Как часто, программируя очередную бизнес-фичу, вы ловили себя на мысли: есть же на Земле люди, которые пишут базы данных, распознают лица на фотографиях, делают фреймворки и реализуют интересные алгоритмы. Почему в моей работе всё сводится к перекладыванию из одной таблицы БД в другую, вызову http-сервисов, верстке html-формы и прочей «бизнес-лапше»? Может быть я занимаюсь чем-то не тем или работаю не в той компании?
Хорошая новость в том, что интересные задачи окружают нас повсюду. Сильное желание и смелость творят чудеса на пути к цели — задача любого масштаба станет вам под силу, стоит просто начать её делать.
Недавно мы написали синтаксический анализатор языка запросов 1С и его транслятор в обычный SQL. Это позволило нам выполнять запросы к 1С без участия 1С :) Минимальная рабочая версия на regexp-ах получилась недели за две. Ещё месяц ушёл на полноценный парсер через грамматики, разгребание нюансов структуры БД разных 1С-объектов и реализацию специфических операторов и функций. В результате решение поддерживает практически все конструкции языка, исходный код выложен на
GitHub.
Под катом мы расскажем, зачем нам это понадобилось, как удалось, а так же затронем несколько интересных технических подробностей.






 В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров. 

 Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.
Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.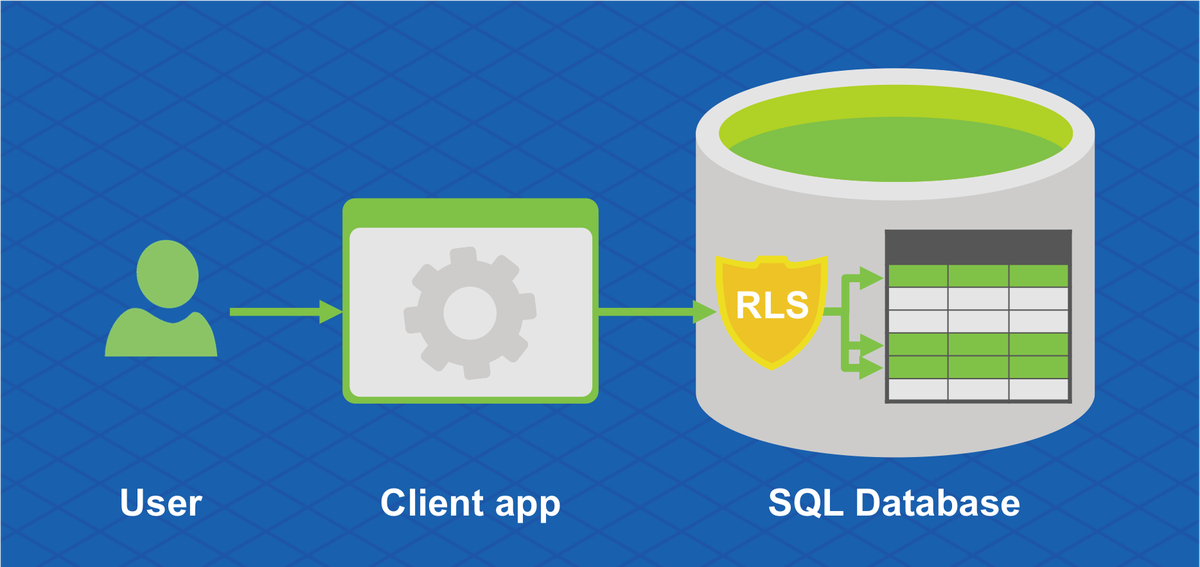
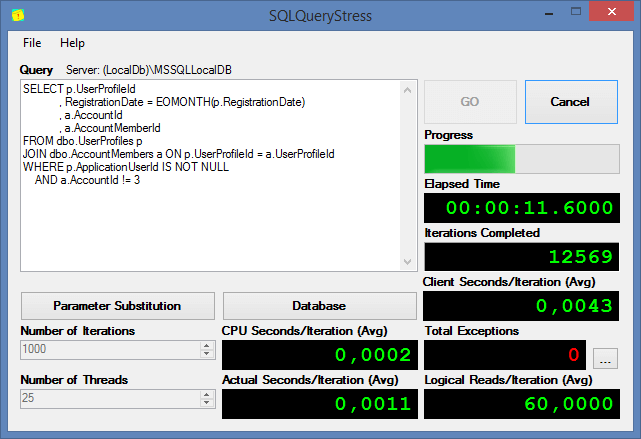
 При проектировании достаточно объёмных реляционных баз данных часто принимается решение об отступлении от
При проектировании достаточно объёмных реляционных баз данных часто принимается решение об отступлении от 


