Введение
В этой заметке я хочу рассказать о том, как можно достаточно легко строить интерактивные графики в Jupyter Notebook'e с помощью библиотеки plotly. Более того, для их построения не нужно поднимать свой сервер и писать код на javascript. Еще один большой плюс предлагаемого подхода — визуализации будут работать и в NBViewer'e, т.е. можно будет легко поделиться своими результатами с коллегами. Вот, например, мой код для этой заметки.
Для примеров я взяла скаченные в апреле данные о фильмах (год выпуска, оценки на КиноПоиске и IMDb, жанры и т.д.). Я выгрузила данные по всем фильмам, у которых было хотя бы 100 оценок — всего 36417 фильмов. Про то, как скачать и распарсить данные КиноПоиска, я рассказывала в предыдущем посте.
Визуализация в python и plotly
В python есть много библиотек для визуализации: matplotlib, seaborn, портированный из R ggplot и другие (подробнее про инструменты можно почитать тут или тут). Есть среди них и те, которые позволяют строить интерактивные графики, например, bokeh, pygal и plotly, о котором собственно и пойдет речь.
Plotly позицинируется как online-платформа, где можно создавать и публиковать свои графики. Однако, эту библиотеку можно использовать и просто в Jupyter Notebook'e. К тому же у библиотеки есть offline-mode, который позволяет использовать ее без регистрации и публикации данных и графиков на сервер plotly (документация).
В целом, мне библиотека очень понравилась: есть подробная документация с примерами, поддержаны разные типы графиков (scatter plots, box plots, 3D графики, bar charts, heatmaps, дендрограммы и т.д.) и графики получаются достаточно симпатичными.
Примеры
Теперь настало время перейти непосредственно к примерам. Как я уже говорила выше, весь код и интерактивные графики доступны в NBViewer'e.
Библиотеку легко установить c помощью команды: pip install plotly.
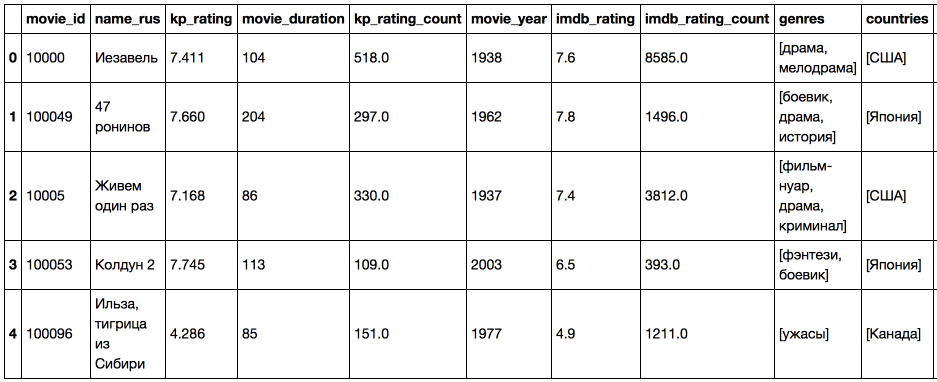
Прежде всего, необходимо сделать import'ы, вызвать команду init_notebook_mode для инициализации plot.ly и загрузить в pandas.DataFrame данные, с которыми будем работать.
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot import plotly.graph_objs as go init_notebook_mode(connected=True) df = pd.read_csv('kp_all_movies.csv') #скачиваем подготовленные данные df.head()
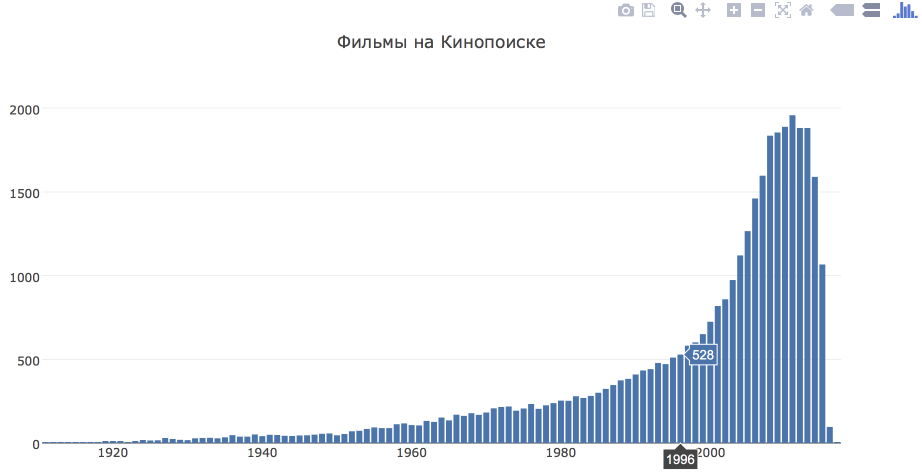
Сколько фильмов выходило в разные годы?
Для начала построим простой bar chart, показывающий распределение фильмов по году выпуска.
count_year_df = df.groupby('movie_year', as_index = False).movie_id.count() trace = go.Bar( x = count_year_df.movie_year, y = count_year_df.movie_id ) layout = go.Layout( title='Фильмы на Кинопоиске', ) fig = go.Figure(data = [trace], layout = layout) iplot(fig)
В результате, получим интерактивный график, который показывает значение при наведении на год и достаточно ожидаемый вывод о том, что с годами фильмов стало больше.
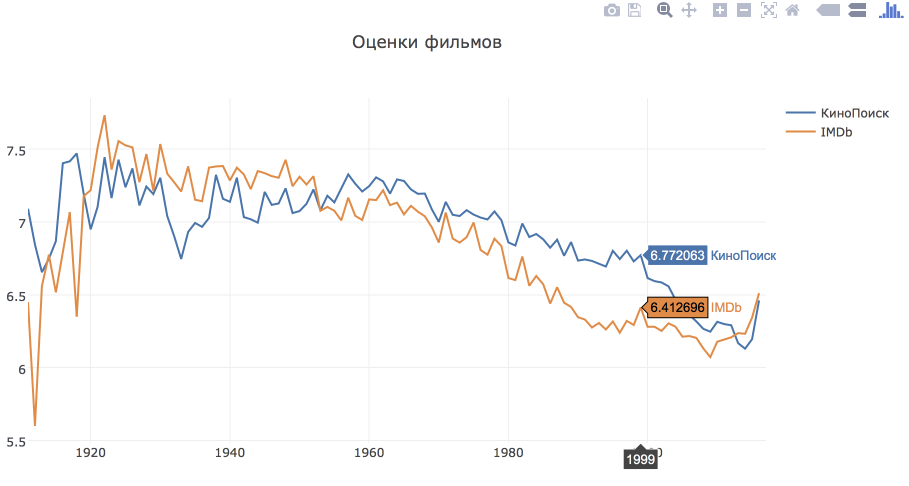
Стали ли с годами снимать более хорошее кино?
Для ответа на этот вопрос построим график зависимости средней оценки на КиноПоиске и IMDb от года выпуска.
rating_year_df = df.groupby('movie_year', as_index = False)[['kp_rating', 'imdb_rating']].mean() trace_kp = go.Scatter( x = rating_year_df.movie_year, y = rating_year_df.kp_rating, mode = 'lines', name = u'КиноПоиск' ) trace_imdb = go.Scatter( x = rating_year_df.movie_year, y = rating_year_df.imdb_rating, mode = 'lines', name = 'IMDb' ) layout = go.Layout( title='Оценки фильмов', ) fig = go.Figure(data = [trace_kp, trace_imdb], layout = layout) iplot(fig)
На оценках по КиноПоиску и IMDb виден тренд на снижение средней оценки в зависимости от года выпуска. Но, на самом деле, из этого нельзя сделать однозначный вывод о том, что раньше снимали более качественные фильмы. Дело в том, что если уж люди смотрят старые фильмы и оценивают их на КиноПоиске, то выбирают культовое кино с заведомо более высокими оценками (думаю, мало кто смотрит проходные фильмы, вышедшие в 1940м году, по крайней мере, я не смотрю).
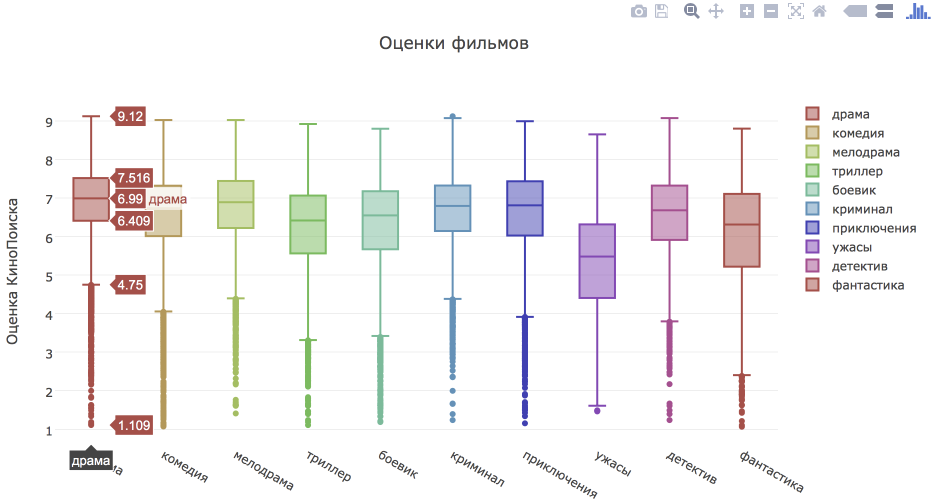
Есть ли различия в оценках в зависимости от жанра фильма?
Для сравнения оценок в зависимости от жанра построим box plot. Стоит помнить, что каждый фильм может принадлежать к нескольким жанрам, поэтому фильмы будут учитываться в нескольких группах.
# прежде всего распарсим поле genres и data frame с размноженными строками для каждого жанра def parse_list(lst_str): return filter(lambda y: y != '', map(lambda x: x.strip(), re.sub(r'[\[\]]', '', lst_str).split(','))) df['genres'] = df['genres'].fillna('[]') genres_data = [] for record in df.to_dict(orient = 'records'): genres_lst = parse_list(record['genres']) for genre in genres_lst: copy = record.copy() copy['genre'] = genre copy['weight'] = 1./len(genres_lst) genres_data.append(copy) genres_df = pd.DataFrame.from_dict(genres_data) # сформируем топ-10 жанров top_genres = genres_df.groupby('genre')[['movie_id']].count()\ .sort_values('movie_id', ascending = False)\ .head(10).index.values.tolist() N = float(len(top_genres)) # cгенерируем цвета для визуализации c = ['hsl('+str(h)+',50%'+',50%)' for h in np.linspace(0, 360, N)] data = [{ 'y': genres_df[genres_df.genre == top_genres[i]].kp_rating, 'type':'box', 'marker':{'color': c[i]}, 'name': top_genres[i] } for i in range(len(top_genres))] layout = go.Layout( title='Оценки фильмов', yaxis = {'title': 'Оценка КиноПоиска'} ) fig = go.Figure(data = data, layout = layout) iplot(fig)
По графику видно, что больше всего выделяются низкими оценками фильмы-ужастики
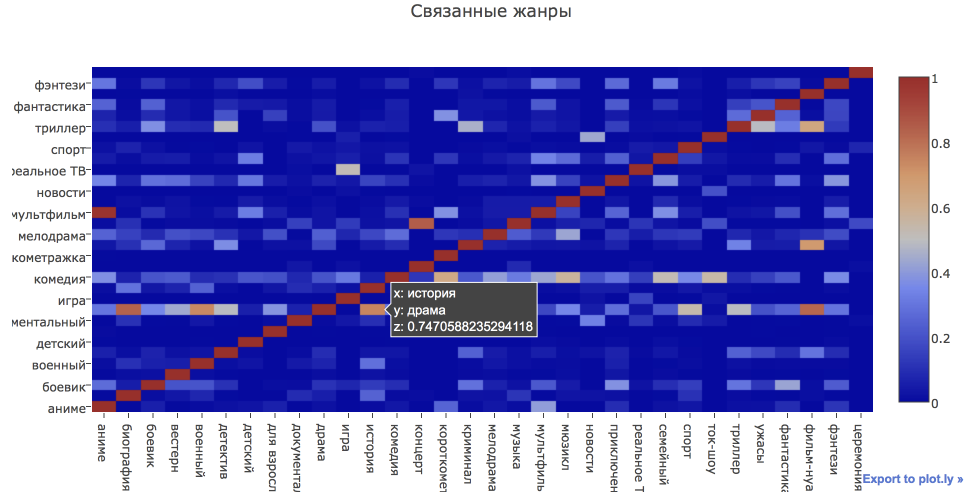
Какие жанры чаще всего соседствуют?
Как я говорила выше, один фильм чаще всего относится к нескольким жанрам сразу. Для того чтобы посмотреть на то, какие жанры чаще встречаются вместе, построим heatmap.
genres_coincidents = {} for item in df.genres: parsed_genres = parse_list(item) for genre1 in parsed_genres: if genre1 not in genres_coincidents: genres_coincidents[genre1] = defaultdict(int) for genre2 in parsed_genres: genres_coincidents[genre1][genre2] += 1 genres_coincidents_df = pd.DataFrame.from_dict(genres_coincidents).fillna(0) # отнормируем таблицу на количество фильмов каждого жанра genres_coincidents_df_norm = genres_coincidents_df\ .apply(lambda x: x/genres_df.groupby('genre').movie_id.count(), axis = 1) heatmap = go.Heatmap( z = genres_coincidents_df_norm.values, x = genres_coincidents_df_norm.index.values, y = genres_coincidents_df_norm.columns ) layout = go.Layout( title = 'Связанные жанры' ) fig = go.Figure(data = [heatmap], layout = layout) iplot(fig)
Читать график нужно следующим образом: 74,7% исторических фильмов также имеют тег драма.
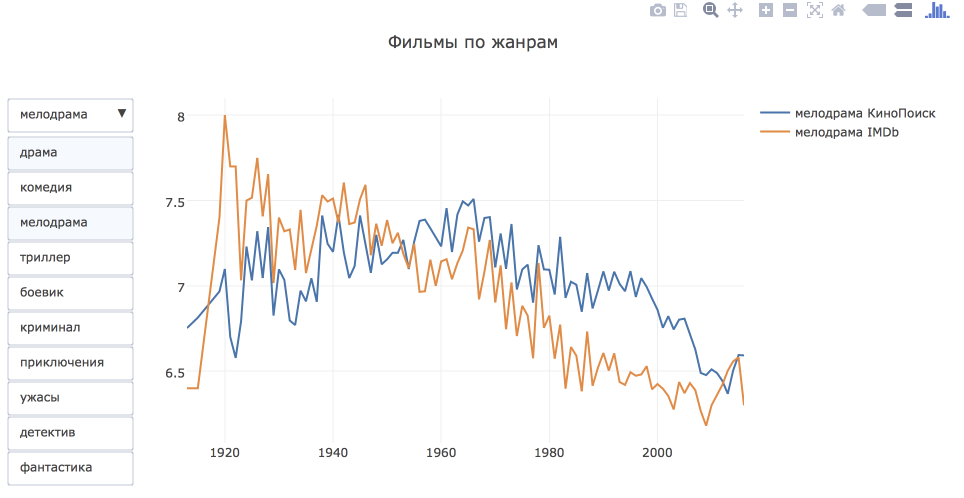
Как менялись оценки фильмов в зависимости от жанра?
Вернемся еще раз к примеру, в котором мы смотрели на зависимость средней оценки от года выпуска и построим такие графики для различных жанров. Параллельно познакомимся с еще одной фишкой plotly: можно сконфигурировать drop-down меню и изменять график в зависимости от выбранной опции.
genre_rating_year_df = genres_df.groupby(['movie_year', 'genre'], as_index = False)[['kp_rating', 'imdb_rating']].mean() N = len(top_genres) data = [] drop_menus = [] # конструируем все интересующие нас линии for i in range(N): genre = top_genres[i] genre_df = genre_rating_year_df[genre_rating_year_df.genre == genre] trace_kp = go.Scatter( x = genre_df.movie_year, y = genre_df.kp_rating, mode = 'lines', name = genre + ' КиноПоиск', visible = (i == 0) ) trace_imdb = go.Scatter( x = genre_df.movie_year, y = genre_df.imdb_rating, mode = 'lines', name = genre + ' IMDb', visible = (i == 0) ) data.append(trace_kp) data.append(trace_imdb) # создаем выпадающие меню for i in range(N): drop_menus.append( dict( args=['visible', [False]*2*i + [True]*2 + [False]*2*(N-1-i)], label= top_genres[i], method='restyle' ) ) layout = go.Layout( title='Фильмы по жанрам', updatemenus=list([ dict( x = -0.1, y = 1, yanchor = 'top', buttons = drop_menus ) ]), ) fig = go.Figure(data = data, layout = layout) iplot(fig)
В качестве заключения
В этой заметке мы познакомились с использованием библиотеки plotly для построения различных интерактивных графиков на python. Мне кажется, это очень полезный инструмент для аналитической работы, поскольку он позволяет делать интерактивные визуализации и легко делиться ими с коллегами.
Заинтересовавшимся советую посмотреть и другие примеры использования plot.ly.
Весь код и данные живут на github

