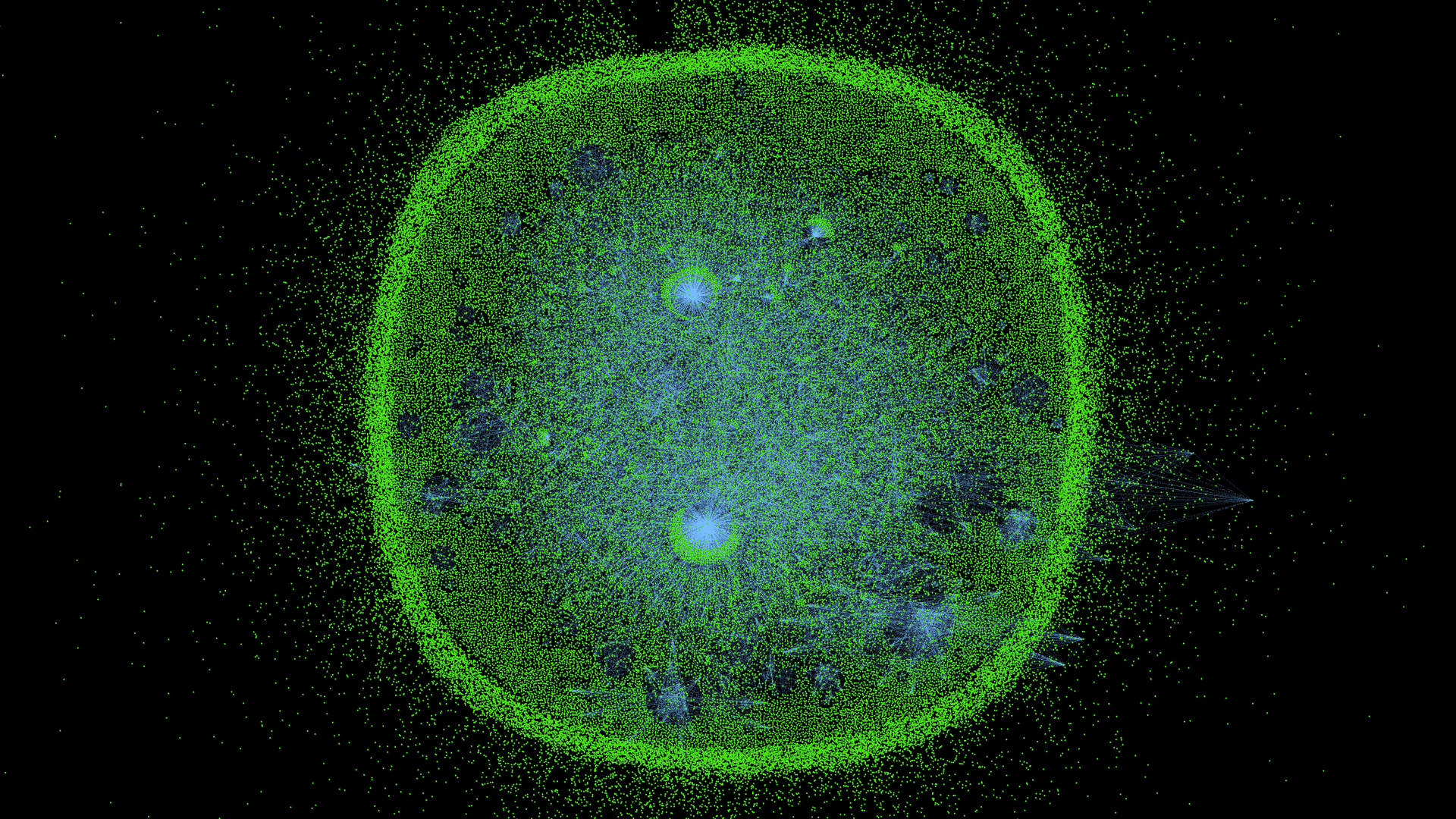
Однажды, мне стало интересно: насколько статьи на Хабре связаны между собой? Поэтому сегодня мы займемся исследованием связности статей, и конечно не только посчитаем численные метрики, но и увидим картину целиком.
(это не просто картинка для привлечения внимания, а граф цитирования статей внутри Хабрахабра, где размер вершин определяется числом входящих рёбер, i.e., "количеством цитат внутри Хабра")
Началось всё с того, что в комментариях к статье про Хабра-граф и карму Tiberius и Loriowar озвучили идею, фактически витающую в воздухе: а почему бы не взглянуть на граф цитирования статьёй внутри самого Хабра?
Вы спрашивали? Мы отвечаем. Для того чтобы рассказ не был размахиванием рук, конкретизируем разбираемые вопросы:
Q1: Как выглядит граф цитирования Хабрахабра и какие в нём хабы (hubs and authorities)?
Q2: Насколько связным является сообщество (граф цитирования) и какие в нём кластеры?
- Q3: Как изменится граф, если из него убрать самоцитирование?
Под катом трафик. Все картинки кликабельны.
Краткие пояснения по терминологии:
Хаб — это вершина с большим количеством исходящих ссылок, а "авторитетный источник" (authority) — вершина с большим количеством входящих ссылок. Под связностью мы будем понимать среднее число рёбер приходящихся на вершину (входящую или выходящую). Самоцитирование — это ребро, у которого обе вершины с одинаковым автором.
Граф цитируемости статей (внутри Хабра)
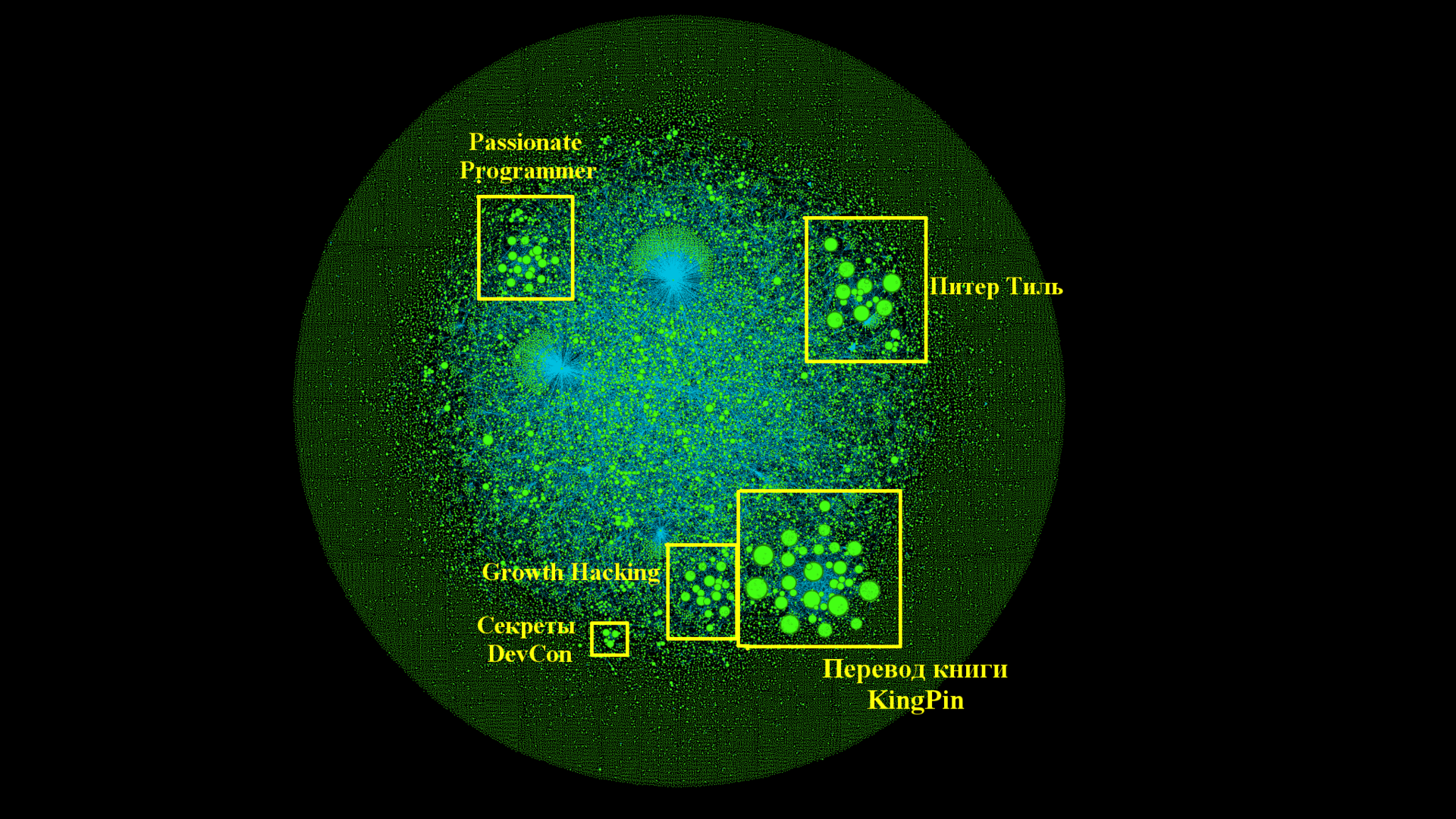
Возьмем граф из начала статьи и внимательно посмотрим на каждый из кластеров и крупные вершины. Мне удалось выделить и пометить несколько интересных "сообществ" статей.
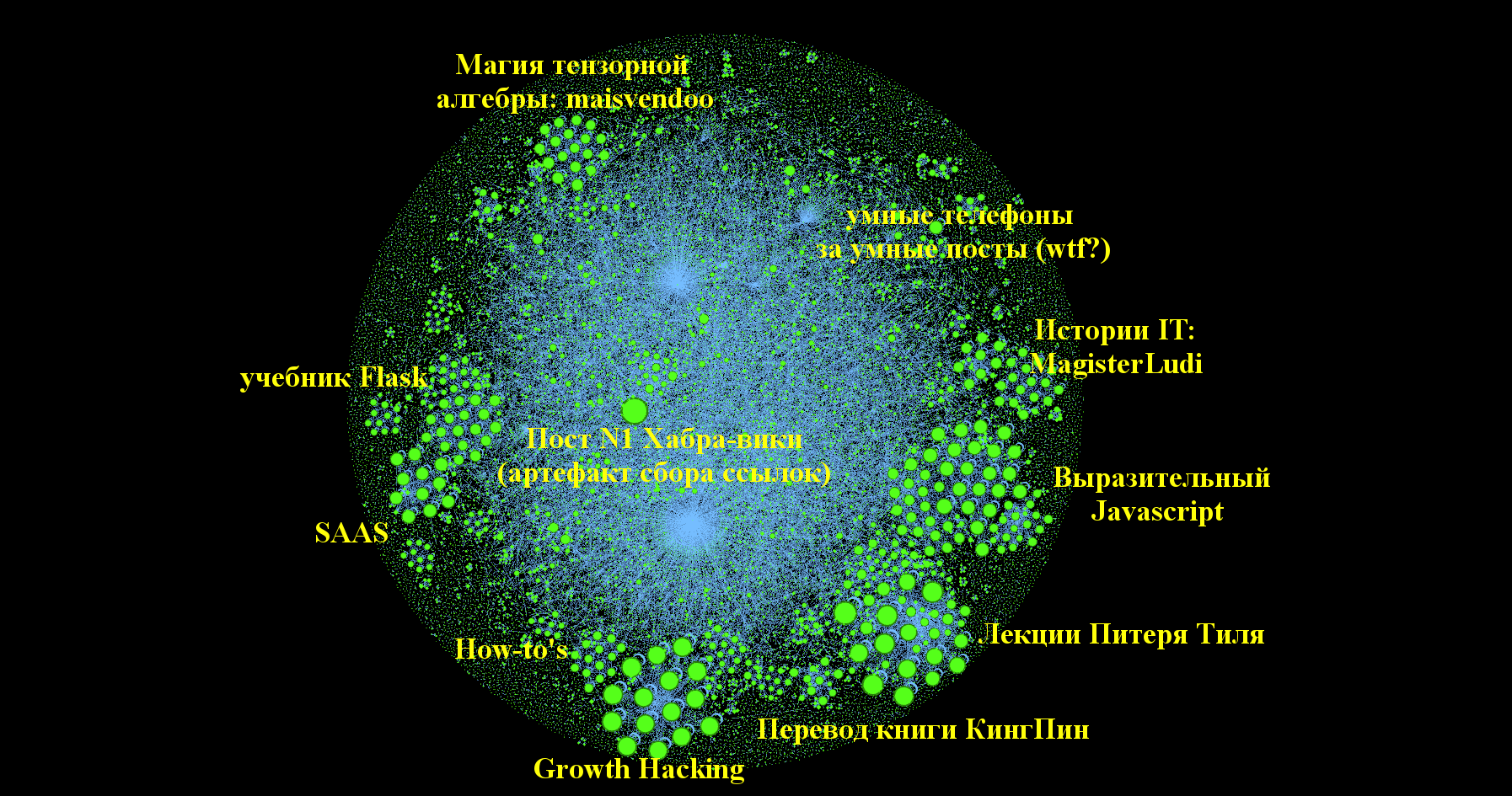
К сожалению, пост номер один: habrahabr.ru/post/1 получил много входящих по чисто техническим причинам (несовершенство парсера), на самом деле на него никто не ссылался.
Остальные кластеры довольно интересны, например есть целая группа историй IT в духе: Грэйс «бабуля COBOL» Хоппер или целый ряд статей по Тензорной Алгебре. Всего у нас 95 тысяч вершин и порядка 50 тысяч рёбер. Связность очень низкая: на одну вершину в среднем приходится порядка одного ребра и примерно 60% всех точек не связаны ни с одной другой статьёй на Хабре — см. большое плотное облако вокруг графа на самой последней картинке внизу.
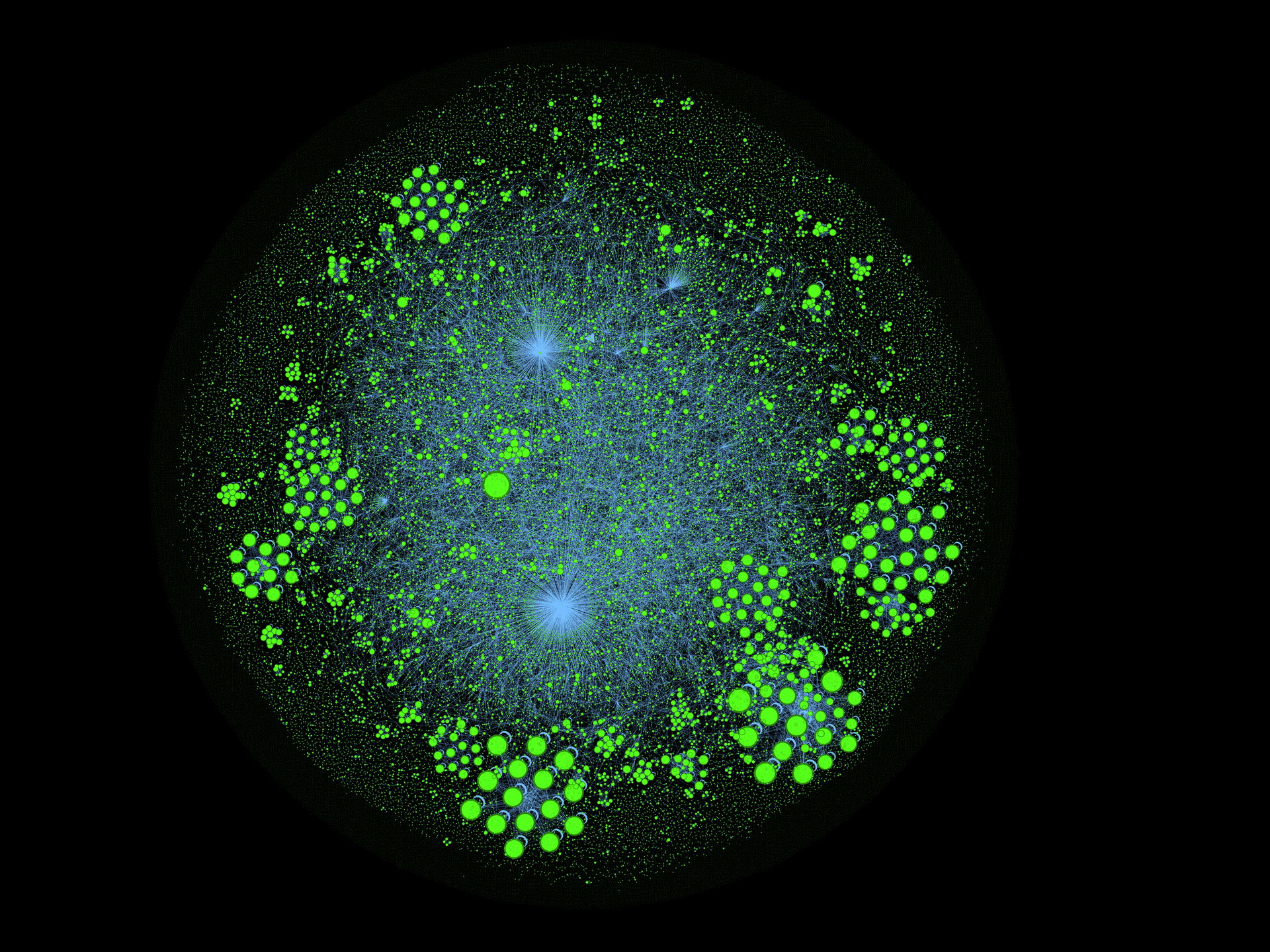
Граф без самоцитирования
Как мы видим картинка существенно поменялась и ряд кластеров пропал. В целом это отражает классический сценарий, когда серия статей одного автора имеет высокую связность за счет ссылок на всю серию в каждой статье.

Однако, ряд кластеров всё-таки выжил. Посмотрим на них повнимательнее.
"Народные" кластеры
Три самых больших и интересных кластера, которые выжили — это перевод книги Passionate Programmer, KingPin и лекции Питера Тиля. Отличная командная работа, в том числе и по документированию серии! Это очень интересный и позитивный результат, он говорит о том, что сообщество может скоординировано проводить достаточно большую и сложную работу, а так же поддерживать ссылочную целостность — найдя одну статью, всегда можно извлечь и найти всю серию.
Карта хабов ака граф исходящих рёбер
Мы уже посмотрели на "авторитетные источники", где вес вершины определялся входящими ребрами, теперь мы можем взглянуть на вершины с большим числом исходящих рёбер. И определить — какие же в сети присутствуют хабы.

Рассмотрим степень влияния каждого из хабов, подсветив их рёбра.

Теперь внимательно посмотрим, что же это за хабы?
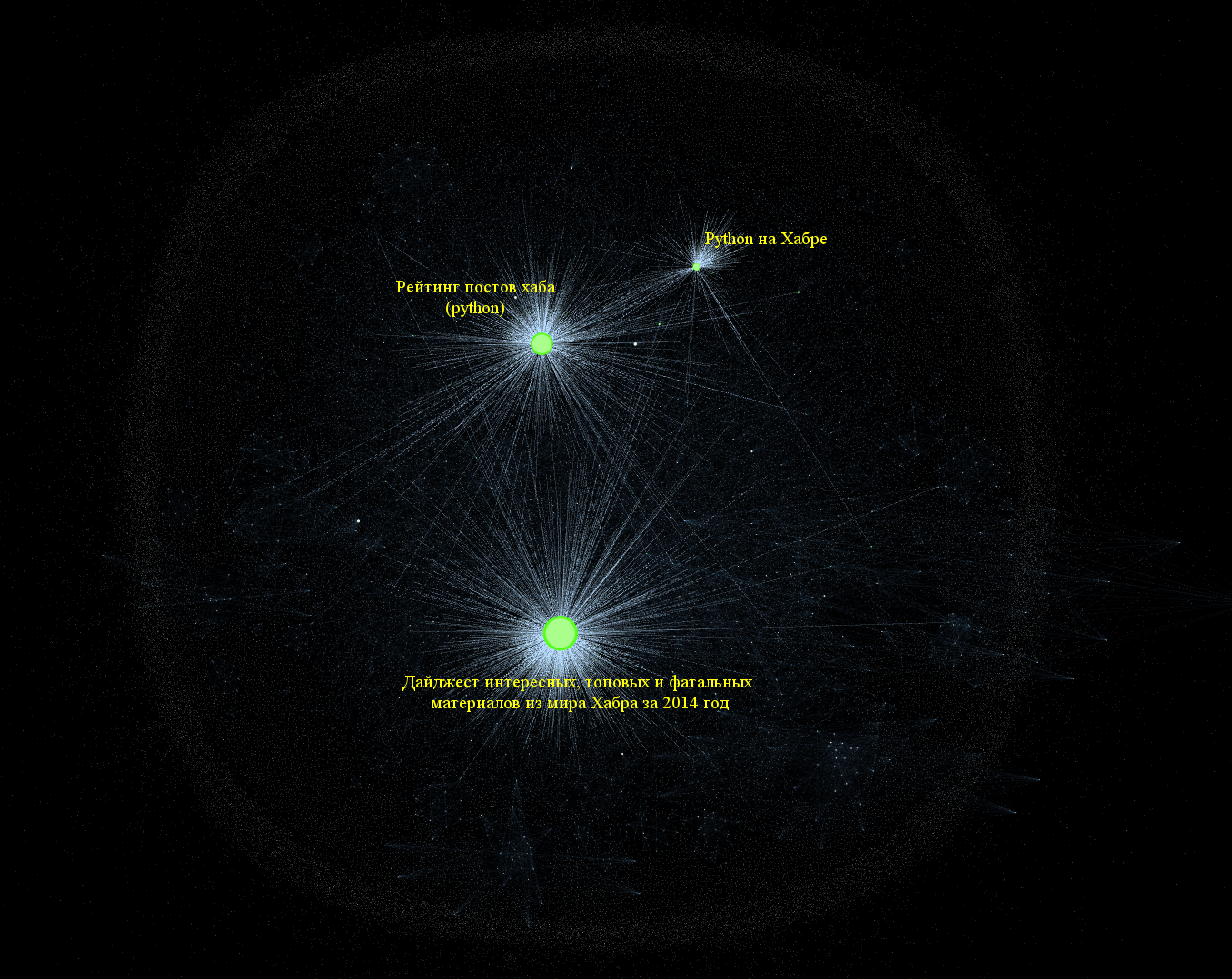
Как мы видим речь в основном идёт о постах с подборками интересных материалов на самом Хабре. Например, топом самого интересного или материалами по питону. Что безусловно логично — самым большим числом внешних ссылок обладают каталоги, хранящие исходящие ссылки (где же этот мета-обзор всех обзоров статей Хабра?).
Также этот граф подсказывает нам о большой любви сообщества к Python (и, надо сказать, небезосновательно).
Лидеры по числу входящих\исходящих цитат
Рассмотрим остальные посты (25+ ссылок) без учёта входящих и исходящих (т.е. считаем граф неориентированным).
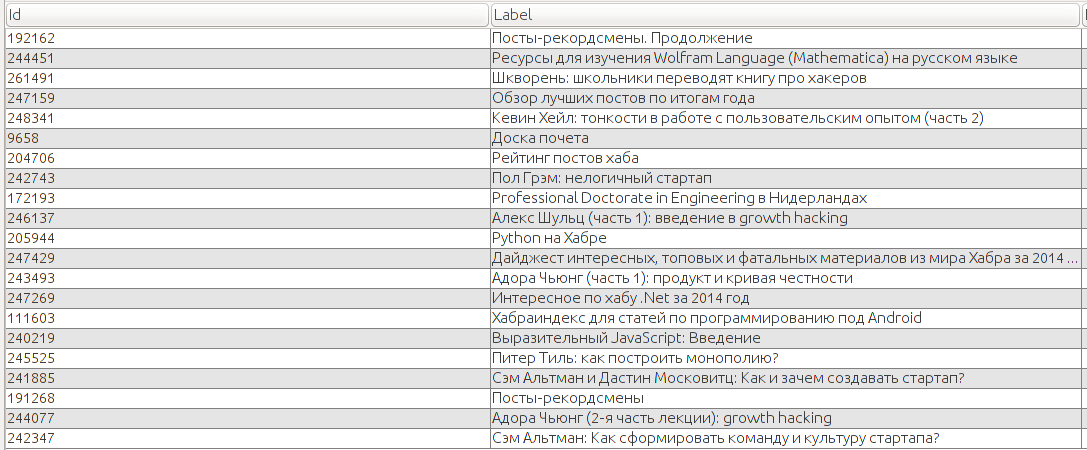
Все статьи в списке можно условно разделить на каталоги (интересные и полезные ссылки по теме Х) и части серии. Если внимательно приглядеться, то первые — это в точности наши хабы, а вторые — authorities.
То есть статей, которые бы просто все активно цитировали на Хабре нет (по крайней мере цитируют их тут реже, чем статьи серий).
Рейтинг цитирования авторов
Также интересно собрать число цитат в статьях, приходящихся на автора. При подсчете и составлении рейтинга не учитывалось самоцитирование (по этой теме будет отдельный рейтинг).
Первое место оказалось довольно предсказуемым — причём с бооольшим отрывом.
1 alizar,743
2 marks,261
3 ilya42,202
4 MagisterLudi,202
5 lapyk,167
6 XaocCPS,144
7 SLY_G,131
8 frii_fond,127
9 grokru,124
10 dmitrykabanov,118
11 kichik,115
12 saul,101
13 itinvest,99
14 jeston,97
15 ValdikSS,95
16 Mithgol,83
17 andorro,76
18 UiDesignGroup,72
19 IT_invest,71
20 amarao,70
21 p-y-t-h-o-n,69
22 esetnod32,66
23 aleksandrit,66
24 azproduction,64
25 nokiaman,64
26 wiygn,63
27 NCNecros,62
28 FSBook,61
29 Boomburum,61
Рейтинг самоцитирования
Данный рейтинг интересен прежде всего тем, что позволяет понять насколько сравнимо число цитат остальных авторов с собственным. В среднем мы видим, что число цитирований своих статей превосходит число обычных цитат. Также это говорит о существенном вкладе в связность графа цитирования личных статей.
Можно считать это личным вкладом в связность статей Хабра (автор данной статьи даже занял в этом рейтинге 26-ое (!) место).
1 itinvest,541
2 SLY_G,526
3 MagisterLudi,469
4 1cloud,424
5 esetnod32,415
6 ptsecurity,410
7 maisvendoo,373
8 zag2art,365
9 ilya42,337
10 EvseyFaydo,302
11 lol_wat,270
12 frii_fond,264
13 1eqinfinity,258
14 alexzfort,229
15 XaocCPS,226
16 andorro,226
17 alizar,222
18 khizmax,218
19 Boomburum,196
20 Mithgol,188
21 Milfgard,174
22 eagleson,173
23 vedenin1980,168
24 OsipovRoman,161
25 CooperMaster,159
26 varagian,155
27 bbk,154
28 Irina_Ua,153
29 dmitrykabanov,133
30 Unrul,131
Воспроизводимость и открытые данные
Твёрдно уверен, что любой результат исследований должен быть воспроизводим, повторяем, а также доступен читателю. Поэтому все исходные данные прилагаются к статье.
Ссылки: граф цитирования Хабрахабра и граф без самоцитирования (Gephi), а также дапм всех статей Хабрахабра доступен здесь (собрано в 20-х числах мая 2016-го), как и большое число других вкусных и интересных данных по Хабру, специально собранных и очищенных для использования (может неплохо подойти, если пишите диплом или нужны реальные текстовые или (полу-)структурированные данные).
Выводы
- Q1: Хабы — подборки интересностей на Хабре, авторитетные источники — серии статей, граф похож на облачко с несколькими сообществами и огромным поясом статей вокруг без единой ссылки (порядка 60% всех вершин)
- Q2: Граф сильно разреженный — порядка одного ребра на вершину, встречаются достаточно связные кластеры — например "Магия тензорной алгебры", поддерживающие связность за счет того, что каждая статья хранит каталог всех ссылок серии
- Q3: Без самоцитирования практически все кластеры пропадают, но остаётся небольшой ряд "народных" кластеров, например перевод книги KingPin, показывающий настоящую командную работу сообщества.
Вместо заключения
Из любви к искусству: граф цитирования без учета рёбер в качестве веса вершин