В последнее время всё чаще и чаще слышишь мнение, что сейчас происходит технологическая революция. Бытует мнение, что мир стремительно меняется.

На мой взгляд такое и правда происходит. И одна из главных движущих сил — новые алгоритмы обучения, позволяющие обрабатывать большие объёмы информации. Современные разработки в области компьютерного зрения и алгоритмов машинного обучения могут быстро принимать решения с точностью не хуже профессионалов.
Я работаю в области связанной с анализом изображений. Это одна из областей которую новые идеи затронули сильнее всего. Одна из таких идей — свёрточные нейронные сети. Четыре года назад с их помощью впервые начали выигрывать конкурсы по обработке изображений. Победы не остались незамеченными. Нейронными сетями, до тех пор стоящими на вторых ролях, стали заниматься и пользоваться десятки тысяч последователей. В результате, полтора-два года назад начался бум, породивший множество идей, алгоритмов, статей.
В своём рассказе я сделаю обзор тех идей, которые появились за последние пару лет и зацепили мою тематику. Почему происходящее — революция и чего от неё ждать.
Кто лишится в ближайшие лет десять работы, а у кого будут новые перспективные вакансии.
Во главе происходящей революции стоит несколько типов алгоритмов. Флагманами являются нейронные сети. Про них и будет речь.

Нейронные сети появились давно. Ещё в сороковых годах. Идея простая: лучшая машина принятия решений — человеческий мозг. Давайте его эмулировать. Идея действительно потрясающая и простая. Вот только всё спотыкается о реализацию. Нейронов в человеческом мозгу… Гхм. Много. Да и архитектура запутанная.
Начиная с сороковых годов каждые пару лет приходил очередной прорыв в вычислительной технике или в понимании мозга. И сразу поднималась волна: "Наконец нейронные сети заработают!". Но, через пару лет волна шла на спад.
Когда я учился на старших курсах (2007-2010) общепринятым мнением было: "Да достали вы своими нейронными сетями! Они не работают! Уже десять раз проверили. Возьмите SVM, Random Forest или Adaboost! Проще, понятнее, точнее". В особом почёте были чисто математические решения задач, когда всё можно было расписать через формулу правдоподобия (такое решение, безусловно, превзойти нельзя).
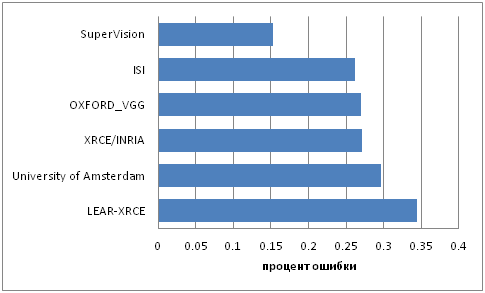
Что же произошло, что к 2012 году нейронные сети сумели всех раскидать и вырваться на олимп? По-моему ответ простой. Ничего. Достаточно мощные видеокарты на которых можно программировать к тому моменту были уже лет 8-9. Идеи, которые произвели прорыв, были посеяны ещё в конце 80-х начале 90-х. Появилась CUDA, но были инструменты и до неё.


Просто произошел планомерный рост. Идеи, которые в 90х ели слишком много вычислительных мощностей стали реальны. Писать под видеокарты стало проще. Слово за слово, статья за статьей, глаз за глаз. И вдруг, в 2012 году конкурс ImageNet выигрывает свёрточная нейронная сеть. При этом не просто выигрывает, а с отрывом от ближайшего преследователя в два раза.
Это такая большая-большая база слов и привязанных к ним картинок. Состоящая из всего: предметов, структур, существ. Картинок может быть десяток, а могут быть тысячи. В зависимости от сложности и распространённости понятия:



Каждый год по ней проводится конкурс. Какой процент из понятий сможет распознать система. Условия конкурса немного меняются, но идея остаётся прежней.
Вы, наверняка, видели картинки с распознанными объектами из этой базы:

Тема длинная. Если интересно — лучше всего почитайте статьи: 1, 2, 3.
Вкратце. Свёрточные сети, это такие нейронные сети, где основным элементом обучения являются «свёртки». Свёртки это маленькие картинки:3*3, 5*5, 20*20. И на каждом уровне сети их обучаются десятки. Кроме них ничего не обучается. Мы учим сеть находить такие «свёртки», которые максимизируют информацию о изображении. Вот так выглядит структура такой сети:
При этом такие свёртки начинают работать как крутые фичер-детекторы сразу на многих уровнях глубины и смысла. Они могут найти как маленькие фичи, так и большие, глобальные. После фильтрации это выглядит как-то так:

Сами свёртки при этом будут, например, такими:

Или такими:

А в динамике процесс будет выглядеть вообще вот так:

Хорошая критика есть в статье rocknrollnerd. Или вот тут.
Вкратце. Что видит сеть — мы не знаем. Она не «понимает», она «находит закономерности». Какими бы безумными они не были. Её просто обмануть, если эти закономерности вскрыть. Например вот это — цифры 1-2-3-4-5-6-7-8-9 с вероятностью 99.9%:


Не похоже? А свёрточные сети считают иначе.
Всё что было выше — это вводная часть к статье. А теперь обещанная революция. Где случился прорыв и к чему он ведёт.

Прорыв заключается в том, что люди начали анализировать и понимать что же такое эти «свёрточные сети». Как результат — задавать им правильные вопросы.
Рассмотрим «устаревшие алгоритмы» (смешно говорить так про идеи, которым зачастую лет десять), которым производился поиск объектов на изображении. Например человека(HOG), лица (Haar), или каких-то более уникальных объектов (SIFT, SURF, ORB):

По сути, используется выделение примитивов, характерных для рассматриваемого объекта, которые мы анализируем. Анализ может производить как какая-то автоматическая система принятий решений (SVM, AdaBoost), так и сам человек, расставив простые правила (через SIFT, SURF). Вот тут есть хорошая лекция ЛеКуна (автора свёрточных сетей).
Первое время после появления свёрточных сетей так и работали: бралась область, проводился её анализ, принималось решение, есть ли в этой области искомый объект (например вот так). Свёрточные сети выделяют более обобщённые примитивы, а по ним мы уже смотрели объект:

Получалось достаточно медленно + писать много логики.
А не может ли свёрточная сеть найти объект за нас? Зачем мучиться с логикой, с окнами, с анализом?
Оказывается может. И на мой взгляд это ОЧЕНЬ круто. В качестве примера мне нравится вот эта статья. В ней нейросеть обучается выдавать x,y,w,h объекта. Просто и со вкусом. Один прогон сети — все объекты в кадре найдены и отмечены. Не нужно запускать сеть по разным областям. И действительно, какая разница: обучать выдавать класс объекта, или обучать выдавать класс + параметры? Главное, чтобы для каждого класса было место в выходных нейронах, куда можно было бы положить ответ:

На выходе сети объём размера ((Число классов)*2+5*2)*7*7. Если классов 10, то объём — 30*7*7. Тут 7*7 — это пространственная координата. По сути, такое уменьшенное изображение. Например точка 4*4 — это центр картинки. На каждую такую точку у нас есть 30 величин. 10 из них для обозначения объекта, который размещается в точке (класс этого объекта имеет значение 1, остальное — 0). Ещё 4 величины — x,y,w,h прямоугольника в точке, который определяет размер объекта, если он там есть. Ещё одна — коэффициент уверенности. Остальные 15 — это повторение всего того на случай, если в одном сегменте был центр двух объектов. Итого получается:

На сайте проекта можно посмотреть достаточно много интересных видео:
А можно ли подавать на вход сети априорную информацию, отличную от изображения? Конечно! Главное подобрать архитектуру сети, например так:

Здесь на вход сети подают изображения, а так же примерную область где расположен интересный объект. Сеть учится выдавать точный кроп + сегментировать объект. Теперь ваша сеть кушает априорные данные, сама определяя что это вообще такое и что с ним делать.
На мой взгляд эти идеи — это прорыв, который позволяет полностью уйти от старой идеологии алгоритмов. Раньше всё было отдельно: логические данные, изображения, связи. А теперь всё можно валить в общий котёл особо не думая (да вру я, вру, думать нужно много — над формированием базы, например). Главное понимать достаточность данных. Не нужно разбираться на какой стадии алгоритма оптимально что совместить. Сеть сама оптимизирует взаимодействие потоков данных.
Но и это не всё, что стало понятно за последние два-три года. Второе концептуальное наблюдение — сеть это нелинейный фильтр. Да, это знали ещё сорок лет назад. Но только сейчас стало понятно, что это значит и к чему это ведёт. Сеть может фильтровать входные данные и выдавать на выходе как логику, так и изображение (а можно и всё одновременно).
Полученные логика или изображения могут быть поданы на вход других алгоритмов. Или на вход человека.)
Начнём с последней работы, которая вроде даже проскакивала в новостях. Сеть делает разметку видео с видеорегистратора по типу объекта: «дорога», «пешеходы», «знаки», «разметка», и.т.д.
Данные, которые так получены могут быть поданы на вход ориентации автомобиля. Это принципиально новое решение, до сих пор системы классификации объектов для автоматических автомобилей были принципиально другими. Требовали лидаров или хотя бы стереокамер.
Вы думаете эта система сложна и монструозна? Да нет, всего несколько обученных слоёв, настраивается за пару дней:
Прямое преобразование данных в ответ. Кадры обрабатываются быстро. На ноуте четырёхлетней давности порядка секунды на кадр. На более-менее адекватном компе — realtime.
Есть ещё несколько сетей, решающих аналогичные проблемы чуть другой архитектурой (многие из них были раньше чем SegNet, но в целом работали хуже): 1, 2, 3




Теперь нейросети решают проблемы и задачи, которые ещё пять лет назад требовали огромного количество сил и были результатом работы целых групп учёных.
Наверняка многие из вас знают, что с двух камер можно восстановить трёхмерную картинку. Обучить сеть на её построение?

Такой подход хорош тем, что сеть сама догадается в каких ситуациях лучше аппроксимировать плоскостью, а в каких ситуациях лучше не надо. Да и обучить такую сеть просто. Погулять пару дней со стереокамерой, набрать видео. И сетка не сильно сложнее тех, что выше:

Оптический поток почти то же стереосоответвие, да? Только вот обучать решили компьютерными играми:

Не знаю, насколько это работает на практике, но идея прикольна.
Вы когда-нибудь использовали Canny фильтрацию в OpenCV? Наверняка знаете, что очень сложно подобрать её чувствительность, чтобы выделились именно границы, а не любой шум?



Вот три статьи как это сделать по-другому, чтобы результат был одинаков и вас не смущал: 1, 2, 3

Ну и да, куда же без этого. Пару недель назад проскакивала сеть по раскраске старых ЧБ фильмов:

Не идеально, но забавно.
Мне кажется, что в ближайшее время фотошоп будет обзаводится рядом новых плагинов…

Это лишь малое число сетей и идей. Их число растёт каждый день. Сейчас происходит тотальный прорыв в медицине. Видели конкурсы на kaggle? О том как по сетчатке распознают болезни? А что происходит за кулисами — вообще страшно. Мы тут за неделю сделали наколенное распознавания флюорографий. Пусть и плохо, но оно работает. А вот ещё проект народ поднимает. Уверяют что могут всё распознать медицинское, лишь бы база была.
А уж число приложений Just For Fun будет расти астрономически. Помните приложения которые по фотографии определяют сколько вам лет? Или вашу привлекательность? Вангую появление приложений в стиле «посмотри на себя с бородой» или «преврати меня в Зевса».
А вообще свёрточных сетей и анализа изображений где только нет. Даже AlphaGo на их базе анализирует позиции в Go.
Вы правда думаете, что машины вас не заменят? Что ваша область уникальна? Система Deep Mind появилась в 10 году. Пару лет спустя они начали заниматься решением задачи «игра ГО». Спустя четыре года решили и сейчас бросают вызов чемпиону мира. За четыре года даже ребёнка в Го не научить играть. Вы правда думаете, что ваша профессия в безопасности? Что сингулярность ещё не здесь?
Все любят шутить про то, что через пару лет, как только появится автопилот для автомобилей таксисты начнут жечь машины- роботы как сегодня жгут машины «Uber». Поймите, до этого произойдёт много событий. Переводчики и юристы-помощники. Секретари. Ваша профессия в том, чтобы расшифровывать изображения? Врач-рентгенолог? Картограф? Нужны ли будут через пару лет специалисты по видеоаналитике, или гугл заменит их своими сервисами?
Конечно, лучшие переводчики останутся. Так же как и лучшие секретари. Да и хорошие рентгенологи, конечно, будут нужны (должен же кто-то верифицировать диагноз). Останутся все, чья специальность — работа руками. Пока ещё механика далека не то, чтобы полностью заменить хирургов и массажистов (я думаю ещё лет 20-30 даже до водопроводчиков не доберутся!). Появятся профессии, которые будут управлять роботами и комплексами из роботов. Будет сильно больше людей, которые будут обучать системы и поддерживать их. А вот средних и плохих программистов, на мой взгляд, уже лет через 5-10 начнут теснить системы автоматического программирования.
В любом случае, жить нам предстоит в интересные времена. И да, пока вы спали сингулярность уже здесь.
Нууу, я немного сгущаю, но в целом всё так, для пятницы сойдёт.
Если вдруг тема заинтересовала, то советую пару мест, где инфы сильно больше, чем на хабре и пополняется регулярно.
Во-первых, мне нравится вот это сообщество в контакте. Да, много мусора, но дельные вещи почти не пропускают.
Во-вторых, где-то половину из перечисленного я брал отсюда. Информации тут сильно меньше, но зато самое ценно и интересное они не пропускают. Плюс хорошо структурируют.
В-третьих, SKolotienko ещё подкинул хорошую ссылочку на реддит.
И ещё. Чтобы не быть голословным мы с другом взяли одну из указанных здесь сетей и пару недель мучили, заставляя распознавать что только попадается под руку (благо баз много собралось). В течении недельки он выложит статью с кучей исходников и мануалов. Так что следите за Nikkolo. А ещё Vasyutka в течении пару недель хотел некоторые мысли опубликовать из той области где нейросети пересекаются с здравой логикой.
Если вдруг вы натолкнулись на эту статью — помните, что она 2016 года. А сейчас 2021 уже. И часть приведенных ссылок устарела, и часть идей.
Зато у меня появился канал (vk, telegram) про более новые методы/подходы.
На мой взгляд такое и правда происходит. И одна из главных движущих сил — новые алгоритмы обучения, позволяющие обрабатывать большие объёмы информации. Современные разработки в области компьютерного зрения и алгоритмов машинного обучения могут быстро принимать решения с точностью не хуже профессионалов.
Я работаю в области связанной с анализом изображений. Это одна из областей которую новые идеи затронули сильнее всего. Одна из таких идей — свёрточные нейронные сети. Четыре года назад с их помощью впервые начали выигрывать конкурсы по обработке изображений. Победы не остались незамеченными. Нейронными сетями, до тех пор стоящими на вторых ролях, стали заниматься и пользоваться десятки тысяч последователей. В результате, полтора-два года назад начался бум, породивший множество идей, алгоритмов, статей.
В своём рассказе я сделаю обзор тех идей, которые появились за последние пару лет и зацепили мою тематику. Почему происходящее — революция и чего от неё ждать.
Кто лишится в ближайшие лет десять работы, а у кого будут новые перспективные вакансии.
Нейронные сети
Во главе происходящей революции стоит несколько типов алгоритмов. Флагманами являются нейронные сети. Про них и будет речь.
Нейронные сети появились давно. Ещё в сороковых годах. Идея простая: лучшая машина принятия решений — человеческий мозг. Давайте его эмулировать. Идея действительно потрясающая и простая. Вот только всё спотыкается о реализацию. Нейронов в человеческом мозгу… Гхм. Много. Да и архитектура запутанная.
Начиная с сороковых годов каждые пару лет приходил очередной прорыв в вычислительной технике или в понимании мозга. И сразу поднималась волна: "Наконец нейронные сети заработают!". Но, через пару лет волна шла на спад.
Когда я учился на старших курсах (2007-2010) общепринятым мнением было: "Да достали вы своими нейронными сетями! Они не работают! Уже десять раз проверили. Возьмите SVM, Random Forest или Adaboost! Проще, понятнее, точнее". В особом почёте были чисто математические решения задач, когда всё можно было расписать через формулу правдоподобия (такое решение, безусловно, превзойти нельзя).
Что же произошло, что к 2012 году нейронные сети сумели всех раскидать и вырваться на олимп? По-моему ответ простой. Ничего. Достаточно мощные видеокарты на которых можно программировать к тому моменту были уже лет 8-9. Идеи, которые произвели прорыв, были посеяны ещё в конце 80-х начале 90-х. Появилась CUDA, но были инструменты и до неё.
Просто произошел планомерный рост. Идеи, которые в 90х ели слишком много вычислительных мощностей стали реальны. Писать под видеокарты стало проще. Слово за слово, статья за статьей, глаз за глаз. И вдруг, в 2012 году конкурс ImageNet выигрывает свёрточная нейронная сеть. При этом не просто выигрывает, а с отрывом от ближайшего преследователя в два раза.
Что такое ImageNet
Это такая большая-большая база слов и привязанных к ним картинок. Состоящая из всего: предметов, структур, существ. Картинок может быть десяток, а могут быть тысячи. В зависимости от сложности и распространённости понятия:
Каждый год по ней проводится конкурс. Какой процент из понятий сможет распознать система. Условия конкурса немного меняются, но идея остаётся прежней.
Вы, наверняка, видели картинки с распознанными объектами из этой базы:
Что такое свёрточные сети?
Тема длинная. Если интересно — лучше всего почитайте статьи: 1, 2, 3.
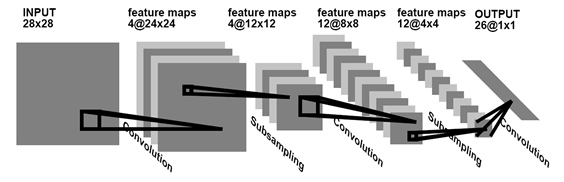
Вкратце. Свёрточные сети, это такие нейронные сети, где основным элементом обучения являются «свёртки». Свёртки это маленькие картинки:3*3, 5*5, 20*20. И на каждом уровне сети их обучаются десятки. Кроме них ничего не обучается. Мы учим сеть находить такие «свёртки», которые максимизируют информацию о изображении. Вот так выглядит структура такой сети:
При этом такие свёртки начинают работать как крутые фичер-детекторы сразу на многих уровнях глубины и смысла. Они могут найти как маленькие фичи, так и большие, глобальные. После фильтрации это выглядит как-то так:
Сами свёртки при этом будут, например, такими:
Или такими:
А в динамике процесс будет выглядеть вообще вот так:
Критика
Хорошая критика есть в статье rocknrollnerd. Или вот тут.
Вкратце. Что видит сеть — мы не знаем. Она не «понимает», она «находит закономерности». Какими бы безумными они не были. Её просто обмануть, если эти закономерности вскрыть. Например вот это — цифры 1-2-3-4-5-6-7-8-9 с вероятностью 99.9%:
Не похоже? А свёрточные сети считают иначе.
Прорыв
Всё что было выше — это вводная часть к статье. А теперь обещанная революция. Где случился прорыв и к чему он ведёт.
Прорыв заключается в том, что люди начали анализировать и понимать что же такое эти «свёрточные сети». Как результат — задавать им правильные вопросы.
Рассмотрим «устаревшие алгоритмы» (смешно говорить так про идеи, которым зачастую лет десять), которым производился поиск объектов на изображении. Например человека(HOG), лица (Haar), или каких-то более уникальных объектов (SIFT, SURF, ORB):
По сути, используется выделение примитивов, характерных для рассматриваемого объекта, которые мы анализируем. Анализ может производить как какая-то автоматическая система принятий решений (SVM, AdaBoost), так и сам человек, расставив простые правила (через SIFT, SURF). Вот тут есть хорошая лекция ЛеКуна (автора свёрточных сетей).
Первое время после появления свёрточных сетей так и работали: бралась область, проводился её анализ, принималось решение, есть ли в этой области искомый объект (например вот так). Свёрточные сети выделяют более обобщённые примитивы, а по ним мы уже смотрели объект:
Получалось достаточно медленно + писать много логики.
А не может ли свёрточная сеть найти объект за нас? Зачем мучиться с логикой, с окнами, с анализом?
Оказывается может. И на мой взгляд это ОЧЕНЬ круто. В качестве примера мне нравится вот эта статья. В ней нейросеть обучается выдавать x,y,w,h объекта. Просто и со вкусом. Один прогон сети — все объекты в кадре найдены и отмечены. Не нужно запускать сеть по разным областям. И действительно, какая разница: обучать выдавать класс объекта, или обучать выдавать класс + параметры? Главное, чтобы для каждого класса было место в выходных нейронах, куда можно было бы положить ответ:
На выходе сети объём размера ((Число классов)*2+5*2)*7*7. Если классов 10, то объём — 30*7*7. Тут 7*7 — это пространственная координата. По сути, такое уменьшенное изображение. Например точка 4*4 — это центр картинки. На каждую такую точку у нас есть 30 величин. 10 из них для обозначения объекта, который размещается в точке (класс этого объекта имеет значение 1, остальное — 0). Ещё 4 величины — x,y,w,h прямоугольника в точке, который определяет размер объекта, если он там есть. Ещё одна — коэффициент уверенности. Остальные 15 — это повторение всего того на случай, если в одном сегменте был центр двух объектов. Итого получается:
На сайте проекта можно посмотреть достаточно много интересных видео:
А можно ли подавать на вход сети априорную информацию, отличную от изображения? Конечно! Главное подобрать архитектуру сети, например так:
Здесь на вход сети подают изображения, а так же примерную область где расположен интересный объект. Сеть учится выдавать точный кроп + сегментировать объект. Теперь ваша сеть кушает априорные данные, сама определяя что это вообще такое и что с ним делать.
На мой взгляд эти идеи — это прорыв, который позволяет полностью уйти от старой идеологии алгоритмов. Раньше всё было отдельно: логические данные, изображения, связи. А теперь всё можно валить в общий котёл особо не думая (
Сеть как фильтр
Но и это не всё, что стало понятно за последние два-три года. Второе концептуальное наблюдение — сеть это нелинейный фильтр. Да, это знали ещё сорок лет назад. Но только сейчас стало понятно, что это значит и к чему это ведёт. Сеть может фильтровать входные данные и выдавать на выходе как логику, так и изображение (а можно и всё одновременно).
Полученные логика или изображения могут быть поданы на вход других алгоритмов. Или на вход человека.)
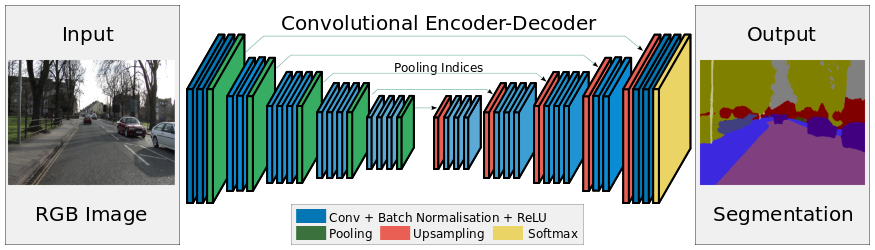
Начнём с последней работы, которая вроде даже проскакивала в новостях. Сеть делает разметку видео с видеорегистратора по типу объекта: «дорога», «пешеходы», «знаки», «разметка», и.т.д.
Данные, которые так получены могут быть поданы на вход ориентации автомобиля. Это принципиально новое решение, до сих пор системы классификации объектов для автоматических автомобилей были принципиально другими. Требовали лидаров или хотя бы стереокамер.
Вы думаете эта система сложна и монструозна? Да нет, всего несколько обученных слоёв, настраивается за пару дней:
Прямое преобразование данных в ответ. Кадры обрабатываются быстро. На ноуте четырёхлетней давности порядка секунды на кадр. На более-менее адекватном компе — realtime.
Есть ещё несколько сетей, решающих аналогичные проблемы чуть другой архитектурой (многие из них были раньше чем SegNet, но в целом работали хуже): 1, 2, 3
Теперь нейросети решают проблемы и задачи, которые ещё пять лет назад требовали огромного количество сил и были результатом работы целых групп учёных.
Стереосоответствие
Наверняка многие из вас знают, что с двух камер можно восстановить трёхмерную картинку. Обучить сеть на её построение?
Такой подход хорош тем, что сеть сама догадается в каких ситуациях лучше аппроксимировать плоскостью, а в каких ситуациях лучше не надо. Да и обучить такую сеть просто. Погулять пару дней со стереокамерой, набрать видео. И сетка не сильно сложнее тех, что выше:
Оптический поток
Оптический поток почти то же стереосоответвие, да? Только вот обучать решили компьютерными играми:
Не знаю, насколько это работает на практике, но идея прикольна.
Фильтрация
Вы когда-нибудь использовали Canny фильтрацию в OpenCV? Наверняка знаете, что очень сложно подобрать её чувствительность, чтобы выделились именно границы, а не любой шум?
Вот три статьи как это сделать по-другому, чтобы результат был одинаков и вас не смущал: 1, 2, 3
Раскрась-ка
Ну и да, куда же без этого. Пару недель назад проскакивала сеть по раскраске старых ЧБ фильмов:
Не идеально, но забавно.
Суперазрешение
Мне кажется, что в ближайшее время фотошоп будет обзаводится рядом новых плагинов…
Прочее из мира свёрточных сетей
Это лишь малое число сетей и идей. Их число растёт каждый день. Сейчас происходит тотальный прорыв в медицине. Видели конкурсы на kaggle? О том как по сетчатке распознают болезни? А что происходит за кулисами — вообще страшно. Мы тут за неделю сделали наколенное распознавания флюорографий. Пусть и плохо, но оно работает. А вот ещё проект народ поднимает. Уверяют что могут всё распознать медицинское, лишь бы база была.
А уж число приложений Just For Fun будет расти астрономически. Помните приложения которые по фотографии определяют сколько вам лет? Или вашу привлекательность? Вангую появление приложений в стиле «посмотри на себя с бородой» или «преврати меня в Зевса».
А вообще свёрточных сетей и анализа изображений где только нет. Даже AlphaGo на их базе анализирует позиции в Go.
Будущее
Вы правда думаете, что машины вас не заменят? Что ваша область уникальна? Система Deep Mind появилась в 10 году. Пару лет спустя они начали заниматься решением задачи «игра ГО». Спустя четыре года решили и сейчас бросают вызов чемпиону мира. За четыре года даже ребёнка в Го не научить играть. Вы правда думаете, что ваша профессия в безопасности? Что сингулярность ещё не здесь?
Все любят шутить про то, что через пару лет, как только появится автопилот для автомобилей таксисты начнут жечь машины- роботы как сегодня жгут машины «Uber». Поймите, до этого произойдёт много событий. Переводчики и юристы-помощники. Секретари. Ваша профессия в том, чтобы расшифровывать изображения? Врач-рентгенолог? Картограф? Нужны ли будут через пару лет специалисты по видеоаналитике, или гугл заменит их своими сервисами?
Конечно, лучшие переводчики останутся. Так же как и лучшие секретари. Да и хорошие рентгенологи, конечно, будут нужны (должен же кто-то верифицировать диагноз). Останутся все, чья специальность — работа руками. Пока ещё механика далека не то, чтобы полностью заменить хирургов и массажистов (я думаю ещё лет 20-30 даже до водопроводчиков не доберутся!). Появятся профессии, которые будут управлять роботами и комплексами из роботов. Будет сильно больше людей, которые будут обучать системы и поддерживать их. А вот средних и плохих программистов, на мой взгляд, уже лет через 5-10 начнут теснить системы автоматического программирования.
В любом случае, жить нам предстоит в интересные времена. И да, пока вы спали сингулярность уже здесь.
Немножко подвала
Если вдруг тема заинтересовала, то советую пару мест, где инфы сильно больше, чем на хабре и пополняется регулярно.
Во-первых, мне нравится вот это сообщество в контакте. Да, много мусора, но дельные вещи почти не пропускают.
Во-вторых, где-то половину из перечисленного я брал отсюда. Информации тут сильно меньше, но зато самое ценно и интересное они не пропускают. Плюс хорошо структурируют.
В-третьих, SKolotienko ещё подкинул хорошую ссылочку на реддит.
И ещё. Чтобы не быть голословным мы с другом взяли одну из указанных здесь сетей и пару недель мучили, заставляя распознавать что только попадается под руку (благо баз много собралось). В течении недельки он выложит статью с кучей исходников и мануалов. Так что следите за Nikkolo. А ещё Vasyutka в течении пару недель хотел некоторые мысли опубликовать из той области где нейросети пересекаются с здравой логикой.
PS
Если вдруг вы натолкнулись на эту статью — помните, что она 2016 года. А сейчас 2021 уже. И часть приведенных ссылок устарела, и часть идей.
Зато у меня появился канал (vk, telegram) про более новые методы/подходы.

