
Мониторинг популярных баз данных из единого интерфейса Quest Foglight — анонс вебинара
2 мин
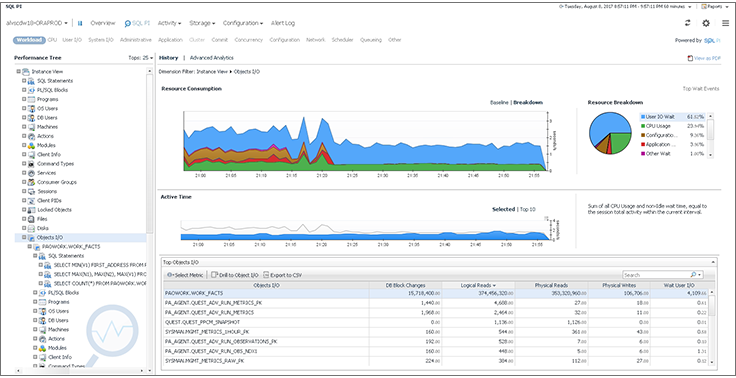
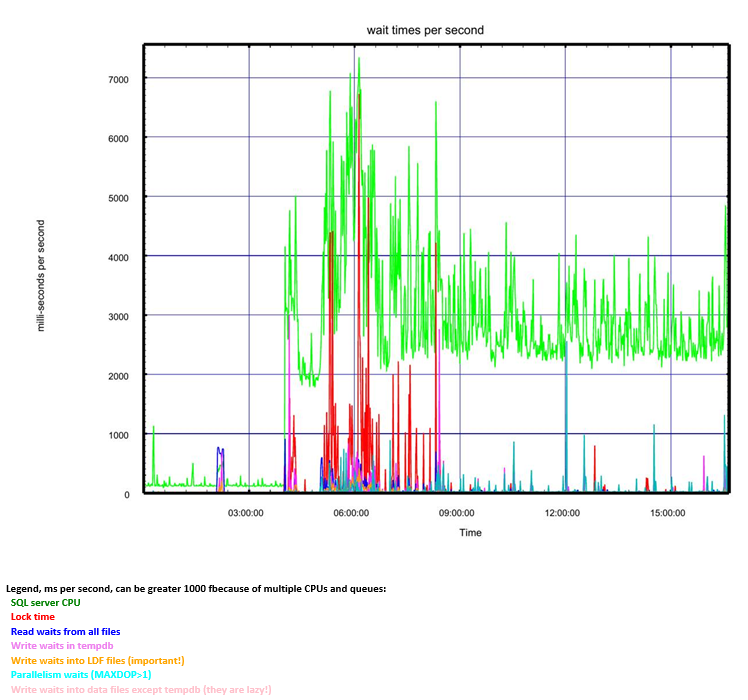
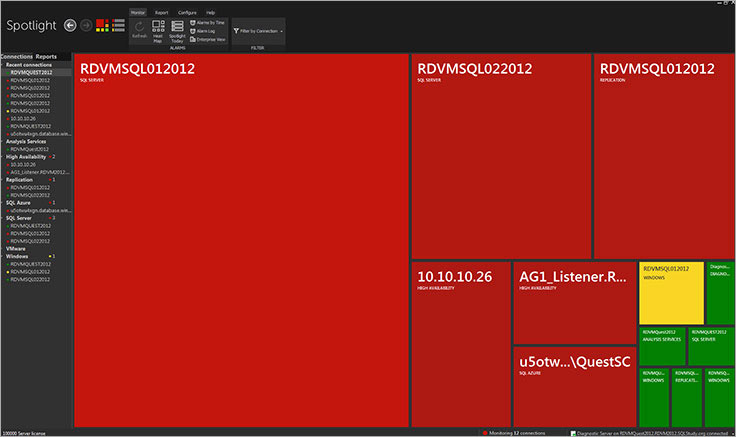
Foglight for Databases — удобный инструмент для DBA, который поддерживает мониторинг SQL Server, Oracle, MySQL, PostgreSQL, DB2, SAP ASE, MongoDB и Cassandra. И всё это в одном интерфейсе.
Кроме этого, инструмент позволяет сравнивать производительности БД в разные периоды времени (например, до релиза и после него), а также выполнять сравнение производительности различных экземпляров.
Приглашаем вас зарегистрироваться на вебинар, который состоится 7 апреля в 11 часов по московскому времени. Вы узнаете о возможностях решения, кейсах использования, лицензировании и сможете задать интересующие вопросы. Если вы не сможете присутствовать на вебинаре, в любом случае оставьте ваши контактные данные, мы вышлем вам запись после мероприятия. Под катом описание функционала решения и несколько скриншотов.
Кроме этого, инструмент позволяет сравнивать производительности БД в разные периоды времени (например, до релиза и после него), а также выполнять сравнение производительности различных экземпляров.
Приглашаем вас зарегистрироваться на вебинар, который состоится 7 апреля в 11 часов по московскому времени. Вы узнаете о возможностях решения, кейсах использования, лицензировании и сможете задать интересующие вопросы. Если вы не сможете присутствовать на вебинаре, в любом случае оставьте ваши контактные данные, мы вышлем вам запись после мероприятия. Под катом описание функционала решения и несколько скриншотов.









 Привет, Хабр!
Привет, Хабр!