Отчёт о попытке получить заявленную эффективность от prepared statements
4 мин
Update: из заголовка статьи убрано слово «неудачной». Подробности ниже!
Рассказывая в своей статье о типичных заблуждениях, связанных с защитой от SQL инъекций, среди прочих я отметил тот факт, что серверные подготовленные выражения не работают в PHP по заявленному эффективному сценарию — 1 раз prepare(), потом 1000 раз executе().
Ну, то есть, в теории-то они работают — в пределах одного запуска скрипта. Но много ли вы знаете скриптов (написанных профессиональными программистами), которые выполняют кучу одинаковых запросов? Вот я тоже не знаю. Повторяющихся запросов (каких-нибудь множественных апдейтов) — доли процента, а в массе своей запросы уникальные (в пределах одного скрипта).
Соответственно, для нашего уникального запроса сначала выполняется prepare(), потом — execute(), потом скрипт благополучно умирает, чтобы, запустившись для обработки следующего HTTP запроса, заново выполнять prepare()… Как-то не слишком похоже на оптимизацию. Скорее — наоборот.
Как верно заметили в комментариях, я должен был упомянуть исключения в виде консольных скриптов и демонов, которые долго держат соединение с БД. Однако основная масса PHP скриптов всё же работает на фронтенде, умирая после выполнения пары десятков запросов.
Но неужели нет способа как-то закэшировать подготовленный запрос между запусками?
Рассказывая в своей статье о типичных заблуждениях, связанных с защитой от SQL инъекций, среди прочих я отметил тот факт, что серверные подготовленные выражения не работают в PHP по заявленному эффективному сценарию — 1 раз prepare(), потом 1000 раз executе().
Ну, то есть, в теории-то они работают — в пределах одного запуска скрипта. Но много ли вы знаете скриптов (написанных профессиональными программистами), которые выполняют кучу одинаковых запросов? Вот я тоже не знаю. Повторяющихся запросов (каких-нибудь множественных апдейтов) — доли процента, а в массе своей запросы уникальные (в пределах одного скрипта).
Соответственно, для нашего уникального запроса сначала выполняется prepare(), потом — execute(), потом скрипт благополучно умирает, чтобы, запустившись для обработки следующего HTTP запроса, заново выполнять prepare()… Как-то не слишком похоже на оптимизацию. Скорее — наоборот.
Как верно заметили в комментариях, я должен был упомянуть исключения в виде консольных скриптов и демонов, которые долго держат соединение с БД. Однако основная масса PHP скриптов всё же работает на фронтенде, умирая после выполнения пары десятков запросов.
Но неужели нет способа как-то закэшировать подготовленный запрос между запусками?

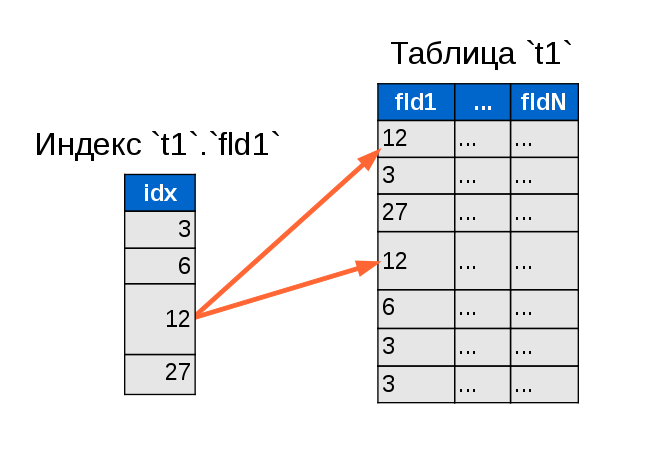
 В нашей прошлой статье —
В нашей прошлой статье — 
 Конечно, в одной статье (и даже не в одной) невозможно описать универсальный «рецепт», который бы подошел абсолютно для всех проектов: для кого-то важнее производительность (иногда — даже в ущерб надежности), для кого-то — наоборот, отказоустойчивость превыше всего, где-то много маленьких таблиц, где-то — большой объем данных…
Конечно, в одной статье (и даже не в одной) невозможно описать универсальный «рецепт», который бы подошел абсолютно для всех проектов: для кого-то важнее производительность (иногда — даже в ущерб надежности), для кого-то — наоборот, отказоустойчивость превыше всего, где-то много маленьких таблиц, где-то — большой объем данных…
 Наверное всем известно, что Django является одним из самых популярных фреймворков для web-разработки на python-е. И даже если в основе web-проекта лежит сторонний код, то зачастую при разработке используют отдельные части этого фреймворка — например ORM. В данной статье я хотел бы рассказать об особенностях использования Django ORM при работе с базой данных MySQL, а именно про транзакции и подводные камни, связанные с ними. Так, например, если в какой-то момент вы осознаёте, что вместо ожидаемых данных, возвращается совершенно другой результат, то возможно, данная статья поможет разобраться что к чему.
Наверное всем известно, что Django является одним из самых популярных фреймворков для web-разработки на python-е. И даже если в основе web-проекта лежит сторонний код, то зачастую при разработке используют отдельные части этого фреймворка — например ORM. В данной статье я хотел бы рассказать об особенностях использования Django ORM при работе с базой данных MySQL, а именно про транзакции и подводные камни, связанные с ними. Так, например, если в какой-то момент вы осознаёте, что вместо ожидаемых данных, возвращается совершенно другой результат, то возможно, данная статья поможет разобраться что к чему.