На протяжении десятилетий покер был сложной и важной проблемой в области искусственного интеллекта. Игра включает в себя скрытую информацию — вы не знаете карты ваших оппонентов — поэтому успех требует применения нескольких стратегий. Каждый игрок корректирует поведение исходя из своего представления о том, что ожидает противник, и исходя из накопленной статистики (если речь об онлайн-покере со вспомогательным статистическим ПО). Ценность действия в игре с неполной информацией зависит от вероятности, с которой оно выбрано, и от вероятности, с которой выбраны другие действия.
Такие нюансы сделали покер устойчивым к методам обучения ИИ, которые добились успеха в других играх. Казалось, компьютеры никогда не смогут успешно играть в покер против людей. Но теперь ясно, что все ошибались.
В последние годы новые методы смогли победить лучших людей в хэдзапе (бот Libratus). А сейчас достигнута ключевая веха: бот Pluribus, разработанный в университете Карнеги — Меллона и Facebook, победил элитных игроков за столом с шестью игроками (научная статья опубликована в Science). Что характерно, самообучение программы проводилось на одном 64-ядерном сервере с 512 ГБ памяти. Это не какие-то корпоративные проекты, где нейросеть обучается на десятках тысяч процессорных ядер. Обучение программы вроде Pluribus может повторить практически любой исследователь.
Несколько замечательных примеров игры Pluribus показаны на видео (к сожалению, оно не встраивается через интерфейс Хабра). В первом примере бот идёт олл-ин (в размере банка) с флэш-дро и дырявым стрит-дро против трёх человек. Имея практически монстр-дро, пожалуй, нельзя назвать это блефом, как сказано в видео.

Во втором примере он выжимает максимум прибыли (вэлью) с топ-парой против оппонента тоже с топ-парой, но младшим кикером. Здесь пример осторожной игры стороны с обеих сторон по всем улицам, так что лучше оценить его на видео.
Наконец, в третьем примере бот успешно вскрывает блеф человека, заколлив с третьей парой олл-ин в четверть банка (см. скриншот ниже), хотя, наверное, это можно назвать не вскрытием блефа, а просто коллом по шансам.

После игры соперники сказали, что бот использовал несколько размеров рейза на префлопе, реализуя нелинейные стратегии. По их словам профессионалов, это немного необычно, потому что отличается от человеческой игры. Крис Фергюсон, участник эксперимента и чемпион WSOP 2000 года, упомянул тонкие ставки на ривере и способность бота грамотно выжимать прибыль.
Кроме Фергюсона, в пул противников бота входили Грег Мерсон (чемпион WSOP 2012 года), Даррен Элиас (четырёхкратный чемпион World Poker Tour), Джимми Чоу, Сет Дэвис, Майкл Гальяно, Энтони Грегг, Донг Ким, Джейсон Лес, Линус Лоэлигер, Даниэль Маколей, Ник Петранджело, Шон Руан, Тревор Сэвидж и Джейк Тул. Каждый из них за свою карьеру выиграл более $1 млн, а многие более $10 млн.
Может быть, примеры на видео и не показательные, но факт в том, что на дистанции в 10 000 рук против пяти оппонентов-профессионалов Pluribus зафиксировал прибыль в размере примерно 5 bb/100 рук. Поскольку игра велась с блайндами $50/100, это соответствует примерно 5 долларам за каждую руку.
Общее количество 10 000 сыгранных рук не очень велико, но для вычисления более объективной статистики исследователи применили версию алгоритма уменьшения дисперсии AIVAT. Например, если бот получает действительно сильную руку, AIVAT вычитает базовое значение из общей оценки. Такая корректировка позволяет показать статистически значимый результат с примерно в 10 раз меньшим количеством рук, чем обычно требуется.
Pluribus тестировали за столом на шесть человек, то есть в самом популярном виде NL Holdem. Но игра шла не на настоящие деньги. Хотя игроки-люди получали вознаграждение за хороший результат по итогам всего эксперимента, но проиграть свои собственные деньги они не имели возможности. Да и вознаграждение $50 тыс. на всех по меркам их лимитов можно считать смехотворным. В принципе, такие тепличные условия влияют на манеру игры.
Тест проходил в двух форматах:
С показателем 5 bb/100 рук это первый случай в истории, когда AI-бот победил лучших профессионалов в любой крупной контрольной игре с участием более двух игроков (или двух команд).
Pluribus добился такого успеха благодаря нескольким инновациям по сравнению с Libratus, новым алгоритмам и коду, разработанным в исследовательской лаборатории университета Карнеги — Меллона Туомаса Сандхолма.
Эти нововведения имеют важное значение не только для покера. Взаимодействия двух игроков с нулевой суммой (в которых один игрок выигрывает, а другой проигрывает) на самом деле распространены только в играх, но очень редки в реальной жизни. Реальные же сценарии — решение проблем кибербезопасности, управление онлайн-аукционами или навигация в автомобильном трафике — обычно включают несколько участников и/или скрытую информацию. Полученные результаты показывают, что тщательно построенный алгоритм ИИ может достичь сверхчеловеческой производительности не только на примере двух игроков с нулевой суммой.
В прошлые годы достижения ИИ ограничивались только играми с двумя игроками или двумя командами в соревновании с нулевой суммой (например, шашки, шахматы, го, покер с двумя игроками, StarCraft 2 и Dota 2). В каждом из этих случаев ИИ был успешен, потому что пытался вывести своего рода стратегию, известную как равновесие Нэша. В играх с двумя игроками и двумя командами с нулевой суммой точное равновесие Нэша не позволяет проиграть независимо от того, что делает противник (например, стратегия равновесия Нэша для игры «камень-ножницы-бумага» заключается в случайном выборе камня, бумаги или ножниц с равной вероятностью).
Хотя равновесие Нэша гарантированно существует в любой конечной игре, обычно невозможно эффективно вычислить его в игре с тремя и более игроками. Более того, в игре с более чем двумя игроками можно проиграть даже при точной стратегии равновесия Нэша, объясняют разработчики в блоге Facebook AI. Одним из таких примеров является игра Lemonade Stand, в которой каждый игрок одновременно выбирает точку на кольце и хочет быть как можно дальше от любого другого игрока. Равновесие Нэша для всех игроков должно представлять собой равноудалённое положение вдоль кольца, но этого можно достичь бесконечным количеством способов. Если каждый игрок независимо вычисляет одно из этих равновесий, то их одновременные действия вряд ли приведут к тому, что все игроки будут расположены одинаково далеко друг от друга.

Недостатки равновесия Нэша за пределами игр с нулевой суммой для двух игроков подняли вопрос в научном сообществе, какая должна быть правильная цель хотя бы в таких играх. Разработчики Pluribus решили, что целью должна быть не конкретная концепция теоретико-игрового решения, а скорее создание ИИ, который эмпирически побеждает человеческих противников в долгосрочной перспективе, включая элитных профессионалов (собственно, это обычно и считается «сверхчеловеческой» производительностью для ботов).
Использованные алгоритмы не гарантированно сходятся к равновесию Нэша. Тем не менее, Pluribus демонстрирует стратегию, которая последовательно побеждает профессионалов за столом с шестью игроками.
Предыдущие покерные боты вроде Libratus работали с неполной информацией в играх, комбинируя теоретически обоснованные алгоритмы самостоятельной игры, основанные на алгоритме минимизации контрфактических сожалений (Counterfactual Regret Minimization, CFR), с тщательно построенной процедурой поиска для игр с неполной информацией. Они работали в играх против одного противника. Но добавление дополнительных игроков увеличивает сложность в геометрической прогрессии. Предыдущие методы не могли масштабироваться на покер с шестью игроками даже при увеличении вычислительной мощности компьютера Libratus в 10 000 раз, пишут разработчики. Поэтому в Pluribus реализованы некоторые принципиально новые методы.
Ядро стратегии Pluribus составлено в результате самообучения путём многократной игры на улучшенном варианте итерационного алгоритма минимизации контрфактических сожалений Монте-Карло (Monte Carlo CFR, MCCFR).
На каждой итерации MCCFR назначает одного игрока в качестве «обходчика» (traverser), чья текущая стратегия обновляется на итерации. В начале итерации MCCFR имитирует покерную комбинацию, основанную на текущей стратегии всех игроков (которая изначально полностью случайна). После того, как смоделированная рука завершена, алгоритм рассматривает каждое решение, принятое обходчиком, и исследует, насколько лучше или хуже это было бы сделано, выбрав вместо этого другие доступные действия. Затем ИИ оценивает достоинства каждого гипотетического решения, которое было бы принято после этих других доступных действий, и так далее (см. видео).
Изучение других гипотетических исходов возможно, потому что ИИ играет против своих копий. Чтобы узнать, что бы произошло при другом действии, ему достаточно спросить у себя, что бы он сделал в ответ на это действие.
Далее разница между тем, что обходчик мог получить, и тем, чего фактически достиг на итерации, добавляется к «контрфактическому сожалению» о действии. В конце итерации стратегия обходчика обновляется таким образом, что действия с более высоким контрфактическим сожалением выбираются с более высокой вероятностью.
Поддержание контрфактических сожалений за каждое действие в каждой точке принятия решения в безлимитном холдеме потребовало бы больше байтов, чем существует атомов во Вселенной, пишут разработчики. Поэтому для уменьшения сложности некоторые действия игнорируются, а похожие точки принятия решений объединяются в процессе, называемом абстракцией. После абстрагирования объединённые точки принятия решений рассматриваются как идентичные.
В результате самообучения разработчики выводят ядро стратегии Pluribus, так называемый blueprint. Во время реальной игры Pluribus улучшает эту стратегию, используя свой алгоритм поиска. Но Pluribus не приспосабливает свою стратегию к оппонентам.
На графике показано, как стратегия Pluribus улучшается во время обучения на 64-ядерном процессоре.
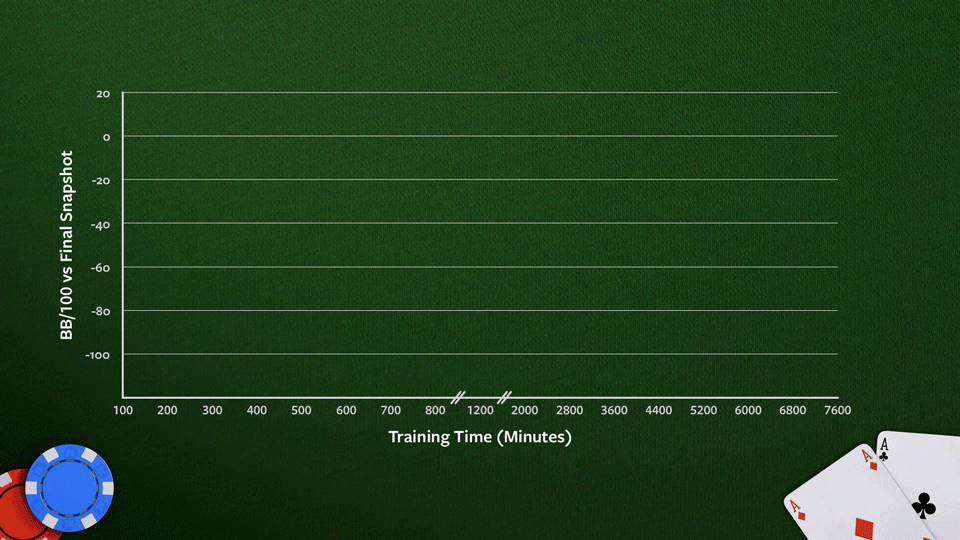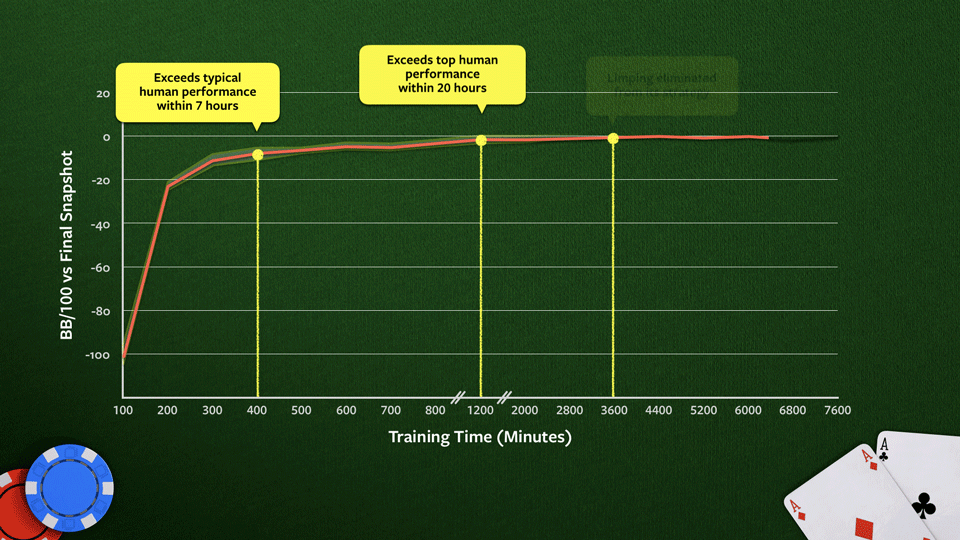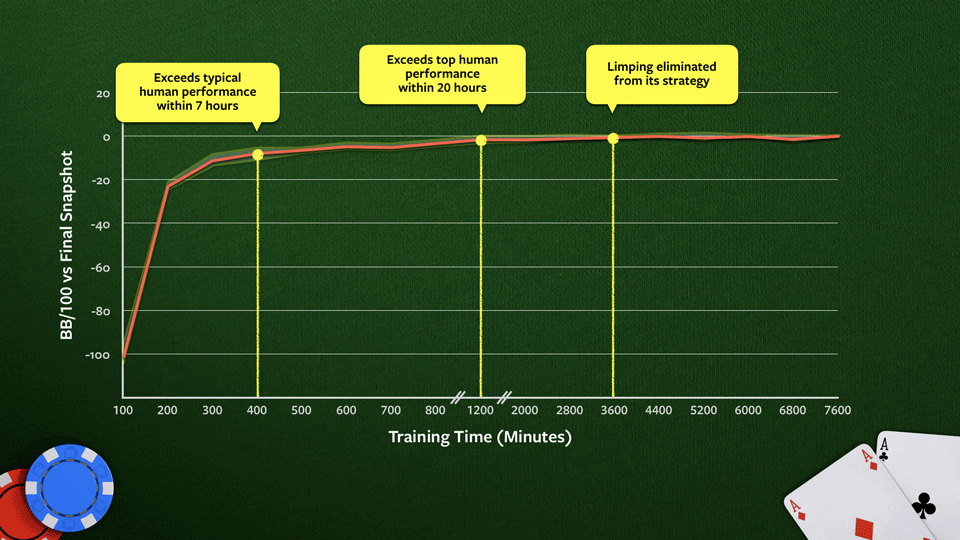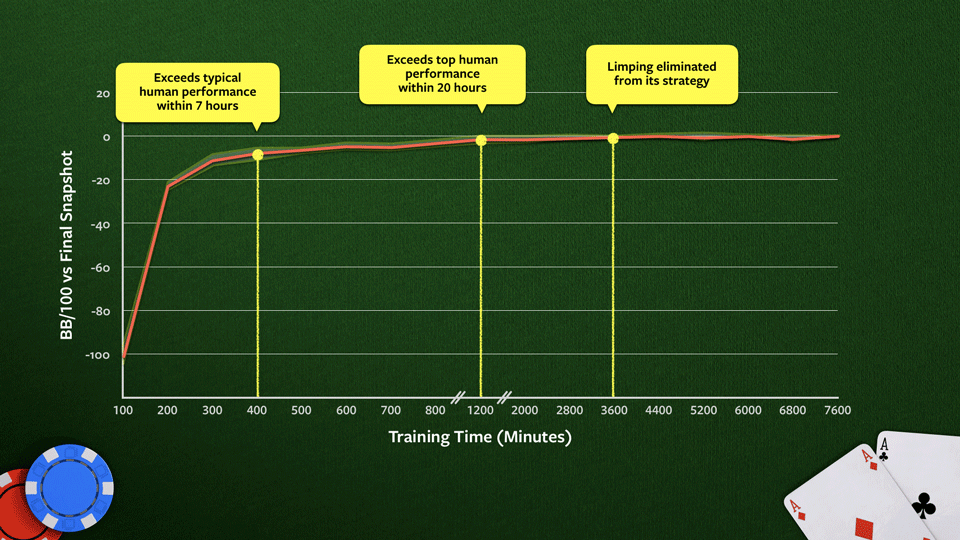
Производительность измеряется по окончательному результату. Здесь ещё не используется поиск. Типичная «человеческая» и «сверхчеловеческая» игра оценивается на основе субъективного мнения игроков-профессионалов. График показывает, что на определённом этапе Pluribus полностью перестаёт лимпить на большом блайнде, чего профессионалы тоже обычно избегают.
Обучение стратегии blueprint заняло восемь дней на 64-ядерном сервере и потребовало менее 512 ГБ оперативной памяти, сообщают исследователи. Графические процессоры не использовались. На обычных тарифах облачных вычислений такое обучение обойдётся менее чем в $150.
Во время реальной игры Pluribus улучшает базовую стратегию, проводя поиск в реальном времени, чтобы определить лучшую и более подробную тактику действий в конкретной ситуации.
AI-боты традиционно используют поиск в реальном времени во многих играх с полной информацией. Например, для определения следующего хода шахматные ИИ обычно смотрят на некоторое количество ходов вперёд, пока не будет достигнут конечный узел на пределе глубины lookahead-алгоритма.
Однако эти методы поиска не работают в играх с неполной информацией, потому что не учитывают способность противников менять стратегию за пределами дерева поиска. Эта приводит алгоритмы к созданию хрупких, несбалансированных стратегий, которые оппоненты могут легко вскрыть. Поэтому раньше AI-боты не могли одолеть покер за столом с шестью игроками.
Вместо этого Pluribus использует подход, в котором поисковый агент явно считает, что любой или все игроки могут изменить стратегию за пределами конечных узлов подигры. Вместо того, чтобы предполагать, что все игроки играют в соответствии с одной фиксированной стратегией (что приводит к тому, что конечные узлы имеют одно фиксированное значение), предполагается, что каждый игрок может выбрать одну из четырёх различных стратегий на оставшуюся часть игры, когда достигнут конечный узел. Вот эти четыре стратегии:
Эта техника позволяет найти более сбалансированную стратегию, которая показывает высокую эффективность на длинной дистанции.
Как отмечалось выше, важная часть игр с неполной информацией — учитывать восприятие самого себя в глазах противника. Если игрок никогда не блефует, его противники всегда сбросят в ответ на большую ставку. Чтобы решить эту проблему, Pluribus постоянно отслеживает вероятность того, что он достиг бы текущей ситуации с каждой возможной рукой в соответствии со своей стратегией. Независимо от имеющихся карт, Pluribus сначала вычислит, как он будет действовать со всеми возможными руками, стараясь сбалансировать свою стратегию во всех руках, чтобы она оставалась непредсказуемой для противника. Как только эта сбалансированная стратегия для всех рук вычислена, Pluribus затем выполняет действие для руки, которую фактически держит.
В реальной игре Pluribus работал на двухпроцессорной машине. Для сравнения, AlphaGo использовал 1920 процессоров и 280 GPU для поиска в реальном времени.
Pluribus также задействовал во время игры менее 128 ГБ памяти. Количество времени для поиска в каждой раздаче варьировалось от 1 до 33 секунд, в зависимости от конкретной ситуации. В среднем Pluribus играет в два раза быстрее, чем обычные человеческие профессионалы: 20 секунд на руку при игре против своих копий за столом с шестью игроками.
На графике центральная линия соответствует реальному винрейту, а две штрихованные линии ограничивают стандартное отклонение.

10 000 рук были сыграны за 12 дней. Каждый день для участия отбирались пять волонтёров из пула профессионалов. В соответствии с показанными результатами между профессионалами делился призовой пул в размере $50 тыс., чтобы сохранить их мотивацию.
Как уже было сказано, по итогам 12-дневной сессии Pluribus показал результат 5 bb/100, что считается очень сильным результатом, особенно против таких профессионалов.
Создатели бота подчёркивают, что не собираются проверять его в «реальном мире». Pluribus создан исключительно для научных исследований в области искусственного интеллекта, а покер выбран только как способ оценки прогресса ИИ в среде с неполной информацией и множеством других агентов.
Методы, которые позволяют Pluribus победить нескольких противников за покерным столом, могут помочь сообществу ИИ разработать эффективные стратегии и в других областях.
Такие нюансы сделали покер устойчивым к методам обучения ИИ, которые добились успеха в других играх. Казалось, компьютеры никогда не смогут успешно играть в покер против людей. Но теперь ясно, что все ошибались.
В последние годы новые методы смогли победить лучших людей в хэдзапе (бот Libratus). А сейчас достигнута ключевая веха: бот Pluribus, разработанный в университете Карнеги — Меллона и Facebook, победил элитных игроков за столом с шестью игроками (научная статья опубликована в Science). Что характерно, самообучение программы проводилось на одном 64-ядерном сервере с 512 ГБ памяти. Это не какие-то корпоративные проекты, где нейросеть обучается на десятках тысяч процессорных ядер. Обучение программы вроде Pluribus может повторить практически любой исследователь.
Несколько замечательных примеров игры Pluribus показаны на видео (к сожалению, оно не встраивается через интерфейс Хабра). В первом примере бот идёт олл-ин (в размере банка) с флэш-дро и дырявым стрит-дро против трёх человек. Имея практически монстр-дро, пожалуй, нельзя назвать это блефом, как сказано в видео.
Во втором примере он выжимает максимум прибыли (вэлью) с топ-парой против оппонента тоже с топ-парой, но младшим кикером. Здесь пример осторожной игры стороны с обеих сторон по всем улицам, так что лучше оценить его на видео.
Наконец, в третьем примере бот успешно вскрывает блеф человека, заколлив с третьей парой олл-ин в четверть банка (см. скриншот ниже), хотя, наверное, это можно назвать не вскрытием блефа, а просто коллом по шансам.
После игры соперники сказали, что бот использовал несколько размеров рейза на префлопе, реализуя нелинейные стратегии. По их словам профессионалов, это немного необычно, потому что отличается от человеческой игры. Крис Фергюсон, участник эксперимента и чемпион WSOP 2000 года, упомянул тонкие ставки на ривере и способность бота грамотно выжимать прибыль.
Кроме Фергюсона, в пул противников бота входили Грег Мерсон (чемпион WSOP 2012 года), Даррен Элиас (четырёхкратный чемпион World Poker Tour), Джимми Чоу, Сет Дэвис, Майкл Гальяно, Энтони Грегг, Донг Ким, Джейсон Лес, Линус Лоэлигер, Даниэль Маколей, Ник Петранджело, Шон Руан, Тревор Сэвидж и Джейк Тул. Каждый из них за свою карьеру выиграл более $1 млн, а многие более $10 млн.
Может быть, примеры на видео и не показательные, но факт в том, что на дистанции в 10 000 рук против пяти оппонентов-профессионалов Pluribus зафиксировал прибыль в размере примерно 5 bb/100 рук. Поскольку игра велась с блайндами $50/100, это соответствует примерно 5 долларам за каждую руку.
Общее количество 10 000 сыгранных рук не очень велико, но для вычисления более объективной статистики исследователи применили версию алгоритма уменьшения дисперсии AIVAT. Например, если бот получает действительно сильную руку, AIVAT вычитает базовое значение из общей оценки. Такая корректировка позволяет показать статистически значимый результат с примерно в 10 раз меньшим количеством рук, чем обычно требуется.
Pluribus тестировали за столом на шесть человек, то есть в самом популярном виде NL Holdem. Но игра шла не на настоящие деньги. Хотя игроки-люди получали вознаграждение за хороший результат по итогам всего эксперимента, но проиграть свои собственные деньги они не имели возможности. Да и вознаграждение $50 тыс. на всех по меркам их лимитов можно считать смехотворным. В принципе, такие тепличные условия влияют на манеру игры.
Тест проходил в двух форматах:
- пять профессионалов + один AI;
- пять AI + один профессионал.
С показателем 5 bb/100 рук это первый случай в истории, когда AI-бот победил лучших профессионалов в любой крупной контрольной игре с участием более двух игроков (или двух команд).
Pluribus добился такого успеха благодаря нескольким инновациям по сравнению с Libratus, новым алгоритмам и коду, разработанным в исследовательской лаборатории университета Карнеги — Меллона Туомаса Сандхолма.
Эти нововведения имеют важное значение не только для покера. Взаимодействия двух игроков с нулевой суммой (в которых один игрок выигрывает, а другой проигрывает) на самом деле распространены только в играх, но очень редки в реальной жизни. Реальные же сценарии — решение проблем кибербезопасности, управление онлайн-аукционами или навигация в автомобильном трафике — обычно включают несколько участников и/или скрытую информацию. Полученные результаты показывают, что тщательно построенный алгоритм ИИ может достичь сверхчеловеческой производительности не только на примере двух игроков с нулевой суммой.
Равновесие Нэша
В прошлые годы достижения ИИ ограничивались только играми с двумя игроками или двумя командами в соревновании с нулевой суммой (например, шашки, шахматы, го, покер с двумя игроками, StarCraft 2 и Dota 2). В каждом из этих случаев ИИ был успешен, потому что пытался вывести своего рода стратегию, известную как равновесие Нэша. В играх с двумя игроками и двумя командами с нулевой суммой точное равновесие Нэша не позволяет проиграть независимо от того, что делает противник (например, стратегия равновесия Нэша для игры «камень-ножницы-бумага» заключается в случайном выборе камня, бумаги или ножниц с равной вероятностью).
Хотя равновесие Нэша гарантированно существует в любой конечной игре, обычно невозможно эффективно вычислить его в игре с тремя и более игроками. Более того, в игре с более чем двумя игроками можно проиграть даже при точной стратегии равновесия Нэша, объясняют разработчики в блоге Facebook AI. Одним из таких примеров является игра Lemonade Stand, в которой каждый игрок одновременно выбирает точку на кольце и хочет быть как можно дальше от любого другого игрока. Равновесие Нэша для всех игроков должно представлять собой равноудалённое положение вдоль кольца, но этого можно достичь бесконечным количеством способов. Если каждый игрок независимо вычисляет одно из этих равновесий, то их одновременные действия вряд ли приведут к тому, что все игроки будут расположены одинаково далеко друг от друга.
Недостатки равновесия Нэша за пределами игр с нулевой суммой для двух игроков подняли вопрос в научном сообществе, какая должна быть правильная цель хотя бы в таких играх. Разработчики Pluribus решили, что целью должна быть не конкретная концепция теоретико-игрового решения, а скорее создание ИИ, который эмпирически побеждает человеческих противников в долгосрочной перспективе, включая элитных профессионалов (собственно, это обычно и считается «сверхчеловеческой» производительностью для ботов).
Использованные алгоритмы не гарантированно сходятся к равновесию Нэша. Тем не менее, Pluribus демонстрирует стратегию, которая последовательно побеждает профессионалов за столом с шестью игроками.
Базовая стратегия
Предыдущие покерные боты вроде Libratus работали с неполной информацией в играх, комбинируя теоретически обоснованные алгоритмы самостоятельной игры, основанные на алгоритме минимизации контрфактических сожалений (Counterfactual Regret Minimization, CFR), с тщательно построенной процедурой поиска для игр с неполной информацией. Они работали в играх против одного противника. Но добавление дополнительных игроков увеличивает сложность в геометрической прогрессии. Предыдущие методы не могли масштабироваться на покер с шестью игроками даже при увеличении вычислительной мощности компьютера Libratus в 10 000 раз, пишут разработчики. Поэтому в Pluribus реализованы некоторые принципиально новые методы.
Ядро стратегии Pluribus составлено в результате самообучения путём многократной игры на улучшенном варианте итерационного алгоритма минимизации контрфактических сожалений Монте-Карло (Monte Carlo CFR, MCCFR).
На каждой итерации MCCFR назначает одного игрока в качестве «обходчика» (traverser), чья текущая стратегия обновляется на итерации. В начале итерации MCCFR имитирует покерную комбинацию, основанную на текущей стратегии всех игроков (которая изначально полностью случайна). После того, как смоделированная рука завершена, алгоритм рассматривает каждое решение, принятое обходчиком, и исследует, насколько лучше или хуже это было бы сделано, выбрав вместо этого другие доступные действия. Затем ИИ оценивает достоинства каждого гипотетического решения, которое было бы принято после этих других доступных действий, и так далее (см. видео).
Изучение других гипотетических исходов возможно, потому что ИИ играет против своих копий. Чтобы узнать, что бы произошло при другом действии, ему достаточно спросить у себя, что бы он сделал в ответ на это действие.
Далее разница между тем, что обходчик мог получить, и тем, чего фактически достиг на итерации, добавляется к «контрфактическому сожалению» о действии. В конце итерации стратегия обходчика обновляется таким образом, что действия с более высоким контрфактическим сожалением выбираются с более высокой вероятностью.
Поддержание контрфактических сожалений за каждое действие в каждой точке принятия решения в безлимитном холдеме потребовало бы больше байтов, чем существует атомов во Вселенной, пишут разработчики. Поэтому для уменьшения сложности некоторые действия игнорируются, а похожие точки принятия решений объединяются в процессе, называемом абстракцией. После абстрагирования объединённые точки принятия решений рассматриваются как идентичные.
В результате самообучения разработчики выводят ядро стратегии Pluribus, так называемый blueprint. Во время реальной игры Pluribus улучшает эту стратегию, используя свой алгоритм поиска. Но Pluribus не приспосабливает свою стратегию к оппонентам.
На графике показано, как стратегия Pluribus улучшается во время обучения на 64-ядерном процессоре.
Производительность измеряется по окончательному результату. Здесь ещё не используется поиск. Типичная «человеческая» и «сверхчеловеческая» игра оценивается на основе субъективного мнения игроков-профессионалов. График показывает, что на определённом этапе Pluribus полностью перестаёт лимпить на большом блайнде, чего профессионалы тоже обычно избегают.
Обучение стратегии blueprint заняло восемь дней на 64-ядерном сервере и потребовало менее 512 ГБ оперативной памяти, сообщают исследователи. Графические процессоры не использовались. На обычных тарифах облачных вычислений такое обучение обойдётся менее чем в $150.
Продвинутая стратегия
Во время реальной игры Pluribus улучшает базовую стратегию, проводя поиск в реальном времени, чтобы определить лучшую и более подробную тактику действий в конкретной ситуации.
AI-боты традиционно используют поиск в реальном времени во многих играх с полной информацией. Например, для определения следующего хода шахматные ИИ обычно смотрят на некоторое количество ходов вперёд, пока не будет достигнут конечный узел на пределе глубины lookahead-алгоритма.
Однако эти методы поиска не работают в играх с неполной информацией, потому что не учитывают способность противников менять стратегию за пределами дерева поиска. Эта приводит алгоритмы к созданию хрупких, несбалансированных стратегий, которые оппоненты могут легко вскрыть. Поэтому раньше AI-боты не могли одолеть покер за столом с шестью игроками.
Вместо этого Pluribus использует подход, в котором поисковый агент явно считает, что любой или все игроки могут изменить стратегию за пределами конечных узлов подигры. Вместо того, чтобы предполагать, что все игроки играют в соответствии с одной фиксированной стратегией (что приводит к тому, что конечные узлы имеют одно фиксированное значение), предполагается, что каждый игрок может выбрать одну из четырёх различных стратегий на оставшуюся часть игры, когда достигнут конечный узел. Вот эти четыре стратегии:
- базовая стратегия Pluribus;
- базовая стратегия со смещением к фолду;
- базовая стратегия со смещением к коллу;
- базовая стратегия со смещением к рейзу.
Эта техника позволяет найти более сбалансированную стратегию, которая показывает высокую эффективность на длинной дистанции.
Как отмечалось выше, важная часть игр с неполной информацией — учитывать восприятие самого себя в глазах противника. Если игрок никогда не блефует, его противники всегда сбросят в ответ на большую ставку. Чтобы решить эту проблему, Pluribus постоянно отслеживает вероятность того, что он достиг бы текущей ситуации с каждой возможной рукой в соответствии со своей стратегией. Независимо от имеющихся карт, Pluribus сначала вычислит, как он будет действовать со всеми возможными руками, стараясь сбалансировать свою стратегию во всех руках, чтобы она оставалась непредсказуемой для противника. Как только эта сбалансированная стратегия для всех рук вычислена, Pluribus затем выполняет действие для руки, которую фактически держит.
Реальная игра
В реальной игре Pluribus работал на двухпроцессорной машине. Для сравнения, AlphaGo использовал 1920 процессоров и 280 GPU для поиска в реальном времени.
Pluribus также задействовал во время игры менее 128 ГБ памяти. Количество времени для поиска в каждой раздаче варьировалось от 1 до 33 секунд, в зависимости от конкретной ситуации. В среднем Pluribus играет в два раза быстрее, чем обычные человеческие профессионалы: 20 секунд на руку при игре против своих копий за столом с шестью игроками.
На графике центральная линия соответствует реальному винрейту, а две штрихованные линии ограничивают стандартное отклонение.
10 000 рук были сыграны за 12 дней. Каждый день для участия отбирались пять волонтёров из пула профессионалов. В соответствии с показанными результатами между профессионалами делился призовой пул в размере $50 тыс., чтобы сохранить их мотивацию.
Как уже было сказано, по итогам 12-дневной сессии Pluribus показал результат 5 bb/100, что считается очень сильным результатом, особенно против таких профессионалов.
Дальнейшая работа
Создатели бота подчёркивают, что не собираются проверять его в «реальном мире». Pluribus создан исключительно для научных исследований в области искусственного интеллекта, а покер выбран только как способ оценки прогресса ИИ в среде с неполной информацией и множеством других агентов.
Методы, которые позволяют Pluribus победить нескольких противников за покерным столом, могут помочь сообществу ИИ разработать эффективные стратегии и в других областях.

