 Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2001 году, так стоит ли в очередной раз возвращаться к этой теме? Мне кажется что как раз сейчас и стоит. За эти пятнадцать лет поменялась сама точка зрения, тот угол под которым мы смотрим на проблему. В те далекие времена только-только вышла первая де-факто стандартная реализация — boost::shared_ptr<>, до этого каждый писал себе реализацию по потребности и как минимум представлял себе детали, сильные и слабые стороны своего кода. Все книги по C++ в то время обязательно описывали одну из вариаций умных указателей в мельчайших деталях.
Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2001 году, так стоит ли в очередной раз возвращаться к этой теме? Мне кажется что как раз сейчас и стоит. За эти пятнадцать лет поменялась сама точка зрения, тот угол под которым мы смотрим на проблему. В те далекие времена только-только вышла первая де-факто стандартная реализация — boost::shared_ptr<>, до этого каждый писал себе реализацию по потребности и как минимум представлял себе детали, сильные и слабые стороны своего кода. Все книги по C++ в то время обязательно описывали одну из вариаций умных указателей в мельчайших деталях.
Сейчас нам дан стандарт, и это хорошо. Но с другой стороны, уже не требуется понимать что там внутри, вместо этого достаточно три раза повторить мантру "используйте умные указатели везде где вы бы использовали обычные указатели", и это уже не так хорошо. Я подозреваю что далеко не все отдают себе отчет что данный стандарт — лишь один из возможных вариантов интерфейса, не говоря уже о разнице между реализациями различных вендоров. При выборе стандарта был сделан выбор между различными возможностями учитывающий разные факторы, но, оптимальный или нет, этот выбор очевидно не единственен.
А еще на stackoverflow например снова и снова задается вопрос — "потокобезопасны ли умные указатели из стандартной библиотеки?". Ответы даются обычно категоричные, но какие-то мало информативные. Если бы я например не знал о чем идет речь, то наверное бы не понял. И кстати, все сравнительно новые книги описывающие новый стандарт C++ этому вопросу тоже уделяют мало внимания.
Так давайте же попробуем сорвать покровы и разберемся с деталями.
Сразу определимся с терминологией, речь не идет о защите данных на которые ссылается указатель, это может быть обьект произвольной сложности и многопоточный доступ к нему требует в общем случае отдельной синхронизации. Под потокобезопасностью умного указателя мы подразумеваем защищенность собственно указателя на данные и валидности внутреннего счетчика ссылок. Образно говоря, если указатели создаются через std::make_shared<>() то никакие присвоения, передача в функции или другие потоки, свопы, уничтожение, не могут привести его в невалидное состояние. До тех пор пока мы не вызвали reset() или get(), мы вправе ожидать что указатель ссылается на некоторый валидный обьект, хотя и не обязательно тот на который мы подразумеваем.
Один из популярных ответов на вопрос заголовка: "It is only the control block itself which is thread-safe.". Вот мы и посмотрим, что понимается конкретно под control block и под safe.
Для экспериментов использовался g++-5.4.0.
Начнем с примера
Пусть в разделяемой памяти находится некоторая информация упакованная в структуру и доступная через указатель. Есть один или множество независимых потоков, которые должны читать и использовать эти данные без модификации, как правило оказывается что для них критически важна скорость доступа. В то же время, пусть существует один или несколько потоков модифицирующих эти данные с нарушением целостности, на практике обычно оказывается что модификации случаются значительно реже и скорость доступа там не настолько важна. Тем не менее, оставаясь в рамках классической (exclusive lock) синхронизации, мы вынуждены сериализовать доступ на чтение даже если если ни одного изменения данных не произошло. Естественно, на эффективности это отражается самым фатальным образом, и эта ситуация встречается настолько часто, возможно в несколько иной версии, что я бы ее рискнул назвать основным вопросом многопоточного программирования.
Конечно существуют стандартные решения, boost::shared_mutex и его юный отпрыск std::shared_mutex, позволяющие два уровня доступа — разделяемый на чтение и исключительный на запись. Однако же я, прослышав что std::shared_ptr дает потокобезопасный доступ к контрольному блоку (и не очень понимая что это значит), а так же что операции над ним реализованы lock-free, хочу предложить свое изящное решение:
// разделяемые данные std::shared_ptr<SHARED_DATA> data; reading_thread { // создаем резервную ссылку на разделяемые данные auto read_copy=data; // читаем данные, целостность гарантирована ... // деструктор read_copy } writing thread { // создаем измененную копию данных auto update=std::make_shared<SHARED_DATA>(...args); // атомарно(?) обновляем данные data=update; // ссылка на старые данные теряется, но обьект будет уничтожен // в памяти только когда последний читатель закончит цикл чтения }
здесь нам приходится пересоздавать структуру с данными каждый раз при любом обновлении, однако это достаточно приемлемый случай на практике.
Ну так что, сработает? Разумеется нет! Но почему именно?
Как оно устроено
Если взглянуть на саму структуру разделяемого указателя
/usr/include/c++/5/bits/shared_ptr_base.h: 1175
template<typename _Tp, _Lock_policy _Lp> class __shared_ptr { ... private: _Tp* _M_ptr; // Contained pointer. __shared_count<_Lp> _M_refcount; // Reference counter. };
видно, что она состоит из двух членов — указателя на собственно данные и того самого контрольного блока. Но дело в том, что не существует способа атомарно и без блокирования поменять, присвоить, переместить и т.д. оба элемента. То есть разделяемые указатели потоко безопасными быть не могут(.?) Точка или вопросительный знак? Ну вроде бы точка, но какая-то расплывчатая, не окончательная, как-то это тривиально и слишком просто. Нам же было сказано что "потоко безопасен только доступ к контрольному блоку", а мы и не проверили.
Давайте разбираться, роем глубже
auto data=std::make_shared<int>(0); void read_data() { // имитация чтения, создается резервная копия данных for(;;) auto read_copy=data; } int main() { std::thread(read_data).detach(); // имитация записи, весь указатель целиком заменяется другим for(;;) data=std::make_shared<int>(0); return 0; }
Вот такой минималистский пример реализует предложенную идею и в общем оправдывает ожидания — валится с грохотом едва намотав несколько сотен циклов. Однако обратите внимание, к собственно данным мы здесь вообще ни разу не обращаемся, указатель не разыменовывается. То есть что-то неладное происходит с контрольным блоком? Зато у нас теперь есть код с которым можно работать дебаггером. Но сначала бросим взгляд на другие возможные варианты:
auto data=std::make_shared<int>(0); void read_data() { for(;;) auto sp=std::atomic_load(&data); } int main(int argc, char**argv) { std::thread(read_data).detach(); for(;;) { std::atomic_exchange(&data, std::make_shared<int>(0)); assert(std::atomic_is_lock_free(&data)); } return 0; }
здесь все прекрасно работаетло бы если бы не assert() в теле цикла. То есть атомарные операции над std::shared_ptr определены, но они блокирующие. Ну, это не наш путь, на мьютексах я и сам могу. Еще один вариант:
std::shared_ptr<int> variant[]={ std::make_shared<int>(0), std::make_shared<int>(0) }; auto data=variant[0]; void read_data() { for(;;) auto sp=data; } int main() { std::thread(read_data).detach(); for(size_t n=0;; ++n) { data=variant[n%2]; } return 0; }
почти идентичный, но он прекрасно работает полностью загружая два ядра под 100%. Разница в том что здесь один из потоков никогда не вызывает деструктор. Что же, деструкторы стандартных указателей небезопасны? Не верю. Давайте вернемся к первоначальному варианту и
Копнем еще поглубже
Рассмотрим поближе читающий поток:
auto sp=data;
Здесь вызываются в цикле копирующий конструктор и деструктор, и все.
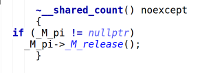
//L1#shared_ptr_base.h : 662 __shared_count(const __shared_count& __r) noexcept : _M_pi(__r._M_pi) { if (_M_pi != 0) _M_pi->_M_add_ref_copy(); } //L2#shared_ptr_base.h : 134 void _M_add_ref_copy() { __gnu_cxx::__atomic_add_dispatch(&_M_use_count, 1); } //L1#shared_ptr_base.h : 658 ~__shared_count() noexcept { if (_M_pi != nullptr) _M_pi->_M_release(); } //L2#shared_ptr_base.h : 147 if (__gnu_cxx::__exchange_and_add_dispatch(&_M_use_count, -1) == 1) { _GLIBCXX_SYNCHRONIZATION_HAPPENS_AFTER(&_M_use_count); _M_dispose(); }
которые, если отбросить все лишнее, сводятся к
// copy ctor __gnu_cxx::__atomic_add_dispatch(&_M_use_count, 1); // old instance dtor if (__gnu_cxx::__exchange_and_add_dispatch(&_M_use_count, -1) == 1) _M_dispose();
или, если перейти к псевдокоду
++_M_pi->_M_use_count; if(--_M_pi->_M_use_count == 0) dispose();
Здесь операторы инкремента и декремента подразумеваются атомарными, а функция dispose() очищает память и в частности инвалидирует сам указатель на счетчик ссылок _M_pi. Надо сказать что для привыкшего многопоточности выражение:
if(--cnt == 0)
do_something();
выглядит как граната с выдернутой чекой, между этими двумя строчками может произойти, и обязательно происходит, буквально что угодно. Единственно от чего такая конструкция надежно защищает — это от аналогичного вызова в другом потоке — сколько бы раз не был вызван атомарный оператор декремента, только в одном из них счетчик обнулится.
Тем не менее, что в это время происходит в другом, пишущем, потоке?
- вызывается конструктор нового обьекта. Это совершенно независимый обьект, поэтому нас никак не касается.
- создается еще один вырожденный указатель
- над этими тремя указателями вызывается классический циклический swap()
- вызывается деструктор временного указателя (содержащего теперь оригинальные данные)
- вызывается деструктор вырожденного указателя, нам это тоже ничем не грозит
//L1#shared_ptr.h : 291 shared_ptr& operator=(shared_ptr&& __r) noexcept { this->__shared_ptr<_Tp>::operator=(std::move(__r)); //L2#shared_ptr_base.h : 997 __shared_ptr& operator=(__shared_ptr&& __r) noexcept { __shared_ptr(std::move(__r)).swap(*this); //L#3shared_ptr_base.h : 932 __shared_ptr(__shared_ptr&& __r) noexcept : _M_ptr(__r._M_ptr), _M_refcount() { _M_refcount._M_swap(__r._M_refcount); //L#4shared_ptr_base.h : 684 void _M_swap(__shared_count& __r) noexcept { _Sp_counted_base<_Lp>* __tmp = __r._M_pi; __r._M_pi = _M_pi; _M_pi = __tmp; } //L2#shared_ptr_base.h : 1073 void swap(__shared_ptr<_Tp, _Lp>& __other) noexcept { std::swap(_M_ptr, __other._M_ptr); _M_refcount._M_swap(__other._M_refcount); } //L3#shared_ptr_base.h : 684 void _M_swap(__shared_count& __r) noexcept { _Sp_counted_base<_Lp>* __tmp = __r._M_pi; __r._M_pi = _M_pi; _M_pi = __tmp; } //L2#shared_ptr_base.h : 658 ~__shared_count() noexcept { if (_M_pi != nullptr) _M_pi->_M_release(); } //L3#shared_ptr_base.h : 142 void _M_release() noexcept { // Be race-detector-friendly. For more info see bits/c++config. _GLIBCXX_SYNCHRONIZATION_HAPPENS_BEFORE(&_M_use_count); if (__gnu_cxx::__exchange_and_add_dispatch(&_M_use_count, -1) == 1) { _GLIBCXX_SYNCHRONIZATION_HAPPENS_AFTER(&_M_use_count); _M_dispose(); //L1#shared_ptr.h : 93 (destructor) //L2#shared_ptr_base.h : 658 ~__shared_count() noexcept { if (_M_pi != nullptr) //_M_pi == nullptr - true here _M_pi->_M_release(); }
Если отбросить все лишнее останутся примерно такие фрагменты кода:
_Sp_counted_base<_Lp>* __tmp = __r._M_pi; __r._M_pi = _M_pi; _M_pi = __tmp; if (__gnu_cxx::__exchange_and_add_dispatch(&_M_use_count, -1) == 1) _M_dispose();
Опять же, первые три строчки (swap()) выглядят чрезвычайно подозрительными, однако при тщательном анализе они оказываются совершенно безопасными (естественно только в данном контексте) и все что нам остается (псевдокод).
if(--_M_pi->_M_use_count == 0) dispose();
то самое выражение, которое мы чуть выше сочли безопасным. Вот тут наступает момент истины:
// assert(_M_use_count == 1);
| // writing thread | // reading thread |
|---|---|
| if(--_M_pi->_M_use_count == 0) //true | . |
| . | ++_M_pi->_M_use_count; // count=1 |
| . | if(--_M_pi->_M_use_count == 0) //true |
| dispose(); // я первый! BANG!! | dispose(); // нет я! BANG!! |
Вот так комбинация атомарного инкремента и атомарного декремента приводит к гонке между потоками и std::shared_ptr<> не является потокобезопасным, даже на уровне контрольного блока. Вот теперь действительно точка.
Немного позже я нашел афористически краткое изложение этого принципа в документации к boost::shared_ptr<>. Звучит примерно так: "Указатели безопасны либо только на запись либо только на чтение, и небезопасны при конкурентном чтении/записи." Чуть развив эту мысль и сообразив что голая запись без чтения данных практически бессмысленна, мы видим что стандартные умные указатели безопасны на чтение, то есть настолько же насколько безопасны обычные константные указатели. То есть, вся эта сложная внутренняя машинерия создана для того чтобы достичь уровня обычных указателей, но не более, жирная точка.
Вместо заключения. От анализа к синтезу
Хотелось бы закончить на светлой ноте, то есть предложить, хотя бы на уровне концепции, алгоритм не использующий блокирующих мьютексов и позволяющий безопасные операции с разделяемыми указателями из разных потоков. Однако я не справился, более того, у меня сложилось убеждение что на основе существующих элементарных неблокирующих примитив это просто невозможно. Разумеется достаточно просто написать вариант основанный на spinlock, однако это было бы неспортивно, я не отношу такие алгоритмы к истинно неблокирующим. Можно взять за основу любую существующую многопоточную блокирующую реализацию и заменить каждый мьютекс на соответствующий spinlock, то есть алгоритмически свести задачу к выбору более эффективного типа мьютекса. Очевидно это не наш путь.
Чего же нам не хватает для полноценной неблокирующей реализации? Существует очень небольшое число неблокирующих примитив работающих только со встроенными типами:
- добавление целой константы (постфиксное или префиксное) — atomic_fetch_and_add и его вариации
- обмен двух значений (на самом деле несимметричный, только один из операндов изменяется атомарно) — atomic_swap
- условный обмен или присвоение с проверкой на равенство — atomic_compare_and_swap
Учитывая безусловный запрет на оператор if() в неблокирующих алгоритмах, только последний подходит на роль оператора ветвления, но его серьезнейшее ограничение в том что он позволяет проверку и присвоение исключительно одной и той же переменной. Вообще легко заметить нечто общее во всех трех примитивах — они атомарно работают с одной и только одной областью памяти размером с машинное слово, причины я думаю очевидны. Присмотревшись к обобщенной структуре разделяемого указателя, мы видим что он обязан содержать внутри себя как минимум один указатель на разделяемые данные (включающие контрольный блок) и где-то внутри этого блока должен находиться счетчик ссылок. При любых операциях с собственно указателем, например присвоении, мы должны атомарно проверять счетчик и одновременно изменять указатель на контрольный блок, что невозможно используя существующие атомарные примитивы. Отсюда следует что создание полноценного неблокирующего разделяемого указателя невозможно в принципе.
На самом деле я был бы рад ошибиться, возможно есть что-то, что я не знаю или понимаю неправильно? Всех желающих оспорить жду в комментариях.

