«Просто так» результат SQL-запроса возвращает записи в том порядке, который наиболее удобен серверу СУБД. Но человек гораздо лучше воспринимает хоть как-то упорядоченные данные — это помогает быстро сравнивать соответствие различных датасетов.
Поэтому со временем у разработчика может выработаться рефлекс «Дай-ка я на всякий случай это вот отсортирую!» Конечно, иногда подобная сортировка бывает оправдана прикладными задачами, но обычно такой случай выглядит как в старом анекдоте:

Обычно мы просто не обращаем внимания на наличие лишнего
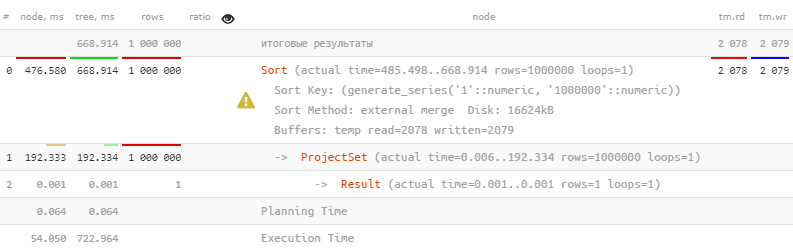
Из-за сортировки мы начали «свапаться» на диск (
Давайте как-то ускорять. И самый простой способ, который рекомендует нам подсказка под иконкой восклицательного знака — просто увеличить параметр work_mem так, чтобы памяти на сортировку все-таки хватало:
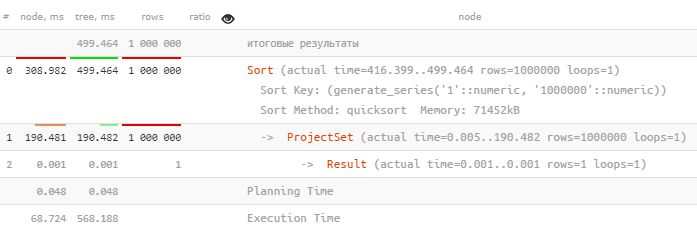
На четверть быстрее, хотя мы не трогали ни текст запроса, ни структуру базы! К сожалению, такой способ не всегда допустим — например, наш СБИС обслуживает одновременно тысячи клиентов в рамках одного узла PostgreSQL, и просто так раздавать память направо-налево мы не можем себе позволить. Может, есть способ вообще избавиться от сортировки?..
Начнем с самого простого варианта — чтения данных из вложенного запроса:
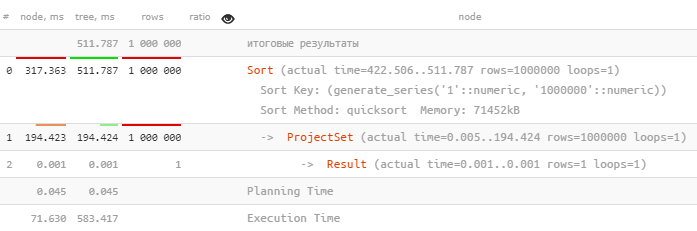
Почти 2/3 всего времени выполнения заняла сортировка, хоть и происходила вся в памяти:
Но был ли в ней вообще смысл? Нет, потому что чтение из вложенного запроса сохраняет порядок записей и так, когда в плане ему соответствуют узлы
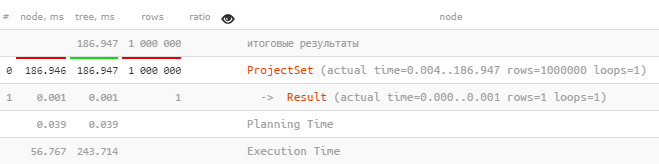
Вроде мы ничего особенного не сделали, а запрос уже ускорился более чем в 2 раза.
Следующий пример обычно возникает в результате отладки, когда разработчик сначала проверял внутренний запрос, а потом вставил его в «обвязку» внешнего:
Мы-то понимаем, что «внутренняя» сортировка ни на что не влияет (в большинстве случаев), но СУБД — нет. Поправим:
Минус одна сортировка. Но вспомним предыдущий пункт насчет упорядоченности SRF, и исправим до конца:
Вот и минус вторая сортировка. На данном конкретном запросе мы выиграли порядка 5%, всего лишь убрав лишнее.
Одна из «классических» причин неэффективности SQL-запросов, о которых я рассказывал в статье «Рецепты для хворающих SQL-запросов»:
То есть при разработке структуры базы мы описали FOREIGN KEY, повесили индекс на это поле, чтобы он отрабатывал быстро… А потом пошли прикладные задачи.
Например, мы хотим узнать, когда был выставлен последний счет по конкретному клиенту:
Н-да… Прочитать почти мегабайт данных ради одного числа — это сильно. Но давайте расширим индекс полем сортировки, используемой в запросе:
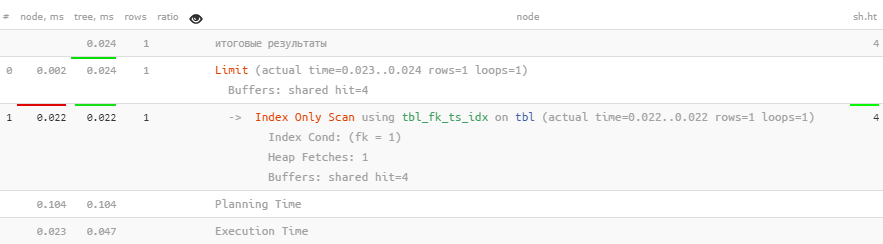
Ух! Теперь весь наш запрос выполнился быстрее, чем одна только сортировка в предыдущем варианте.
Но что делать, если от нас хотят такую сортировку, которая ну никак нормально на индекс не укладывается, хотя вроде и должна?
Допустим, что нам надо показать оператору в CRM «топовые» 10 заявок — сначала все «неназначенные» заявки (
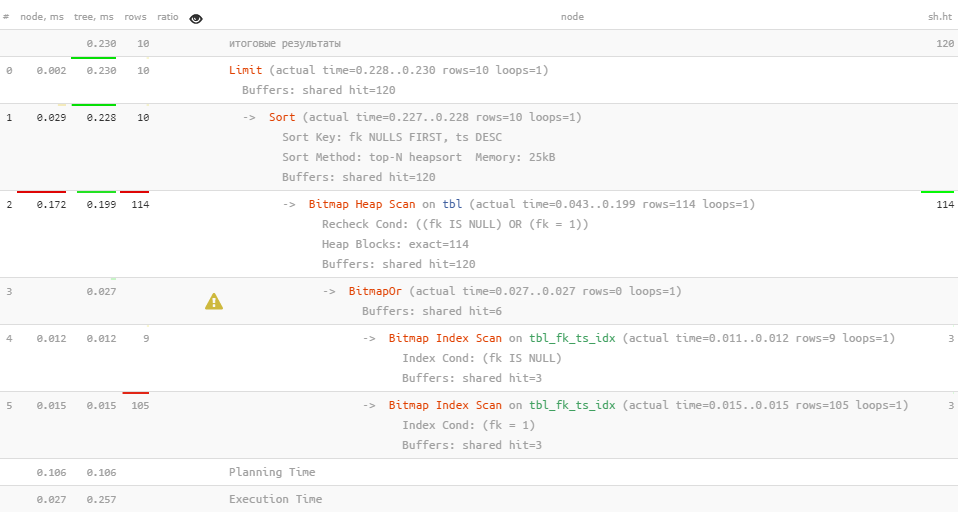
Вроде и индекс у нас есть, вроде и сортировка по нужным ключам, но как-то все некрасиво в плане… Но давайте воспользуемся знанием, что чтение из вложенного запроса сохраняет порядок — разделим нашу выборку на две заведомо непересекающиеся и снова «склеим» с помощью
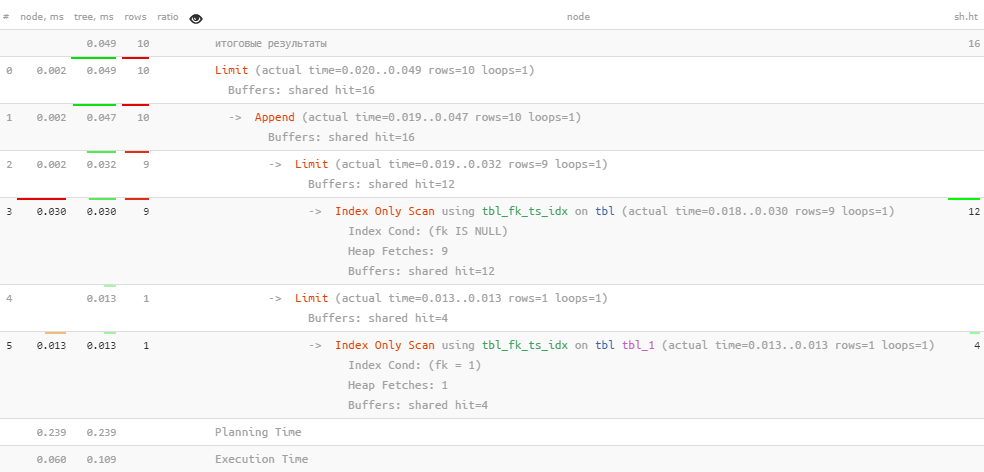
И — снова ни одной сортировки в плане, а запрос стал почти в 5 раз быстрее.
Давайте теперь попробуем посчитать сразу по первым 10 клиентам одновременно количество заявок и время последней с помощью оконных функций:
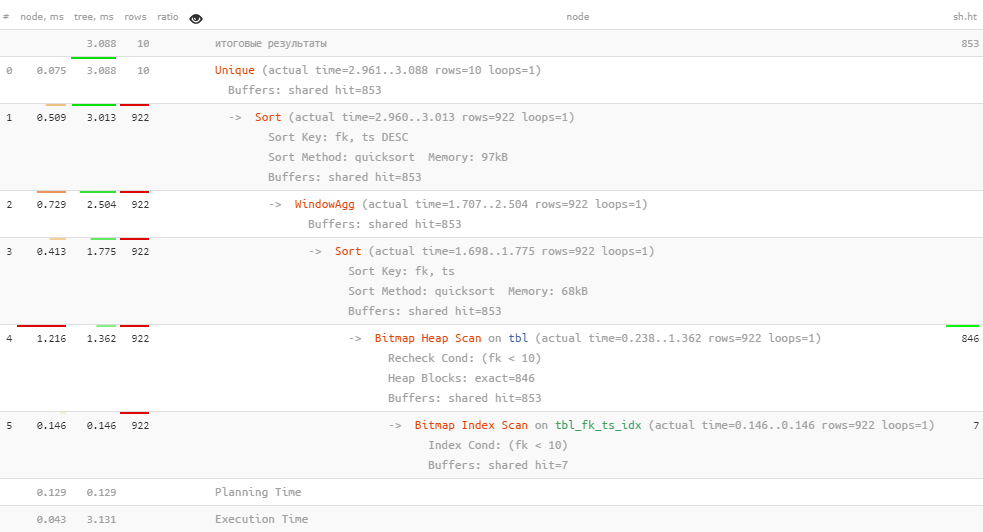
Сначала мы сортируем по
Замечу, что если просто написать сортировку как в самом запросе
Но ведь
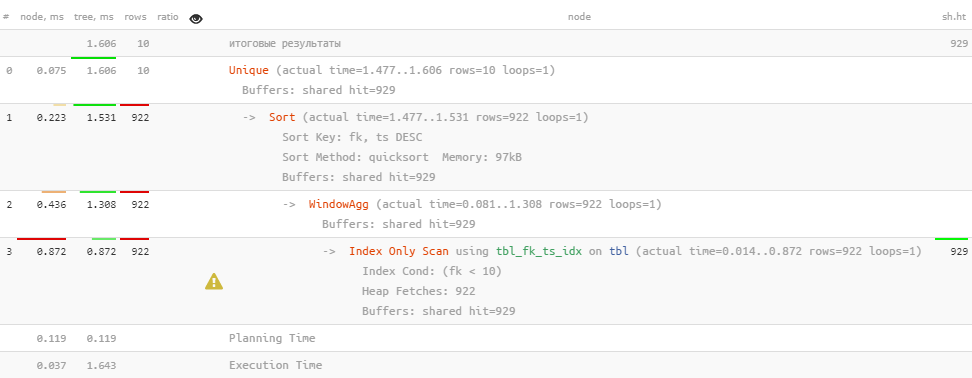
Так, от одной сортировки избавились. Правда, из-за этого теперь стали читать чуть больше
Хм… Но ведь и оставшаяся сортировка с ним тоже совпадает. Можно ли и от нее избавиться, не нарушив корректность результата? Вполне! Для этого всего лишь укажем нужную «рамку» окна «по всем записям» (
Итого — тот же результат в 2.5 раза быстрее, и без единой лишней сортировки.
Давайте продолжим экспериментировать, и попробуем получить полный список клиентов со временем последней заявки для каждого, раз у нас есть подходящий индекс:
Прочитать почти 8GB данных ради 10K записей — как-то многовато… Давайте воспользуемся методикой «рекурсивного DISTINCT»:
Получилось в 12 раз быстрее, потому что мы не читали ничего лишнего, в отличие от
Знаете другие способы устранения лишних сортировок? Напишите в комментариях!
Поэтому со временем у разработчика может выработаться рефлекс «Дай-ка я на всякий случай это вот отсортирую!» Конечно, иногда подобная сортировка бывает оправдана прикладными задачами, но обычно такой случай выглядит как в старом анекдоте:
Программист ставит себе на тумбочку перед сном два стакана. Один с водой — на случай, если захочет ночью пить. А второй пустой — на случай, если не захочет.Давайте разбираться — когда сортировка в запросе точно не нужна и несет с собой потерю производительности, когда от нее можно относительно дешево избавиться, а когда сделать из нескольких — одну.
#1: Нехватка work_mem
Обычно мы просто не обращаем внимания на наличие лишнего
Sort-узла в плане — он отрабатывает очень быстро по сравнению с самим извлечением данных. Но стоит чему-то пойти не так и перестать сортируемой выборке умещаться в памяти…SELECT generate_series(1, 1e6) i ORDER BY i;Из-за сортировки мы начали «свапаться» на диск (
buffers temp written), и потратили на это порядка 70% времени!Давайте как-то ускорять. И самый простой способ, который рекомендует нам подсказка под иконкой восклицательного знака — просто увеличить параметр work_mem так, чтобы памяти на сортировку все-таки хватало:
ALTER SYSTEM SET work_mem = '128MB';На четверть быстрее, хотя мы не трогали ни текст запроса, ни структуру базы! К сожалению, такой способ не всегда допустим — например, наш СБИС обслуживает одновременно тысячи клиентов в рамках одного узла PostgreSQL, и просто так раздавать память направо-налево мы не можем себе позволить. Может, есть способ вообще избавиться от сортировки?..
#2: Сортировка уже отсортированного
Начнем с самого простого варианта — чтения данных из вложенного запроса:
SELECT
*
FROM
(
SELECT generate_series(1, 1e6) i
) T
ORDER BY
i;Почти 2/3 всего времени выполнения заняла сортировка, хоть и происходила вся в памяти:
Но был ли в ней вообще смысл? Нет, потому что чтение из вложенного запроса сохраняет порядок записей и так, когда в плане ему соответствуют узлы
Subquery Scan/Materialize/ProjectSet. Поправим:SELECT
*
FROM
(
SELECT generate_series(1, 1e6) i
) T;Вроде мы ничего особенного не сделали, а запрос уже ускорился более чем в 2 раза.
Этим же свойством сохранения порядка записей обладают чтение из CTE (Common Table Expression, узелCTE Scan), SRF (Set-Returning Function,Function Scan) или VALUES (Values Scan).
#3: Вложенная отладочная сортировка
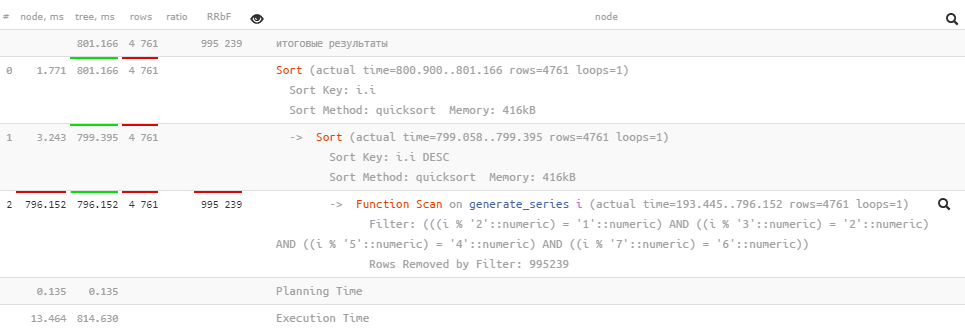
Следующий пример обычно возникает в результате отладки, когда разработчик сначала проверял внутренний запрос, а потом вставил его в «обвязку» внешнего:
SELECT
i
, 1e6 - i
FROM
(
SELECT
*
FROM
generate_series(1, 1e6) i
WHERE
(i % 2, i % 3, i % 5, i % 7) = (1, 2, 4, 6)
ORDER BY -- осталось от отладки
i DESC
) T
ORDER BY
i;
Мы-то понимаем, что «внутренняя» сортировка ни на что не влияет (в большинстве случаев), но СУБД — нет. Поправим:
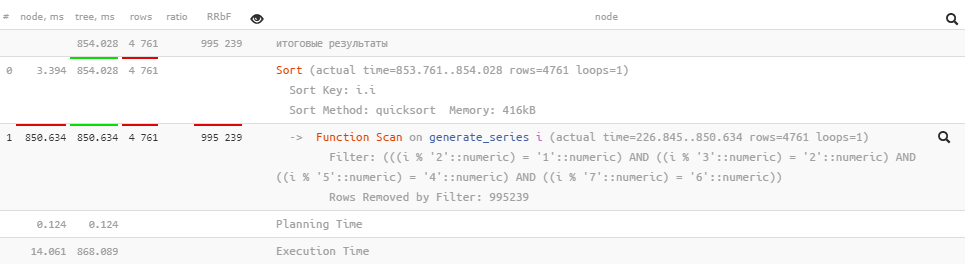
SELECT
i
, 1e6 - i
FROM
(
SELECT
*
FROM
generate_series(1, 1e6) i
WHERE
(i % 2, i % 3, i % 5, i % 7) = (1, 2, 4, 6)
) T
ORDER BY
i;
Минус одна сортировка. Но вспомним предыдущий пункт насчет упорядоченности SRF, и исправим до конца:
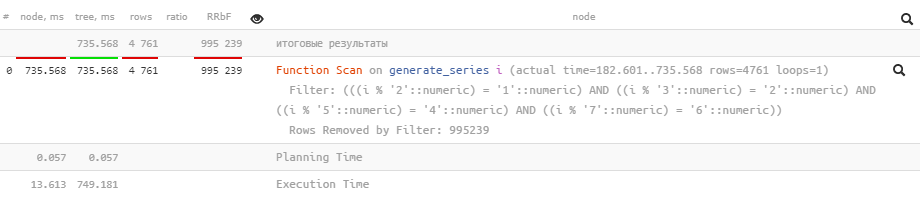
SELECT
i
, 1e6 - i
FROM
generate_series(1, 1e6) i
WHERE
(i % 2, i % 3, i % 5, i % 7) = (1, 2, 4, 6);
Вот и минус вторая сортировка. На данном конкретном запросе мы выиграли порядка 5%, всего лишь убрав лишнее.
#4: Index Scan вместо сортировки
Одна из «классических» причин неэффективности SQL-запросов, о которых я рассказывал в статье «Рецепты для хворающих SQL-запросов»:
CREATE TABLE tbl AS
SELECT
(random() * 1e4)::integer fk -- 10K разных внешних ключей
, now() - ((random() * 1e8) || ' sec')::interval ts
FROM
generate_series(1, 1e6) pk; -- 1M "фактов"
CREATE INDEX ON tbl(fk); -- индекс для foreign keyТо есть при разработке структуры базы мы описали FOREIGN KEY, повесили индекс на это поле, чтобы он отрабатывал быстро… А потом пошли прикладные задачи.
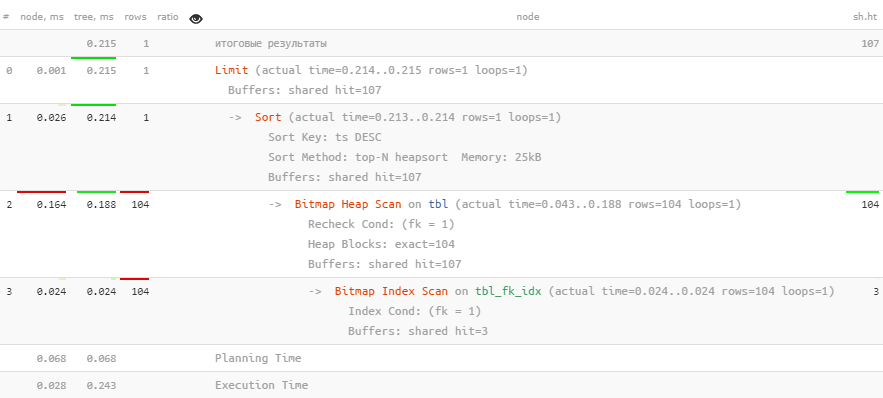
Например, мы хотим узнать, когда был выставлен последний счет по конкретному клиенту:
SELECT
ts
FROM
tbl
WHERE
fk = 1 -- отбор по конкретной связи
ORDER BY
ts DESC -- хотим всего одну "последнюю" запись
LIMIT 1;Н-да… Прочитать почти мегабайт данных ради одного числа — это сильно. Но давайте расширим индекс полем сортировки, используемой в запросе:
DROP INDEX tbl_fk_idx;
CREATE INDEX ON tbl(fk, ts DESC);Ух! Теперь весь наш запрос выполнился быстрее, чем одна только сортировка в предыдущем варианте.
#5: UNION ALL вместо сортировки
Но что делать, если от нас хотят такую сортировку, которая ну никак нормально на индекс не укладывается, хотя вроде и должна?
TRUNCATE TABLE tbl;
INSERT INTO tbl
SELECT
CASE
WHEN random() >= 1e-5
THEN (random() * 1e4)::integer
END fk -- 10K разных внешних ключей, из них 0.0001 - NULL'ы
, now() - ((random() * 1e8) || ' sec')::interval ts
FROM
generate_series(1, 1e6) pk; -- 1M "фактов"Допустим, что нам надо показать оператору в CRM «топовые» 10 заявок — сначала все «неназначенные» заявки (
fk IS NULL), начиная от самых старых, а затем все «его» (fk = 1):SELECT
*
FROM
tbl
WHERE
fk IS NULL OR
fk = 1
ORDER BY
fk NULLS FIRST, ts DESC
LIMIT 10;Вроде и индекс у нас есть, вроде и сортировка по нужным ключам, но как-то все некрасиво в плане… Но давайте воспользуемся знанием, что чтение из вложенного запроса сохраняет порядок — разделим нашу выборку на две заведомо непересекающиеся и снова «склеим» с помощью
UNION ALL, примерно как делали это в статье «PostgreSQL Antipatterns: сказ об итеративной доработке поиска по названию, или «Оптимизация туда и обратно»»:(
SELECT
*
FROM
tbl
WHERE
fk IS NULL
ORDER BY
fk, ts DESC
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk = 1
ORDER BY
fk, ts DESC
LIMIT 10
)
LIMIT 10;И — снова ни одной сортировки в плане, а запрос стал почти в 5 раз быстрее.
#6: Сортировки для оконных функций
Давайте теперь попробуем посчитать сразу по первым 10 клиентам одновременно количество заявок и время последней с помощью оконных функций:
SELECT DISTINCT ON(fk)
*
, count(*) OVER(PARTITION BY fk ORDER BY ts) -- без DESC!
FROM
tbl
WHERE
fk < 10
ORDER BY
fk, ts DESC; -- хотим "последнее" значение tsСначала мы сортируем по
(fk, ts) для вычисления «оконного» count(*), а потом еще раз по (fk, ts DESC) — для вычисления DISTINCT.Замечу, что если просто написать сортировку как в самом запросе
count(*) OVER(PARTITION BY fk ORDER BY ts DESC), то будет, конечно, быстрее. Только вот результат неправильный — везде будут одни единички.Но ведь
count, в отличие от разных first_value/lead/lag/..., вообще не зависит от порядка записей — давайте просто уберем сортировку для него:SELECT DISTINCT ON(fk)
*
, count(*) OVER(PARTITION BY fk)
FROM
tbl
WHERE
fk < 10
ORDER BY
fk, ts DESC;Так, от одной сортировки избавились. Правда, из-за этого теперь стали читать чуть больше
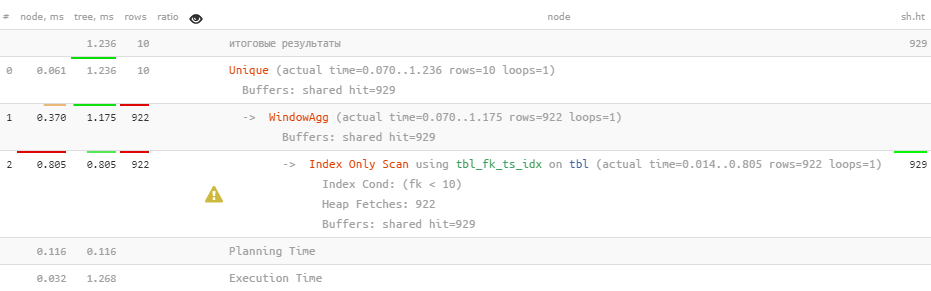
buffers, обменяв Bitmap Heap Scan на Index Only Scan по нашему индексу, с которым совпадает целевая сортировка — зато быстрее!Хм… Но ведь и оставшаяся сортировка с ним тоже совпадает. Можно ли и от нее избавиться, не нарушив корректность результата? Вполне! Для этого всего лишь укажем нужную «рамку» окна «по всем записям» (
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING):SELECT DISTINCT ON(fk)
*
, count(*) OVER(PARTITION BY fk ORDER BY ts DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)
FROM
tbl
WHERE
fk < 10
ORDER BY
fk, ts DESC;Итого — тот же результат в 2.5 раза быстрее, и без единой лишней сортировки.
Bonus: Полезные сортировки, которые не происходят
Давайте продолжим экспериментировать, и попробуем получить полный список клиентов со временем последней заявки для каждого, раз у нас есть подходящий индекс:
SELECT DISTINCT ON(fk)
*
FROM
tbl
ORDER BY
fk, ts DESC;
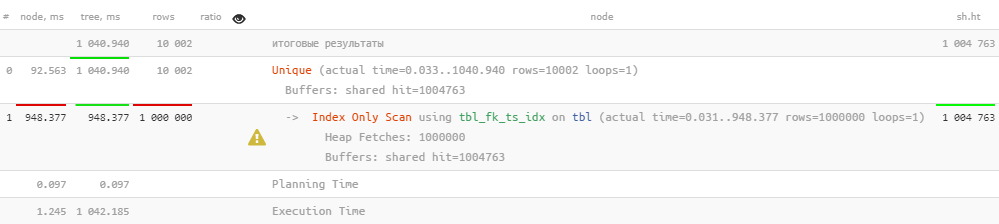
Прочитать почти 8GB данных ради 10K записей — как-то многовато… Давайте воспользуемся методикой «рекурсивного DISTINCT»:
WITH RECURSIVE T AS (
(
SELECT
fk
, ts
FROM
tbl
ORDER BY
fk, ts DESC
LIMIT 1 -- первая запись с минимальным ключом
)
UNION ALL
SELECT
X.*
FROM
T
, LATERAL(
SELECT
fk
, ts
FROM
tbl
WHERE
fk > T.fk
ORDER BY
fk, ts DESC
LIMIT 1 -- следующая по индексу запись
) X
WHERE
T.fk IS NOT NULL
)
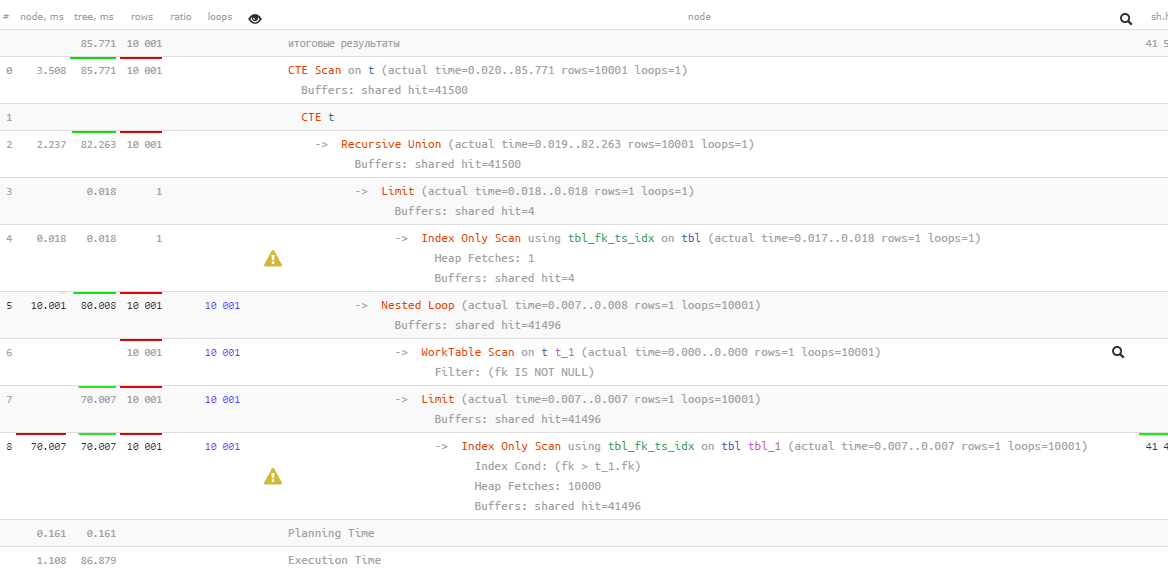
TABLE T;Получилось в 12 раз быстрее, потому что мы не читали ничего лишнего, в отличие от
Index Only Scan. Хоть мы и использовали дважды в запросе ORDER BY, ни одной сортировки в плане так и не появилось.Вероятно, в будущих версиях PostgreSQL для таких «точечных» чтений появится соответствующий тип узла Index Skip Scan. Но скоро его ждать не стоит.Замечу, что результат этих запросов все-таки немного отличается — второй не обрабатывает записи с fk IS NULL. Но кому надо — извлечет их отдельно.Знаете другие способы устранения лишних сортировок? Напишите в комментариях!
