
SQL HowTo: рисуем морозные узоры на SQL
2 мин

Немного SQL-магии под катом: математика, рекурсия, псевдографика.
Заодно вспоминаем под Новый год формулу угла между векторами:

Довольно типичная схема при разработке системы, когда основная логика обработки сосредоточена в приложении (в нашем случае Erlang), а данные для работы этого приложения (настройки, профили пользователей и т. д.) в базе данных (PostgreSQL). Приложение Erlang кэширует настройки в ETS для ускорения обработки и снижения нагрузки на БД путём отказа от постоянных запросов. При этом изменение этих данных происходит через отдельный (возможно, внешний) сервис.
В таких ситуациях встаёт задача поддержания закэшированных данных в актуальном состоянии. Есть разные подходы для решения этой задачи. Один из них — это логическая репликация PostgreSQL. О нем и пойдёт речь ниже.
Так уж вышло, что на момент постановки задачи я не обладал достаточной степенью опытности, чтобы разработать и запустить это решение в одиночку. И тогда я начал гуглить.
Не знаю, в чем загвоздка, но уже в который раз я сталкиваюсь с тем, что даже если делать все пошагово как в туториале, подготовить такой же enviroment как у автора, то все равно никогда ничего не работает. Понятия не имею, в чем тут дело, но когда я столкнулся с этим в очередной раз, я решил — а напишу-ка я свой туториал, когда все получится. Тот, который точно будет работать.





Для организации обработки потока задач используются очереди. Они нужны для накопления и распределения задач по исполнителям. Также очереди могут обеспечивать дополнительные требования к обработке задач: гарантия доставки, гарантия однократного исполнения, приоритезация и т. д.
Как правило, используются готовые системы очередей сообщений (MQ — message queue), но иногда нужно организовать ad hoc очередь или какую-нибудь специализированную (например, очередь с приоритетом и отложенным перезапуском не обработанных из-за исключений задач). О создании таких очередей и пойдёт речь ниже.
Предлагаемые решения предназначены для обработки потока однотипных задач. Они не подходят для организации pub/sub или обмена сообщениями между слабо связанными системами и компонентами.
Очередь поверх реляционной БД хорошо работает при малых и средних нагрузках (сотни тысяч задач в сутки, десятки-сотни исполнителей), но для больших потоков лучше использовать специализированное решение.
select ... for update skip locked
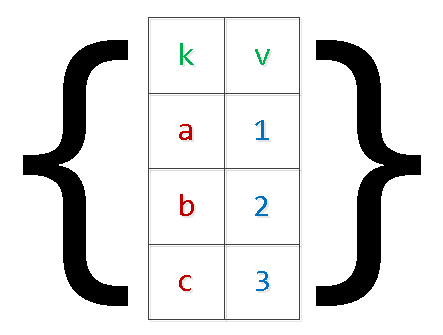
Добрый день, читатели habr!
В первой заметке о posgres_exporter, я рассмотрел достаточно частный случай, при работе с новой, на тот момент фитчей, а именно возможностью мониторинга одним экспортером набора экземпляров и/или баз данных. И описал тот "букет" проблем с которыми при этом столкнулся и какие обходные решения применял, что бы это всё заработало.
И вот, 25 ноября, вышел очередной релиз postgres_exporter 0.8.0. В нём были решены проблемы описанные в предыдущей заметке, а также, что особо приятно, добавлен новый функционал.
Прошу под кат...
Как построить бизнес в России на основе открытого ПО?
Рассказывает Олег Бартунов — сооснователь и CEO Postgres Professional, профессиональный астроном.
Поговорили немного об астрономии в России, кто такой астроном и чем он занимается, про интеграцию IT-технологий и науки, о том, как выиграть в конкурсе деньги и не получить их от государства, что такое СУБДстроение, и о том, как они с Крюковым и Лысаковым Rambler делали на базе Астронета.

