В области распознавания о сигналах часто думают как о продукте умножения, которые действуют статистически. Таким образом, цель анализа таких сигналов – как можно точнее смоделировать статические свойства источников сигналов. Основой такой модели является простое исследование данных и возможная степень ограничения возникающих отклонений. Однако, модель, которая будет определяться, должна не только повторять выработку определенных данных как можно точнее, но и доставлять полезную информацию о некоторых значимых единиц для сегментации сигналов.
Скрытые модели Маркова способны обработать оба вышеуказанных аспекта моделирования. В двухэтапном стохастическом процессе информация для сегментации может быть получена из внутренних состояний модели, в то время как сама генерация сигнала данных происходит на втором этапе.
Большую популярность эта технология моделирования получила в результате успешного применения и дальнейшего развития в области автоматического распознавания речи. Исследования скрытых моделей Маркова превзошли все конкурирующие подходы, и являются доминирующей парадигмой обработки. Их способность описывать процессы или сигналы успешно изучается в течение длительного времени. Причиной этого, в частности, является и то, что технология построения искусственных нейронных сетей, редко применяется для распознавания речи и аналогичных проблем сегментации. Тем не менее, существует ряд гибридных систем состоящих из комбинации скрытых моделей Маркова и искусственных нейронных сетей, в которых используют преимущества обоих методов моделирования (см. раздел 5.8.2).
Скрытые модели Маркова (СММ) описывают двухэтапный стохастический процесс. Первый этап состоит из дискретного стохастического процесса, который является статичным, каузативным и простым. Пространство состояний рассматривается как конечное. Таким образом, процесс вероятностно описывает состояние перехода в дискретность, конечное пространство состояний. Это можно наглядно представить как конечный автомат с перепадами между любыми парами состояний, которые помечены вероятностью перехода. Поведение процесса в данный момент времени t зависит только от непосредственного состояния предшествующего элемента и может быть охарактеризовано следующим образом:

На втором этапе для каждого момента времени t дополнительно, путем вывода или выходных данных, генерируется Ot. Распространение ассоциативной вероятности зависит только от текущего состояния St, а не от каких-либо предыдущих состояний или выводных данных.

Эта последовательность выводных данных единственное, что можно наблюдать в поведении модели. С другой стороны, состояние последовательности принятое во время генерации данных не может быть исследована. Это и есть, так называемая, «скрытость», из которой выводится определение скрытых моделей Маркова. Если посмотреть на модель внешне – то есть понаблюдать за ее поведением – довольно часто встречаются ссылки на последовательность выводных состояний Oi, O2… OT, как на причину наблюдения за последовательностью. Далее отдельные элементы этой последовательности будем называть результатом наблюдения.
В литературе паттерны распознавания поведений СММ всегда рассматриваются на определенном отрезке времени T. Для инициализации модели в начале этого периода используются дополнительные вероятности, чтобы описать вероятность распределения состояний во время t=1. Эквивалентный критерий конечного состояния, как правило, отсутствует. Таким образом, действия модели приходят в конечное состояние, как только будет достигнуто произвольное состояние в момент времени Т. Ни статические, ни декларативные критерии не используются, чтобы более точно отметить окончания состояний.
Тем не менее, скрытые модели Маркова первого порядка, которые обычно обозначают как А, полностью описываются:
• установлением конечного множества состояний {s| 1<s<N}, в литературе, как правило, называют только их индексы,
• состоянием вероятностей переходов, матрицей А
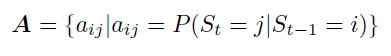
• вектором начала состояний π

• состоянием конкретного распределения вероятностей
 f для вывода моделей
f для вывода моделей
Однако, распределение вывода необходимо различать в зависимости от вида выходных данных во время генерации. В самом простом случае выходные данные генерируются из дискретных распределений вероятности {O1, O2 … OM}, и следовательно, имеют символьный тип. Параметр bj(ok) представляет дискретную вероятность распределения, который может быть сгруппирован в матрицу вероятностей выходных данных:

При таком выборе выходных данных моделирования получаются так называемые дискретные СММ.
Если при наблюдается вектор значений последовательности x e IRn, а не выхода данных распределения описанных на основе непрерывной функции распределения вероятности:

Современное применение СММ для задач анализа сигнала используются исключительно, так называемые, непрерывные СММ, хотя необходимость моделирования непрерывного распределения значительно увеличивает сложность анализа.
Перевод 5 главы (1 пункт)
Gernot A. Fink «Markov Models for Pattern Recognition From Theory to Applications»
Скрытые модели Маркова способны обработать оба вышеуказанных аспекта моделирования. В двухэтапном стохастическом процессе информация для сегментации может быть получена из внутренних состояний модели, в то время как сама генерация сигнала данных происходит на втором этапе.
Большую популярность эта технология моделирования получила в результате успешного применения и дальнейшего развития в области автоматического распознавания речи. Исследования скрытых моделей Маркова превзошли все конкурирующие подходы, и являются доминирующей парадигмой обработки. Их способность описывать процессы или сигналы успешно изучается в течение длительного времени. Причиной этого, в частности, является и то, что технология построения искусственных нейронных сетей, редко применяется для распознавания речи и аналогичных проблем сегментации. Тем не менее, существует ряд гибридных систем состоящих из комбинации скрытых моделей Маркова и искусственных нейронных сетей, в которых используют преимущества обоих методов моделирования (см. раздел 5.8.2).
Определение
Скрытые модели Маркова (СММ) описывают двухэтапный стохастический процесс. Первый этап состоит из дискретного стохастического процесса, который является статичным, каузативным и простым. Пространство состояний рассматривается как конечное. Таким образом, процесс вероятностно описывает состояние перехода в дискретность, конечное пространство состояний. Это можно наглядно представить как конечный автомат с перепадами между любыми парами состояний, которые помечены вероятностью перехода. Поведение процесса в данный момент времени t зависит только от непосредственного состояния предшествующего элемента и может быть охарактеризовано следующим образом:
На втором этапе для каждого момента времени t дополнительно, путем вывода или выходных данных, генерируется Ot. Распространение ассоциативной вероятности зависит только от текущего состояния St, а не от каких-либо предыдущих состояний или выводных данных.
Эта последовательность выводных данных единственное, что можно наблюдать в поведении модели. С другой стороны, состояние последовательности принятое во время генерации данных не может быть исследована. Это и есть, так называемая, «скрытость», из которой выводится определение скрытых моделей Маркова. Если посмотреть на модель внешне – то есть понаблюдать за ее поведением – довольно часто встречаются ссылки на последовательность выводных состояний Oi, O2… OT, как на причину наблюдения за последовательностью. Далее отдельные элементы этой последовательности будем называть результатом наблюдения.
В литературе паттерны распознавания поведений СММ всегда рассматриваются на определенном отрезке времени T. Для инициализации модели в начале этого периода используются дополнительные вероятности, чтобы описать вероятность распределения состояний во время t=1. Эквивалентный критерий конечного состояния, как правило, отсутствует. Таким образом, действия модели приходят в конечное состояние, как только будет достигнуто произвольное состояние в момент времени Т. Ни статические, ни декларативные критерии не используются, чтобы более точно отметить окончания состояний.
Тем не менее, скрытые модели Маркова первого порядка, которые обычно обозначают как А, полностью описываются:
• установлением конечного множества состояний {s| 1<s<N}, в литературе, как правило, называют только их индексы,
• состоянием вероятностей переходов, матрицей А
• вектором начала состояний π
• состоянием конкретного распределения вероятностей
f для вывода моделейОднако, распределение вывода необходимо различать в зависимости от вида выходных данных во время генерации. В самом простом случае выходные данные генерируются из дискретных распределений вероятности {O1, O2 … OM}, и следовательно, имеют символьный тип. Параметр bj(ok) представляет дискретную вероятность распределения, который может быть сгруппирован в матрицу вероятностей выходных данных:
При таком выборе выходных данных моделирования получаются так называемые дискретные СММ.
Если при наблюдается вектор значений последовательности x e IRn, а не выхода данных распределения описанных на основе непрерывной функции распределения вероятности:
Современное применение СММ для задач анализа сигнала используются исключительно, так называемые, непрерывные СММ, хотя необходимость моделирования непрерывного распределения значительно увеличивает сложность анализа.
Перевод 5 главы (1 пункт)
Gernot A. Fink «Markov Models for Pattern Recognition From Theory to Applications»
