
Оптический поток (Optical flow) – технология, использующаяся в различных областях computer vision для определения сдвигов, сегментации, выделения объектов, компрессии видео. Однако если мы захотим его по-быстрому реализовать в своем проекте, прочитав про него на википедии или где-нибудь еще, то, скорее всего, очень быстро наткнемся на то, что он работает очень плохо и сбоит при определении сдвигов уже порядка 1-2 пикселей (по крайней мере так было у меня). Тогда обратимся к готовым реализациям, например, в OpenCV. Там он реализован различными методами и совершенно непонятно, чем аббревиатура PyrLK лучше или хуже обозначения Farneback или чего-нибудь в этом роде, да и придется поразбираться со смыслом параметров, которых в некоторых реализациях очень много. Причем, что интересно, эти алгоритмы как-то работают, в отличие от того, что мы написали сами. В чем же секрет?
Что же такое оптический поток
Оптический поток (ОП) – изображение видимого движения, представляющее собой сдвиг каждой точки между двумя изображениями. По сути, он представляет собой поле скоростей (т. к. сдвиг с точностью до масштаба эквивалентен мгновенной скорости). Суть ОП в том, что для каждой точки изображения
") находится такой сдвиг (dx, dy), чтобы исходной точке соответствовала точка на втором изображении
находится такой сдвиг (dx, dy), чтобы исходной точке соответствовала точка на втором изображении ") . Как определить соответствие точек – отдельный вопрос. Для этого надо взять какую-то функцию точки, которая не изменяется в результате смещения. Обычно считается, что у точки сохраняется интенсивность (т. е. яркость или цвет для цветных изображений), но можно считать одинаковыми точки, у которых сохраняется величина градиента, гессиан, его величина или его определитель, лапласиан, другие характеристики. Очевидно, сохранение интенсивности дает сбои, если меняется освещенность или угол падения света. Тем не менее, если речь идет о видеопотоке, то, скорее всего, между двумя кадрами освещение сильно не изменится, хотя бы потому, что между ними проходит малый промежуток времени. Поэтому часто используют интенсивность в качестве функции, сохраняющейся у точки.
. Как определить соответствие точек – отдельный вопрос. Для этого надо взять какую-то функцию точки, которая не изменяется в результате смещения. Обычно считается, что у точки сохраняется интенсивность (т. е. яркость или цвет для цветных изображений), но можно считать одинаковыми точки, у которых сохраняется величина градиента, гессиан, его величина или его определитель, лапласиан, другие характеристики. Очевидно, сохранение интенсивности дает сбои, если меняется освещенность или угол падения света. Тем не менее, если речь идет о видеопотоке, то, скорее всего, между двумя кадрами освещение сильно не изменится, хотя бы потому, что между ними проходит малый промежуток времени. Поэтому часто используют интенсивность в качестве функции, сохраняющейся у точки.По такому описанию можно перепутать ОП с поиском и сопоставлением характерных точек. Но это разные вещи, суть оптического потока в том, что он не ищет какие-то особенные точки, а по параметрам изображений пытается определить, куда сместилась произвольная точка.
Есть два варианта расчета оптического потока: плотный (dense) и выборочный (sparse). Sparse поток рассчитывает сдвиг отдельных заданных точек (например, точек, выделенных некоторым feature detector'ом), dense поток считает сдвиг всех точек изображения. Естественно, выборочный поток вычисляется быстрее, однако для некоторых алгоритмов разница не такая уж и большая, а для некоторых задач требуется нахождение потока во всех точках изображения.
Для вырожденных случаев можно применять более простые методы определения сдвига. В частности, если все точки изображения имеют один и тот же сдвиг (изображение сдвинуто целиком), то можно применить метод фазовой корреляции: вычислить преобразование Фурье для обоих изображений, найти свертку их фаз и по ней определить сдвиг (см. en.wikipedia.org/wiki/Phase_correlation). Также можно применять поблочное сравнение (block matching): находить сдвиг, минимизирующий норму разности изображений в окне. В чистом виде такой алгоритм будет работать долго и неустойчиво к поворотам и прочим искажениям. Английская википедия причисляет перечисленные алгоритмы к различным вариантам вычисления оптического потока, но мне это кажется не слишком корректным, так как эти алгоритмы могут быть применены и в других целях и не полностью решают данную задачу. Мы будем называть оптическим потоком методы, основанные на локальных характеристиках изображений (то, что в английской википедии называется differential methods).
Стандартный подход (метод Лукаса-Канаде)
Математическое описание алгоритма достаточно подробно приведено в этой статье, но в ней затрагиваются лишь теоретические аспекты.
Рассмотрим математическую модель оптического потока, считая, что у точки в результате смещения не изменилась интенсивность.
Пусть
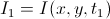 – интенсивность в некоторой точке (x, y) на первом изображении (т. е. в момент времени t). На втором изображении эта точка сдвинулась на (dx, dy), при этом прошло время dt, тогда
– интенсивность в некоторой точке (x, y) на первом изображении (т. е. в момент времени t). На втором изображении эта точка сдвинулась на (dx, dy), при этом прошло время dt, тогда 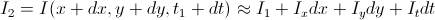 – это мы разложили по Тейлору функцию интенсивности до первого члена (позже будет упомянуто, почему только до первого), здесь
– это мы разложили по Тейлору функцию интенсивности до первого члена (позже будет упомянуто, почему только до первого), здесь  – частные производные по координатам и времени, то есть по сути
– частные производные по координатам и времени, то есть по сути  – изменение яркости в точке (x, y) между двумя кадрами.
– изменение яркости в точке (x, y) между двумя кадрами.Мы считаем, что у точки сохранилась интенсивность, значит

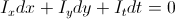
Получаем одно уравнение с двумя неизвестными (dx и dy), значит его недостаточно для решения, то есть только на этом уравнении далеко не уедешь.
Самое простое решение проблемы – алгоритм Лукаса-Канаде. У нас же на изображении объекты размером больше 1 пикселя, значит, скорее всего, в окрестности текущей точки у других точек будут примерно такие же сдвиги. Поэтому мы возьмем окно вокруг этой точки и минимизируем (по МНК) в нем суммарную погрешность с весовыми коэффициентами, распределенными по Гауссу, то есть так, чтобы наибольший вес имели пиксели, ближе всего находящиеся к исследуемому. После простейших преобразований, получаем уже систему из 2 уравнений с 2 неизвестными:
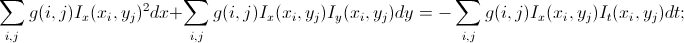
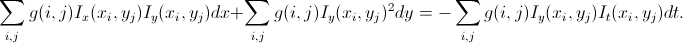
Как известно, эта система имеет единственное решение не всегда (хотя и очень часто): если детерминант системы равен нулю, то решений либо нет, либо бесконечное число. Эта проблема известна как Aperture problem – неоднозначность сдвига при ограниченном поле зрения для периодических картинок. Она соответствует случаю, когда в поле зрения попадает фрагмент изображения, в котором присутствует некоторая цикличность; тут уж и человек не сможет однозначно определить, куда картинка сместилась. Проблема в том, что из-за шумов в таких неоднозначных ситуациях мы получим не нулевой детерминант, а очень маленький, который, скорее всего, приведет к очень большим значениям сдвига, особо не коррелирующим с действительностью. Так что на определенном этапе нужно просто проверять, не является ли детерминант системы достаточно маленьким, и, если что, не рассматривать такие точки или отмечать их как ошибочные.
Почему не работает?
Если мы остановимся на этом этапе и реализуем этот алгоритм, то он будет успешно работать. Но только если сдвиг между соседними изображениями будет очень маленький, порядка 1 пикселя, и то не всегда. (Для анализа качества генерировались синтетические последовательности с различным относительным сдвигом, причем этот сдвиг может выражаться нецелым числом пикселей, тогда результирующее изображение соответствующим образом интерполируется) Уже на сдвиге в 2 пикселя погрешность будет большая, а если 3 и более, то результат будет вообще неадекватным. В чем же дело?
Тут нам устроила подставу математика. Она привила нам ощущение, что все функции вокруг непрерывные и много раз дифференцируемые. И вообще нас в институте приучили приближение функции в окрестности точки записывать с помощью формулы Тейлора, и мы везде
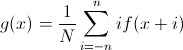 , где
, где 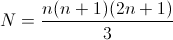 . Если мы строили производную по одной соседней точке с каждой стороны, то нам повезло: в этом случае формула совпадает с формулой приближенного вычисления производных: g(x) = (f(x+1) – f(x-1)) / 2. Что характерно, в OpenCV при вычислении оптического потока Лукаса-Канаде используется именно такая формула, к этому мы еще вернемся потом. А вот если взять больше точек, то формула уже становится совсем не похожа на классические разностные схемы для первой производной.
. Если мы строили производную по одной соседней точке с каждой стороны, то нам повезло: в этом случае формула совпадает с формулой приближенного вычисления производных: g(x) = (f(x+1) – f(x-1)) / 2. Что характерно, в OpenCV при вычислении оптического потока Лукаса-Канаде используется именно такая формула, к этому мы еще вернемся потом. А вот если взять больше точек, то формула уже становится совсем не похожа на классические разностные схемы для первой производной.Очевидно, если мы строим эту функцию, например, по трем окрестным точкам слева и справа от исходной, то она никаким образом не зависит от точек, расположенных дальше, и, соответственно, при сдвиге более трех точек все равно у нас часто будут получаться неадекватные результаты. А еще, чем больше число точек, по которым мы строим эту функцию, тем больше среднее отклонение получаемой линии от используемых точек – опять же из-за того, что у нас не линейно меняющиеся изображения, а черт знает какие. На практике сдвиги более 2 пикселей уже дают неадекватно большую ошибку, сколько бы точек мы ни взяли.
Другим слабым местом алгоритма является то, что мы опять же имеем дело не с гладкими непрерывными функциями, а с произвольными, да еще и дискретными. Поэтому на некоторых фрагментах изображения интенсивность может «скакать» вообще без явных закономерностей, например на границах объектов, или из-за шумов. В этом случае никакая функция g(x) не сможет достаточно точно описать изменения изображения в окрестности точки. Чтобы с этим побороться (хотя бы частично), предлагается исходное изображение размазать, причем полезно будет его размазать достаточно сильно, то есть лучше применять даже не всеми любимый gaussian blur (усреднение с весовыми коэффициентами), а прямо таки box filter (равномерное усреднение по окну), да еще и несколько раз подряд. Гладкость изображения для нас сейчас важнее, чем детализация.
Тем не менее, эти меры так же не спасут нас от ограничения детектируемого сдвига в 2-3 пикселя. И кстати, в OpenCV 1.0 присутствовала такая реализация оптического потока, и работала она только в идеальных условиях на очень маленьких сдвигах.
Что же делать?
Итого, обычный Лукас-Канаде хорошо определяет маленькие сдвиги, такие, в рамках которых картинка похожа на свое линейное приближение. Чтобы с этим побороться, воспользуемся стандартным приемом CV – multi-scaling'ом: построим «пирамиду» изображений разного масштаба (почти всегда берется масштабирование в 2 раза по каждой оси, так проще считать) и пройдем по ним оптическим потоком от меньшего изображения к большему, тогда детектированный маленький сдвиг на маленьком изображении будет соответствовать большому сдвигу на большом изображении. На самом маленьком изображении мы обнаруживаем сдвиг не более 1-2 пикселей, а переходя от меньшего масштаба к большему, мы пользуемся результатом с предыдущего шага и уточняем значения сдвига. Собственно, в OpenCV его и реализует функция calcOptFlowPyrLK. Использование этого пирамидального алгоритма позволяет нам не заморачиваться вычислением линейной аппроксимации по многим точкам: проще взять больше уровней пирамиды, а на каждом уровне брать довольно грубое приближение этой функции. Поэтому в OpenCV и идет расчет всего по двум соседним точкам. И поэтому применительно к этой реализации алгоритма наши умозаключения про преимущество аппроксимирующей функции перед производной оказались бесполезными: для такого количества опорных точек производная и есть лучшая аппроксимирующая функция.
А какие еще бывают?
Этот алгоритм не является единственным вариантом вычисления оптического потока. В OpenCV кроме потока Лукаса-Канаде есть еще поток Farneback и SimpleFlow, также часто ссылаются на алгоритм Horn–Schunck.
Метод Horn–Schunck носит несколько более глобальный характер, чем метод Лукаса-Канаде. Он опирается на предположение о том, что на всем изображении оптический поток будет достаточно гладким. От того же самого уравнения
предлагается перейти к функционалу 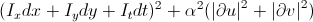 , то есть добавить требование на отсутствие резкого изменения сдвигов с весовым коэффициентом α. Минимизация этого функционала приводит нас к системе из двух уравнений:
, то есть добавить требование на отсутствие резкого изменения сдвигов с весовым коэффициентом α. Минимизация этого функционала приводит нас к системе из двух уравнений: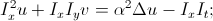
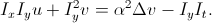
В этих уравнениях лапласиан предлагают посчитать приближенно:
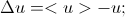 – разница со средним значением. Получаем систему уравнений, которую записываем для каждого пикселя и решаем общую систему итеративно:
– разница со средним значением. Получаем систему уравнений, которую записываем для каждого пикселя и решаем общую систему итеративно: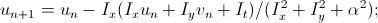
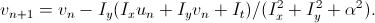
В данном алгоритме тоже предлагают использовать multi-scaling, причем рекомендуют масштабировать изображения не в 2 раза, а с коэффициентом 0.65
Этот алгоритм был реализован в первых версиях OpenCV, но в последствии от него отказались.
Farneback предложил аппроксимировать изменение интенсивности в окрестности с помощью квадратичной формы: I = xAx + bx + c с симметричной матрицей A (по сути, рассматривая разложение по Тейлору до первого члена, мы брали линейную аппроксимацию I = bx + c, то есть сейчас мы как раз решили повысить точность приближения) Если изображение сдвинулось в пределах этой окрестности, то
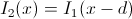 , подставляем в квадратичное разложение, раскрываем скобки, получаем
, подставляем в квадратичное разложение, раскрываем скобки, получаем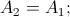
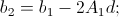
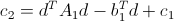 .
.Теперь мы можем вычислить значения A, b, c на обеих картинках, и тогда эта система станет избыточной относительно d (особенно смущает первое уравнение), и вообще d можно получить из второго уравнения:
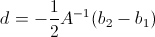 . Приходится прибегать к следующей аппроксимации:
. Приходится прибегать к следующей аппроксимации: 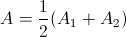 . Обозначим еще для простоты
. Обозначим еще для простоты 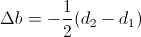 , Тогда получим просто
, Тогда получим просто 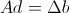 .
. Для компенсации шумов при вычислении, снова обратимся к тому предположению, что в окрестности исследуемой точки у всех точек более или менее одинаковый сдвиг. Поэтому опять же проинтегрируем погрешность
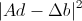 по окну с гауссовскими весовыми коэффициентами w, и найдем вектор d, минимизирующий эту суммарную погрешность. Тогда мы получим оптимальное значение
по окну с гауссовскими весовыми коэффициентами w, и найдем вектор d, минимизирующий эту суммарную погрешность. Тогда мы получим оптимальное значение 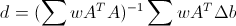 и соответствующую минимальную ошибку
и соответствующую минимальную ошибку 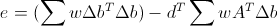 . То есть нам надо для каждой точки посчитать
. То есть нам надо для каждой точки посчитать 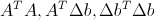 , усреднить по окну, инвертировать матрицу и получить результат. Соответственно эти произведения можно посчитать для всей картинки и использовать заранее рассчитанные значения для разных точек, то есть это как раз тот случай, когда имеет смысл считать dense поток.
, усреднить по окну, инвертировать матрицу и получить результат. Соответственно эти произведения можно посчитать для всей картинки и использовать заранее рассчитанные значения для разных точек, то есть это как раз тот случай, когда имеет смысл считать dense поток.Как обычно, у этого алгоритма есть некоторое количество модификаций и усовершенствований, в первую очередь позволяющих использовать известную априорную информацию – заданную начальную аппроксимацию потока – и, опять же, multi-scaling.
В основе метода SimpleFlow лежит следующая идея: если мы все равно не умеем определять сдвиг больше чем размер окна, по которому мы искали производные, то зачем вообще заморачиваться с вычислением производных? Давайте просто в окне найдем наиболее похожую точку! А для разрешения неоднозначностей и для компенсации шумов учтем, что поток непрерывный и в окрестности данной точки все точки имеют почти одинаковый сдвиг. А проблему с размером окна опять же решим за счет multi-scaling'а.
Более строго, алгоритм звучит так: для всех точек в окне находится функция «энергии», отвечающая (с обратной логарифмической зависимостью) за вероятность перехода исходной точки в эту точку:
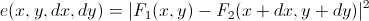 . Далее, считается свертка этой энергии с гауссовым окном
. Далее, считается свертка этой энергии с гауссовым окном 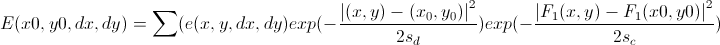 и находятся значения (dx,dy), минимизирующие эту функцию. Чтобы получить субпиксельную точность, рассматривается малая окрестность найденной оптимальной точки (dx,dy) и в ней ищется пик функции энергии как пик параболоида. И, как было упомянуто выше, эта процедура выполняется для пирамиды масштабированных изображений. Еще у них в алгоритме предложены хитрые методы ускорения расчетов, но это уже кому интересно разберутся сами. Для нас же важно, что за счет этого данный алгоритм является (теоретически) достаточно быстрым при неплохой точности. И у него нет такой проблемы, как у предыдущих, что чем больше сдвиг, тем хуже он детектируется.
и находятся значения (dx,dy), минимизирующие эту функцию. Чтобы получить субпиксельную точность, рассматривается малая окрестность найденной оптимальной точки (dx,dy) и в ней ищется пик функции энергии как пик параболоида. И, как было упомянуто выше, эта процедура выполняется для пирамиды масштабированных изображений. Еще у них в алгоритме предложены хитрые методы ускорения расчетов, но это уже кому интересно разберутся сами. Для нас же важно, что за счет этого данный алгоритм является (теоретически) достаточно быстрым при неплохой точности. И у него нет такой проблемы, как у предыдущих, что чем больше сдвиг, тем хуже он детектируется. А если брать не интенсивность?
Выше было сказано, что соответствие между точками может определяться разными величинами, так почему же мы рассматриваем только интенсивность? А потому, что любую другую величину можно свести к ней: мы просто фильтруем изображения соответствующим фильтром и на вход описанных выше алгоритмов подаем отфильтрованные изображения. Соответственно, если вы хотите использовать оптический поток, то сначала подумайте, в ваших условиях какая характеристика изображения будет наиболее стабильной, и проведите соответствующую фильтрацию, чтобы на входе алгоритма оказалась не интенсивность, а эта характеристика.
Практика
Давайте опробуем на практике алгоритмы, которые нам предлагает OpenCV.
Здесь можно проводить множество различных исследований каждого алгоритма, варьируя параметры, изменяя входные последовательности – с разными сдвигами, поворотами, проективными преобразованиями, сегментами, с разными шумами и т. д. Это все заняло бы уйму времени и по размеру отчета превзошло бы настоящую статью, поэтому здесь предлагаю ограничиться простым случаем параллельного сдвига изображения на фиксированное расстояние и наложение небольших шумов. Это позволит понять в общих чертах, как запускать алгоритмы и кто из них круче.
Подробно синтаксис процедур описан на странице с мануалом, здесь я приведу выжимку-перевод с моими комментариями.
Классический Лукас-Канаде реализован с пирамидой в процедуре calcOpticalFlowPyrLK. Алгоритм рассчитывает sparse-поток, то есть для заданного набора точек на первом изображении оценивает их положение на втором. Входные параметры достаточно очевидны: два входных изображения, входной и выходной наборы точек, status – выходной вектор, показывающий, найдена ли успешно соответствующая точка, err – выходной вектор оцененных погрешностей соответствующих точек, WinSize – размер окна, по которому происходит гауссово усреднение, я брал 21х21 и работало хорошо, maxLevel – количество слоев в пирамиде минус один, т. е. номер последнего слоя, я брал 5, criteria – условие выхода из итеративного процесса определения сдвига (минимизация погрешности производится итеративно) – этот параметр я оставлял по умолчанию, flags – дополнительные флаги, например можно использовать начальное приближение потока или выбрать метод оценки погрешности, minEigThreshold – пороговое значение градиента, ниже которого матрица считается вырожденной, я оставлял по умолчанию. Начиная с OpenCV 2.4.1, при вычислении потока можно использовать заранее вычисленную пирамиду отмасштабированных изображений.
Результат работы – успешно и стабильно обнаруживаются как малые, так и большие сдвиги, устойчив к довольно большим шумам, время работы – порядка 10 мс для 400 точек c 5-слойной пирамидой (на core i7 950).
Кстати, этот алгоритм реализован так же на Gpu (CUDA), причем как dense, так и sparse версии.
Поток Farneback реализуется процедурой calcOpticalFlowFarneback, рассчитывается dense-поток, то есть сдвиг каждой точки. Параметры: входные изображения, выходной поток в формате двухканальной матрицы float'ов, pyr_scale определяет отношение масштабов между слоями пирамиды, levels – количество уровней в пирамиде, winsize – размер окна, по которому производится усреднение, iterations – количество итераций на каждом уровне, poly_n – размер полинома, по которому оцениваются значения A и b, poly_sigma – сигма гауссовского размытия при сглаживании производных, рекомендованные значения параметров указаны в мануале, flags – дополнительные флаги, например можно использовать начальное приближение потока или по-другому усреднять по окну.
Этот алгоритм куда менее стабилен (по моим наблюдениям), легче промахивается на довольно равномерных картинках (видимо, проблема в отсутствии фильтрации неудачных точек), плохо определяет большие сдвиги. У меня отрабатывал за 600 мс на изображении 512х512.
Поток SimpleFlow реализует процедура calcOpticalFlowSF (рассчитывается опять же dense поток), и у нее есть множество загадочных параметров без дефолтных значений, и вообще на данный момент на странице информация предоставлена весьма лаконично. Попробуем разобраться. Первые 3 – входные изображения и выходное двухканальное; layers – количество слоев в пирамиде, то есть сколько раз масштабируем исходное изображение; averaging_block_size – размер окна, в котором мы считали функцию энергии пикселей; max_flow – максимальный сдвиг, который мы хотим уметь определять на каждом шаге, по сути он определяется размером окна (хотя не совсем понятно, почему он int). На этом можно остановиться, а можно задать еще несколько параметров, смысл некоторых из них от меня ускользает.
На сайте предлагают посмотреть пример его использования, в котором он запускается с такими параметрами: calcOpticalFlowSF(frame1, frame2, flow, 3, 2, 4, 4.1, 25.5, 18, 55.0, 25.5, 0.35, 18, 55.0, 25.5, 10);
У меня алгоритм работает значительно медленнее других, порядка 9-12 секунд на картинку 512х512. Результат работы кажется более правдоподобным, чем Farneback, по крайней мере лучше определяется сдвиг на равномерных картинках, заметно лучше срабатывает с большими сдвигами.
Выводы
Если вы хотите использовать где-то оптический поток, сначала подумайте, нужен ли он вам: часто можно обойтись более простыми методами. Браться реализовывать поток самостоятельно стоит только несколько раз подумав: каждый алгоритм имеет множество хитростей, тонкостей и оптимизаций; что бы вы ни сделали, скорее всего, в OpenCV оно же работает лучше (естественно, при условии, что оно там есть). Тем более что они там вовсю используют логические и хардварные оптимизации типа использования SSE инструкций, многопоточность, возможности вычисления с CUDA или OpenCL и т. д. Если вам достаточно посчитать сдвиг некоторого набора точек (т. е. sparse поток), то можете смело использовать функцию calcOpticalFlowPyrLK, оно работает хорошо, надежно и достаточно быстро. Для вычисления dense-потока хорошо использовать функцию calcOpticalFlowSF, но она работает очень медленно. Если быстродействие критично, то calcOpticalFlowFarneback, но надо еще удостовериться, что результаты его работы вас устроят.
Литература
docs.opencv.org/modules/video/doc/motion_analysis_and_object_tracking.html
Pyramidal Implementation of the Lucas Kanade Feature Tracker. Description of the algorithm — Jean-Yves Bouguet
Two-Frame Motion Estimation Based on Polynomial Expansion — Gunnar Farneback
SimpleFlow: A Non-iterative, Sublinear Optical Flow Algorithm — Michael Tao, Jiamin Bai, Pushmeet Kohli, and Sylvain Paris
Horn-Schunck Optical Flow with a Multi-Scale Strategy — Enric Meinhardt-Llopis, Javier Sanchez
en.wikipedia.org/wiki/Optical_flow

