
Репликация из MySQL в Tarantool

Привет, Хабр! Сегодня поделюсь с вами статьёй, написанной по мотивам моего доклада на Tarantool Meetup. Маленькая история, почему в компании Мамба стали использовать Tarantool. Почему мы занялись репликацией из MySQL в Tarantool? Первая причина в том, что в какой-то момент нужно было начинать переходить на MySQL 5.7, но в нём отсутствует handler socket, который активно используется на наших серверах в MySQL 5.6. Мы даже связались с командой Percona, и они подтвердили, что 5.6 — это последняя версия c handler socket.
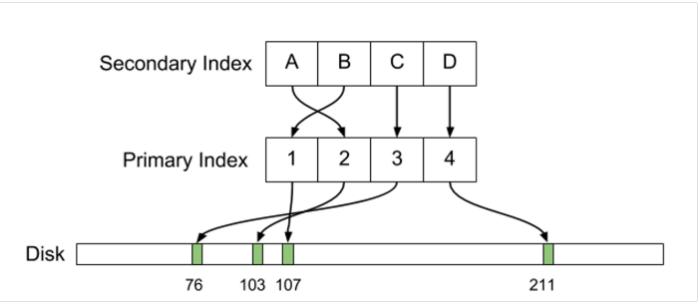
Вторая причина — мы начали пробное использование Tarantool, и скорость работы нам понравилась: мы просто сравнили memcache и Tarantool как key/value-хранилище, получив прирост производительности — с 0,6 до 0,3 мс на одинаковом железе. В относительном выражении Tarantool в два раза быстрее, в абсолютном выражении это не так круто, но всё же. И третья причина — желание полностью сохранить текущую структуру: есть MySQL Server Master и его Slave’ы, ничего переписывать не хотелось, хотелось оставить максимально близко к той архитектуре, что есть сейчас. Как бы нам сделать так, чтобы вместо Slave’ов MySQL 5.6, на которых используется handler socket, применить что-то другое и полностью не переписывать всю огромную архитектуру?

 Всё просто. Тут можно найти «Основы разбора запросов для чайников» в случае PostgreSQL и замечательные невыдуманные примеры из продакшена о том, как не надо писать запросы на PostgreSQL и MySQL и что бывает, если их так всё-таки писать.
Всё просто. Тут можно найти «Основы разбора запросов для чайников» в случае PostgreSQL и замечательные невыдуманные примеры из продакшена о том, как не надо писать запросы на PostgreSQL и MySQL и что бывает, если их так всё-таки писать.







 В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров. 