Не так давно товарищ Makeman описывал, как с помощью спектрального анализа можно разложить некоторый звуковой сигнал на слагающие его ноты. Давайте немного абстрагируемся от звука и положим, что у нас есть некоторый оцифрованный сигнал, спектральный состав которого мы хотим определить, и достаточно точно.
Под катом краткий обзор метода выделения гармоник из произвольного сигнала с помощью цифрового гетеродинирования, и немного особой, Фурье-магии.
Итак, что имеем.
Файл с отсчетами оцифрованного сигнала. Известно, что сигнал представляет собой сумму синусоид со своими частотами, амплитудами и начальными фазами, и, возможно, белый шум.
Что будем делать.
Использовать спектральный анализ для того, чтобы определить:
- количество гармоник в составе сигнала, а для каждой: амплитуду, частоту (далее в контексте числа длин волн на длину сигнала), начальную фазу;
- наличие/отсутствие белого шума, а при наличии, его СКО (среднеквадратическое отклонение);
- наличие/отсутствие постоянной составляющей сигнала;
- всё это оформить в красивенький PDF отчёт
с блэкджеком ииллюстрациями.
Будем решать данную задачу на Java.
Матчасть
Как я уже говорил, структура сигнала заведомо известна: это сумма синусоид и какая-то шумовая составляющая. Так сложилось, что для анализа периодических сигналов в инженерной практике широко используют мощный математический аппарат, именуемый в общем «Фурье-анализ». Давайте кратенько разберём, что же это за зверь такой.
Немного особой, Фурье-магии
Не так давно, в 19 веке, французский математик Жан Батист Жозеф Фурье показал, что любую функцию, удовлетворяющую некоторым условиям (непрерывность во времени, периодичность, удовлетворение условиям Дирихле) можно разложить в ряд, который в дальнейшем получил его имя — ряд Фурье.
В инженерной практике разложение периодических функций в ряд Фурье широко используется, например, в задачах теории цепей: несинусоидальное входное воздействие раскладывают на сумму синусоидальных и рассчитывают необходимые параметры цепей, например, по методу наложения.
Существует несколько возможных вариантов записи коэффициентов ряда Фурье, нам же лишь необходимо знать суть.
Разложение в ряд Фурье позволяет разложить непрерывную функцию в сумму других непрерывных функций. И в общем случае, ряд будет иметь бесконечное количество членов.
Дальнейшим усовершенствованием подхода Фурье является интегральное преобразование его же имени. Преобразование Фурье.
В отличие от ряда Фурье, преобразование Фурье раскладывает функцию не по дискретным частотам (набор частот ряда Фурье, по которым происходит разложение, вообще говоря, дискретный), а по непрерывным.
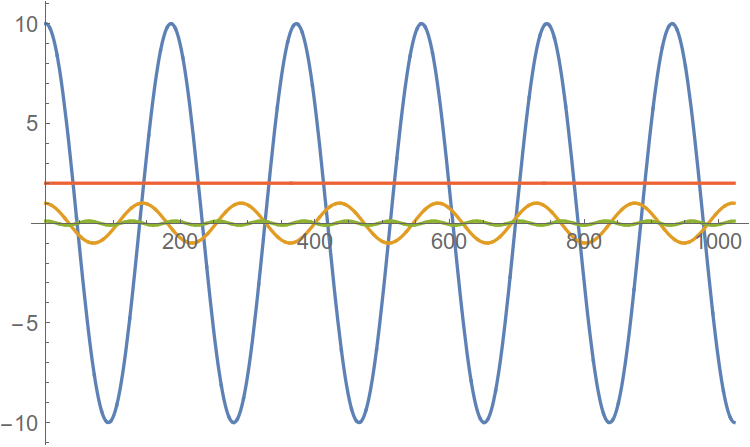
Давайте взглянем на то, как соотносятся коэффициенты ряда Фурье и результат преобразования Фурье, именуемый, собственно, спектром.
Небольшое отступление: спектр преобразования Фурье — в общем случае, функция комплексная, описывающая комплексные амплитуды соответствующих гармоник. Т.е., значения спектра — это комплексные числа, чьи модули являются амплитудами соответствующих частот, а аргументы — соответствующими начальными фазами. На практике, рассматривают отдельно амплитудный спектр и фазовый спектр.
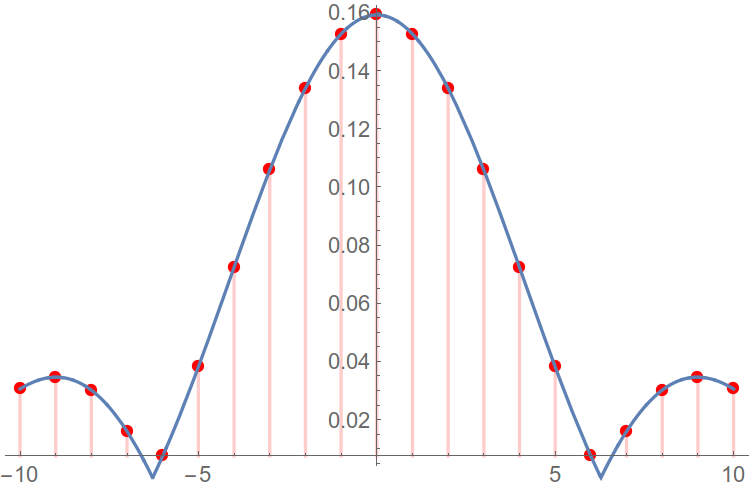
Рис. 1. Соответствие ряда Фурье и преобразования Фурье на примере амплитудного спектра.
Легко видно, что коэффициенты ряда Фурье являются ни чем иным, как значениями преобразования Фурье в дискретные моменты времени.
Однако, преобразование Фурье сопоставляет непрерывной во времени, бесконечной функции другую, непрерывную по частоте, бесконечную функцию — спектр. Как быть, если у нас нет бесконечной во времени функции, а есть лишь какая-то записанная её дискретная во времени часть? Ответ на этот вопрос даёт дальнейшей развитие преобразования Фурье — дискретное преобразование Фурье (ДПФ).
Дискретное преобразование Фурье призвано решить проблему необходимости непрерывности и бесконечности во времени сигнала. По сути, мы полагаем, что вырезали какую-то часть бесконечного сигнала, а всю остальную временную область считаем этот сигнал нулевым.
Математически это означает, что, имея исследуемую бесконечную во времени функцию f(t), мы умножаем ее на некоторую оконную функцию w(t), которая обращается в ноль везде, кроме интересующего нас интервала времени.
Если «выходом» классического преобразования Фурье является спектр – функция, то «выходом» дискретного преобразования Фурье является дискретный спектр. И на вход тоже подаются отсчёты дискретного сигнала.
Остальные свойства преобразования Фурье не изменяются: о них можно прочитать в соответствующей литературе.
Нам же нужно лишь знать о Фурье-образе синусоидального сигнала, который мы и будем стараться отыскать в нашем спектре. В общем случае, это пара дельта-функций, симметричная относительно нулевой частоты в частотной области.
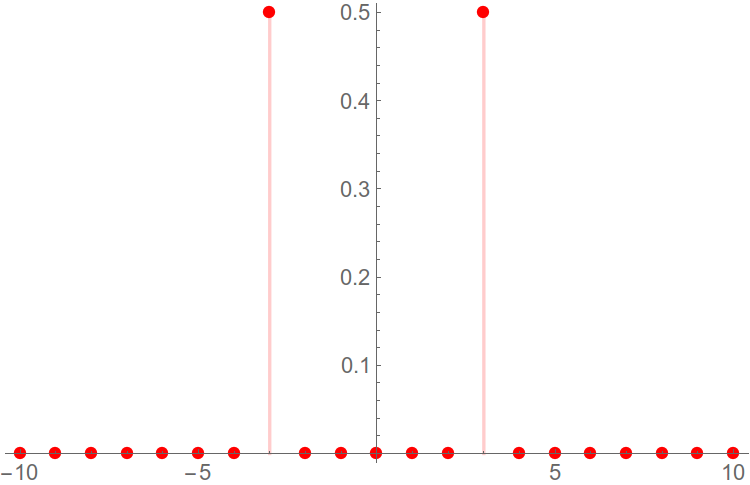
Рис. 2. Амплитудный спектр синусоидального сигнала.
Я уже упомянул, что, вообще говоря, мы рассматриваем не исходную функцию, а некоторое её произведение с оконной функцией. Тогда, если спектр исходной функции — F(w), а оконной W(w), то спектром произведения будет такая неприятная операция, как свёртка этих двух спектров (F*W)(w) (Теорема о свёртке).
На практике это означает, что вместо дельта-функции, в спектре мы увидим что-то вроде этого:
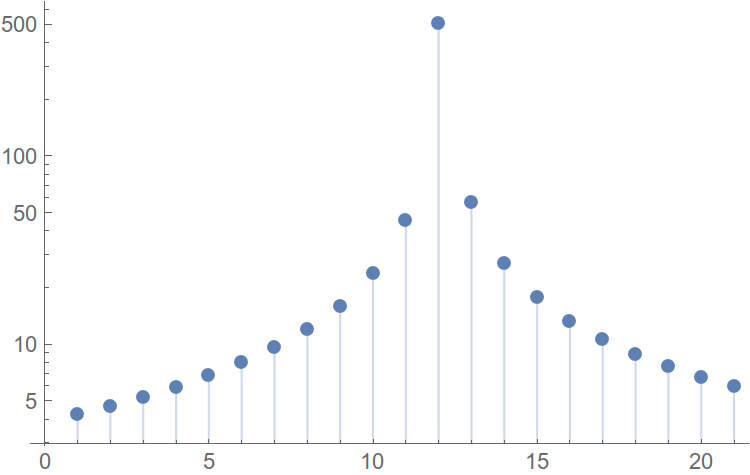
Рис. 3. Эффект растекания спектра.
Этот эффект именуют также растеканием спектра (англ. spectral leekage). А шумы, появляющиеся вследствие растекания спектра, соответственно, боковыми лепестками (англ. sidelobes).
Для борьбы с боковыми лепестками применяют другие, непрямоугольные оконные функции. Основной характеристикой «эффективности» оконной функции является уровень боковых лепестков (дБ). Сводная таблица уровней боковых лепестков для некоторых часто используемых оконных функций приведена ниже.
| Оконная функция | Уровень боковых лепестков (дБ) |
| Окно Дирихле (прямоугольное окно) | -13 дБ |
| Окно Ханна | -31.5 дБ |
| Окно Хэмминга | -42 дБ |
Основной проблемой в нашей задаче является то, что боковые лепестки могут маскировать другие гармоники, лежащие рядом.
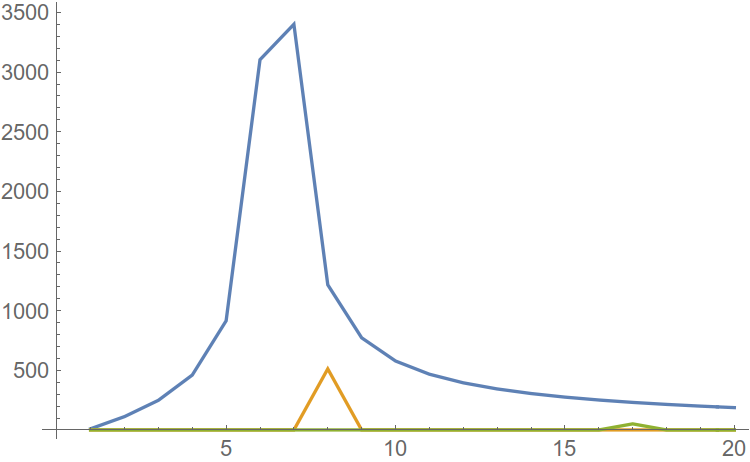
Рис. 4. Отдельные спектры гармоник.
Видно, что при сложении приведённых спектров, более слабые гармоники как бы растворятся в более сильной.
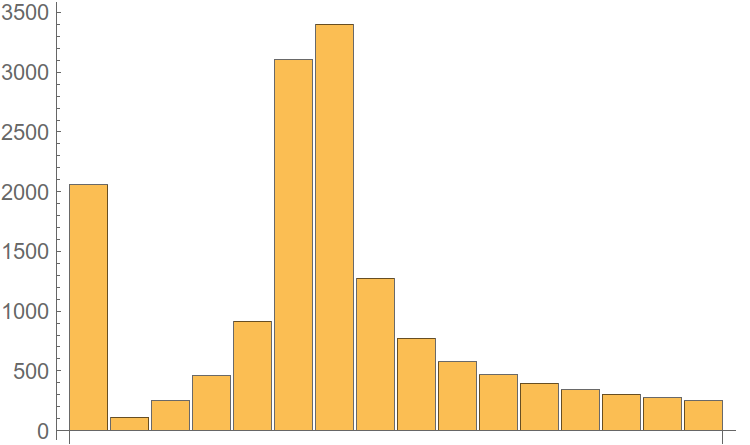
Рис. 5. Чётко видна лишь одна гармоника. Нехорошо.
Другой подход к борьбе с растеканием спектра состоит в вычитании из сигнала гармоник, создающих это самое растекание.
То есть, установив амплитуду, частоту и начальную фазу гармоники, можно вычесть её из сигнала, при этом мы уберём и «дельта-функцию», соответствующую ей, а вместе с ней и боковые лепестки, порождаемые ей. Другой вопрос состоит в том, как же точно узнать параметры нужной гармоники. Недостаточно просто взять нужные данные из комплексной амплитуды. Комплексные амплитуды спектра сформированы по целым частотам, однако, ничто не мешает гармонике иметь и дробную частоту. В этом случае, комплексная амплитуда как бы расплывается между двумя соседними частотами, и точную её частоту, как и другие параметры, установить нельзя.
Для установления точной частоты и комплексной амплитуды нужной гармоники, мы воспользуемся приёмом, широко применяемым во многих отраслях инженерной практики – гетеродинирование.
Посмотрим, что получится, если умножить входной сигнал на комплексную гармонику Exp(I*w*t). Спектр сигнала сдвинется на величину w вправо.
Этим свойством мы и воспользуемся, сдвигая спектр нашего сигнала вправо, до тех пор, пока гармоника не станет ещё больше напоминать дельта-функцию (то есть, пока некоторое локальное отношение сигнал/шум не достигнет максимума). Тогда мы и сможем вычислить точную частоту нужной гармоники, как w0 – wгет, и вычесть её из исходного сигнала для подавления эффекта растекания спектра.
Иллюстрация изменения спектра в зависимости от частоты гетеродина показана ниже.
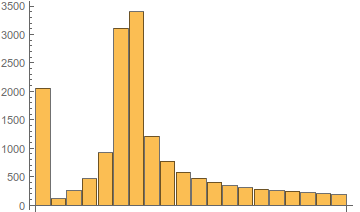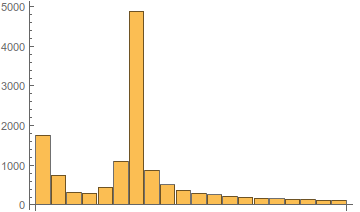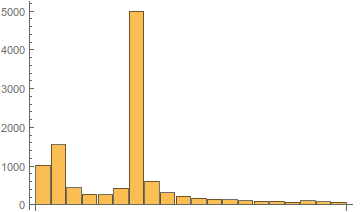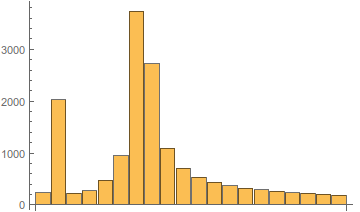
Рис. 6. Вид амплитудного спектра в зависимости от частоты гетеродина.
Будем повторять описанные процедуры до тех пор, пока не вырежем все присутствующие гармоники, и спектр не будет напоминать нам спектр белого шума.
Затем, надо оценить СКО белого шума. Хитростей здесь нет: можно просто воспользоваться формулой для вычисления СКО:
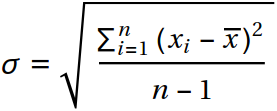
Автоматизируй это
Пришло время для автоматизации выделения гармоник. Повторим ещё разочек алгоритм:
1. Ищем глобальный пик амплитудного спектра, выше некоторого порога k.
1.1 Если не нашли, заканчиваем
2. Варируя частоту гетеродина, ищем такое значение частоты, при которой будет достигаться максимум некоторого локального отношения сигнал/шум в некоторой окрестности пика
3. При необходимости, округляем значения амплитуды и фазы.
4. Вычитаем из сигнала гармонику с найденной частотой, амплитудой и фазой за вычетом частоты гетеродина.
5. Переходим к пункту 1.
Алгоритм не сложный, и единственный возникающий вопрос — откуда же брать значения порога, выше которого будем искать гармоники?
Для ответа на этот вопрос, следует оценить уровень шума еще до вырезания гармоник.
Построим функцию распределения (привет, мат. cтатистика), где по оси абсцисс будет амплитуда гармоник, а по оси ординат — количество гармоник, не превышающих по амплитуде это самое значение аргумента. Пример такой построенной функции:
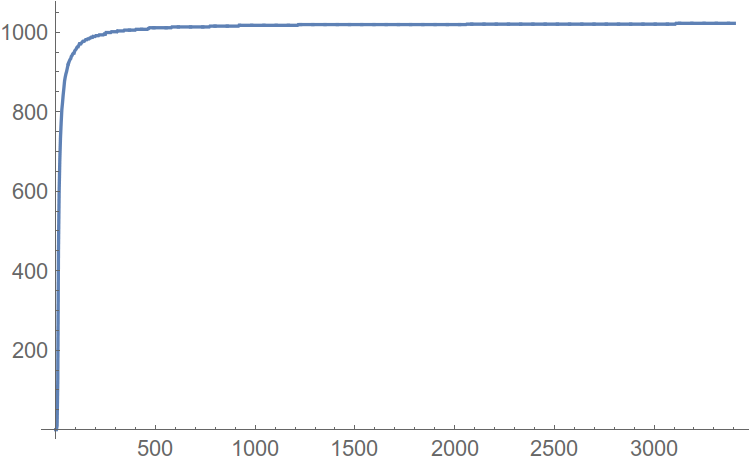
Рис. 7. Функция распределения гармоник.
Теперь построим еще и функцию — плотность распределения. Т.е., значения конечных разностей от функции распределения.
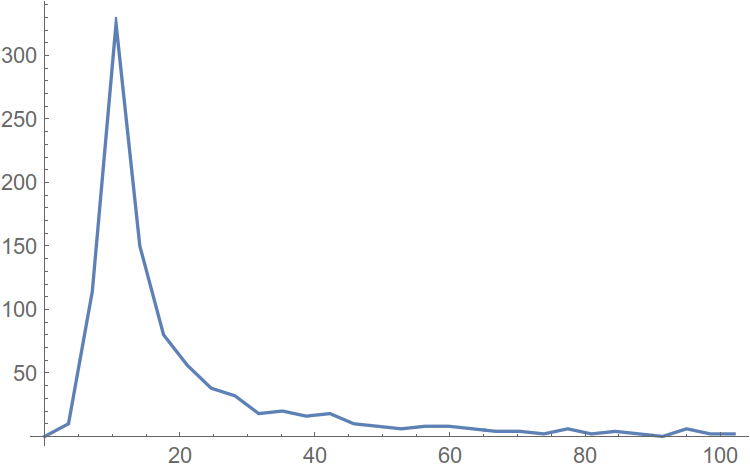
Рис. 8. Плотность функции распределения гармоник.
Абсцисса максимума плотности распределения и является амплитудой гармоники, встречающейся в спектре наибольшее число раз. Отойдем от пика вправо на некоторое расстояние, и будем считать абсциссу этой точки оценкой уровня шума в нашем спектре. Вот теперь можно и автоматизировать.
Посмотреть на кусок кода, детектирующий гармоники в составе сигнала
public ArrayList<SynthesizableSignal> detectHarmonics() { SignalCutter cutter = new SignalCutter(source, new Signal(source)); SynthesizableComplexExponent heterodinParameter = new SynthesizableComplexExponent(); heterodinParameter.setProperty("frequency", 0.0); Signal heterodin = new Signal(source.getLength()); Signal heterodinedSignal = new Signal(cutter.getCurrentSignal()); Spectrum spectrum = new Spectrum(heterodinedSignal); int harmonic; while ((harmonic = spectrum.detectStrongPeak(min)) != -1) { if (cutter.getCuttersCount() > 10) throw new RuntimeException("Unable to analyze signal! Try another parameters."); double heterodinSelected = 0.0; double signalToNoise = spectrum.getRealAmplitude(harmonic) / spectrum.getAverageAmplitudeIn(harmonic, windowSize); for (double heterodinFrequency = -0.5; heterodinFrequency < (0.5 + heterodinAccuracy); heterodinFrequency += heterodinAccuracy) { heterodinParameter.setProperty("frequency", heterodinFrequency); heterodinParameter.synthesizeIn(heterodin); heterodinedSignal.set(cutter.getCurrentSignal()).multiply(heterodin); spectrum.recalc(); double newSignalToNoise = spectrum.getRealAmplitude(harmonic) / spectrum.getAverageAmplitudeIn(harmonic, windowSize); if (newSignalToNoise > signalToNoise) { signalToNoise = newSignalToNoise; heterodinSelected = heterodinFrequency; } } SynthesizableCosine parameter = new SynthesizableCosine(); heterodinParameter.setProperty("frequency", heterodinSelected); heterodinParameter.synthesizeIn(heterodin); heterodinedSignal.set(cutter.getCurrentSignal()).multiply(heterodin); spectrum.recalc(); parameter.setProperty("amplitude", MathHelper.adaptiveRound(spectrum.getRealAmplitude(harmonic))); parameter.setProperty("frequency", harmonic - heterodinSelected); parameter.setProperty("phase", MathHelper.round(spectrum.getPhase(harmonic), 1)); cutter.addSignal(parameter); cutter.cutNext(); heterodinedSignal.set(cutter.getCurrentSignal()); spectrum.recalc(); } return cutter.getSignalsParameters(); }
Практическая часть
Я не претендую на звание эксперта Java, и представленное решение может быть сомнительным как по части производительности и потреблению памяти, так и в целом философии Java и философии ООП, как бы я ни старался сделать его лучше. Написано было за пару вечеров, как proof of concept. Желающие могут ознакомиться с исходным кодом на GitHub.
Единственной сложностью стала генерация PDF отчёта по результатам анализа: PDFbox ну никак не хотел работать с кириллицей. К слову, не хочет и сейчас.
В проекте использовались библиотеки:
JFreeChart – отображение графиков
PDFBox – построение отчёта
JLatexMath – рендер Latex формул
В итоге, получилась довольно массивная программа (13.6 мегабайт), удобно реализующая поставленную задачу.
Есть возможность как вырезать гармоники вручную, так и доверить эту задачу алгоритму.
Всем спасибо за внимание!
Пример отчёта, создаваемого программой.
Литература
Сергиенко А. Б. — Цифровая обработка сигналов

