Полезные возможности dbForge для администрирования баз данных MS SQL Server
2 мин
Туториал
Предисловие
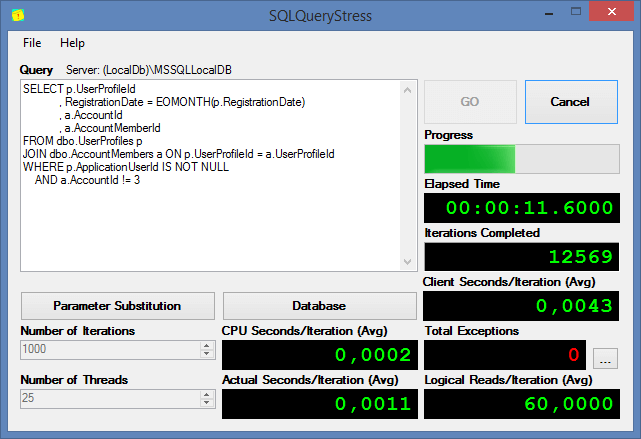
В данной статье будут разобраны полезные возможности dbForge, которые помогают в администрировании баз данных MS SQL Server. Также прошу заметить, что не все возможности будут разобраны.
Буду очень признателен, если в комментариях появятся альтернативные решения, а также дополнения к этой статье.