Введение
Работая в издательстве журнала, я много раз становился свидетелем попыток создания хорошего рубрикатора. Большинство попыток сводились или к делению одной большой рубрики на несколько мелких, или, наоборот, к объединению нескольких мелких рубрик в одну крупную. Все попытки создать идеальный рубрикатор превращались в нахождение компромисса между сложным и очень сложным рубрикатором.
Так же хотелось бы отметить, что все виденные мной рубрикаторы были организованны в виде классического дерева с глубиной вложенности 2-3 уровня. И не было замечено попыток организовать рубрикатор иным образом (Речь идет только о печатных рубрикаторах).
В итоге у меня накопился список вопросов, которые приходится решать любому составителю рубрикатора.

 Продолжаем описание
Продолжаем описание  Этим постом мы продолжаем
Этим постом мы продолжаем  У нас великолепная работа — нам платят за просмотр порнографических роликов. Ну а серьезнее, мы работаем в R&D отделе компании
У нас великолепная работа — нам платят за просмотр порнографических роликов. Ну а серьезнее, мы работаем в R&D отделе компании 
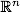 . Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).
. Координаты вектора описывают отдельные аттрибуты объекта. Например, цвет c, заданный в модели RGB, является вектором в трехмерном пространстве: c=(red, green, blue).