В прошлый раз мы пришли к выводу, что для эффективной работы пространственного индекса на основе Z-order необходимо сделать 2 вещи:
- эффективный алгоритм получения подинтервалов
- низкоуровневую работу с B-деревом
Вот именно этим мы и займёмся под катом.
Начнём с более интересного, алгоритма.
Разбиение на подзапросы
Будем рассматривать 2-мерный алгоритм (индексация точек) в силу его относительной простоты. Впрочем, на большие размерности алгоритм легко обобщается.
Сейчас мы (также для простоты) будем использовать неотрицательные целочисленные координаты. Координаты ограничены 32 битами, поэтому значение ключа индекса можно хранить в uint64
Нам понадобятся следующие простые свойства z-нумерации:
- Пусть на плоскости отмечен некий прямоугольник. Тогда среди всех точек прямоугольника наименьший z-номер имеет левый нижний угол прямоугольника (будем называть его “z”), а наибольший – правый верхний угол (его назовём “Z”). Данное свойство очевидным образом следует из способа построения z-номера.
- Всякий прямоугольник можно разделить единственным образом на два прямоугольника (вертикальным или горизонтальным разрезом) так, что все z-номера первого прямоугольника меньше всех z-номеров второго. Это следует из самоподобия Z-кривой. Элементарная ячейка из четырех клеток делится пополам, затем еще пополам двумя разрезами, то же самое происходит на всех уровнях иерархии.
Как именно необходимо разрезать экстент, чтобы сохранить свойство непрерывности подинтервалов?
Из самоподобия кривой следует, что разрезать можно только по решетке с шагом в степень двойки и с узлом в начале координат.
Но какую конкретно решетку из доступных 64 выбрать? Это довольно просто. Разрезаемый экстент должен занимать в искомой решетке больше одной клетки, иначе просто нечего разрезать. С другой стороны, по любой из координат размер не может превышать 2 клетки, а по крайней мере по одной должен быть строго 2 клетки. Если по обеим размерностям разрезаемый экстент занимает 2 клетки, резать будем по той координате, чей разряд в построении Z-значения старший.
Как же найти такую решетку? Это тоже несложно. Достаточно сравнить Z-значения углов z и Z. Начнем сравнивать со старших разрядов и найдём разряд, где их значения разошлись. Вот и искомая решетка.
Как осуществить разрез? Тут необходимо вспомнить метод построения Z-значения, а именно то, что x&y координаты чередуются через разряд. Следовательно:
- Пусть различие между z и Z началось в разряде m
- Разрезать будем по одной координате, на которую пришлось m, независимо от того, x это или y, пусть в данном случае это x, впрочем, для y всё работает точно так же
- Из экстента (x0,y0,x1,y1) мы должны получить два: (x0,y0,x2-1,y1),(x2,y0,x1,y1)
- А для того, чтобы получить x2 достаточно обнулить все разряды x координаты младше m, т.е. через один
- x2-1 получается обнулением бита m и присвоением 1 всем младшим x разрядам
Итак, как же выглядит алгоритм генерации подзапросов? Довольно незатейливо:
- Заводим очередь подзапросов, изначально в этой очереди один единственный элемент — искомый экстент
- Пока очередь не пуста:
- Достаем элемент с вершины очереди
- Если для этого запроса не срабатывает критерий остановки
- Получаем z и Z — значения для его углов
- Сравниваем z и Z — находим разряд m, по которому будем резать
- Вышеописанным способом получаем два подзапроса
- Помещаем их в очередь, сначала тот, что с бОльшими Z-значениями, затем второй
Такой способ гарантирует нам генерацию подзапросов, при котором Z-значения финальных (т.е. те, на которых сработал критерий остановки) подзапросов только лишь возрастают, пробросов назад не возникает.
Критерий остановки
Он очень важен, если им пренебречь, генерация подзапросов продолжится до тех пор, пока всё не будет порезано на единичные квадратики.
Стоит отметить, что при выработке такого критерия мы не можем полагаться лишь на параметры запроса, площади, геометрические свойства … В реальных данных распределение точек может быть весьма неравномерны, например, города и пустые пространства. Населенность площадей нам заранее неизвестна.
Значит необходима интеграция с поиском в дереве индекса, который, как мы помним, B-дерево.
Как выглядит подзапрос с точки зрения индекса? Это совокупность данных, расположенных на некотором числе страниц. Если подзапрос пуст, то и интервал данных пуст, но тем не менее куда-то смотрит, т.к. чтобы понять что данных нет, надо попытаться их прочитать и спуститься с вершины дерева до листовой страницы. Может так случиться, что пустой запрос смотрит и за пределы дерева.
Вообще, процесс вычитывания данных подзапроса состоит из двух фаз —
- Зондирование дерева. Начиная с корневой страницы мы ищем ключ меньше или равный Z-значению левого нижнего угла подзапроса (z) и так спускаемся до листовой страницы. На выходе получаем стек страниц и листовую страницу “в воздухе”. На этой странице ищем элемент больше или равный искомому.
- Чтение вперед до конца подзапроса. В PostgreSQL листовые страницы B-дерева связаны списком, если бы этого не было, для того, чтобы получить следующую страницу пришлось бы подняться вверх по стеку страниц, чтобы затем спуститься на неё.
Итак, после зондирующего запроса у нас в руках листовая страница, на которой предположительно начинаются наши данные. Возможны разные ситуации:
- Найденный элемент страницы больше правого верхнего угла подзапроса (Z). Т.е. данных нет.
- Найденный элемент страницы меньше Z, последний элемент страницы меньше Z. Т.е. подзапрос начинается на этой странице, заканчивается где-то дальше.
- Найденный элемент страницы меньше Z, последний элемент страницы больше Z. Т.е. весь подзапрос расположен на этой странице.
- Найденный элемент страницы меньше Z, последний элемент страницы равен Z. Т.е. подзапрос начинается на этой странице, но возможно заканчивается на следующей (несколько элементов с одними координатами). А может и сильно дальше, если дубликатов много.
Вариант N1 не требует никаких действий. Для N2 естественным представляется следующий критерий остановки (расщепления подзапросов) — будем разрезать их до тех пор, пока не получим варианты 3 или 4. С вариантом N3 всё очевидно, в случае N4 страниц с данными может быть несколько, но разрезать подзапрос бессмысленно т.к. на последующей странице(цах) могут быть только данные с ключом равным Z, после разреза мы окажемся в той же самой ситуации. Чтобы справиться с этим, достаточно просто считать со следующей(щих) страниц все данные с ключом равным Z. Их может и не быть, вообще, N4 — это достаточно экзотический случай.
Работа с B-деревом
Низкоуровневая работа с B-деревом не представляет особых трудностей. Но придётся создать расширение. Общая логика такова — зарегистрируем SRF функцию:
CREATE TYPE __ret_2d_lookup AS (c_tid TID, x integer, y integer); CREATE FUNCTION zcurve_2d_lookup(text, integer, integer, integer, integer) RETURNS SETOF __ret_2d_lookup AS 'MODULE_PATHNAME' LANGUAGE C IMMUTABLE STRICT;
Которая на вход получает имя индекса и экстент. А возвращает набор элементов, в каждом из которых указатель на строку таблицы и координаты.
Доступ к собственно дереву происходит так:
const char *relname; /* внешний параметр */ ... List *relname_list; RangeVar *relvar; Relation rel; ... relname_list = stringToQualifiedNameList(relname); relvar = makeRangeVarFromNameList(relname_list); rel = indexOpen(rel); ... indexClose(rel);
Получение корневой страницы:
int access = BT_READ; Buffer buf; ... buf = _bt_getroot(rel, access);
В целом, поиск в индексе сделан подобно обычному поиску в B-дереве (см postgresql/src/backend/access/nbtree/nbtsearch.c). Изменения связаны со спецификой ключа, возможно, можно было обойтись и без нее, пусть это было бы и чуть медленнее.
Поиск внутри страницы выглядит так:
Page page; BTPageOpaque opaque; OffsetNumber low, high; int32 result, cmpval; Datum datum; bool isNull; ... page = BufferGetPage(buf); opaque = (BTPageOpaque) PageGetSpecialPointer(page); low = P_FIRSTDATAKEY(opaque); high = PageGetMaxOffsetNumber(page); ... тут идёт бинарный поиск ... /* для листовой страницы возвращаем найденное значение */ if (P_ISLEAF(opaque)) return low; /* для промежуточной - предыдущий элемент */ return OffsetNumberPrev(low);
Получение элемента страницы:
OffsetNumber offnum; Page page; Relation rel; TupleDesc itupdesc = RelationGetDescr(rel); IndexTuple itup; Datum datum; bool isNull; uint64 val; ... itup = (IndexTuple) PageGetItem(page, PageGetItemId(page, offnum)); datum = index_getattr(itup, 1, itupdesc, &isNull); val = DatumGetInt64(datum);
Итоговый алгоритм
- Заводим очередь подзапросов, изначально в этой очереди один единственный элемент — искомый экстент
- Пока очередь не пуста:
- Достаем элемент с вершины очереди
- Выполняем зондирующий запрос в индексе для z (левого нижнего угла). В целях экономии, можно делать зондирование не каждый раз, а только если последнее найденное значение (которое изначально 0) больше или равно z
- В случае, если найденное минимальное значение превышает Z (правый верхний угол), заканчиваем обработку этого подзапроса, переходим на П.2
- Проверяем последний элемент листовой страницы B-дерева, на которой остановился зондирующий запрос
- Если он больше или равен Z, выбираем элементы страницы, фильтруем их на предмет принадлежности поисковому экстенту и запоминаем результирующие точки.
- Если он равен Z, читаем индекс вперед до полного исчерпания ключей со значением равным Z и тоже запоминаем их
- В противном случае — последнее значение страницы меньше Z
- Сравниваем z и Z — находим разряд m, по которому будем резать
- Вышеописанным способом получаем два подзапроса
- Помещаем их в очередь, сначала тот, что с бОльшими Z-значениями, затем второй
Предварительные результаты
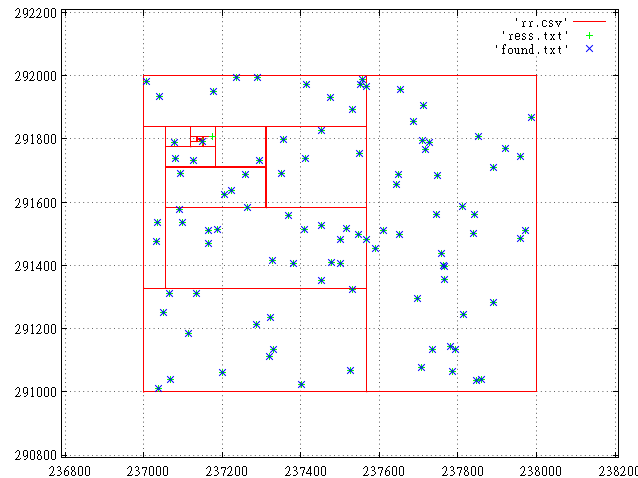
В заглавной иллюстрации статьи представлено разбиение реального запроса на подзапросы и результирующие точки. Показано сравнение найденных R-деревом результатов с полученными вышеописанным алгоритмом. Картинка времен отладки и видно, что одной точки не хватает.
Но картинки — картинками, а хочется увидеть сравнение производительности. С нашей стороны будет та же таблица:
create table test_points (x integer,y integer); COPY test_points from '/home/.../data.csv'; create index zcurve_test_points on test_points(zcurve_val_from_xy(x, y));
И запросы типа:
select count(1) from zcurve_2d_lookup('zcurve_test_points', 500000,500000,501000,501000);
Сравнивать будем с R-деревом как со стандартом de facto. Причем, в отличие от прошлой статьи, нам нужен “index only scan” по R-дереву т.к. наш Z-индекс больше не обращается к таблице.
create table test_pt as (select point(x,y) from test_points); create index test_pt_idx on test_pt using gist (point); vacuum test_pt;
На таких данных запрос:
explain (analyze, buffers) select * from test_pt where point <@ box( point(500000, 500000), point(510000, 510000));
выдаёт:
QUERY PLAN --------------------------------------------------------------------------------------------- Index Only Scan using test_pt_idx on test_pt (cost=0.42..539.42 rows=10000 width=16) (actual time=0.075..0.531 rows=968 loops=1) Index Cond: (point <@ '(510000,510000),(500000,500000)'::box) Heap Fetches: 0 Buffers: shared hit=20 Planning time: 0.088 ms Execution time: 0.648 ms (6 rows)
что и требовалось.
Собственно сравнение:
| Тип запроса | Тип индекса | Время мсек. | Shared reads | Shared hits |
|---|---|---|---|---|
| 100Х100 ~1 точка |
R-tree Z-curve |
0.4* 0.34* |
1.8 1.2 |
3.8 3.8 |
| 1000Х1000 ~100 точек |
R-tree Z-curve |
0.5...7** 0.41* |
6.2 2.8 |
4.9 37 |
| 10000Х10000 ~10000 точек |
R-tree Z-curve |
4...150*** 6.6**** |
150 43.7 |
27 2900 |
** — данные получены при усреднении серии разной длины, 10 000 vs 100 000
*** — данные получены при усреднении серии разной длины, 1 000 vs 10 000
**** — данные получены при усреднении серии длины 10 000
Замеры проводились на скромной виртуальной машине с двумя ядрами и 4 Гб ОЗУ, поэтому времена не имеют абсолютной ценности, а вот числам прочитанных страниц можно доверять.
Времена показаны на вторых прогонах, на разогретом сервере и виртуальной машине. Количества прочитанных буферов — на свеже-поднятом сервере.
Выводы
- во всяком случае на маленьких запросах Z-индекс работает быстрее R-дерева
- и читает при этом заметно меньше страниц
- R-дерево намного раньше начинает массово промахиваться мимо кэша
- при этом и сам Z-индекс вчетверо компактнее, так что для него кэш работает более эффективно
- причем, не исключено, что промахи идут и мимо дискового кэша хост-машины, иначе трудно объяснить такую разницу
Что дальше
Рассмотренный двумерный точечный индекс предназначен лишь для проверки концепции, в жизни он мало-полезен.
Даже для трехмерного индекса 64-разрядного ключа уже не хватает (или впритык) для полезной разрешающей способности.
Так что впереди будет:
- переход на другой ключ, numeric
- 3D вариант, в том числе точки на сфере
- проверка возможности работы с кривой Гильберта
- полноценные замеры
- 4D вариант — прямоугольники
- 6D вариант — прямоугольники на сфере
- ...
PS: Исходники выложены здесь с лицензией BSD, описанное в данной статье соответствует ветке “raw-2D”
PPS: Алгоритм как таковой был разработан в стародавние времена (2004-2005 гг) в соавторстве с Александром Артюшиным.
PPPS: Огромное спасибо ребятам из PostgresPro за то, что сподвигли меня на внедрение данного алгоритма в PostgreSQL.
PPPPS: Продолжение здесь

