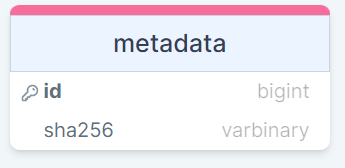
Именно такие претензии я услышал от наших девелоперов. Самое интересное, что это оказалось правдой, дав начало длительному расследованию. Речь пойдет про SQL servers, которые крутятся у нас на VMware.

Система управления реляционными базами данных

Если у вас на машине стрелочка показывает, что у вас осталась половина бака, то у вас точно осталась половина бака? На самом деле больше, так как современные машины врут и топлива еще немного есть, даже когда стрелка на нуле - забота об альтернативно одаренных водителях. А если сервер показывает 50% cpu, то сколько ресурсов у нас осталось?
Для многих ответ ясен, и это не 50%. Поэтому извините, если многие вещи будут вам очевидны. А вот для менеджеров, например, которые планируют ресурсы, это может быть открытием.


Приветствую, уважаемые хаброжители!
Так как занимаюсь переводом кода с MS SQL в Postgre SQL с начала 2019 года, то решил продолжить сравнение этих двух СУБД.
В прошлой публикации мы рассматривали отличия в быстродействии MS SQL и PostgreSQL для 1C.
Сегодня давайте сравним основные конструкции синтаксиса MS SQL и PostgreSQL для правильного чтения кода, а также для того, чтобы быстро изменить код из MS SQL для PostgreSQL или наоборот.
Начнем рассмотрение с сопоставления типов.

Поводом написать эту статью стал весьма достойный обзор Как мы тестировали VMware vSAN... компании КРОК. Обзор-то достойный, но в нем есть фраза, с которой я борюсь уже больше десятка лет. Админы СХД, виртуализаторы и интеграторы раз за разом повторяют: "Задержки в 5 мс — это отличный показатель". Даже цифра в 5 мс десять лет не меняется. Я это слышал вживую от весьма уважаемых админов уже не меньше десятка раз. От менее уважаемых — десятки, а уж сколько раз читал в интернете… Нет, нет, нет. Для OLTP нагрузок 5 мс, особенно так, как их обычно измеряют — это epic fail. Мне приходилось объяснять причины этого уже много раз, на этот раз я решил собрать свои мысли в переиспользуемую форму.
Сразу оговорюсь, что в упомянутой выше статье этих ошибок нет, скорее фраза сработала как триггер.
Эта статья не является ответом на множество вопросов по базам данных (БД) и системам управлениям базами данных (СУБД). Я как автор выражаю своё собственное мнение о трендах, стараясь опираться на беспристрастные показатели, статистики и т.д., но для примера приводя собственный опыт. Я не являюсь ангажированным представителем какой-либо компании и выражаю точку зрения опираясь на опыт более 25 лет работы с разными СУБД, в том числе, которую создавал своими руками. Не так много даже опытных программистов и архитекторов, которые знают все термины, технологии, какие подводные камни и куда идёт движение. Тема поистине огромная, поэтому в рамках одной статьи не раскрыть даже верхний уровень информации. Если кто-то не встретит свою любимую СУБД или её невероятный плюс, который стоит упомянуть, то прошу в комментариях указать и этим дополнить общую картину, что поможет другим разобраться и понять лучше предметную область. Поехали!
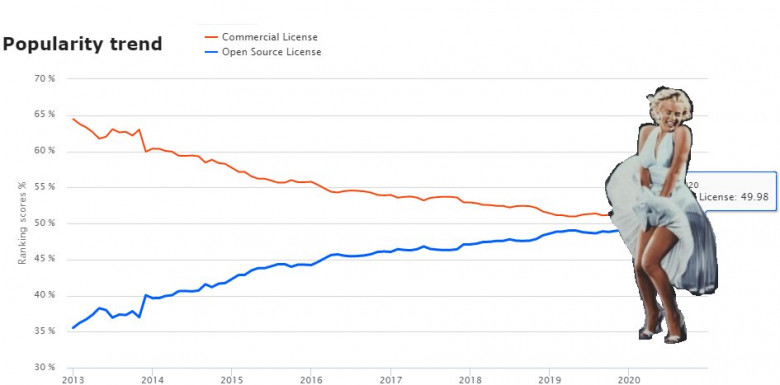
Open Source DBMS vs Commercial DBMS
Для начала приведён график с сайта, db-engines.com, по моим ощущениям, неплохо отслеживающим тренды БД. Именно этот график добавил желания написать статью о текущем положении дел.

Всем привет! Меня зовут Евгений, я занимаюсь разработкой и проектированием в Ozon. Больше всего работаю с MS SQL и C#, но попадаются и другие СУБД и языки программирования.
Ozon как продукт быстро растёт: во втором квартале этого года мы доставляли больше миллиона посылок в день. Для обработки такого объёма заказов мы используем разные языки и платформы: .NET (C#), Go, MS SQL Server и PostgreSQL.
Заказы пользователей обрабатываются разными системами, которые взаимодействуют между собой. Это порождает необходимость учитывать многочисленные интеграции и приводит к проблеме дублирования данных.
Я расскажу об одном таком случае, когда наша команда потратила много времени и сил, но всё-таки нашла оптимальный способ решения проблемы дублирования данных.
Но сначала позвольте погрузить вас немного в предметную область — объясню, на примере чего будет демонстрироваться проблема дублирования данных, и освещу некоторые методы её решения.

Недавно я писал статью - что такое 50% cpu? На системах с hyperthreading 50% cpu по метрикам означает, что большая часть ресурсов сервера уже использована. То есть cpu>50% - это уже "желтая зона", и мы ожидаем замедление всего, чего можно. Но я никогда не думал до экспериментов, что падение может быть столь катастрофическим.
Для экспериментов я использую MSSQL. Если вы не связаны с базами, прочитайте первую часть по диагонали до выводов.

 Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.
Недавно выдалась минутка посмотреть почему старый тестовый сервер безбожно тормозил… К нему я не имел никакого отношения, но меня одолевал спортивный интерес разобраться, что с ним не так.D:\SQL_2012\SYSTEM\MSDBData.mdf
D:\SQL_2012\SYSTEM\MSDBLog.ldf
SELECT name, size = size * 8. / 1024, space_used = FILEPROPERTY(name, 'SpaceUsed') * 8. / 1024
FROM sys.database_files
name size space_used
------------ -------------- ---------------
MSDBData 42626.000000 42410.374395
MSDBLog 459.125000 6.859375

Хотите легкого чтива под новый год? Вот крошечные истории про случаи из моей работы или случаи, свидетелем которых я стал.


Развитие происходит по спирали: когда-то люди не умели правильно индексировать, потом (в основном) научились, потом пришли noSQL и все снова забыли знание древних. Что вы будете делать, когда последние из старых DBA отплывут в Валинор?
Снова и снова и сталкиваюсь с полным набором антипаттернов индексирования. Я их перечислю, но! Для каждого антипаттерна есть исключение, когда именно это и стоит делать. Поэтому кликбейтно сформулированное правило верно в 95% случаях, но если вы хотите копнуть глубже, то прочитайте про исключения.
И в конце полезные скрипты для MSSQL, Postgres и MySQL.
 В далёком 2005 году я менял стек технологий с Java на .NET и поначалу в Visual Studio мне очень не хватало возможностей, которыми располагала IntelliJ IDEA. Пробуя различные плагины к студии, я остановился на ReSharper'е и по сей день его использую. Недавно стало интересно, есть ли похожие продукты для работы с SQL Server, а точнее с T-SQL кодом хранимых процедур. Собственно про один такой продукт я и хочу рассказать в этой статье.
В далёком 2005 году я менял стек технологий с Java на .NET и поначалу в Visual Studio мне очень не хватало возможностей, которыми располагала IntelliJ IDEA. Пробуя различные плагины к студии, я остановился на ReSharper'е и по сей день его использую. Недавно стало интересно, есть ли похожие продукты для работы с SQL Server, а точнее с T-SQL кодом хранимых процедур. Собственно про один такой продукт я и хочу рассказать в этой статье.