Много ядер не бывает
Атомарные операции (atomics), например, Compare-and-Swap (CAS) или Fetch-and-Add (FAA) широко распространены в параллельном программировании.
Мульти- или многоядерные архитектуры установлены одинаково как в продуктах настольных и серверных компьютеров, так и в крупных центрах обработки данных и суперкомпьютерах. Примеры конструкций включают Intel Xeon Phi с 61 ядрами на чипе, который установлен в Tianhe-2, или AMD Bulldozer с 32 ядрами на узле, развернутых в Cray XE6. Кроме того, количество ядер на кристалле неуклонно растет и процессоры с сотнями ядер, по прогнозам, будут изготовлены в обозримом будущем. Общей чертой всех этих архитектур является растущая сложность подсистем памяти, характеризующаяся несколькими уровнями кэш-памяти с разными политиками включения, различными протоколами когерентности кэш-памяти, а также различными сетевыми топологиями на чипе, соединяющими ядра и кэш-память.
Практически все такие архитектуры обеспечивают атомарные операции, которые имеют многочисленные применения в параллельном коде. Многие из них (например, Test-and-Set) могут быть использованы для реализации блокировок и других механизмов синхронизации. Другие, например, Fetch-and-Add и Compare-and-Swap позволяют строить разные lock-free и wait-free алгоритмы и структуры данных, которые имеют более прочные гарантии прогресса, чем блокировки на основе кода. Несмотря на их важность и повсеместное употребление, выполнение атомарных операций полностью не проанализировано до сих пор. Например, по общему мнению, Compare-and-Swap идет медленнее, чем Fetch-and-Add. Тем не менее, это всего лишь показывает, что семантика Compare-and-Swap вводит понятие «wasted work», в результате – более низкая производительность некоторого кода.
Compare-and-Swap
Вспомним, что из себя представляет CAS (в процессорах Intel он осуществляется группой команд cmpxchg) – Операция CAS включает 3 объекта-операнда: адрес ячейки памяти (V), ожидаемое старое значение (A) и новое значение (B). Процессор атомарно обновляет адрес ячейки (V), если значение в ячейке памяти совпадает со старым ожидаемым значением(A), иначе изменения не зафиксируется. В любом случае, будет выведена величина, которая предшествовала времени запроса. Некоторые варианты метода CAS просто сообщают, успешно ли прошла операция, вместо того, чтобы отобразить само текущее значение. Фактически, CAS только сообщает: «Наверное, значение по адресу V равняется A; если так оно и есть, поместите туда же B, в противном случае не делайте этого, но обязательно скажите мне, какая величина — текущая.»
Самым естественным методом использования CAS для синхронизации будет чтение значения A со значением адреса V, проделать многошаговое вычисление для получения нового значения B, и затем воспользоваться методом CAS для замены значения параметра V с прежнего, A, на новое, B. CAS выполнит задание, если V за это время не менялось. Что, собственно говоря, наблюдается в JDK 7:
public final int incrementAndGet() { for (;;) { int current = get(); int next = current + 1; if (compareAndSet(current, next)) return next; } } public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); }
Где сам метод — unsafe.compareAndSwapInt является native, выполняется на процессоре атомарно и на ассемблере выглядит следующим образом, если включить распечатку ассемблерного кода:
lock cmpxchg [esi+0xC], ecx
Инструкция выполняется следующим образом: читается значение из области памяти, указанное первым операндом и блокировка шины после чтения не снимается. Затем происходит сравнение значения по адресу памяти с регистром eax, где хранится ожидаемое старое значение, и если они были равны, то процессор записывает значение второго операнда (регистр ecx) в область памяти, указанную первым операндом. По завершении записи блокировка шины снимается. Особенности x86 в этом, что запись происходит в любом случае, за тем небольшим исключением, что если значения были не равны, то в область памяти заносится значение, которое было получено на этапе чтения из этой же области памяти.
Таким образом мы получаем работу в цикле с проверкой переменной, причем которая может окончиться неудачей и всю работу в цикле до проверки необходимо начинать заново.
Fetch-and-Add
Fetch-and-Add работает проще и не содержит никаких циклов (в архитектуре Intel осуществляется группой команд xadd). Также он включает 2 объекта-операнда: адрес ячейки памяти (V) и значение (S), на которое следует увеличить старое значение, хранимое по адресу памяти (V). Так, FAA можно описать в таком виде: получить значение, располагаемое по указанному адресу (V) и сохранить его временно. Затем в указанный адрес (V) занести сохраненное ранее значение, увеличенное на значение, которое из себя представляет 2 объект-операнд (S). Причем, все указанные выше операции выполняются атомарно и реализованы на аппаратном уровне.
В JDK 8 код выглядит так:
public final int incrementAndGet() { return unsafe.getAndAddInt(this, valueOffset, 1) + 1; } public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
«Ноо, — скажете Вы, — чем данная реализация отличается от 7 версии»?
Тут приблизительно такой же цикл и все выполняется схожим образом. Однако, тот код, который вы видите и написан на Java не выполняется в конечном итоге на процессоре. Тот код, который связан с циклом и установкой нового значения заменяется в конечном итоге на одну операцию ассемблера:
lock xadd [esi+0xC], eax
Где, соответственно, в регистре eax хранится значение, на которое нужно будет увеличить старое значение, хранимое по адресу [esi+0xC]. Повторюсь, все выполняется атомарно. Но такой фокус сработает, если у Вас 8 версия JDK, иначе выполнится обычный CAS.
Что бы я еще хотел бы добавить...
Хочу тут отметить, что здесь упоминается протокол MESI, о котором можно почитать в очень хорошем цикле статей: Lock-free структуры данных. Основы: откуда пошли быть барьеры памяти.
Спасибо kmu1990 за уточнение перевода с англ.
- CAS является «оптимистичным» алгоритмом и допускает невыполнение операции, в то время как FAA нет. У FAA нет явной лазейки в виде уязвимости из-за удаленного вмешательства, следовательно, нет необходимости в цикле для повторных попыток.
- Если вы применяете стандартный CAS подход, предполагая, что ваша система использует наиболее популярную реализацию когерентности через snoop-base или «подслушивание», то это может вызвать read-to-share транзакцию, чтобы получить основную строку кэша или состояние E. CAS операция, по сути, переводит кэш линию в состояние M (Modified), для чего может потребоваться дополнительная транзакция. Таким образом, в самом худшем случае стандартный CAS подход может подвергнуть шину двум транзакциям, но реализация Fetch-And-Add будет стремиться провести передачу линии непосредственно до M состояния. В процессе вы бы могли спекулировать значениями и получать короткий путь без предварительных загрузок, как это пытается получить «голый» CAS. К тому же, это возможно при сложных реализациях процессора для выполнения согласованных операций и целевого исследования линии в M состоянии. Наконец, в некоторых случаях можно успешно вставить инструкцию предвыборки-для-записи (PREFETCHW) перед выполнением операций, чтобы избежать транзакции обновления. Но этот подход должен быть применен с особым вниманием, так как в некоторых случаях это может принести больше вреда, чем пользы. Учитывая все это, FAA, где это возможно, имеет преимущество. Другими словами (спасибо за подсказку jcmvbkbc) — что для того, чтобы сделать CAS нужно загрузить старое значение из памяти, что даёт два обращения к памяти, а чтобы сделать xadd старое значение загружать не нужно, и обращение к памяти нужно только одно.
- Допустим, вы пытаетесь увеличить переменную (например, инкрементировать) с помощью CAS цикла. Когда CAS начинает сбиваться достаточно часто, можно обнаружить, что ветвь для выхода из цикла (обычно возникает при отсутствии или легкой нагрузке) начинает прогнозировать ошибочные пути, которые прогнозируют нам, что мы останемся в петле. Поэтому, когда CAS в конечном счете достигнет цели, вы словите branch mispredict (ошибочное предположение ветви) при попытке выйти из цикла. Это может быть болезненно на процессорах с глубоким конвейером и привести к целому вороху out-of-order (внеочередные исполнения) спекуляций машины. Как правило, вы не хотите, чтобы этот кусок кода приводил к потерям скорости. В связи с выше сказанным, когда CAS начинает часто терпеть неудачу, ветвь начинает прогнозировать, что управление остается в цикле и в свою очередь, цикл работает быстрее за счет удачного предсказания. Как правило, мы хотим некоторого back-off в цикле. И при легкой нагрузке с нечастыми неудачами branch mispredict служит в качестве потенциального неявного back-off. Но при более высокой нагрузке мы теряем преимущество back-off, вытекающих из branch mispredict. У FAA нет циклов и никаких проблем.
Тесты
Ну и напоследок я написал простенький тест, который иллюстрирует работу атомарного инкрементирования в JDK 7 и 8:
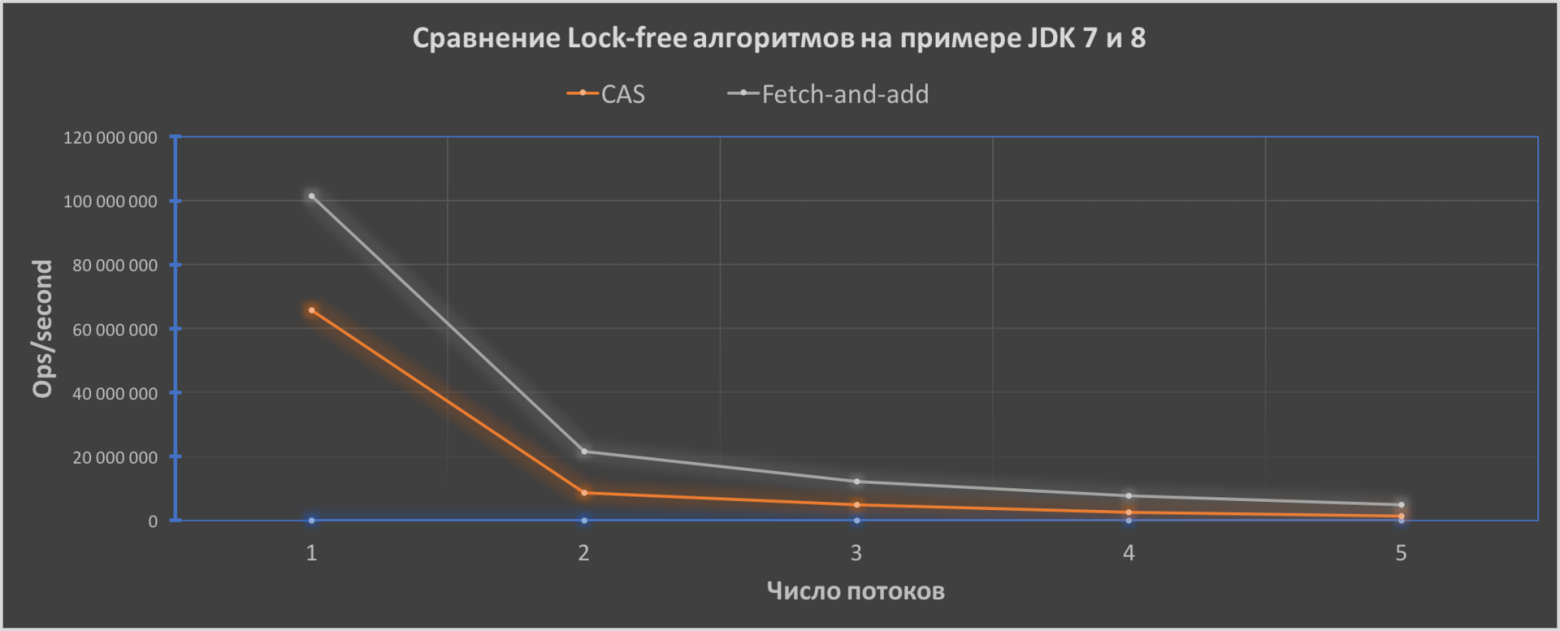
Как мы видим, производительность кода у FAA будет лучше и его эффективность увеличивается с увеличением числа потоков от 1.6 раза до приблизительно 3.4 раза.
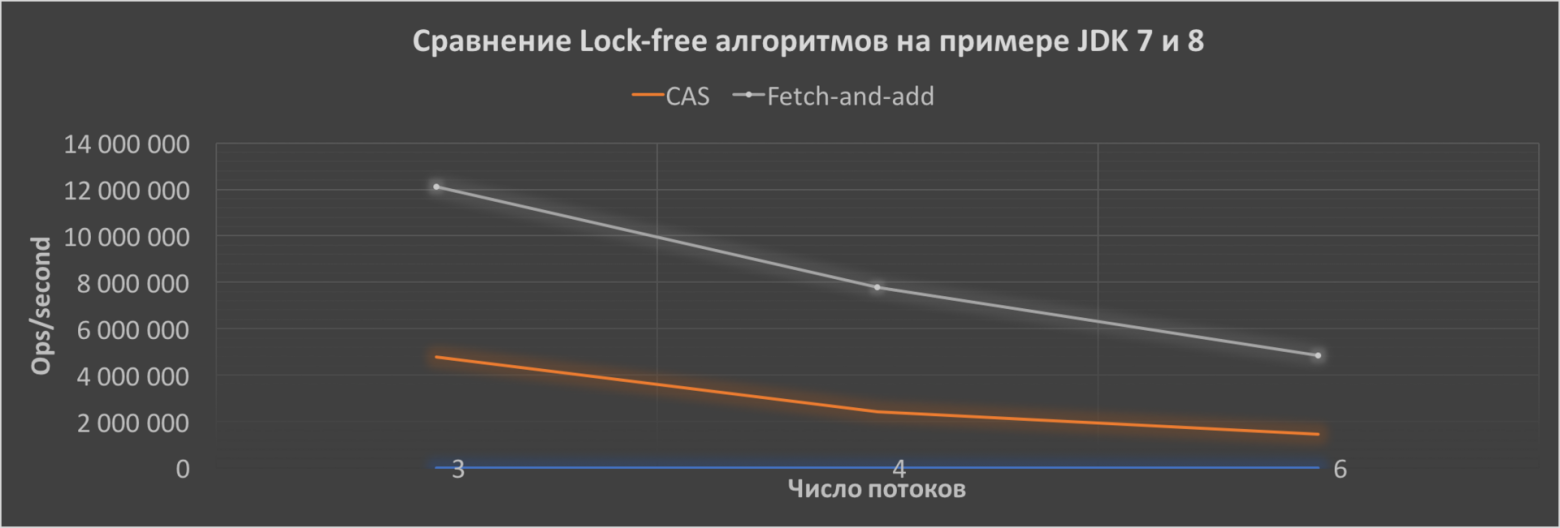
Версии Java для тестов: Oracle JDK7u80 и JDK8u111 — 64-Bit Server VM. CPU — Intel Core i5-5250U поколения Broadwell, OS — macOS Sierra 10.12.2, RAM — 8-Gb.
Ну и если интересно, ссылка на код теста — исходники теста.
Жду замечаний, улучшений и прочее.

