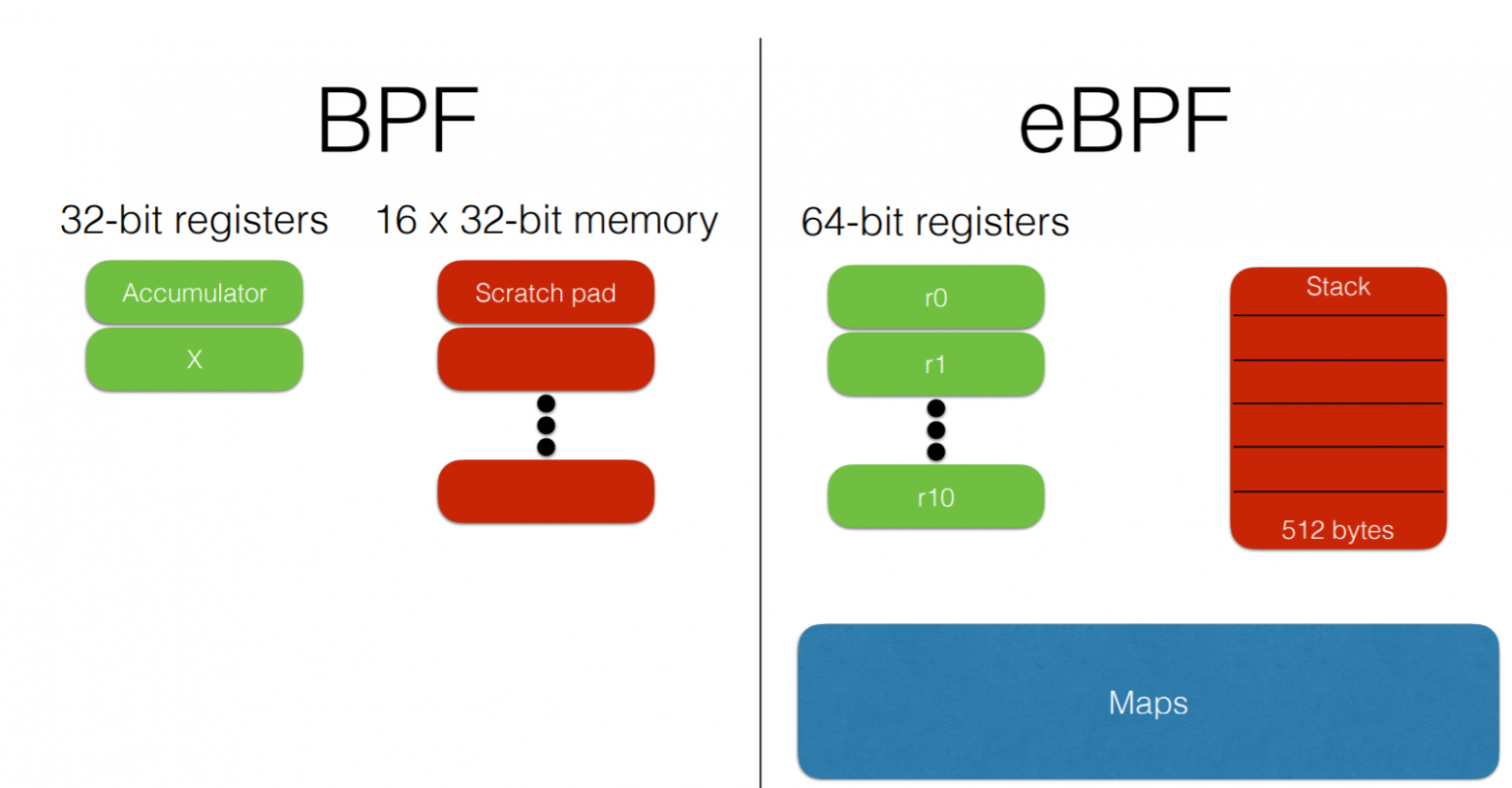
Что же такое eBPF и откуда он взялся? На самом деле, eBPF — это Extended Berkeley Packet Filter, а BPF был разработан в 1992 году как виртуальная машина для эффективной фильтрации пакетов файрволлом. Никакого отношения к мониторингу, наблюдаемости, трейсингу он изначально не имел.
В более современных версиях eBPF был расширен (отсюда слово extended), как общий фреймворк для обработки событий. Текущие версии интегрированы с JIT-компилятором для большей эффективности.
Отличия eBPF от классического BPF:
- добавлены регистры;
- появился стек;
- есть дополнительные структуры данных (maps).
Сейчас люди чаще всего забывают, что был старый BPF, и называют eBPF просто BPF. В большинстве современных выражений eBPF и BPF — это одно и то же. Поэтому же и инструмент называется bpfTrace, а не eBpfTrace.
eBPF включен в mainline Linux начиная с 2014 года и постепенно входит в многий инструментарий около Linux, в том числе Perf, SystemTap, SysDig. Происходит стандартизация.
Интересно, что по-прежнему идет разработка. Современные ядра поддерживают eBPF все лучше и лучше.
Посмотреть, что в каких современных версиях ядра появилось, можно здесь.
Программы eBPF
Итак, что такое eBPF и чем он интересен?
eBPF — это программа в своем специальном байт-коде, которая включается непосредственно в ядро и выполняет обработку трейс-эвентов. Причем то, что она сделана в специальном байт-коде, позволяет ядру провести определенную верификацию, что код достаточно безопасный. Например, проверить, что в нём не используются циклы, потому что цикл в critical-секции в ядре может повесить всю систему.
Но полностью обезопаситься это не позволяет. Например, если написать очень сложную eBPF-программу, всунуть ее в эвент в ядре, который происходит 10 млн раз в секунду, то все может очень сильно затормозиться. Но при этом eBPF куда более безопасен, чем старый подход, когда просто какие-то Kernel Modules вставлялись через insmod, и в этих модулях могло быть все что угодно. Если кто-то допустил ошибку, или просто из-за бинарной несовместимости все ядро могло упасть.
eBPF-код можно скомпилировать LLVM Clang, то есть по большому счету использовать подмножество C для создания eBPF-программ, что, конечно, достаточно сложно. И важно, что компиляция зависит от ядра: используются хэдеры, чтобы понимать, какие структуры и для чего используются и т.д. Это не очень удобно в том плане, что всегда поставляются либо какие-то модули, связанные с конкретным ядром, либо нужно перекомпилировать.
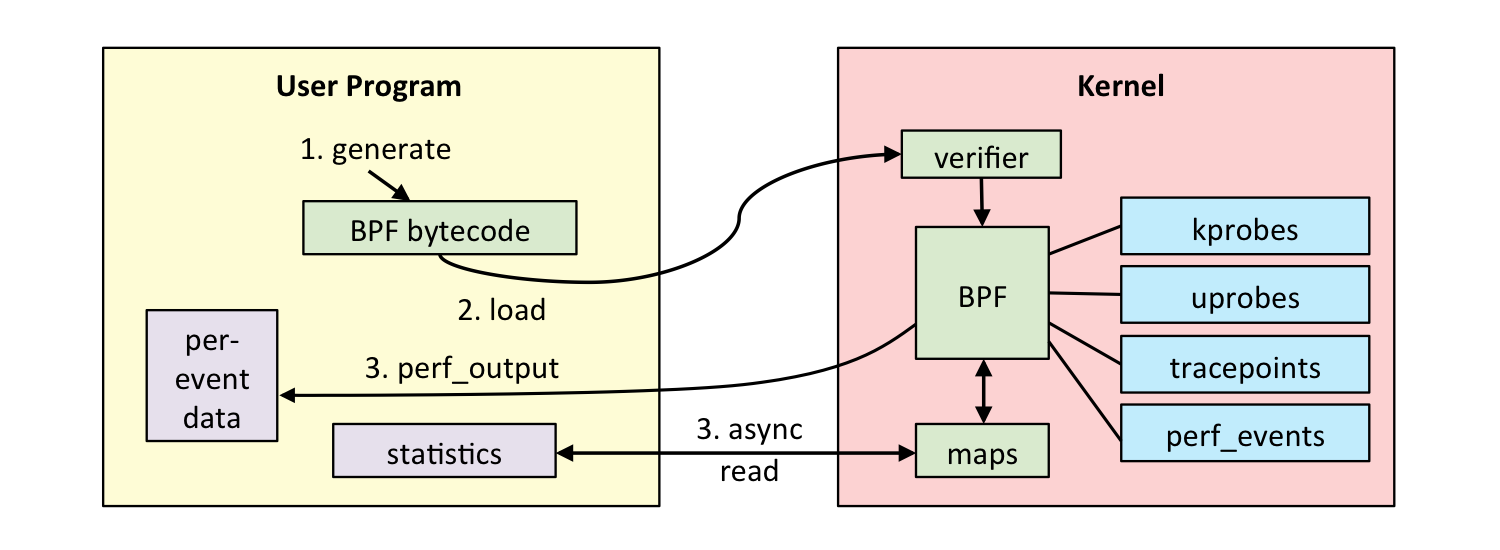
На схеме представлено, как работает eBPF.
http://www.brendangregg.com/ebpf.html
Пользователь создает eBPF-программу. Дальше ядро со своей стороны ее проверяет и загружает. После этого eBPF может подключиться к разным инструментам для трейсов, обрабатывать информацию, сохранять ее в maps (структуру данных для временного хранения). Потом user program может читать статистику, получать perf-эвенты и т.д.
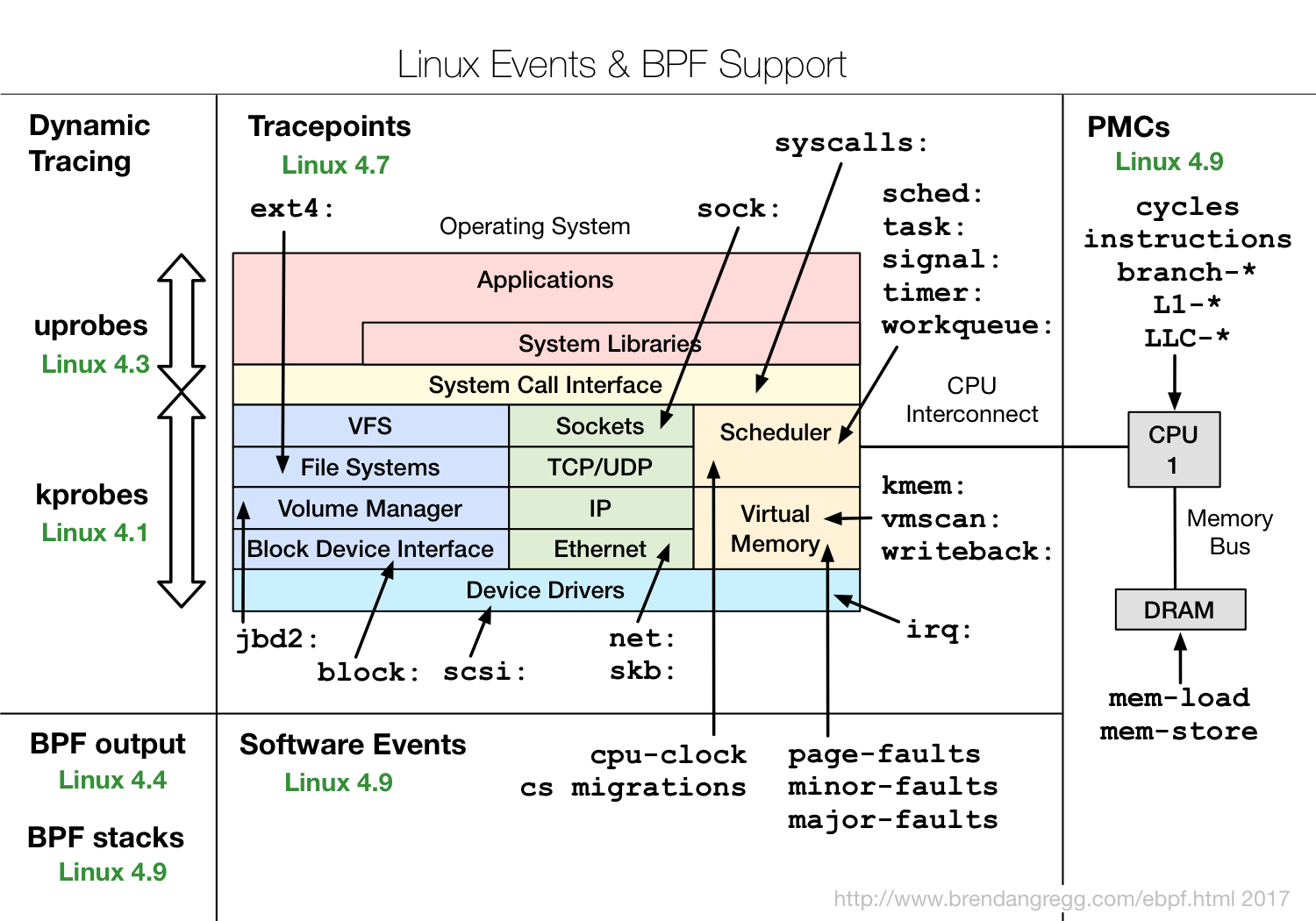
Здесь показано, какие функции eBPF в каких версиях ядрах Linux есть.
Видно, что покрываются практически все подсистемы ядра Linux, плюс есть хорошая интеграция с hardware-данными, у eBPF есть доступ ко всяким cache miss или branch miss prediction и т.д.
Если вам интересен eBPF, обратите внимание на проект IO Visor, в нём собрано большинство инструментов. Компания IO Visor занимается их разработкой, у них вы найдете последние версии и очень хорошую документацию. В дистрибутивах Linux появляется все больше и больше eBPF-инструментов, поэтому я бы рекомендовал всегда использовать последние доступные версии.
Производительность eBPF
По производительности eBPF достаточно эффективный. Чтобы понять, насколько и есть ли overhead, можно добавить probe, который дергается несколько раз в секунду, и проверить, сколько требуется времени на его выполнение.
Ребята из Cloudflare сделали бенчмарк. Простой eBPF probe занимал у них около 100 нс, более сложный — 300 нс. Это означает, что даже сложный probe может вызываться на одном ядре около 3 млн раз в секунду. Если probe дергается 100 тысяч или миллион раз в секунду на многоядерном процессоре, то это не слишком скажется на производительности.
Фронтенд для eBPF
Если вы интересуетесь eBPF и темой Observability вообще, то наверняка слышали о Брендане Грегге (Brendan Gregg). Он много об этом пишет и рассказывает и сделал такую красивую картинку, на которой представлены инструменты для eBPF.
Здесь видно, что, например, можно использовать Raw BPF — просто писать байт-код — это даст полный набор возможностей, но работать с этим будет очень тяжело. Raw BPF это примерно как писать веб-приложение на ассемблере — в принципе можно, но без необходимости делать этого не стоит.
Интересно, что bpfTrace, с одной стороны, по возможностям позволяет получить практически всё, что и BCC, и сырой BPF, но при этом значительно проще в использовании.
На мой взгляд, наиболее полезны два инструмента:
- BCC. Несмотря на то, что по схеме Грегга BCC сложный, он включает в себя множество готовых функций, которые можно просто запустить из командной строки.
- BpfTrace. Позволяет достаточно просто писать свой инструментарий или же использовать готовые решения.
Насколько проще писать на bpfTrace можно представить, если посмотреть на код одного и того же инструмента в двух вариантах.
DTrace vs bpfTrace
В общем и целом DTrace и bpfTrace используется для одного и того же.
http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.html
Разница в том, что в BPF-экосистеме есть еще и BCC, который можно использовать для сложных инструментов. В DTrace эквивалента BCC нет, поэтому, чтобы делать сложный инструментарий, обычно используют связку Shell + DTrace.
Когда создавали bpfTrace, не было задачи полностью эмулировать DTrace. То есть нельзя взять DTrace-скрипт и запустить его на bpfTrace. Но в этом и нет особого смысла, потому что в инструментарии нижнего уровня логика достаточно простая. Обычно важнее понять, к каким tracepoints нужно подсоединиться, а названия системных вызовов и то, что они непосредственно делают на низком уровне, отличаются в Linux, Solaris, FreeBSD. Именно в этом возникает разница.
При этом bpfTrace сделан через 15 лет после DTrace. В нём есть некоторые дополнительные возможности, которых в DTrace нет. Например, он может делать стек-трейсы.
Но, конечно, многое унаследовано от DTrace. Например, названия функций и синтаксис похожи, хотя не полностью эквивалентны.
Скрипты DTrace и bpfTrace близки по объему кода и похожи по сложности и возможностям языка.
bpfTrace
Посмотрим подробнее, что есть в bpfTrace, как его можно использовать и что для этого нужно.
Требования к Linux для использования bpfTrace:
Чтобы использовать все фичи, нужна версия, как минимум, 4.9. BpfTrace позволяет делать очень много разных probes, начиная с uprobe для инструментирования вызова функции в user-приложении, kernel-probes и т.д.
Интересно, что для пользовательской функции uprobe есть эквивалент uretprobe. Для kernel то же самое — есть kprobe и kretprobe. Это означает, что на самом деле в трейсинг-фреймворке можно генерировать события по вызову функции и по завершению этой функции — это часто используется для тайминга. Или можно анализировать значения, которые функция вернула, и группировать их по параметрам, с которыми функция была вызвана. Если ловить и вызов функции, и возврат из нее, можно делать много классных вещей.
Внутри bpfTrace работает так: пишем bpf-программу, которая парсится, конвертируется в C, потом обрабатывается через Clang, который генерирует bpf-байт-код, после этого программа загружается.
Процесс достаточно тяжелый, поэтому есть ограничения. На мощных серверах bpfTrace работает хорошо. Но тащить Clang на маленький embedded-девайс, чтобы разобраться, что там происходит, не лучшая идея. Для этого подойдет Ply. У него, конечно, нет всех возможностей bpfTrace, но он генерирует байт-код напрямую.
Поддержка в Linux
Стабильная версия bpfTrace вышла около года назад, поэтому в старых дистрибутивах Linux его нет. Лучше всего брать пакеты или компилировать последнюю версию, которую распространяет IO Visor.
Интересно, что в последнем Ubuntu LTS 18.04 нет bpfTrace, но его можно поставить с помощью snap-пакета. С одной стороны это удобно, но с другой стороны из-за того, как сделаны и изолируются snap-пакеты, будут работать не все функции. Для kernel-трейсинга пакет со snap работает хорошо, для user-трейсинга — может работать неправильно.
Пример трейсинга процесса
Рассмотрим простейший пример, который позволяет получить статистику IO-запросов:
bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'Здесь мы подключаемся к функции
vfs_read, причем как kretprobe, так и kprobe. Дальше для каждого thread ID (tid), то есть для каждого запроса отслеживаем начало и окончание его выполнения. Данные можно сгруппировать не только по совокупности всей системы, но и по разным процессам. Ниже вывод по IO для MySQL.Видно классическое бимодальное распределение ввода/вывода. Большое число быстрых запросов — это данные, которые читаются из кэша. Второй пик — чтение данных с диска, где latency значительно выше.
Можно сохранить это как скрипт (обычно используется bt-расширение), написать комментарии, отформатировать и просто дальше использовать
#bpftrace read.bt.// read.bt file
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid]/
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}Общий концепт языка достаточно простой.
- Синтаксис: выбираем probe для подсоединения
probe[,probe,...] /filter/ { action }. - Filter: указываем фильтр, например, только данные по данному процессу данного Pid.
- Action: мини-программа, которая конвертируется непосредственно в bpf-программу и выполняется при вызове bpfTrace.
Более детально можно познакомиться здесь.
BpfTrace Tools
В bpfTrace тоже есть набор инструментов. Многие достаточно простые инструменты на BCC сейчас реализуются на bpfTrace.
Коллекция пока небольшая, но там есть кое-что, чего нет в BCC. Например, killsnoop позволяет отслеживать сигналы, вызванные kill().
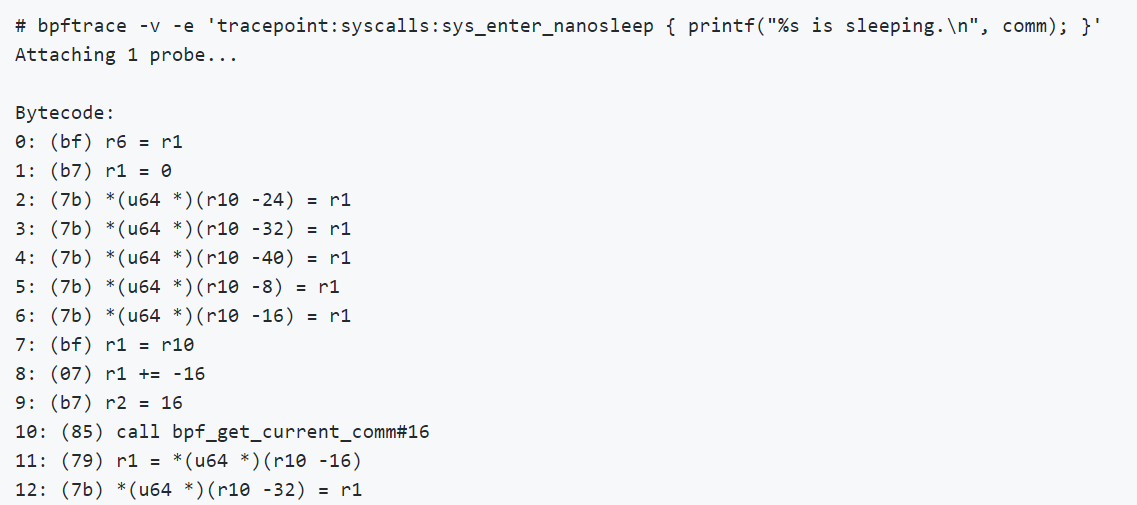
Если интересно посмотреть bpf-код, то в bpfTrace можно через
-v посмотреть сгенерированный байт-код. Это полезно, если хотите понять, тяжелый probe или не очень. Посмотрев код и просто прикинув его размер (одна страница или две), можно понять, насколько он сложный.Пример трейсинга MySQL
Покажу на примере MySQL, как это работает. В MySQL есть функция
dispatch_command, в которой происходят все выполнения запросов MySQL.bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
failed to stat uprobe target file /usr/sbin/mysqld: No such file or directoryЯ хотел просто подсоединить uprobe, чтобы распечатать текст запросов, которые приходят к MySQL — примитивная задача. Получил проблему — говорит, что нет такого файла. Как нет, когда вот он:
root@mysql1:/# ls -la /usr/sbin/mysqld
-rwxr-xr-x 1 root root 60718384 Oct 25 09:19 /usr/sbin/mysqldЭто как раз сюрпризы со snap. Если ставить через snap, то могут быть проблемы трейсинга на уровне приложений.
Тогда поставил через apt-версию, более новую Ubuntu, запустил снова:
root@mysql1:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
Could not resolve symbol: /usr/sbin/mysqld:dispatch_command«Нет такого символа», — как нет?! Смотрю через
nm, есть такой символ или нет:root@mysql1:~# nm -D /usr/sbin/mysqld | grep dispatch_command
00000000005af770 T
_Z16dispatch_command19enum_server_commandP3THDPcjbb
root@localhost:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcjbb { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
select @@version_comment limit 1
select 1Такой символ есть, но поскольку MySQL скомпилирован из C++, там используется mangling. На самом деле настоящее имя функции, которое используется в этой команде, такое:
_Z16dispatch_command19enum_server_commandP3THDPcjbb. Если именно его использовать в функции, то можно подключиться и получить результат. В perf-экосистеме многие инструменты делают unmangling автоматом, а bpfTrace пока не умеет.Еще обратите внимание на флаг
-D для nm. Он важен, потому что MySQL, а сейчас и многие другие пакеты, поставляются без динамических символов (debug symbols) — они идут в других пакетах. Если хочется использовать эти символы, нужен флаг -D, иначе nm их не увидит.
Полезные ссылки
- github.com/zoidbergwill/awesome-ebpf
- slideplayer.com/slide/12710510
- www.brendangregg.com/ebpf.html
- vger.kernel.org/netconf2018_files/BrendanGregg_netconf2018.pdf
- www.brendangregg.com/Slides/Velocity2017_BPF_superpowers.pdf
- lwn.net/Articles/740157
- tracingsummit.org/w/images/8/82/Tracingsummit2018-bpftrace-robertson.pdf
Хорошая новость номер раз: на РИТ++ 25–26 мая Пётр Зайцев расскажет о технологиях и тенденциях на рынке баз данных, которые изменят бизнес через год. Это отличная возможность узнать, какие конкретные решения подойдут в разных ситуациях, от человека с невероятной экспертизой в области БД и оптимизации их производительности.
Хорошая новость номер два: РИТ++ Online стал намного доступнее. Билет для физлиц сейчас стоит всего 5 900 и позволяет разобраться в тенденциях не только БД, но и многих других актуальных технологий, и подробно познакомиться с их применением на мастер-классах.
Хорошая новость номер три: мы открыли видео всех докладов DevOpsConf 2019 и HighLoad++ 2019 — хотите больше хардкора, вам сюда.
Подобные полезности мы собираем в нашей рассылке — подпишитесь, пригодится.
