Всем привет. В преддверии старта базового и продвинутого курсов «Математика для Data Science», мы подготовили перевод еще одного интересного материала.

Почему? Существующие инструменты плохо подходят для решения задач, связанных с временными рядами и эти инструменты сложно интегрировать друг с другом. Методы пакета scikit-learn предполагают, что данные структурированы в табличном формате и каждый столбец состоит из независимых и одинаково распределенных случайных величин – предположений, которые не имеют ничего общего с данными временных рядов. Пакеты, в которых есть модули для машинного обучения и работы с временными рядами, такие как statsmodels, не особо хорошо дружат между собой. Более того, множество важных операций с временными рядами, такие как разбиение данных на обучающий и тестовый наборы по временным промежуткам, в существующих пакетах недоступны.
Для решения подобных задач и была создана sktime.

Логотип библиотеки sktime на GitHub
Sktime – это инструментарий для машинного обучения на Python с открытым исходным кодом, разработанный специально для работы с временными рядами. Этот проект разрабатывается сообществом и финансируется Британским Советом по экономическим и социальным исследованиям, центром Consumer Data Research и Институтом Алана Тьюринга.
Sktime расширяет API scikit-learn для решения задач временных рядов. В нем собраны все необходимые алгоритмы и инструменты преобразования для эффективного решения задач регрессии временных рядов, прогнозирования и классификации. Библиотека включает в себя специальные алгоритмы машинного обучения и методы преобразования для временных рядов, которых нет в других популярных библиотеках.
Sktime был разработан для работы с scikit-learn, легкой адаптации алгоритмов для взаимосвязанных задач временных рядов и построения сложных моделей. Как это работает? Многие задачи временных рядов так или иначе связаны друг с другом. Алгоритм, который можно применить для решения одной задачи, очень часто можно применить и для решения другой, связанной с ней. Эта идея называется редукцией. Например, модель для регрессии временных рядов (которая использует ряд для прогнозирования выходного значения) может быть переиспользована для задачи прогнозирования временных рядов (которая предсказывает выходное значение – значение, которое будет получено в будущем).
Основная идея проекта: «sktime предлагает понятное и интегрируемое машинное обучение с использованием временных рядов. Он располагает алгоритмами, которые совместимы с scikit-learn и инструментами совместного использования моделей, поддерживаемые четкой таксономией задач обучения, с понятной документацией и дружелюбным сообществом.»
В этой статье я выделю некоторые уникальные особенности sktime.
Sktime использует вложенную структуру данных для временных рядов в виде датафреймов pandas.
Каждая строчка в типичном датафрейме содержит независимые и одинаково распределенные случайные величины – наблюдения, а столбцы – различные переменные. Для методов sktime каждая ячейка датафрейма Pandas теперь может содержать целый временной ряд. Такой формат является гибким для многомерных, панельных и гетерогенных данных и позволяет повторно использовать методы как в Pandas, так и в scikit-learn.
В таблице ниже каждая строка – это наблюдение, содержащее массив временных рядов, в столбце Х и значение класса в столбце Y. Оценщики и трансформаторы sktime умеют работать с такими временными рядами.
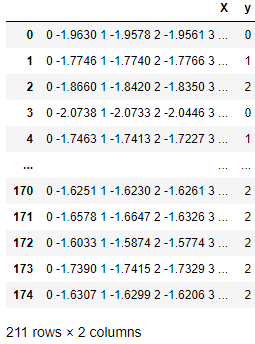
Нативная структура данных для временных рядов, совместимая с sktime.
В следующей таблице каждый элемент ряда Х был вынесен в отдельный столбец, как того требуют методы scikit-learn. Размерность довольно высокая – 251 столбец! Помимо этого, упорядоченность столбцов по времени игнорируется алгоритмами обучения, которые работают с табличными величинами (однако используется алгоритмами классификации и регрессии временных рядов).
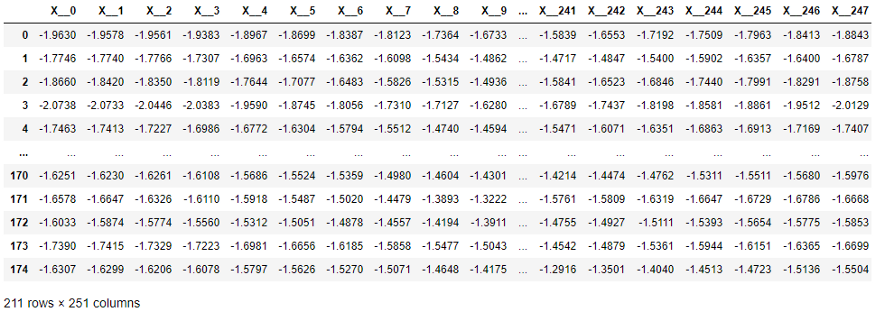
Структура данных временных рядов, требуемая scikit-learn.
Для задач моделирования нескольких совместных рядов нативная структура данных временных рядов, которая совместима с sktime, подходит идеально. Модели, обученные на табличных данных, ожидаемых scikit-learn, завязнут в большом количестве признаков.
Согласно странице на GitHub, sktime в настоящее время предоставляет следующие возможности:
Как было сказано раньше, sktime поддерживает базовый API scikit-learn с методами классов
Для классов оценщиков (или же моделей) sktime предоставляет метод
Оценщики в sktime расширяют регрессоры и классификаторы scikit-learn, предоставляя аналоги этих методов, которые умеют работать с временными рядами.
Для классов трансформаторов sktime предоставляет методы
Следующий пример – это адаптация руководства по прогнозированию с GitHub. Ряд в данном примере (набор данных авиакомпании Box-Jenkins) показывает количество международных пассажиров самолетов в месяц с 1949 по 1960 год.
Для начала загрузите данные и разделите их на обучающий и тестовый наборы, а также сделайте график. В sktime есть две удобные функции для легкого выполнения этих задач —
Перед созданием сложных прогнозов полезно сравнить свой прогноз со значениями полученным по наивным баейсовским алгоритмам. Хорошая модель должна превзойти эти значения. В sktime есть метод
Код и диаграмма ниже демонстрируют два наивных прогноза. Предсказатель с
Предсказатель с
Следующий фрагмент прогноза показывает, как существующие регрессоры sklearn можно легко, корректно и с минимальными усилиями адаптировать под задачи прогнозирования. Ниже метод
В sktime также есть собственные методы прогнозирования, например

Чтобы глубже погрузиться в функционал прогнозирования sktime, ознакомьтесь с руководством по ссылке.
Также
В примере кода ниже классификация одиночных временных рядов делается также просто, как и классификация в scikit-learn. Единственное отличие – это вложенная структура данных временных рядов, о которой мы говорили выше.
Пример был взят отсюда pypi.org/project/sktime
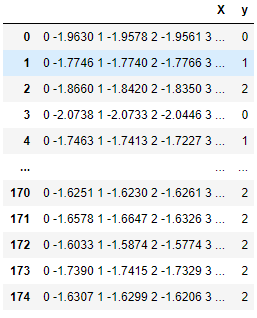
Данные, переданные в TimeSeriesForestClassifier
Чтобы узнать больше о классификации рядов, посмотрите руководства по одномерной и многомерной классификации в sktime.
Чтобы узнать больше о Sktime, посмотрите следующие ссылки с документацией и примерами.
Логистическая регрессия для классификации данных. Бесплатный вебинар.
Решение задач из области data science на Python – это непросто
Почему? Существующие инструменты плохо подходят для решения задач, связанных с временными рядами и эти инструменты сложно интегрировать друг с другом. Методы пакета scikit-learn предполагают, что данные структурированы в табличном формате и каждый столбец состоит из независимых и одинаково распределенных случайных величин – предположений, которые не имеют ничего общего с данными временных рядов. Пакеты, в которых есть модули для машинного обучения и работы с временными рядами, такие как statsmodels, не особо хорошо дружат между собой. Более того, множество важных операций с временными рядами, такие как разбиение данных на обучающий и тестовый наборы по временным промежуткам, в существующих пакетах недоступны.
Для решения подобных задач и была создана sktime.
Логотип библиотеки sktime на GitHub
Sktime – это инструментарий для машинного обучения на Python с открытым исходным кодом, разработанный специально для работы с временными рядами. Этот проект разрабатывается сообществом и финансируется Британским Советом по экономическим и социальным исследованиям, центром Consumer Data Research и Институтом Алана Тьюринга.
Sktime расширяет API scikit-learn для решения задач временных рядов. В нем собраны все необходимые алгоритмы и инструменты преобразования для эффективного решения задач регрессии временных рядов, прогнозирования и классификации. Библиотека включает в себя специальные алгоритмы машинного обучения и методы преобразования для временных рядов, которых нет в других популярных библиотеках.
Sktime был разработан для работы с scikit-learn, легкой адаптации алгоритмов для взаимосвязанных задач временных рядов и построения сложных моделей. Как это работает? Многие задачи временных рядов так или иначе связаны друг с другом. Алгоритм, который можно применить для решения одной задачи, очень часто можно применить и для решения другой, связанной с ней. Эта идея называется редукцией. Например, модель для регрессии временных рядов (которая использует ряд для прогнозирования выходного значения) может быть переиспользована для задачи прогнозирования временных рядов (которая предсказывает выходное значение – значение, которое будет получено в будущем).
Основная идея проекта: «sktime предлагает понятное и интегрируемое машинное обучение с использованием временных рядов. Он располагает алгоритмами, которые совместимы с scikit-learn и инструментами совместного использования моделей, поддерживаемые четкой таксономией задач обучения, с понятной документацией и дружелюбным сообществом.»
В этой статье я выделю некоторые уникальные особенности sktime.
Корректная модель данных для временных рядов
Sktime использует вложенную структуру данных для временных рядов в виде датафреймов pandas.
Каждая строчка в типичном датафрейме содержит независимые и одинаково распределенные случайные величины – наблюдения, а столбцы – различные переменные. Для методов sktime каждая ячейка датафрейма Pandas теперь может содержать целый временной ряд. Такой формат является гибким для многомерных, панельных и гетерогенных данных и позволяет повторно использовать методы как в Pandas, так и в scikit-learn.
В таблице ниже каждая строка – это наблюдение, содержащее массив временных рядов, в столбце Х и значение класса в столбце Y. Оценщики и трансформаторы sktime умеют работать с такими временными рядами.
Нативная структура данных для временных рядов, совместимая с sktime.
В следующей таблице каждый элемент ряда Х был вынесен в отдельный столбец, как того требуют методы scikit-learn. Размерность довольно высокая – 251 столбец! Помимо этого, упорядоченность столбцов по времени игнорируется алгоритмами обучения, которые работают с табличными величинами (однако используется алгоритмами классификации и регрессии временных рядов).
Структура данных временных рядов, требуемая scikit-learn.
Для задач моделирования нескольких совместных рядов нативная структура данных временных рядов, которая совместима с sktime, подходит идеально. Модели, обученные на табличных данных, ожидаемых scikit-learn, завязнут в большом количестве признаков.
Что умеет sktime?
Согласно странице на GitHub, sktime в настоящее время предоставляет следующие возможности:
- Современные алгоритмы классификации временных рядов, регрессионного анализа и прогнозирования (портированного из инструментария
tsmlна Java); - Трансформаторы для временных рядов: преобразования одиночных рядов (например, детрендинг или десезонализация), преобразования рядов как признаков (например, извлечение признаков), и инструменты для совместного использования нескольких трансформаторов.
- Пайплайны для трансформаторов и моделей;
- Настройка модели;
- Ансамбль моделей, например, полностью настраиваемый случайный лес для классификации и регрессии временных рядов, ансамбль для многомерных задач.
API sktime
Как было сказано раньше, sktime поддерживает базовый API scikit-learn с методами классов
fit, predict, и transform. Для классов оценщиков (или же моделей) sktime предоставляет метод
fit для обучения модели и метод predict для генерации новых прогнозов.Оценщики в sktime расширяют регрессоры и классификаторы scikit-learn, предоставляя аналоги этих методов, которые умеют работать с временными рядами.
Для классов трансформаторов sktime предоставляет методы
fit и transform для преобразования данных рядов. Есть несколько типов доступных преобразований:- Преобразования табличных данных, такие как метод главных компонент, которые работают с экземплярами независимых и одинаково распределенных случайных величин;
- Преобразования рядов в примитивы, которые преобразуют временные ряды в каждой строке в примитивные числа (например, транзакции признаков);
- Преобразование рядов к другим рядам (например, преобразование Фурье);
- Трансформаторы, осуществляющие детрендинг, возвращают временной ряд в том же домене, что и входной ряд (например, сезонный детрендинг).
Примеры кода
Прогнозирование временных рядов
Следующий пример – это адаптация руководства по прогнозированию с GitHub. Ряд в данном примере (набор данных авиакомпании Box-Jenkins) показывает количество международных пассажиров самолетов в месяц с 1949 по 1960 год.
Для начала загрузите данные и разделите их на обучающий и тестовый наборы, а также сделайте график. В sktime есть две удобные функции для легкого выполнения этих задач —
temporal_train_test_splitfor, которая разделит набор данных по времени и plot_ys, которая построит графики на основе тестовой и обучающей выборки.from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.utils.plotting.forecasting import plot_ys
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
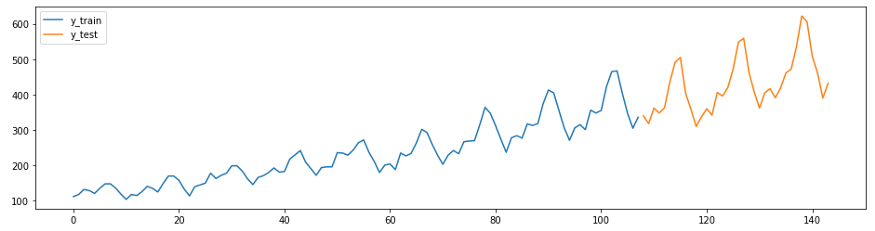
plot_ys(y_train, y_test, labels=["y_train", "y_test"])Перед созданием сложных прогнозов полезно сравнить свой прогноз со значениями полученным по наивным баейсовским алгоритмам. Хорошая модель должна превзойти эти значения. В sktime есть метод
NaiveForecaster с различными стратегиями для создания базовых прогнозов.Код и диаграмма ниже демонстрируют два наивных прогноза. Предсказатель с
strategy = “last” всегда будет давать прогноз относительно последнего значения ряда. Предсказатель с
strategy = “seasonal_last” предсказывает последнее значение ряда в данном сезоне. Сезонность в примере задана как “sp=12”, то есть 12 месяцев.from sktime.forecasting.naive import NaiveForecaster
naive_forecaster_last = NaiveForecaster(strategy="last")
naive_forecaster_last.fit(y_train)
y_last = naive_forecaster_last.predict(fh)
naive_forecaster_seasonal = NaiveForecaster(strategy="seasonal_last", sp=12)
naive_forecaster_seasonal.fit(y_train)
y_seasonal_last = naive_forecaster_seasonal.predict(fh)
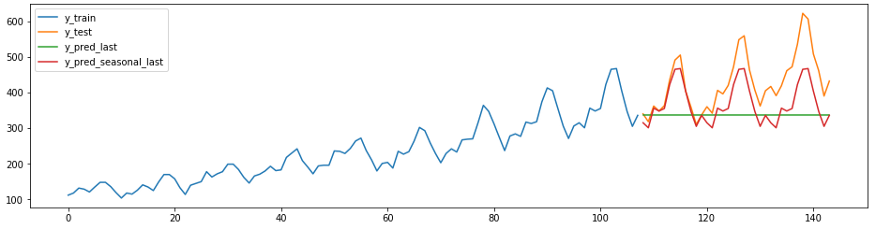
plot_ys(y_train, y_test, y_last, y_seasonal_last, labels=["y_train", "y_test", "y_pred_last", "y_pred_seasonal_last"]);
smape_loss(y_last, y_test)
>>0.231957Следующий фрагмент прогноза показывает, как существующие регрессоры sklearn можно легко, корректно и с минимальными усилиями адаптировать под задачи прогнозирования. Ниже метод
ReducedRegressionForecaster из sktime предсказывает ряд, используя модель sklearnRandomForestRegressor. Под капотом sktime разбивает обучающие данные на окна по 12, чтобы регрессор мог продолжать обучение.from sktime.forecasting.compose import ReducedRegressionForecaster
from sklearn.ensemble import RandomForestRegressor
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.performance_metrics.forecasting import smape_loss
regressor = RandomForestRegressor()
forecaster = ReducedRegressionForecaster(regressor, window_length=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=['y_train', 'y_test', 'y_pred'])
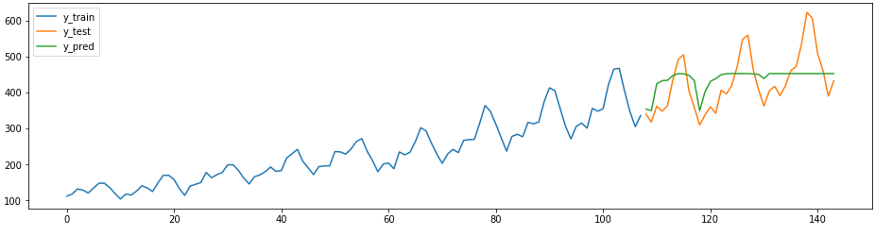
smape_loss(y_test, y_pred)В sktime также есть собственные методы прогнозирования, например
AutoArima.from sktime.forecasting.arima import AutoARIMA
forecaster = AutoARIMA(sp=12)
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
plot_ys(y_train, y_test, y_pred, labels=["y_train", "y_test", "y_pred"]);
smape_loss(y_test, y_pred)
>>0.07395319887252469Чтобы глубже погрузиться в функционал прогнозирования sktime, ознакомьтесь с руководством по ссылке.
Классификация временных рядов
Также
sktime можно использовать для классификации временных рядов на различные группы. В примере кода ниже классификация одиночных временных рядов делается также просто, как и классификация в scikit-learn. Единственное отличие – это вложенная структура данных временных рядов, о которой мы говорили выше.
from sktime.datasets import load_arrow_head
from sktime.classification.compose import TimeSeriesForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
X, y = load_arrow_head(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y)
classifier = TimeSeriesForestClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy_score(y_test, y_pred)
>>0.8679245283018868Пример был взят отсюда pypi.org/project/sktime
Данные, переданные в TimeSeriesForestClassifier
Чтобы узнать больше о классификации рядов, посмотрите руководства по одномерной и многомерной классификации в sktime.
Дополнительные ресурсы по sktime
Чтобы узнать больше о Sktime, посмотрите следующие ссылки с документацией и примерами.
- Детальное описание API: sktime.org
- Страница sktime на GitHub (с документацией);
- Примеры кода;
- Статья про Sktime: Markus Löning, Anthony Bagnall, Sajaysurya Ganesh, Viktor Kazakov, Jason Lines, Franz Király (2019): “sktime: A Unified Interface for Machine Learning with Time Series”
Логистическая регрессия для классификации данных. Бесплатный вебинар.
