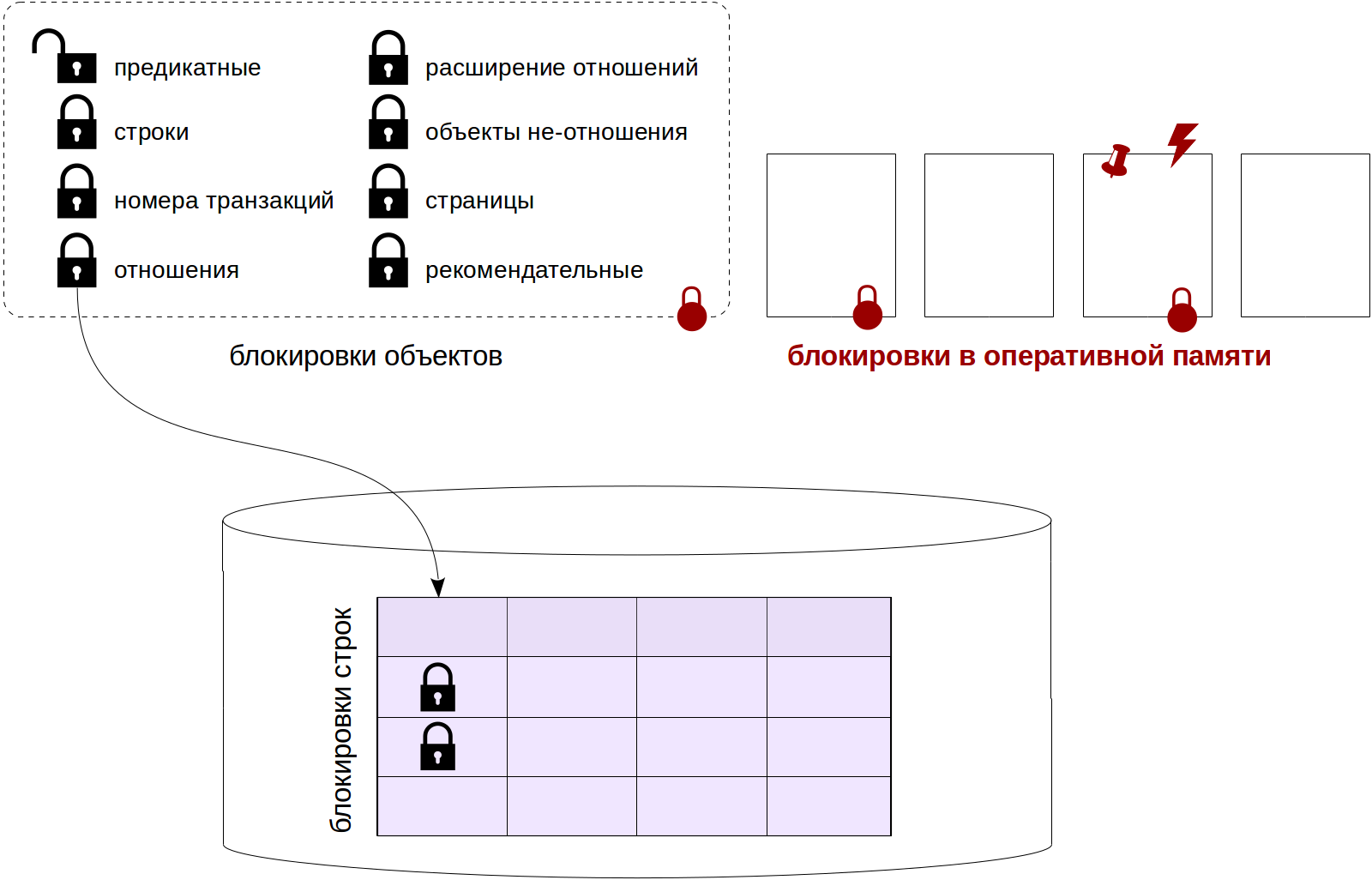
2 лайфхака: альтернативы классическому поиску в Microsoft SQL Server
12 мин
Привет, Хабр! Наши друзья из Softpoint подготовили интересную статью про Microsoft SQL Server. В ней разбирается два практических примера использования полнотекстового поиска:
Присоединяйтесь!

- Поиск по «бесконечным» строкам (напр., Комментарии) в противовес обычному поиску через LIKE;
- Поиск по номерам документов с префиксами. Там, где обычно полнотекстовый поиск применять нельзя: ему мешают постоянные префиксы. Разбирается 2 подхода: предварительная обработка номера документа и добавление собственной библиотеки-word breaker’а.
Присоединяйтесь!




 Зная, что антипаттерны не статичны и эволюционируют по мере того, как вы растете как разработчик SQL, и тот факт, что есть много, что нужно учитывать, когда вы задумываетесь об альтернативах, также означает, что избежать антипаттернов и переписывания запросов может быть довольно сложной задачей. Любая помощь может пригодиться, и именно поэтому более структурированный подход к оптимизации запроса с помощью некоторых инструментов может быть наиболее эффективным.
Зная, что антипаттерны не статичны и эволюционируют по мере того, как вы растете как разработчик SQL, и тот факт, что есть много, что нужно учитывать, когда вы задумываетесь об альтернативах, также означает, что избежать антипаттернов и переписывания запросов может быть довольно сложной задачей. Любая помощь может пригодиться, и именно поэтому более структурированный подход к оптимизации запроса с помощью некоторых инструментов может быть наиболее эффективным.