
Предисловие
На текущем проекте я столкнулся с необходимостью внедрения единого процесса разработки и деплоймента для нескольких команд дата-инженеров. “Несколько команд” - это 5 команд дата-инженеров из разных стран (Америка, Индия, СНГ) плюс команда, которая отвечает за DataOps, назовём их админами. Разные часовые пояса, немного разная культура работы, немного разный уровень дисциплины и менеджмента. Мысль о том, что нужно менять процессы работы сразу в 5 командах для 40+ человек, приводила в небольшой трепет. Как разрабатывать и внедрять SDLC (software development lifecycle) для команд разработчиков я знал, но тут и люди другие, и специфика проекта другая. В общем, я ждал сложностей. И они были.
Моя команда непосредственно разрабатывает платформу обработки данных. Для платформы было принято несколько ключевых архитектурных решений (некоторые моменты упрощены)
Платформа состоит из набора очень простых сервисов. 1 сервис - это 1 питон-скрипт, исполняемый в Databricks.
Каждый сервис принимает на вход 1 конфигурацию.
Конфигурация - это yaml-файл с набором параметров для сервиса.
Дата-инженеры пишут конфигурации.
Текстовые конфигурации хранятся с системе контроля версий (gitlab в нашем случае).
Команда dataops отвечает за деплой всего в прод.
Получается, что 1 дата-пайплайн - это несколько yaml-файлов, хранящихся в GitLab и задеплоенных в наш оркестратор.
Какой процесс существовал
Изначально дата-инженеры решили использовать немного изменённый и вроде бы упрощённый git flow.
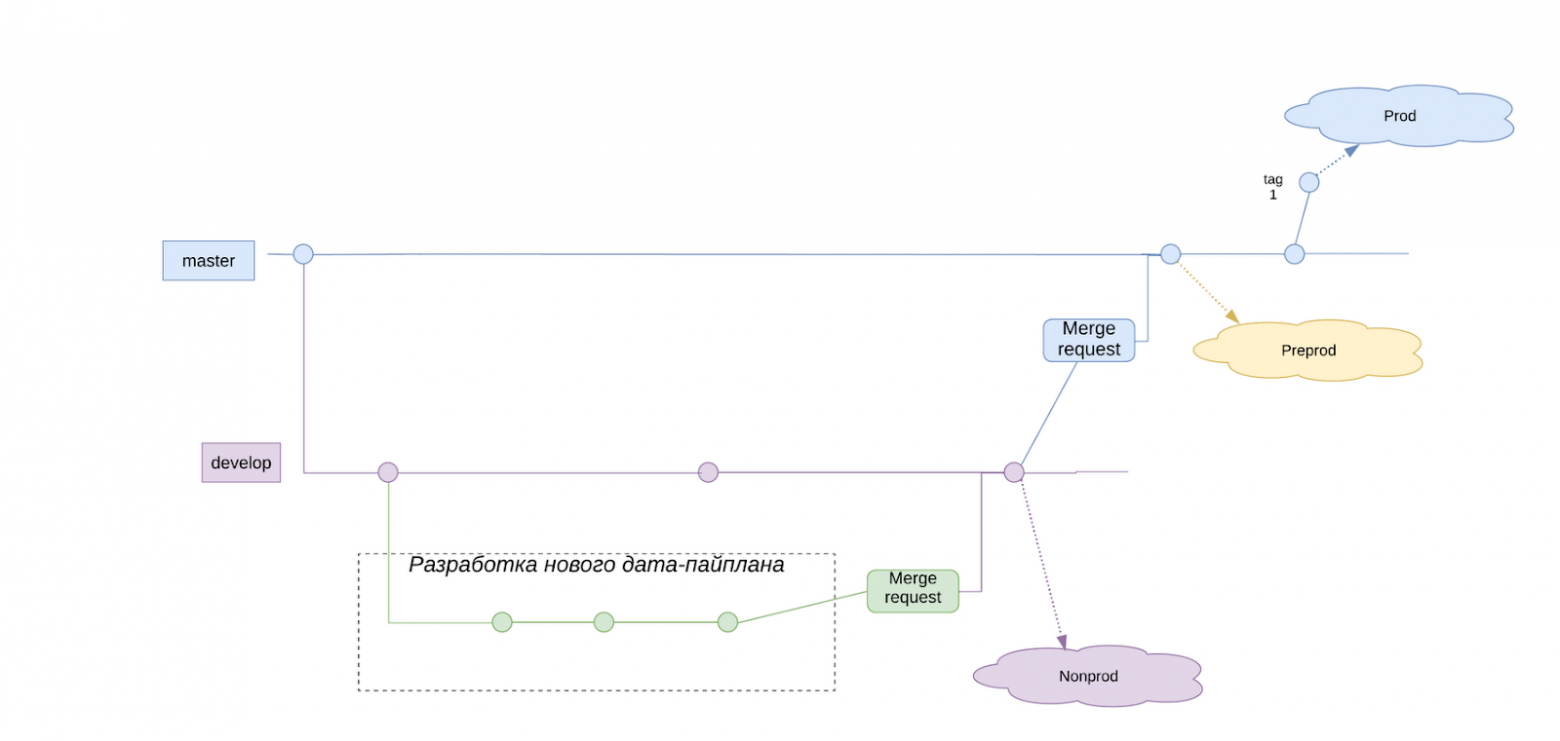
Есть master, есть develop, делаем фича-ветки, мёржим готовое в master, делаем релизы с тегов. Так как одного артефакта для деплоя не было, то от релизных веток решили отказаться, они как-то не вписывались в процесс.
Это был простой и понятный для всех процесс разработки. С помощью CI/CD новые и изменнёные конфигурации попадали на каждый из стендов (нонпрод, препрод, прод). Однако почти сразу выяснилось, что при таком подходе невозможно поддерживать состояние, когда теги делаются с полностью протестированной ветки master. Несколько команд параллельно создавали и меняли несколько наборов конфигураций. Все мёржили свою работу в master, и в итоге в прод постоянно улетали незаконченные конфигурации. Спасало лишь то, что запуск каждой конфигурации по расписанию нужно было настраивать отдельно. Но каждый деплоймент оказывался кошмаром: нужно было выяснить когда и кто уже успел выложить твой незаконченный конфиг в прод и что нужно доделать, чтобы твой конфиг попал в прод в нужном состоянии.
Команды буквально мешали друг другу разрабатывать и релизить новые конфигурации.
Как руководитель команды разработки платформы я понял, что именно мы должны предложить альтернативный подход. Потому что процесс релиза конфигураций на платформу является частью самой платформы: мы отвечаем не только за сервисы и набор параметров для них, но и за то, как (и насколько удобно и надёжно) текстовые конфигурации превращаются в работающие дата-пайпланы.
Мы должны были дать нашим пользователям и стабильно работающую платформу, и удобные вспомогательные инструменты работы с ней.
Это осознание привело к многим полезным последствиям. И одним из них была инициатива по внедрению нового процесса деплоймента.
Новый процесс
Несколько недель мы рисовали различные схемы и подходы, копались в документации GitLab, и наконец нашли ключевую фишку, которая решила 90% наших проблем: GitLab умеет работать с файлами, которые изменены в конкретном merge request’е. Спасибо @KOHEGYCb за отличную имплементацию. Т.к. команды дата-инженеров работали 99% времени над разными конфигурациями, это давало возможность расценивать каждый merge request как некий маленький артефакт и деплоить каждый из них независимо друг от друга.
На схеме это можно изобразить следующим образом:
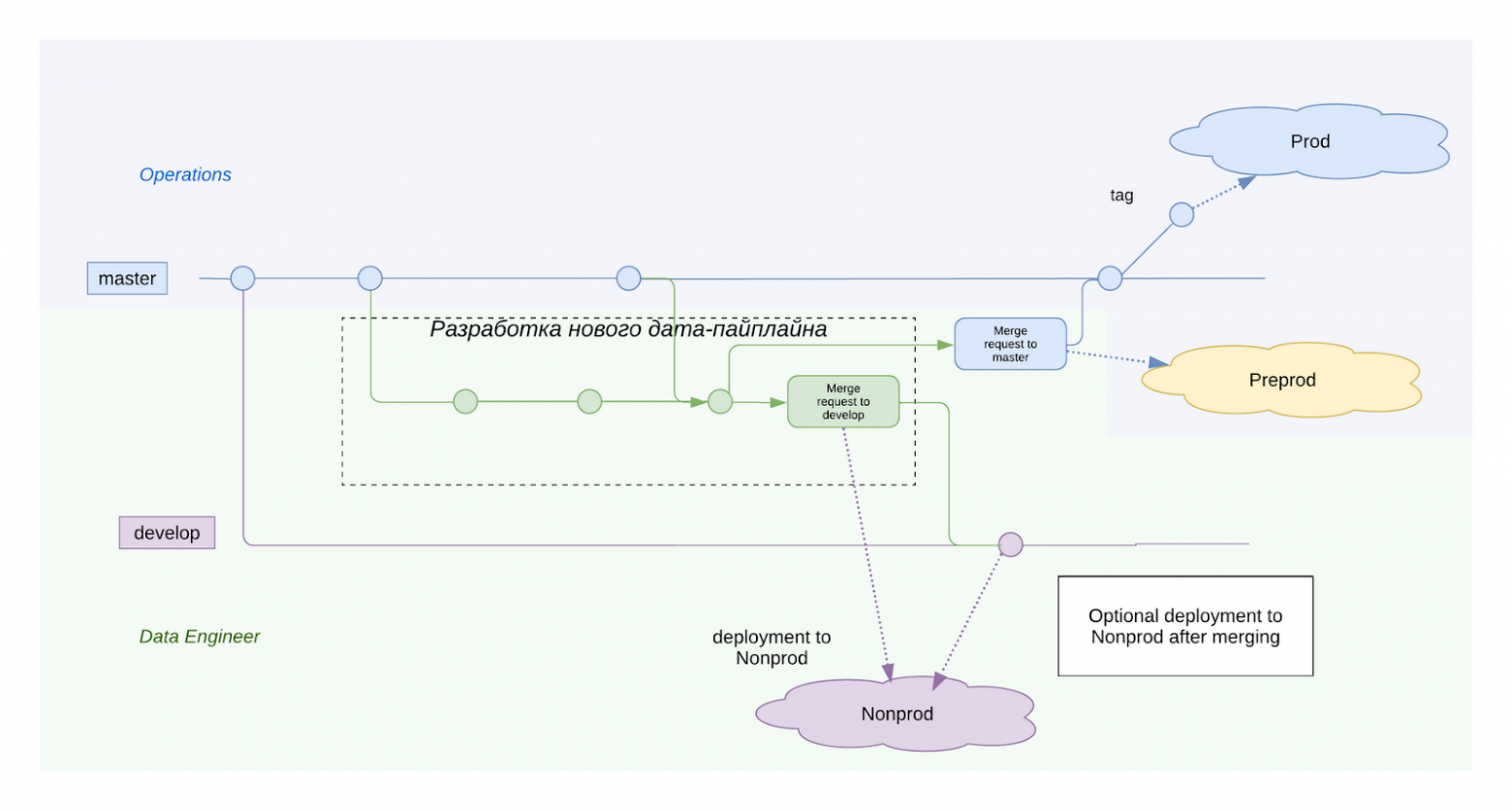
Ключевые моменты данного подхода:
develop никогда не вливается в master.
Feature-ветка делается с master.
С каждой feature-ветки делается два merge request`а: один в develop, чтобы выложить всё в нонпрод (стенд для разработки), другой в master, чтобы в выложить в препрод.
В деплой уходит сам merge request. Кнопку “Merge” для деплоя нажимать не надо. Merge происходит только после тестирования и верификации конфигов на определённом стенде.
В master попадают только конфигурации, протестированные на препроде.
Т.о. в любой момент времени master находится в стабильном состоянии и любой тег - это код, готовый к деплою в прод. Каждая команда получила возможность работать независимо друг от друга. Единственное место пересечения - это мёрж готовых конфигов в master ветку. То обстоятельство, что набор конфигов у каждой команды свой, помогало избегать конфликтов при мёрже.
Стоит отметить, что 10% проблем (кривые ветки, срочные фиксы, ошибки в деплое) были впоследствии решены возможностью ручного указания списка конфигураций для деплоя.
Этот подход сложнее первого, требует неплохих навыков работы с git’ом, и решает почти все проблемы с работой дата-инженеров.
Попытки внедрения
Попыток внедрения было 3. Точнее удачной была третья попытка. Первые две не увенчались успехом и были только шагами к внедрению.
Я готовился и к первой, и ко второй презентации: рисовал схемы, готовил план выступления, репетировал. Не помогло. После каждого выступления я чувствовал непонимание и недоверие к сказанному. Внедрение не двигалось с мёртвой точки, хотя уже все были вроде как согласны, что по-старому больше работать просто нельзя.
Здесь отрицательную роль сыграла распределённость команд: никто не знал друг друга в лицо, в лучшем случае по голосам. Не все понимали кто я такой, почему я перед ними выступаю и почему они должны меня слушать.
После второй презентации я сходил на TeamLead Conf. Трек от Aletheia Digital дал очень много пищи для размышлений. Так что третий подход сильно отличался от предыдущих двух.
Третья презентация начиналась с большого блока “почему я имею право говорить вам о том, как вы должны работать”. В чуть более мягкой форме, но смысл был именно такой. Этот “разгон” был необходим мне лично, чтобы буквально самому себе дать право на внедрение нового процесса. И этот “разгон” решил проблему недоверия ко мне: все согласились, что я имею право и авторитет на внедрение.
Только после того, как внимание людей было обращено ко мне, я начал показывать схемы и объяснять процессы работы. Потом мы обсудили, что нужны конкретные даты перехода на новый процесс и обучение людей. После презентации я создал страницу с командами и картинками как работать с новым процессом из командной строки, из веб-интерфейса GitLab и из PyCharm. Это сняло 80% вопросов от дата-инженеров.
Последняя презентация сильно отличалась от стандартных слайдов. Она была сделала в Lucidchart с непривычной анимацией: на одном большом слайде были вопросы и ответы, презентация фокусировалась на каждом из них и двигалась нелинейно. Это привлекало внимание, а плавная анимация давала возможность показать сначала масштаб происходящего, а потом обсудить каждую из деталей.
Вынесенные уроки
Поставить себя над командами
Одним из важнейших условий успешного внедрения новых процессов, в том числе и разработки ПО, является наличие и признание прав на это внедрение.
С одной стороны, вы должны обладать правами на внедрение новых процессов, например по распоряжению вышестоящего начальства. А с другой - осознавать сами, что имеете эти права.
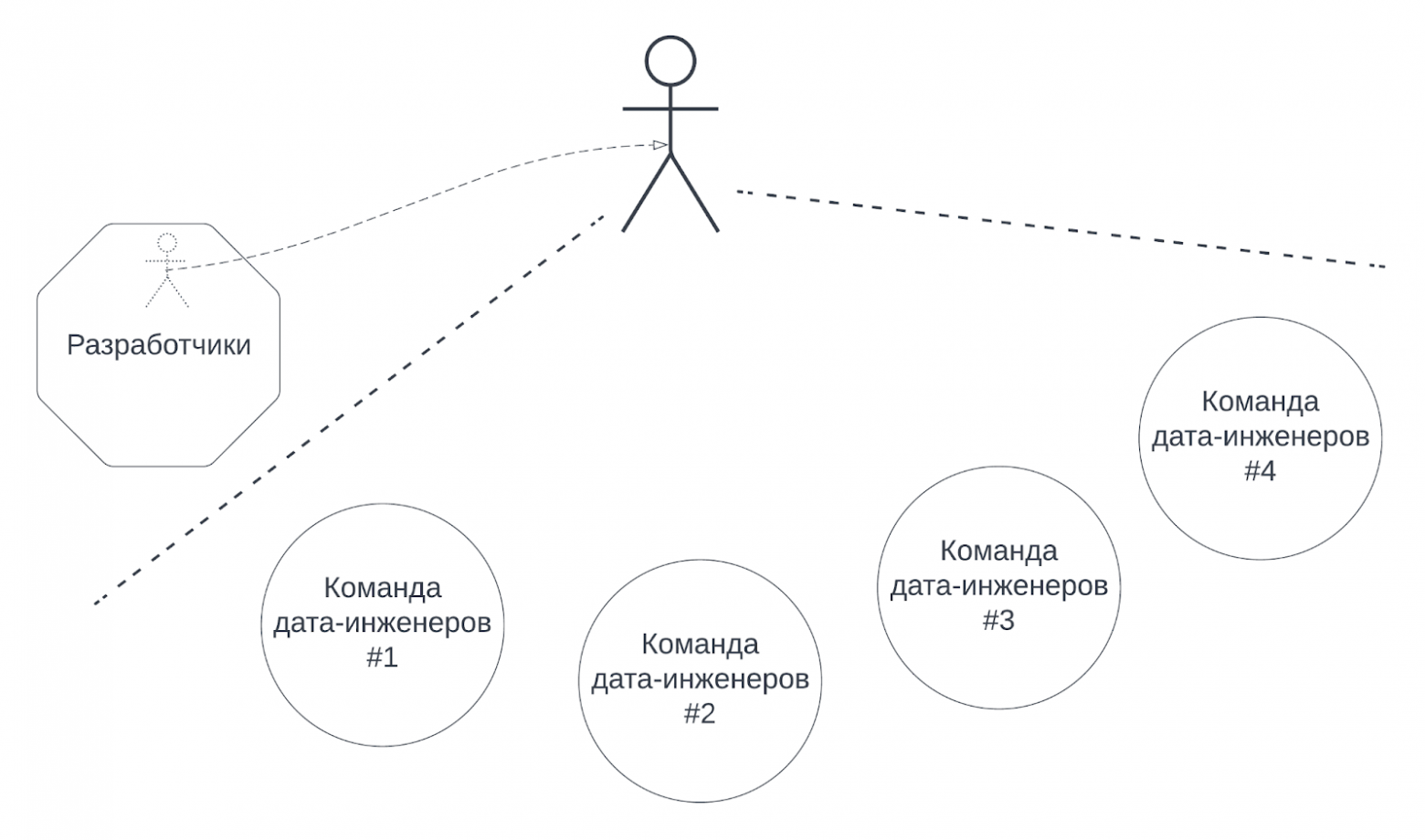
Команды напрямую или опосредованно должны вам подчиняться, и члены команд должны признавать ваше право на управление ими.
В моём случае схематично это выглядело следующим образом:
Донести проблему
Донесение наличия проблемы - ещё одно важное условие успешного внедрения. Если члены команд понимают, что у них есть сложности, если они осознают, что есть вариант работать быстрее и проще, тогда можно считать, что половина дела уже сделана.
Объяснить людям, что у них есть проблема чаще сложнее, чем эту проблему потом решить.
Проверить квалификацию
Одной из сложностей при внедрении было то, что дата-инженеры не обладали хорошими навыками по работе с git`ом. Работая в командах программистов, я ошибочно стал думать, что буквально все умеют использовать системы контроля версий. Оказалось, что не все. Пришлось несколько раз объяснять разницу между созданием Merge Request’а в GitLab и настоящим мёржем. Я бы предпочёл термины “pull request” и “merge” как в GitHub: разные слова снимают часть вопросов. Но в GitLab это называется как называется.
Внедрение любого процесса требует проверки квалификации и обучения людей.
Донести решение
Очевидно, что людям нужно не только донести проблему, но и объяснить как вы предлагаете её решить.
Подготовьте схемы, нарисуйте процессы. Меньше текста, больше диаграмм. Финальной диаграммой, которая объяснила почти всё и всем, была BPMN-схема: роли, шаги, зависимости были показаны в доступном виде.
Несколько дата-пайплайнов было задеплоено совместно с моей командой, что дало возможность научиться работать по новой схеме и дата-инженерам, и команде dataops.
Live Demo было очень полезным и важным элементом презентации нового процесса деплоймента.
Дать время на адаптацию
Внедрение требует времени. Не только на разработку и апробацию самого подхода, но и на то, чтобы люди освоили его и начали использовать. По умолчанию люди встречают изменения с большой неохотой и сопротивлением. Привычное чаще понятнее и проще, даже если оно плохо работает. Дайте людям время на адаптацию.
Предоставьте людям возможность задавать вам вопросы и консультироваться, будьте отзывчивы и терпеливы.
***
В конечном итоге новый процесс разработки и развёртывания успешно работает полтора года, выдержал глобальную миграцию, масштабирование на большее количество команд дата-инженеров и на большее (на два порядка) количество конфигураций.
Разница языков, культур и часовых поясов не сыграла значительной роли: ключевые моменты внедрения новых процессов остаются такими же. Принципы конструктивной конфронтации снимают большую часть проблем и при работе в мультикультурной среде.
В заключение приглашаю всех на бесплатный вебинар, где рассмотрим с какими сложностями сталкивается тимлид при управлении сотрудниками на удалёнке, как с этими сложностями справиться, какие подходы и инструменты можно использовать. Как работать с мотивацией, как ставить задачи и контролировать их выполнение, какие особенности при планировании работ и обсуждении требований, как проводить онбординг - коснёмся всех этих тем и проанализируем какие специфичные моменты есть при удалённой работе. И конечно же "сверим часы" в прямом смысле этого слова: разница в часовых поясах - это особая изюминка удалённой работы.
