
Двоичные таблицы Юнга
7 мин
Итак, как и обещал, продолжение темы о таблицах Юнга. Напомню, что под таблицей Юнга понимается числовая матрица, обладающая некоторыми специальными свойствами. Матрица – это двумерный массив. И вот тут должен возникнуть естественный вопрос – а почему, собственно, массив должен быть двумерным? А что, если мы попробуем реализовать на тех же принципах таблицу размерности три, или четыре, а лучше всего, конечно, пять звездочек! О том, куда приведет нас такое обобщение, можно прочитать под катом…

 Доброго времени суток, хабр! Сегодня я бы хотел рассказать про жадные алгоритмы.
Доброго времени суток, хабр! Сегодня я бы хотел рассказать про жадные алгоритмы. В статье расскажу как можно очень быстро перечислить связные объекты на бинарном растре, значительно быстрее, чем я рассказывал в
В статье расскажу как можно очень быстро перечислить связные объекты на бинарном растре, значительно быстрее, чем я рассказывал в 
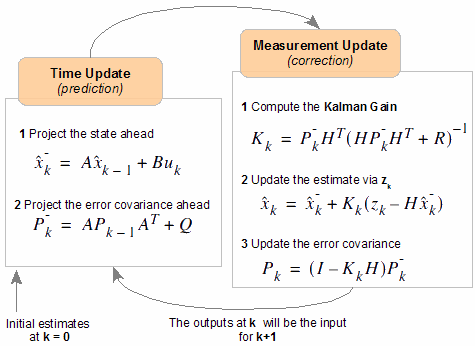 Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями.
Недавно прочитал пост из «Дополненной реальности», в котором упоминается Фильтр Калмана в сравнении с более простым «альфа-бета» фильтром. Давно собирался сочинить нечто вроде сниппета по составлению ФК, и вот думаю самое время. В статье я вам расскажу как на практике можно составить расширенный ФК не особо утруждая себя высоконаучными размышлениями и глубокими теоретическими изысканиями. Карта расстояний (Distance Map) — это объект, позволяющий быстро получить расстояние от заданной точки до определенной поверхности. Обычно представляет собой матрицу значений расстояний для узлов с фиксированным шагом. Часто используется в играх для определения «попадания» в игрока или предмет, и для оптимизационных задач по совмещению объектов: расположить объекты максимально близко друг к другу, но так, чтобы они не пересекались. В первом случае качество карты расстояний (то есть точность значений в узлах) не играет большой роли. Во втором — от нее могут зависеть жизни (в ряде приложений, связанных с нейрохирургией). В этой статье я расскажу как можно достаточно точно обсчитать карту расстояний за разумное время.
Карта расстояний (Distance Map) — это объект, позволяющий быстро получить расстояние от заданной точки до определенной поверхности. Обычно представляет собой матрицу значений расстояний для узлов с фиксированным шагом. Часто используется в играх для определения «попадания» в игрока или предмет, и для оптимизационных задач по совмещению объектов: расположить объекты максимально близко друг к другу, но так, чтобы они не пересекались. В первом случае качество карты расстояний (то есть точность значений в узлах) не играет большой роли. Во втором — от нее могут зависеть жизни (в ряде приложений, связанных с нейрохирургией). В этой статье я расскажу как можно достаточно точно обсчитать карту расстояний за разумное время.