
Привет! Этот пост о том, что нового в DataGrip 2016.3. Напомню, что описанное справедливо и для других IDE на платформе IntelliJ с поддержкой баз данных: PHPStorm, PyCharm, RubyMine и, конечно, IntelliJ IDEA. Кроме одной маленькой возможности, о чём отмечу отдельно.
Этот релизный цикл был очень важным — удалось многое из того, что нас долго просили сделать: поддержка триггеров, поиск использований внутри представлений и функций, отложенное редактирование таблиц. Благодарим тех, кто не стесняется тестировать наши инструменты и пробует новые версии задолго до релиза.
Итак, DataGrip 2016.3!

Этот релизный цикл был очень важным — удалось многое из того, что нас долго просили сделать: поддержка триггеров, поиск использований внутри представлений и функций, отложенное редактирование таблиц. Благодарим тех, кто не стесняется тестировать наши инструменты и пробует новые версии задолго до релиза.
Итак, DataGrip 2016.3!




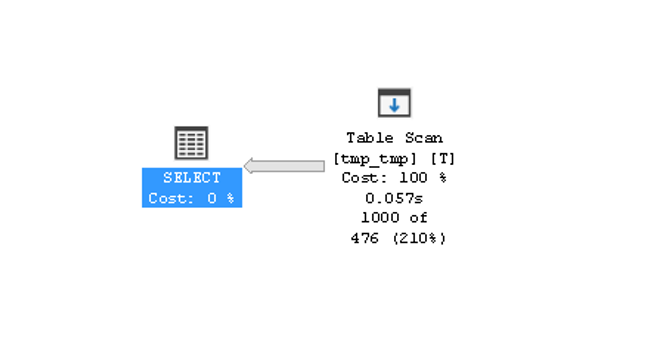
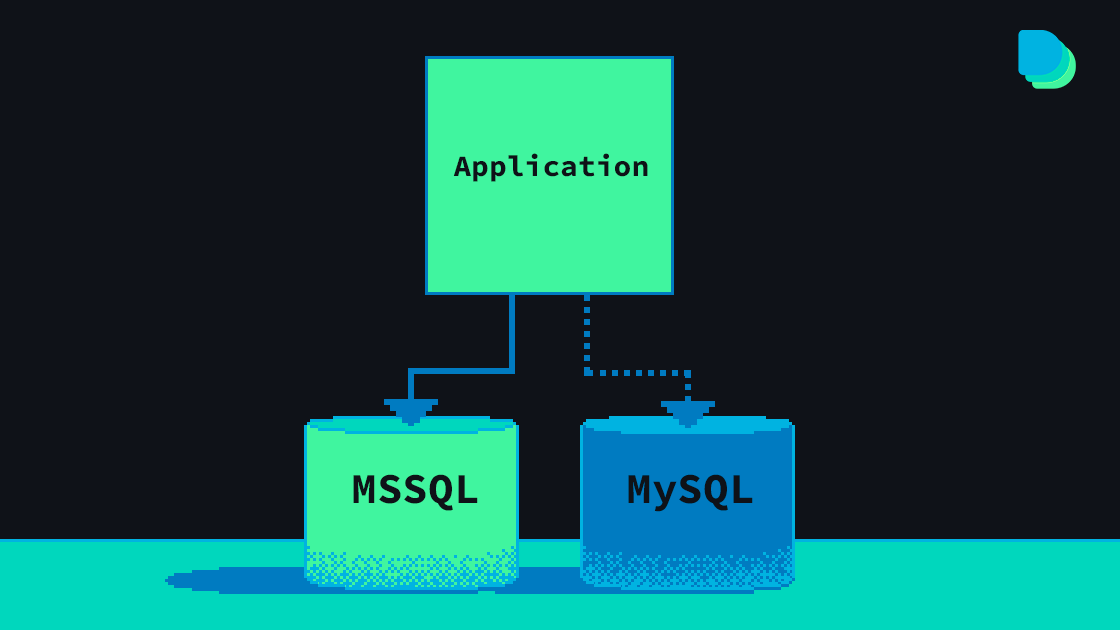






 Первого апреля принято начинать новость с очередной «правдивой» истории. Утром я уже читал обзор инженерного образца AMD Zen. Но в случае с SQL Server, все действительно является правдой.
Первого апреля принято начинать новость с очередной «правдивой» истории. Утром я уже читал обзор инженерного образца AMD Zen. Но в случае с SQL Server, все действительно является правдой.
 На той неделе пришлось разбираться в логике работы одного бесплатного тула. Почти детективная история вышла с ее автором, который впоследствии оказался индусом канадского происхождения проживающим в Южной Америке.
На той неделе пришлось разбираться в логике работы одного бесплатного тула. Почти детективная история вышла с ее автором, который впоследствии оказался индусом канадского происхождения проживающим в Южной Америке.