
Роман Гребенников объясняет сложность построения распределённых систем. Это — доклад Highload++ 2016.
Всем привет, меня зовут Гребенников Роман. Я работаю в компании Findify. Мы делаем поиск для онлайн-магазинов. Но разговор не об этом. В компании Findify я занимаюсь распределенными системами.
Что же такое распределённые системы?

Из слайдов понятно, что «страх и ненависть» — это обычное дело в IT, а распределённые системы — не совсем обычное. Мы попытаемся понять вначале, что такое распределённые системы, почему тут такая боль, и почему нужен этот доклад.
Представим, что у вас есть какое-то приложение, которое где-то там работает. Допустим, оно серверное, но отличается оно от обычных приложений тем, что у него есть какое-то внутреннее состояние. Например, у вас есть игра, внутреннее состояние — это мир, где человечки набегают и прочее. Рано или поздно вы растёте, и ваше внутреннее состояние всё пухнет, оно изменяется и перестаёт помещаться на один сервер.

Тут на картинке Винни-Пух застрял в норе.
Если вы начали расти и перестали помещаться в один сервер, то надо что-то делать.
У вас есть несколько вариантов.
Вы можете взять сервер помощнее, но это может быть тупиковый путь, потому что вы возможно уже работаете на самом быстром сервере, который есть.
Мы можете оптимизировать, но что — непонятно, по щелчку всё ускорить в два раза тяжело.
Вы можете встать на очень шаткую дорожку – создание распределенных систем.
Эта дорожка шаткая и страшная.
О чём я буду сегодня рассказывать
Сначала мы поговорим, что такое распределенные системы. Немного матчасти, почему это важно, что такое целостность, как эту целостность причёсывать, какие есть подходы к проектированию распределённых систем, которые данные не теряют или теряют их совсем чуть-чуть, какие есть инструменты для проверки ваших распределенных систем на то, что у вас всё хорошо с данными или почти всё хорошо.
Поскольку одна теория — это скучно, мы поговорим немножко по делу и немножко практики. Мы возьмём вот этот ноутбук и напишем свою маленькую простенькую распределенную базу данных. Не совсем базу данных, там будет не key value хранилище, а value хранилище. Потом попробуем доказать, что она не теряет данные, причем неоднократно и в особо страшных позах.
Дальше немного философии «как с этим жить».
Мы представляем, что распределённые системы – это такие штуки, которые работают где-то далеко, а мы сидим все здесь. Это могут быть сервера, это могут быть мобильные приложения, которые друг с другом общаются, у них есть какое-то внутреннее состояние. Если вы со своими друзьями переписываетесь по смс, то вы тоже часть распределенной системы, у вас есть общее состояние, о чём вы пытаетесь договориться. В общем случае распределённая система — это такая шутка, которая состоит из нескольких частей, и эти части общаются друг с другом. Но всё усложняется тем, что они общаются с задержками и с ошибками. Это всё сильно усложняет.
Небольшой пример из жизни.
Мы однажды писали веб-паук, который ходил по Интернету, скачивал всякие разные странички. У него была большая очередь задач, мы туда наваливали все. У нас есть несколько базовых операций у очереди. Это что-то взять из очереди, что-то положить в очередь. Также у нас была третья операция для очереди: проверить есть ли объект в очереди, чтобы два раза одно и тоже туда не класть.
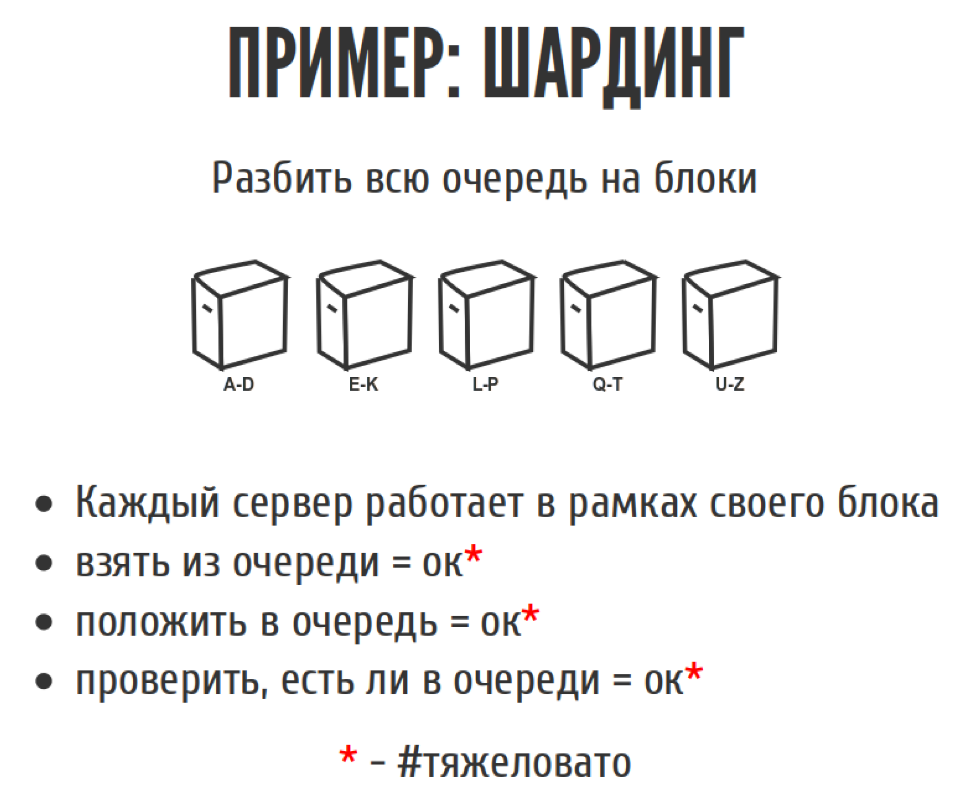
Проблема была в том, что очередь была довольно большая, и в память она не помещалась. Мы подумали: что здесь сложного? Мы же умные, на HighLoad ходим. Поэтому давайте эту очередь разрежем на кусочки, раскатаем на разные сервера. Каждый сервер будет заниматься своим кусочком очереди. Да, мы немножечко потеряем в целостности, в том плане что мы не сможем взять самый первый элемент из очереди, но мы сможем взять почти самый первый. Просто выбрав случай шард, взяв из него, и всё хорошо. То есть если взять из очереди, почти всё хорошо, чуть-чуть стала сложнее логика. Положить в очередь — тоже всё просто, мы смотрим, в какой шард класть, и кладём. Проверить, есть ли в очередь, тоже никаких проблем. Да, бизнес-логика стала чуть-чуть сложнее, но, по крайней мере, она стала некритичной, и крови здесь вроде как никакой нет.
Какие могут быть проблемы
Мы понимаем, что если у нас добавилось какое-то сетевое взаимодействие, и у нас стало больше компонентов, то у системы стала меньше надежность. Если меньше надёжность, то обязательно что-нибудь пойдёт не так. Если с софтом и железом, всё понятно. С железом можно взять сервера побрендовее, с софтом — не деплоить по пьяни в пятницу. А с сетью, такая штука, ломается независимо от того, что вы с ней делаете. У Microsoft есть отличная статья со статистикой отказа сетевого оборудования в зависимости от типа коммутатора в Windows Azure. Вероятность того, что порт load balancer крякнет в течение года, порядка 17%. То есть если вы не предусматриваете что делать в случае отказа, то вы рано или поздно хлебнёте кого-нибудь добра.
Самая популярная проблема, которая случается с сетью – это NETSPLIT. Когда ваша сеть развалилась пополам, либо она постоянно развалилась, либо у вас потеря пакетов. В результате этого она то развалилась, то не развалилась.
Что же будет у нас с очередью на шардинге, если у нас проблемы с сетью?
Если что-то взять из очереди, если мы готовы взять не самый первый элемент из очереди, то мы можем просто брать из тех шардов, которые нам доступны, и как-то дальше жить.
Если нам нужно проверить, есть ли компонент в очереди, то тут всё усложняется тем, что если нам нужно зайти на тот шард, который нам недоступен, то мы ничего не можем сделать.
Но всё усложняется с тем, когда нам нужно что-то в очередь положить, а шард недоступен. Нам деть это некуда, потому что тот шард где-то далеко. Ничего не остается, кроме как это потерять, либо куда-то отложить и потом что-то с этим делать. Потому что мы не заложили отказы в дизайн системы.

На картине дядечка грустит. Потому что он не заложил отказы в дизайн системы. Мы-то умные, мы-то знаем, что наверняка есть другие дядечки, которые очень умные и придумали много разных вариантов, как с этой проблемой жить.
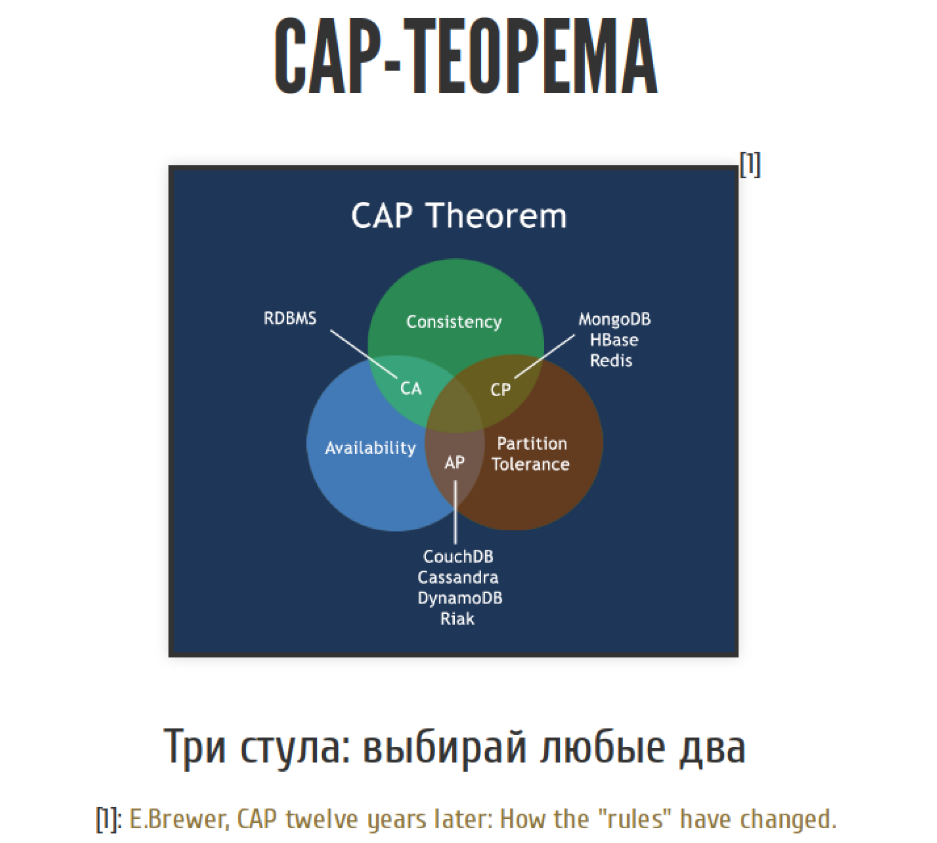
Тут на сцене появляется CAP-теорема.
CAP-теорема – это краеугольный камень проектирования распределённых систем. Это теорема, которая формально не теорема, а эмпирическое правило, но все её называют теоремой.
Звучит она следующим образом. У нас есть три кита создания распределённых систем. Это целостность, доступность и устойчивость к сетевым проблемам. У нас есть три кита, мы можем выбрать любые два. Причем не совсем любые два, почти любые два. Чуть позже мы об этом поговорим.
По порядку — что такое целостность, доступность и устойчивость. Это же вроде теорема, должны быть формальные описания.
Доступность
Это доступность (availability), и она подразумевает под собой постоянную доступность. Каждый запрос к системе, любой запрос к системе к любому живому узлу должен быть успешно обработан. То есть если мы часть запросов куда-то на потом откладываем, либо мы записи в сторонку откладываем, потому что у нас что-то пошло не так — это непостоянная доступность. Если не все узлы отвечают на запросы, или не на все запросы все узлы отвечают — это тоже непостоянная доступность с точки зрения CAP-теоремы.
Если оно у вас отвечает вот так:

Это тоже непостоянная доступность.
Целостность
Следующий пункт — это целостность. С точки зрения целостности вы можете сказать, что существует вот столько разных типов целостности в распределённых системах:
Их порядка 50-ти. Какой их из них в CAP-теореме?
В CAP-теореме самый строгий тип. Называется линеаризуемость.
Целостность, линеаризуемость. Звучит очень просто, но под собой имеет большие последствия. Если операция B началась после операции A, то B должна увидеть систему на момент окончания A или в более новом состоянии. То есть если A завершилась, то следующая операция не может видеть то, что было до A. Вроде бы всё логично, ничего сложного нет. Если переформулировать это другими словами: «Существует непротиворечивая история последовательных операций».
Сейчас мы поподробнее поговорим об этих историях.
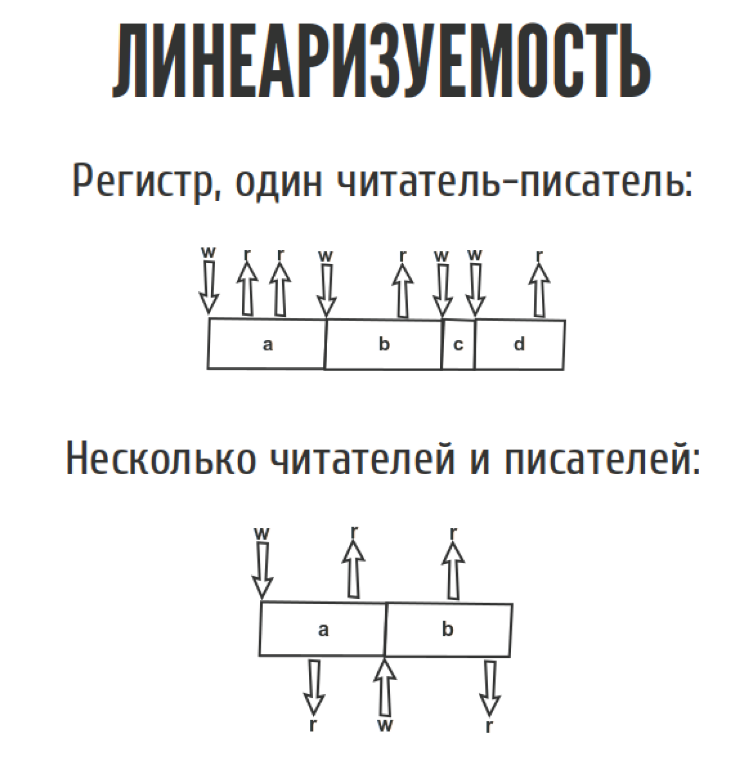
Представим, у нас есть какой-то регистр. Это то что мы можем прочитать, только то что мы до этого туда записали. Просто одна дырочка для переменной. У нас есть один читатель-писатель. Мы всё туда читаем-пишем, ничего сложного. Даже если у нас несколько читателей и писателей, тоже ничего сложного.
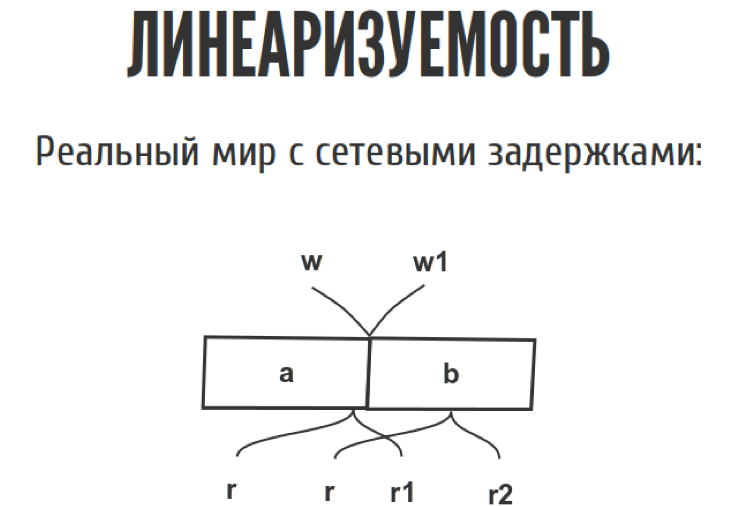
Но как только мы перемещаем из слайда в реальный мир, эта диаграмма выглядит немножко по-другому, потому что у нас появляются сетевые задержки. Мы точно не знаем, когда. Запись случилась между w и w1, где именно она случилась, мы не знаем. То же самое с чтениями. С точки зрения истории у нас, допустим, можно записать три таких простеньких истории.
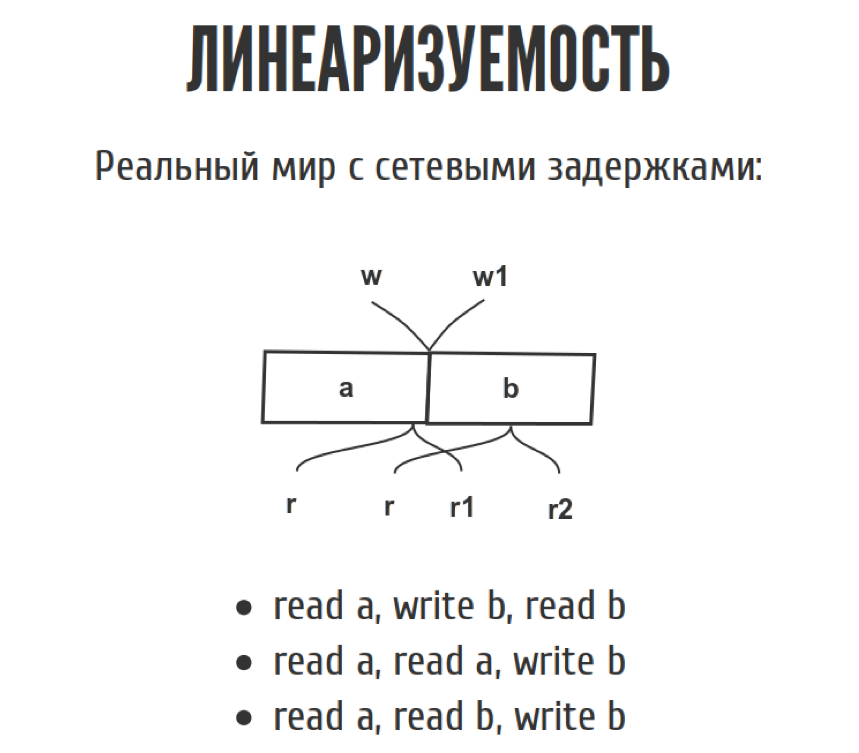
Сначала мы прочитали a, потом записали b, потом прочитали b, четко как на картинке нарисовано. В принципе возможна и другая история, когда мы прочитали a, мы снова прочитали a, а потом мы записали b, если у нас всё как на картинке.
Третья история. Если мы прочитали a, а потом внезапно прочитали b, а потом записали b, она противоречит сама себе, потому что мы прочитали b до того, как его записали. С точки зрения линеаризуемости такая история не линеаризуема, но CAP-теорема требует, чтобы была хотя бы одна история, которая не противоречит сама себе. Тогда ваша система линеаризуема. Их может быть несколько.
Устойчивость
Последний пункт — это буква P. Partition tolerance, по-русски можно сказать, что это «устойчивость к сбоям в сети». Выглядит она следующим образом:
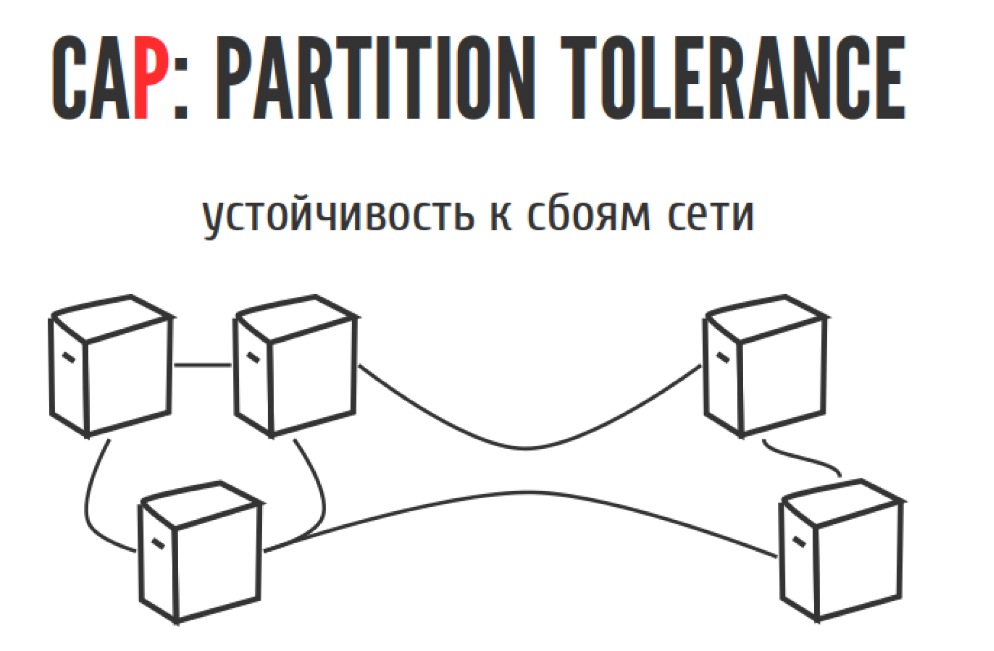
Представим, что у вас есть несколько серверов, и рано утром тут проехал экскаватор и перерубил между ними провода. У вас есть два выхода, если ваш кластер развалился пополам. Первый выход: большая половинка живет, а меньшая отвалилась. Вы потеряли доступность, потому что меньшая отвалилась. Зато большая живет. Зато не потеряли целостность. Либо работают обе половинки, мы и тут и там принимаем записи, всё принимаем, всё хорошо. Только потом, когда провод спаяют, мы поймем, что у нас была одна система, а стало две, и они живут своей жизнью.
С точки зрения CAP-теоремы у нас есть три возможных подхода к проектированию системы. Это системы CP / AP / AC в зависимости от двух комбинаций из трёх.
С AC-системами есть проблема. С одной стороны, они гарантируют, что у нас есть высокая доступность и целостность. Всё классно, пока у нас не поломалась сеть. А поскольку такое часто бывает, в реальном мире AC-системы можно использовать, но только если вы понимаете те компромиссы, на которые вы идёте, когда вы используете AC-системы.
В реальном мире есть два выхода. Вы можете либо сместиться в целостности и потерять доступность, либо сместиться к доступности, но потерять целостность. Третьего не дано.
В реальной жизни есть много алгоритмов, которые реализуют различные системы CP / AP / AC. Двухфазный коммит, Paxos, кворум и прочие рафты, Gossip и прочие кучи алгоритмов.
Мы сейчас попробуем некоторые из них реализовать и посмотреть, что получится. Вы можете сказать: «10 минут прошло, у нас уже голова взорвалась, а мы только пришли». Поэтому мы попытаемся на практике что-нибудь сделать.
Что мы сделаем на практике
Мы напишем простенькую master-slave распределенную систему. Для этого мы возьмем Scala, Docker, всё запакуем. У нас будет master-slave распределенная система, которая с асинхронной/синхронной репликацией. Потом мы достанем Jepsen и покажем, что на самом деле мы всё написали правильно или неправильно. Попытаемся объяснить результат после того, как мы запустим Jepsen. Что такое Jepsen? Я чуть позже расскажу, наверняка многие из вас об этом слышали, но глазами не видели.
Итак, master-slave. В общем случае это выглядит как базовая вещь. Клиент отправляет запрос на запись мастеру. Мастер пишет на диск. Мастер синхронно или асинхронно раскидывает это всё по слейвам. Cинхронно или асинхронно отвечает клиенту, либо до того, как он как записи раскидал, либо после того.
Мы попробуем понять с точки зрения CAP-теоремы, как дела обстоят с целостностью, доступностью и прочим.
Попробуем что-нибудь накодить.

У здесь есть небольшая заготовка, дальше я буду писать больше под караоке. У нас есть две функции, которые помогут нам работать с другими серверами. То есть мы будем использовать HTTP как самый простой способ взаимодействия между нодами в распределенной системе. Почему бы и нет?
У нас есть две функции. Одна пишет вот в эту ноду вот эти данные:

Другая функция, которая читает из вот этой ноды какие-то данные, причем делает всё это асинхронно:

Тоже полезная функция, которая парсит Response. Берёт Response, возвращает String:

Ничего сложного.
Для начала мы напишем простенький сервер нашей распределённой системы.
Для начала, у нас тут есть домашние заготовки. Данные внутри нашей системы, весь stat мы будем хранить в одной переменной, потому что у нас тут live demo, а не настоящая база данных.

Поэтому мы просто храним строку, её же мы будем реплицировать и прочее. Тут всякие полезные шутки, типа — прочитать из переменного окружения HOSTNAME, NODES соседние и прочее.

Мы тут напишем затычки для двух функций.

Чтение с нашей распределенной системы и записи из нашей распределенной системы. Мы их, конечно же, сейчас реализовывать не будем, а пойдем дальше.
Тут мы запускаем нашу балалайку:
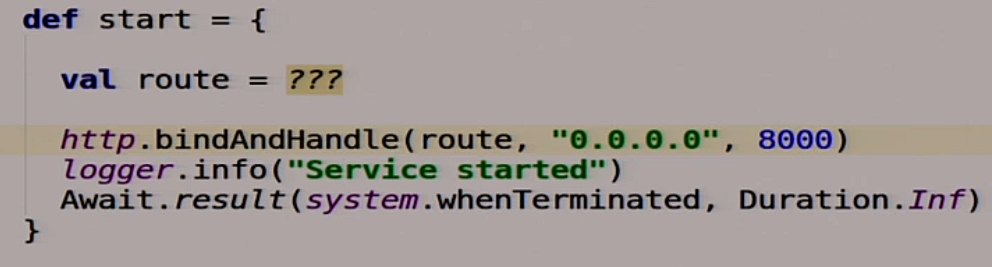
Всё очень просто. У нас есть функция route, которая пока ещё не реализована, но она что-то делает. Она описывает rest route, которыми мы будем пользоваться.

Всё это мы на 8000-ый порт натягиваем:

Какие route у нас будут? У нас будет два route. Первый это db.
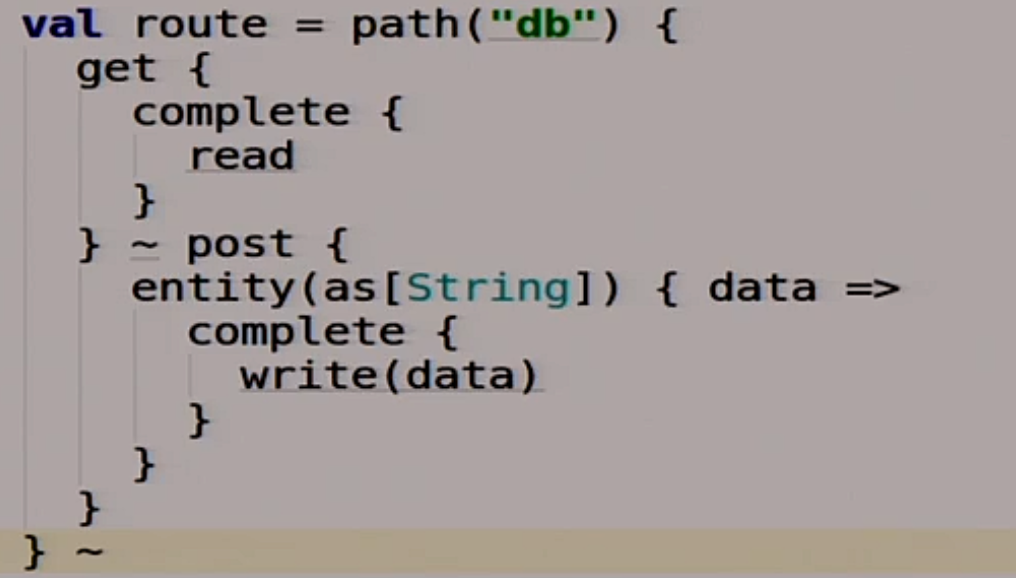
Этот route для нас, для клиентов базы данных. Мы с ним работаем, а она под капотом что-то делает.
Если мы туда делаем get, то мы вызываем нашу волшебную функцию read, которую мы ещё не реализовали.

Если мы туда постим какие-то данные, то мы вызываем нашу функцию write. Вроде ничего сложного.
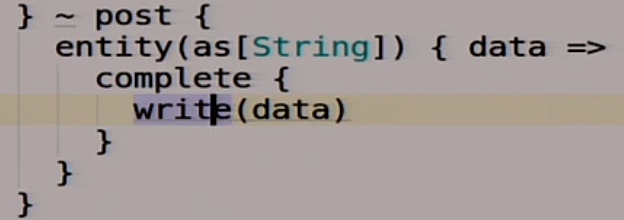
Помимо этого, у нас будет ещё один route, под названием local.
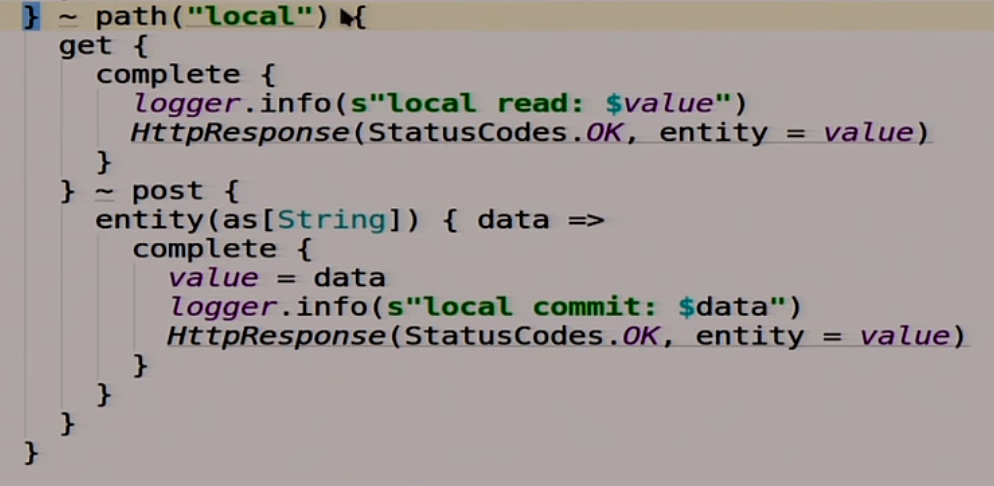
Он сделан не для нас, а для того, чтобы члены распределённой системы, разные ноды могли друг с другом общаться. Одна у другой могла прочитать, что у неё там записано.
Если мы туда делаем get, то мы читаем нашу волшебную переменную value.

Если мы туда делаем post, значит мы пишем в эту переменную то, что мы туда запостили.
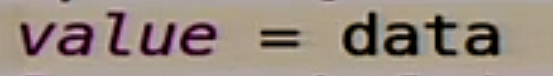
Ничего сложного. Немножко мозг взрывается от Scala, наверное, но ничего страшного.
Мы вроде написали наш сервер. Осталось сделать логику для нашего MasterSlave. Мы сейчас будем делать отдельный класс, который будет реализовывать MasterSlave. Чтение из асинхронного MasterSlave, по факту — просто локальное чтение того, что у нас там записано в нашу переменную.

Запись немного сложнее.
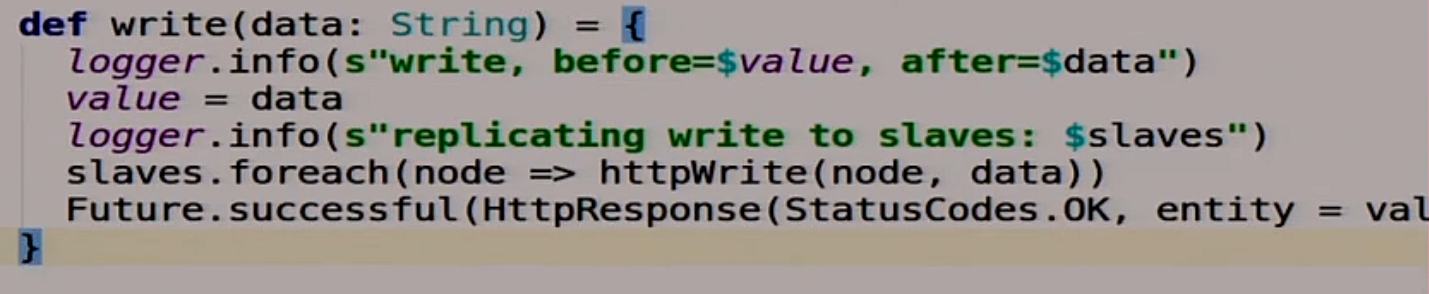
Мы сначала пишем в себя.

Потом пробегаемся по всем slaves, которые у нас есть, и пишем во все slaves.

Но у этой функции есть особенность, она возвращает Future.

Здесь мы выпаливаем асинхронно все запросы на запись к slaves, а клиенту говорим: «Всё ок, мы записали, можно идти дальше». Типичная асинхронная репликация, возможно с подводными камнями, сейчас мы это всё увидим.
Теперь мы попробуем всё это скомпилить. Это Scala, она делает это долго. Вообще должно скомпилиться, я репетировал. Скомпилилось.
Что же делать дальше
Мы написали, но нам же нужно всё это запустить, а у меня один ноутбук. А мы же делаем распределённую систему. Распределённая система с одной нодой — это не совсем распределённая система. Поэтому мы будем использовать Docker.

Docker – это система контейнеризации приложений, все, наверное, про неё слышали. Не все, вероятно, использовали в продакшене. Мы попробуем использовать его. Это лайтовая система виртуализации, если совсем всё упростить. У Docker есть богатая экосистема вокруг, мы не будем использовать всё из этой экосистемы. Но поскольку нам нужно запускать не один контейнер, а сразу группу, то мы будем использовать Docker Compose, чтобы их скопом сразу все накатить.
У нас есть простенький Dockerfile, но он не совсем простенький.
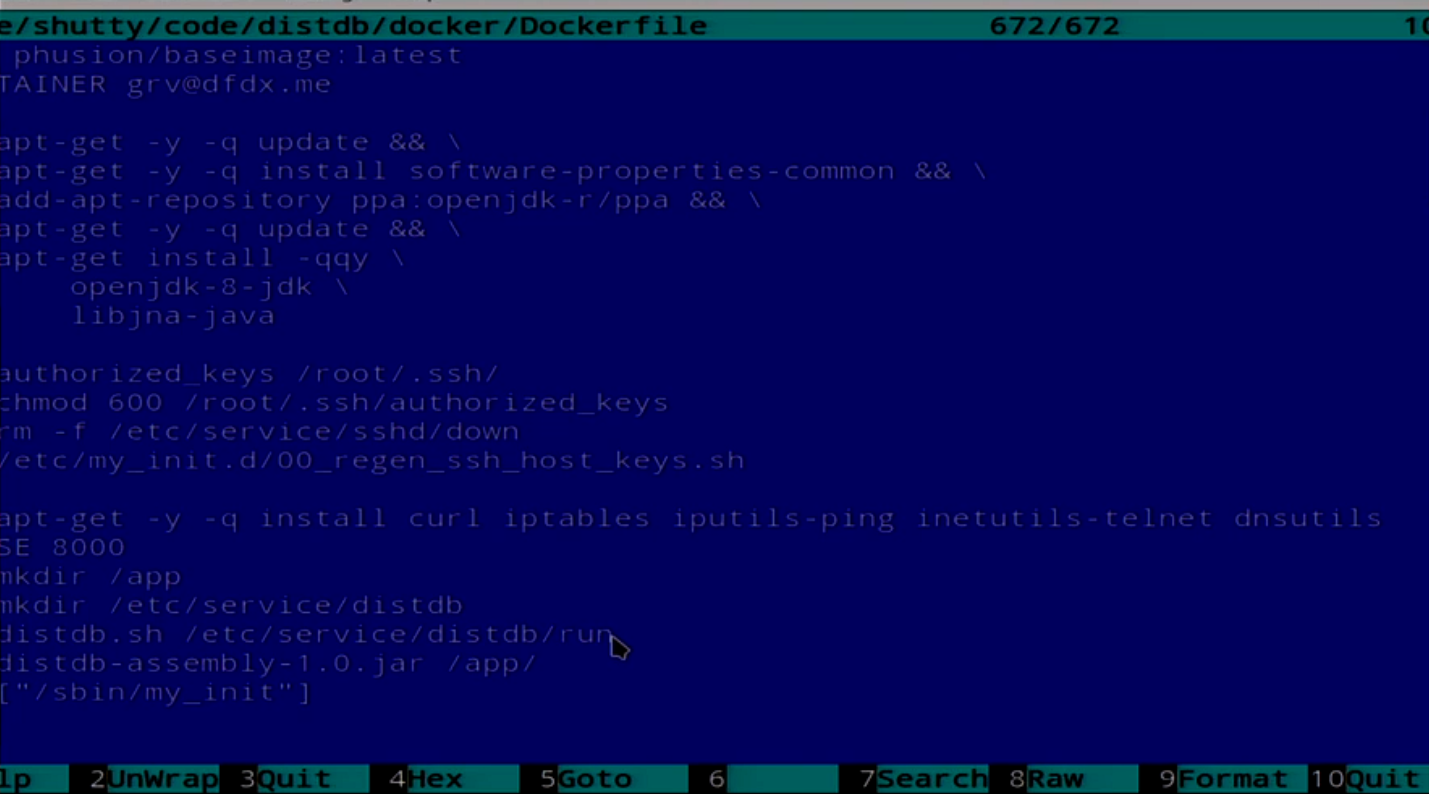
Тут Dockerfile, который ставит Java, засовывает туда SSH. Не спрашивайте, зачем он нужен. Наше приложение это всё запускает.
И у нас есть Compose файл, который описывает все 5 нод.
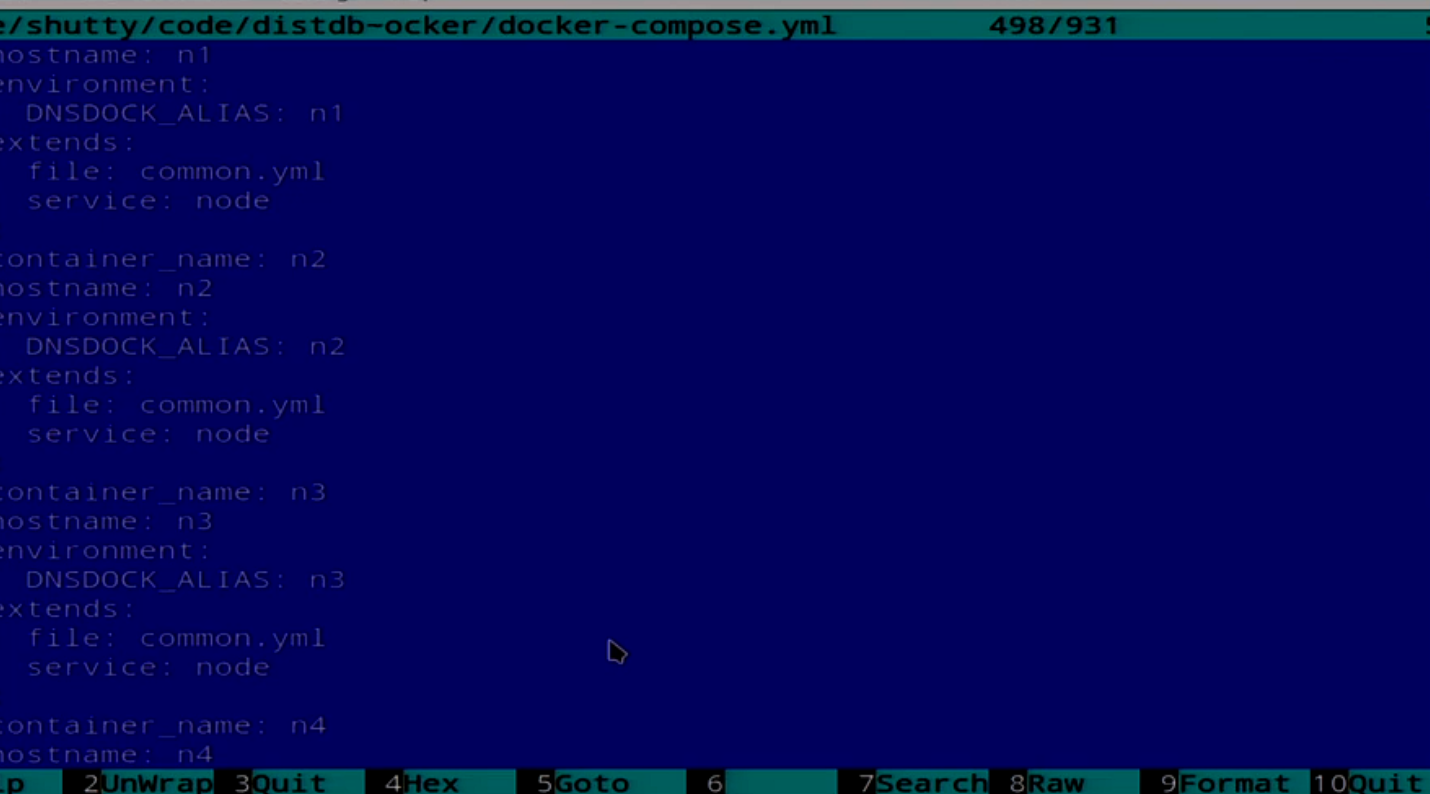
У нас тут есть описание нескольких нод. Мы попробуем сейчас это всё задеплоить. У меня есть скриптик для этого.

Пока оно деплоится, я поменяю цвета.
Сейчас оно создает Docker-контейнер. Сейчас оно его запустит. Все наши 5 нод запустились.
Сейчас ждем, пока наша распределённая система стукнет о том, что она жива. На это уходит некоторое время, это же Java. Наш MasterSlave сказал, что он запустился.
Помимо этого, всего у нас есть простенькие скриптики, которые позволят нам что-то из этой распределённой системы прочитать.
Посмотрим, что у нас в ноде n1.
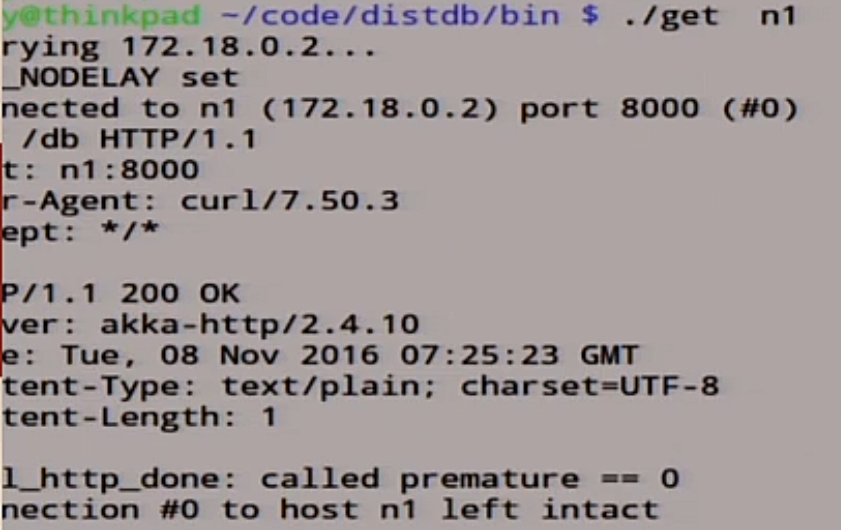
Там записан 0.
Поскольку тут не было защиты от того, кто здесь master, кто slave, мы будем брать на веру, что n1 у нас всегда master. Мы будем только в него всегда писать, чтобы всё упростить.
Давайте попробуем в этот master что-нибудь записать.
put n1 1
Туда записалась единица. Посмотрим, что у нас тут в логах.
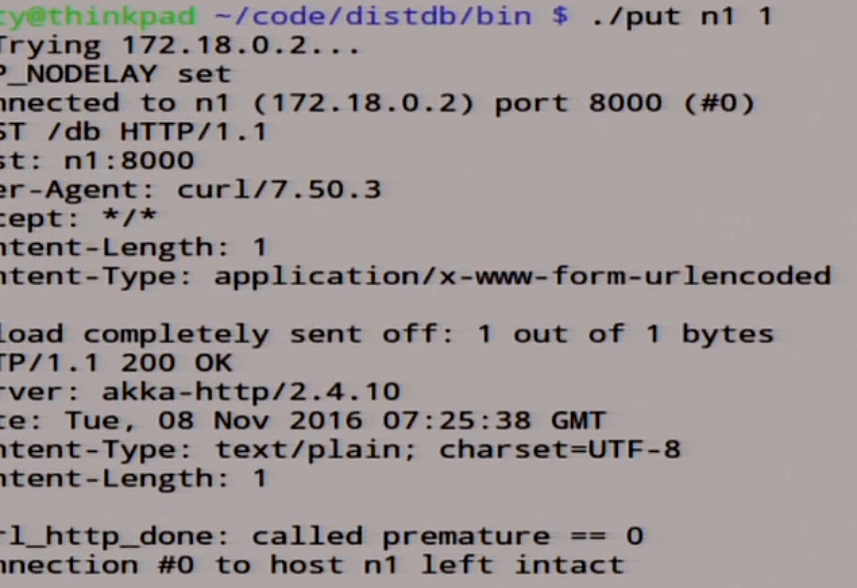
Вот у нас пришла наша единичка здесь в записи, мы эту запись раскатали по всем slave, вот здесь она записалась.
Можем даже зайти на ноду n3, посмотрим, что там.
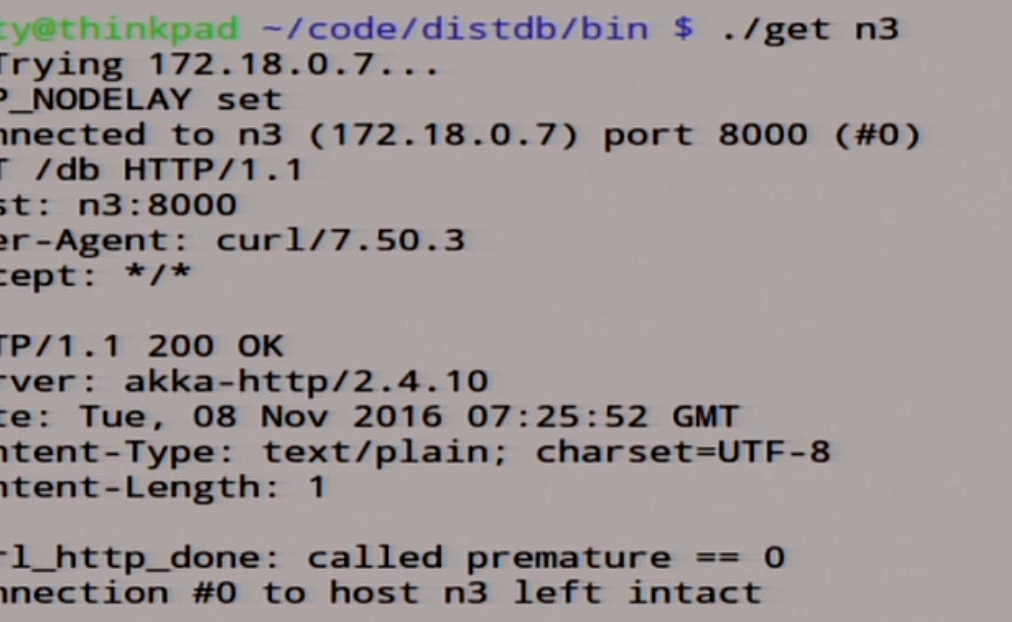
Там записана единичка.
Мы можем идти за премией, мы написали свою распределённую систему на коленке, которая даже работает. Но она работает, пока всё хорошо.
Сейчас мы попробуем сделать ей плохо. Для того, чтобы сделать ей плохо, мы возьмем такой фреймворк под называнием Jepsen. Jepsen – ое-фреймворк для тестирования распределённых систем, с одной тонкостью: он написан на Clojure. Clojure – это такой лисп, кто не в курсе. Это набор готовых тестов для уже существующих баз данных, очередей и прочего. Вы всегда можете написать свой. Помимо этого есть еще куча статей о найденных проблемах, наверное, во всех базах данных, кроме экзотики. Пожалуй, не досталось только ZooKeeper и RethinkDB. Им досталось, но чуть-чуть по сравнению с остальными. Можете почитать об этом.
Каким образом работает Jepsen
Он имитирует сетевые ошибки, потом генерирует случайные операции к вашей распределённой системе. Потом смотрит каким образом эти операции были применены к вашей распределённой системе и к эталонному поведению, к модели этой распределённой системы, и есть ли с этим проблемы.
Если Jepsen у вас нашел такую проблему:
Это я тут хотел пошутить.
Если Jepsen нашел у вас какую-то проблему, то он нашел для вашей распределённой системы контрпримеры, и там действительно есть какой-то косяк. Но поскольку Jepsen-тесты носят вероятностный характер, если он ничего не нашёл, возможно, он недостаточно хорошо искал. Но если он хорошо поищет, он что-нибудь найдет. В случае, например, RethinkDB они гоняли тесты около двух недель перед релизом, чтобы доказать, что более-менее как-то работает.
Мы тут две недели тесты гонять не будем, будем секунд по пять. Наша задача с тестом Jepsen — это писать в master, читать с MasterSlave и понять, как обстоят дела с целостностью и правильно ли мы написали нашу мастер/слейв репликацию или, может быть, нет.
Jepsen-тест состоит из нескольких важных частей.

У нас есть генератор, который генерирует случайные операции, которые мы применяем к нашей распределённой системе. Сама распределённая система, которую мы где-то там запустили. Она может быть в Docker, может быть на реальных железных серверах, почему нет. И у нас есть эталонная модель, которая описывает поведение распределённой системы. В нашем случае это регистр, то, что мы туда записали, мы это и должны прочитать. Ничего сложного нет. В Jepsen есть огромное количество моделей на все случаи жизни, но мы будем использовать только регистр и Checker, который проверяет соответствие истории операции, примененной к распределённой системе на соответствие их к модели.
Проблема в том, что Jepsen написан на Clojure, и тесты нужно писать тоже Clojure. Если бы была возможность писать их на чём-нибудь другом, было бы классно. Но беда, беда. Clojure – это такой язык, где всегда есть список. Если, например, вы хотите сложить два числа, то вы делаете список, в котором первый элемент — это сложение, а потом два числа, в конце получится три.
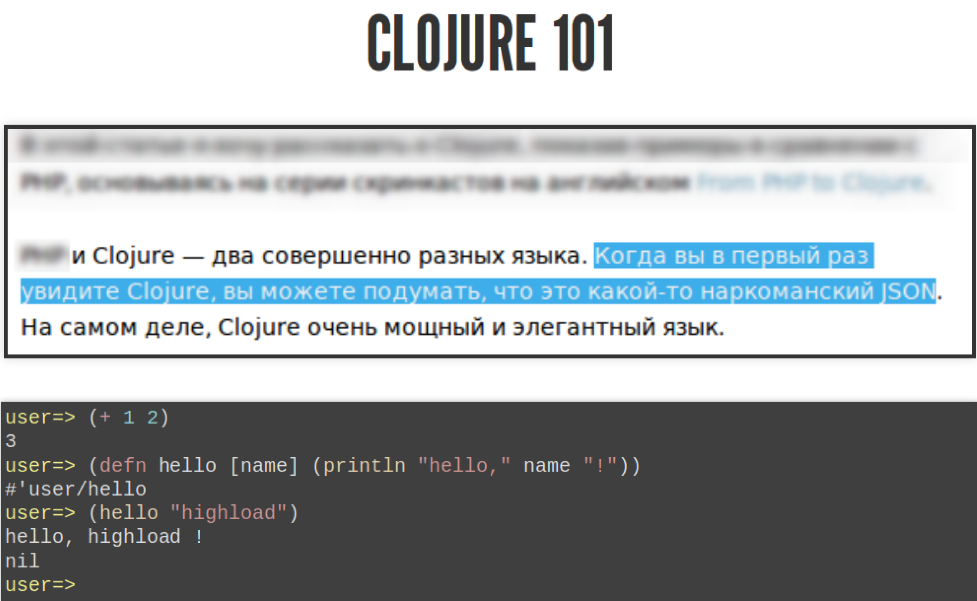
Вы можете задать свою функцию вызова в другую функцию под названием defn и сказать, что первый аргумент — это название функции, дальше аргумент — это функции, дальше тело функции. Если вы вызовете её таким образом, она скажет «hello, highload!». Это такой курс Clojure для начинающих.
Вы можете сказать, что этот курс Clojure выглядит вот так:

И сейчас наверняка будет, то что там справа. На самом деле, да. Но я рассказал, вам достаточно, чтобы хотя бы примерно понимать, что сейчас будет проходить на кадрах, потому что Clojure немного специфичный.
Итак, Jepsen. Для начала мы опишем наш тест.

Эту портянку правильно читать не слева направо, сверху вниз, потому что это лисп, лучше читать изнутри и наружу. У нас есть какая-то функция, которая возвращает описание нашего теста, который мы ещё не реализовали. Мы это описание суём в другую функцию, которая этот тест запускает, и она возвращает справочник. По этому справочнику мы выковыриваем что-то по ключу results и смотрим, есть ли в этом справочнике ключ под названием valid. Если он там есть, то тест пройден. Clojure читает вот так. Нужно сначала мозг сломать, но потом всё становится понятно.
Теперь мы опишем наш тест.
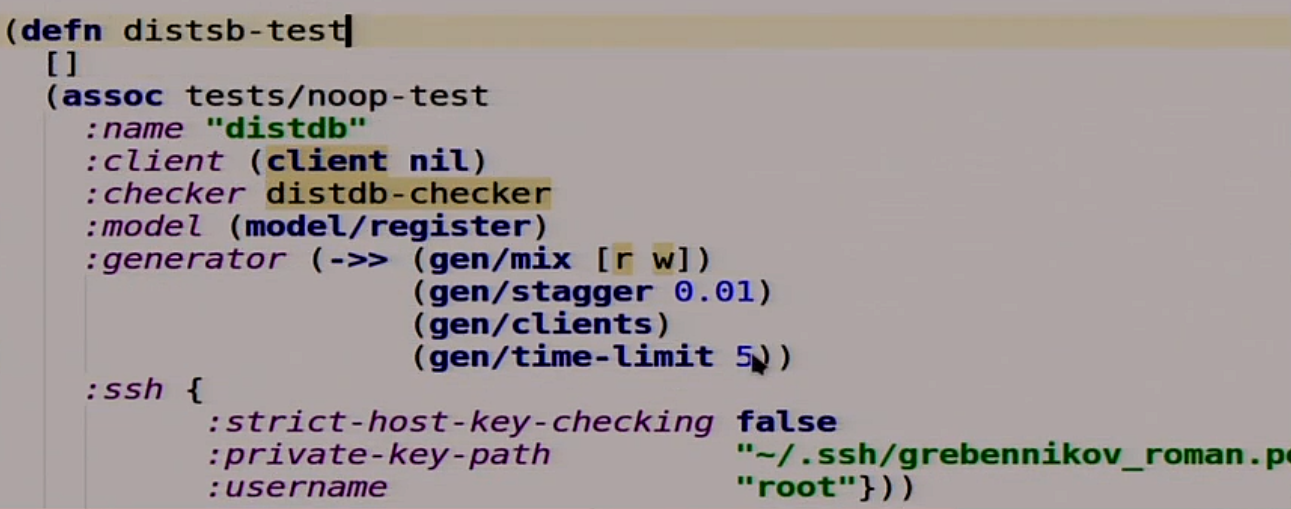
Наш тест — это тоже функция, в которой нет аргументов. Она расширяет другой тест, который вообще ничего не делает, и дополняет его некоторыми штучками. Например, названием, клиентом, который он будет использовать для общения с нашей базой данных, потому Jepsen не знает ни про что, ни про какие HTTP. Checker, который мы ещё не написали, но напишем. Модель, которую мы будем использовать как эталон нашей распределённой системы. Генератор, который берет случайные операции чтения и записи, вставляет между ними задержку в 10 миллисекунд, запускает их с клиентом и пускает это всё на протяжении 5 секунд. Дальше там для работы с SSH.
Теперь мы опишем наши чтение и запись. Это тоже функции. Это же Clojure, тут всё функции, тут ничего другого нет.
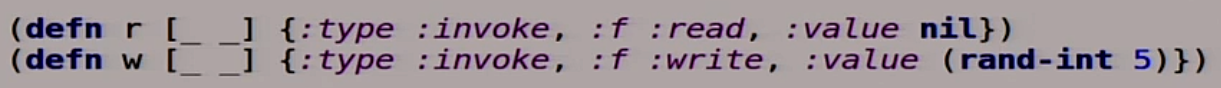
Также опишем наш клиент, но сначала HTTP-клиент.
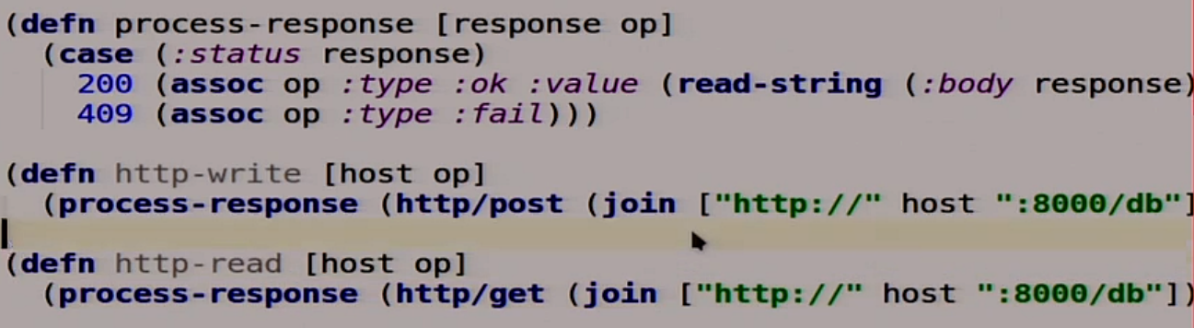
У нас тут несколько функций для записи в HTTP, для чтения в HTTP. Мы не будем вдаваться, как это всё делается. Но по факту если нам вернулось 200, то всё окей. Если 409 – это HTTP 409 Conflict, очень полезный код, значит, что-то не так. Мы будем его немного дальше использовать.
Дальше мы опишем наш клиент.

Тоже функция, которая берёт хост, который мы сейчас будем писать, и расширяет интерфейс под названием client. У него есть три функции. Setup которая возвращает саму себя. Teardown которой не надо удалять клиента, там и так ничего нет внутри. invoke которая нашу операцию, которую мы туда передаём, применяет к этому хосту. У нас тут есть пятисекундный таймаут, то есть если за 5 секунд наша распределённая система не заработала, то можно сказать, что она и не заработает. Если у нас это чтение, мы выполняем HTTP-read, делаем GET-запрос. Если запись, то мы делаем HTTP-write, то есть POST-запрос. Поскольку у нас MasterSlave и у нас только одни Master, мы тут немного поменяем, мы пишем всё время в Master.

Последний пункт, который у нас остался – это Checker. Можно было бы использовать, который внутри Jepsen под названием linearizability checker, но мы не будем это использовать, потому что я на это наступил.
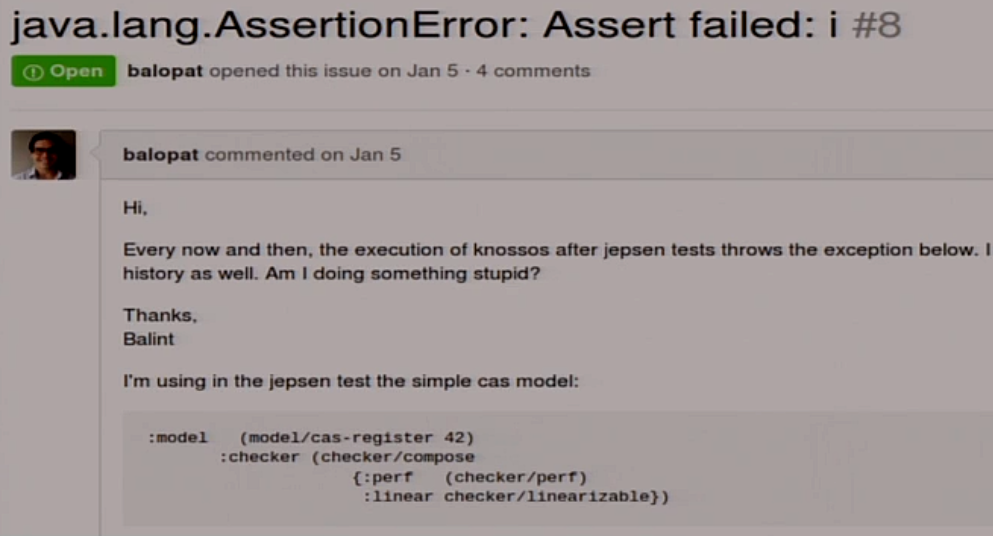
Я не знаю, что с этим делать. Поэтому я написал свой, который не падает. По факту он использует то же самое, только не пытается в конце сгенерировать красивую картинку, где он обычно и падает.
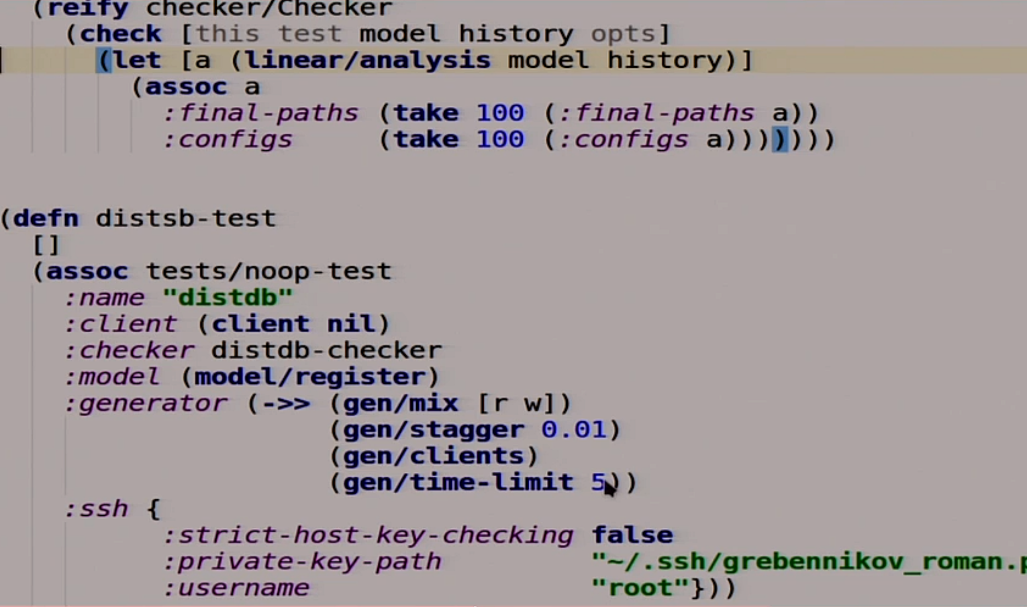
Мы написали наш мега-тест, давайте попробуем его запустить.

У нас есть наша распределённая система, тест, мы ждём, пока он запустится.
lein – это такая система сборки для Clojure.
Оно начало писать разные хосты, разные чтение/запись, в логах тоже магия творится — чтение/запись, репликация. В конце оно нам говорит “fail”. Что-то вы здесь забыли. Тут есть список историй, который не линеаризуемый, и что-то здесь явно напутали.
Давайте посмотрим на такую ситуацию:
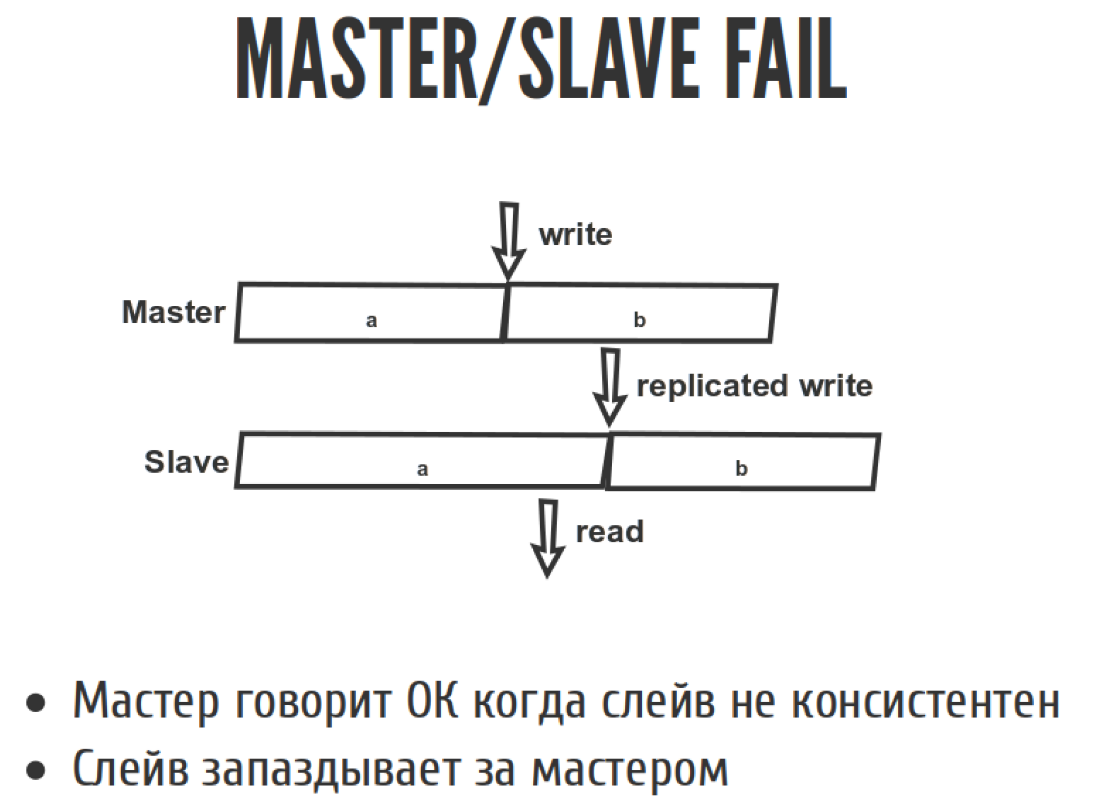
Все знают, что если мы делаем асинхронную репликацию в Master/slave, то slave у нас всегда запаздывает. Что значит запаздывание slave с точки зрения линеаризуемости? Это значит то, что здесь случилась запись, через некоторые время запись отреплицировалась, а здесь случилось чтение. В результате мы прочитали то что не должны были прочитать. Мы должны были прочитать B, а прочитали A. То есть вернулись во времени назад, когда операция вроде как уже закончилась, а мы вернулись назад и прочитали то, что было с неё. Потому что Master при асинхронной репликации говорит «ок» слишком рано, потому что еще не все slaves догнали поток репликации. Поэтому slave всегда запаздывает за master.
Вы конечно скажете, что это детский сад, давайте сделаем всё по-взрослому. Напишем синхронную репликацию, мы же умные. Она будет почти такая же, как и асинхронная, только синхронная.
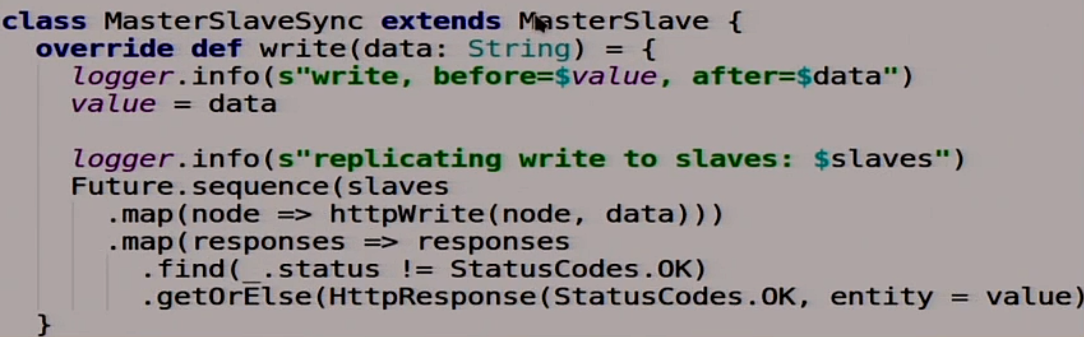
Мы переопределим одну функцию, которая пишет в нашу распределённую систему. Она теперь делает это по-умному: она дожидается того момента, когда все slaves скажут «ок». Только потом она говорит, что хорошо, всё записалось. Если один из slaves сказал, что не «ок», то значит у нас пошла беда, и мы туда не идём.
Теперь попробуем всю эту балалайку запустить. Наверное, чувствуете, что сейчас будет какая-то подстава, не может всё так хорошо быть. 25 минут прошло, а тут человек все налайвкодил, и всё заработало, поэтому мы сейчас подождём, пока оно скомпилится. Сейчас оно всё собирает, это вам не динамически языки, когда всё сразу работает, тут всё долго и мучительно. Есть время подумать, то ли ты написал, не то написал, переписать всё, пока деплоится.
Master/slave sync запустился, отлично. Давайте теперь запустим нам Jepsen-тест снова в надежде, что всё будет хорошо. Мы же синхронную репликацию сделали, что может пойти не так. Он запускается, начало писать, но уже не так быстро. Опять пишет, опять читает, что-то там происходит. В результате опять что-то плохое происходит.
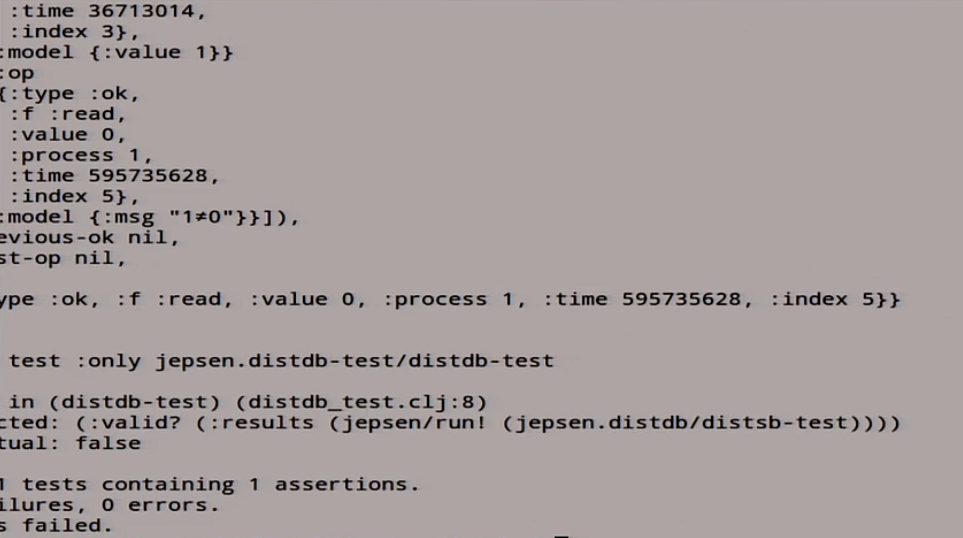
У нас опять случился fail: она нам выдало огромное количество историй, которые не линеаризуемы с точки зрения линеаризуемости.
В чём же проблема?
Мы думали, что всё сделали правильно. Как-то получилось всё плохо.

На картинке видно, что всё стало ещё хуже, чем было.
Представим такую ситуацию.
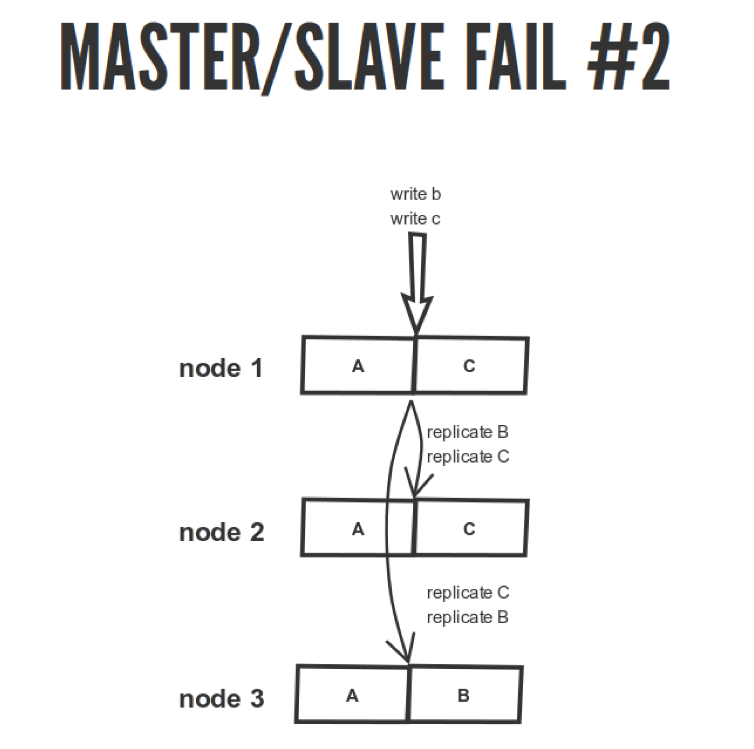
У нас есть наша мастер-нода 1. Мы туда записали операции B и C. У нас здесь C, отреплицировали сюда. Мы же по HTTP асинхронно всё делаем, что может пойти не так. В ноду 2 они записались именно в этой последовательности. А на ноду 3 они перепутались, мы же их случайно отправили. Мы же забыли, что есть журналы и прочие штуки. Они применились не в той последовательности, в которой должны были примениться. У нас в результате вместо C получилось B, и мы тут читаем непонятно что. То ли B, то ли C, хотя должны читать C. Поэтому такая вот беда.
С точки зрения CAP-теоремы master/slave и целостности репликация зависит от того, синхронная репликация или нет. Если асинхронная, то понятно, что никакой линеаризуемости нет, потому что slaves запаздывают. С точки зрения синхронной это зависит от того, насколько вы криворукий и правильно всё реализуете. Если повезет, то хорошо. Если такие же как я, то плохо. С точки зрения доступности проблема в том, что у нас slave не умеет писать, он умеет только читать. С точки зрения высокой доступности мы не можем исполнить все те запросы, которые к нам приходят. Мы можем делать только чтение. Поэтому мы нифига не доступы.
Поэтому CAP-теорема — это очень специфичная штука. Применять её к базам данных надо очень осторожно, потому что определения её строгие, они не всегда описывают то, что есть в реальных базах данных. Потому что она описывает 1 регистр. Если вы можете все ваши транзакции и прочее свести к операциям на одном регистре, то это хорошо. Но обычно это сложно или даже невозможно. Доступность она такая доступность, но latency ничего не говорит. Если ваша распределённая система офигенно консистентна, но отвечает на запрос раз в сутки, то это тоже очень тяжело в продакшне использовать. Есть куча разных практических аспектов, которые в CAP-теореме никак не рассматриваются. Та же потеря пакетов partitions, то есть если у нас partition сетевой непостоянный, а переменный, раз в 5 секунд несколько пакетов теряются.
Поэтому по личному опыту, когда люди начинают писать распределённые системы с неокрепшим умом, у них рано или поздно знания кристаллизуются, все костыли набивают новые шишки, и получается что-то похоже на кривой-косой алгоритм консенсуса. Когда все ваши ноды пытаются договориться о общем состоянии, но этот алгоритм не очень тестирован в экстремальных случаях, они же бывают редко, зачем об этом волноваться. Но консенсус в общем случае — это соглашение об общем состоянии с возможностью ещё-то как пережить сбои, если они случились.
Такой пример:
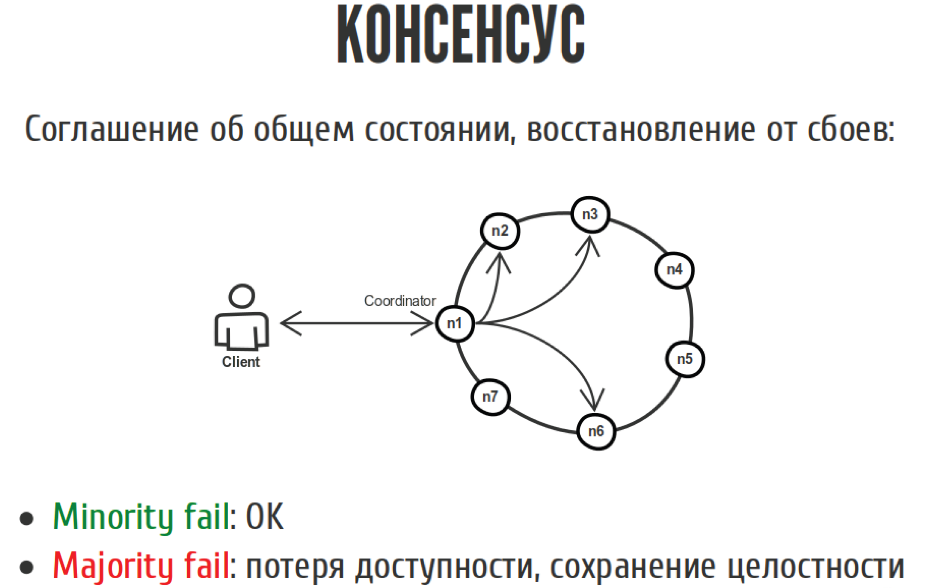
У нас есть клиент, который пишет в нашу распределённую систему, в которой семь нод. Мы тут голосуем. Если большинство нод согласилось, что мы должны это всё записать, то вроде как всё хорошо. То же самое с чтением. Если у нас меньшинство нод отвалилось, 1-2-3, то ничего страшного. Мы не потеряли ни в доступности, ни в целостности, потому что всё хорошо. Если отвалилось большинство, то мы потеряли доступность, потому мы уже не можем исполнять записи, но пока ещё не потеряли целостность.
Давайте сделаем лайв-демо на коленке.
Мы попробуем сделать кворум. Попробуем еще раз достать Jepsen и попытаемся объяснить то, что у нас получится.
Тут будет всё немножко посложнее, потому что мы вроде как уже умные. Для начала мы сделаем функцию, которая будет описывать размер кворума.

Для трёх нод — это две, для пяти нод — три и т. д. Просто банальное большинство.
Дальше мы опишем наши волшебные функции read и write.

Если мы читаем из нашей распределённой системы с кворумом, то мы спрашиваем у всех нод по HTTP, что у вас там лежит:

Потом вызываем нашу функцию, которая будет работать с кворумом, которую мы сейчас напишем:

В конце говорим, что у нас в конце должно получиться:

Примерно то же самое с записью. Мы пишем во все ноды, смотрим, что записалось:

Собрался у нас кворум или нет:

Дальше формируем какой-то ответ пользователю:

Как мы будем жить с кворумом?

Это немножко Scala, более каноническая. У нас тут есть последовательность ответов, которые нам прилетели от разных серверов, от разных нод нашей распределённой системы. Это практически просто последовательность строк, которые мы прочитаем, например, 0000.

Мы их группируем по самому себе:
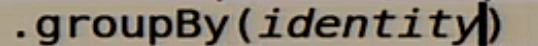
Смотрим как часто какие группы встречаются:

Сортируем по популярности:

Берём самый популярный ответ:

Вроде как всё правильно.
Дальше функция, которая формирует ответ:
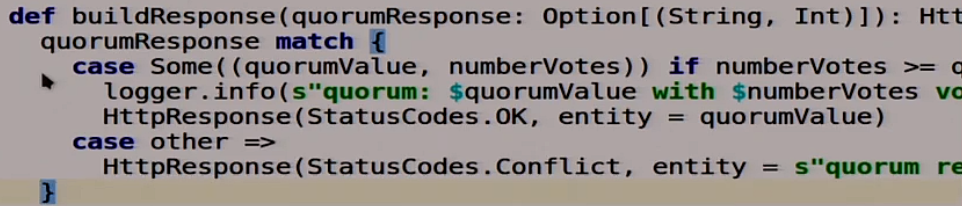
Она тоже очень каноническая на Scala, не совсем понятно, что происходит.
Мы берём пару: самый популярный ответ и количество голосов:

И смотрим, если количество голосов больше нашего кворума или равно этому кворуму, то всё ок, мы записали. Мы говорим, что нормально, запись удалась, кворум собрался.

Что же может пойти не так?
Если что-то не то, то мы говорим наш волшебный HTTP 409 Conflict:

Теперь мы попробуем всё это прикрутить:
И передеплоить.
Мы сейчас опять попробуем наши волшебные скриптики, которые делают. Давайте посмотрим, что у нас в ноде n2.

Сейчас оно задеплоится, такой медитативный процесс. Уже почти. Ждём пока она отстучится. Отстучалось.
Посмотрим, что у нас в ноде n2.
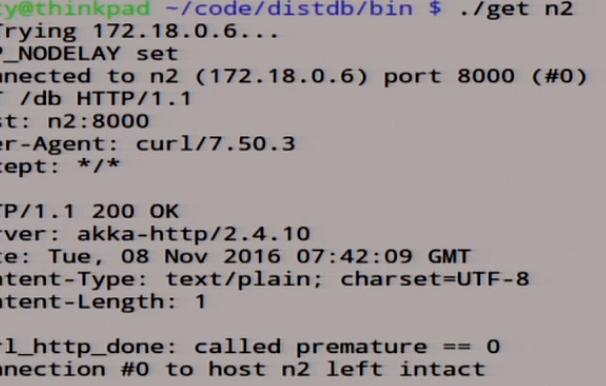
Там лежит 0. Мы смотрим, что у нас тут произошло:
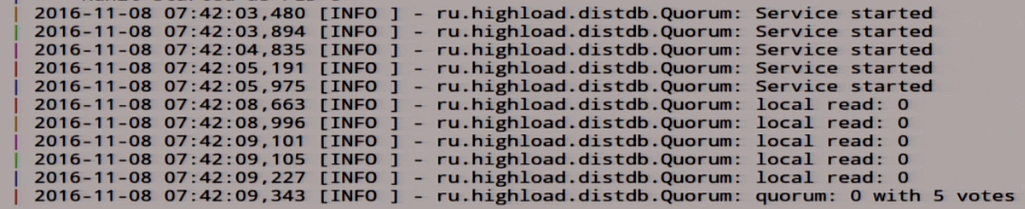
Local read, у нас 0 прочитался с пятью голосами, вообще классно. Настоящая распределённая система.
Давайте туда что-нибудь запишем:

Мы записали туда единичку. Она записалась:

У нас тут раскатало эту единичку по другим нодам. У нас тут кворум сошелся, один с пятью голосами. Вроде как всё хорошо.
Вернёмся к нашему Jepsen. Поскольку у нас кворум, а у кворума может быть много мастеров. Вообще, там нет такого понятия, как кворум.
Уберём здесь наш костыль в клиенте:
И попробуем это всё заново запустить и посмотреть, что же будет с нашим кворумом, когда мы опять наш тест на целостность запустим. Если надругиваться над кодом, то со всей силой.
Оно начало писать, здесь происходит куча всего.
В конце оно нам сказало true:
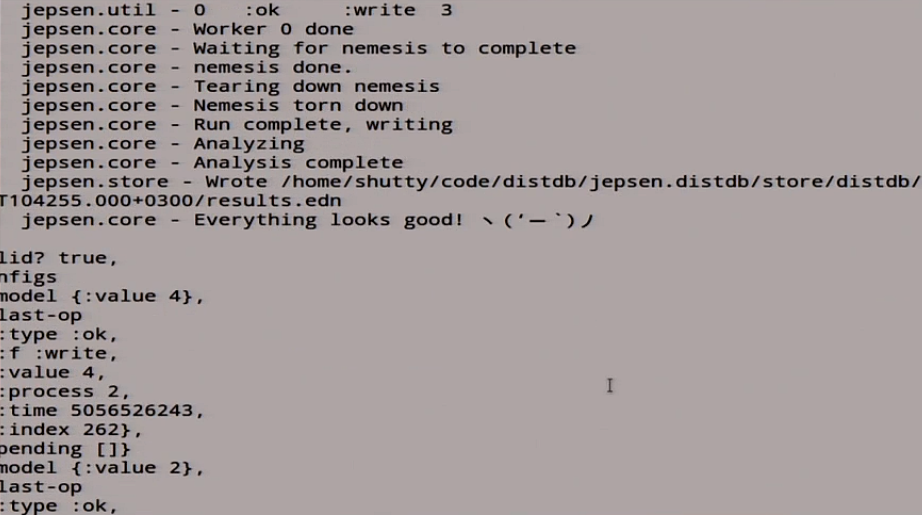
Вроде как всё хорошо. Но я вам об этом говорил, что Jepsen — это такой некий вероятностный характер тестов. Поэтому мы здесь вместо 5 секунд включим 15:
И для надежности ещё раз запустим этот тест. В надежде, что он нам может быть что-то ещё принесёт, ловля багов вероятностная. Очень интересный и расслабляющий процесс. Будем надеяться, что со второй попытки, оно что-то нам найдет. Сейчас мы погоняем её подольше, 15 секунд, в надежде, что наш кворум где-нибудь крякнет. Уже почти. Все с нетерпением ждут, что же он нам скажет. Оно нам сказало fail:
Чего мы и ждали. Что же у нас тут случилось с fail?
Давайте аномально посмотрим вот на эти две функции:
Здесь что-то не так. Во-первых, потому что это Scala, там всегда что-то может быть не так. Во-вторых, там какая-то проблема в логике.
Посмотрим вот на такую последовательность записей:

У нас есть два клиента. Мы здесь записали операцию А, дальше ноды сказали «ок», мы записали, у нас тут кворум сошелся. Но пока мы не сказали клиенту, что мы записали А, вот здесь прибежал более быстрый клиент, который успел записать B, ноды ему сказали, что кворум сошёлся, и мы тоже успели сказать, что всё хорошо. Этому клиенту мы сказали, что мы записали B, этому мы сказали, что мы записали А. Тут мы прочитали что-то, что же мы тут такое прочитали?
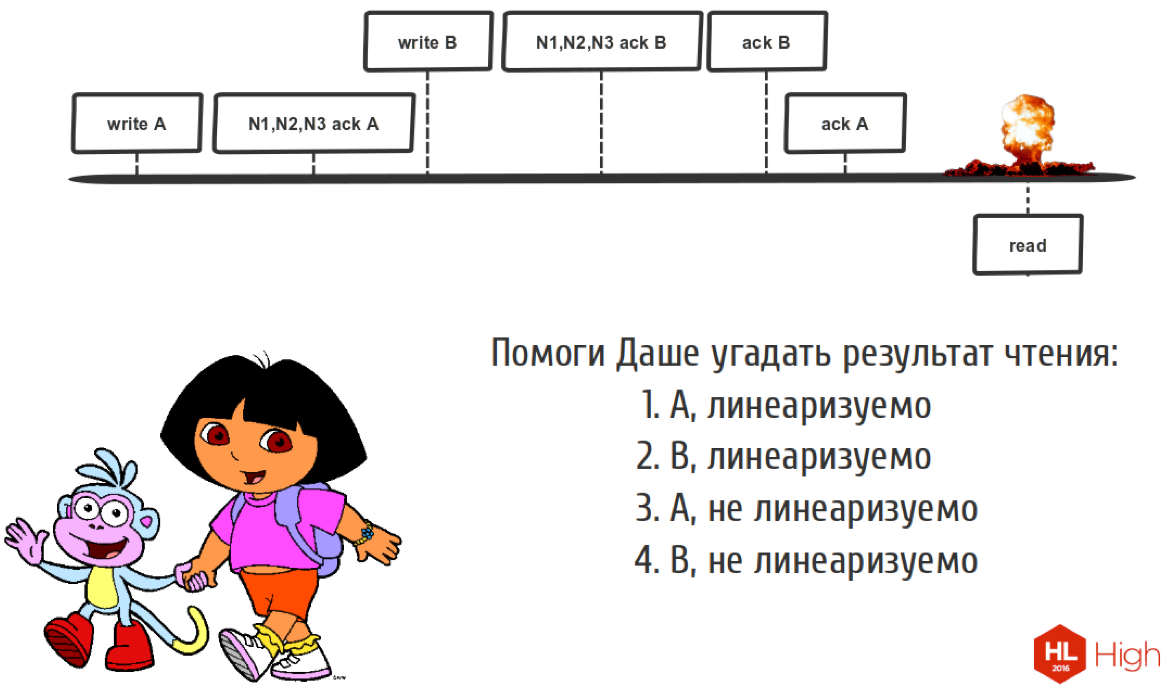
Поскольку времени мало, я подскажу, что мы прочитаем тут B, и это всё нелинеаризуемо. Потому что мы должны были прочитать А, потому что такой ситуации не должно быть. Потому что мы должны разруливать конфликты в нашей системе.
Чтобы такого не было, не надо изобретать велосипеды и писать кворум самостоятельно, если только вы не автор алгоритма RAFT или PAXOS. Это алгоритм нам всем очень помогает делать нормальные распределённые системы.
Алгоритмы кворума PAXOS & RAFT описывают конечный автомат, и ваш конечный автомат переходит между состояниями. Все эти переходы записываются в журнал.
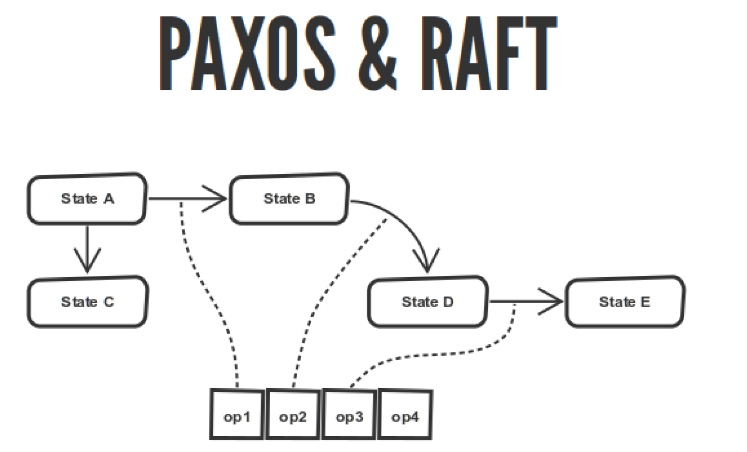
Эти алгоритмы описывают соглашение о порядке операций в этом журнале. Они описывают выбор мастера, применение операции, как этот журнал раскладывать по вашим нодам. Но если у вас на всех нодах будет одинаковый журнал, то ваш конечный автомат, исполняя этот журнал от начала до конца, придёт к одинаковому состоянию на всех нодах. Вроде как хорошо.
Проблема в том, что PAXOS довольно сложный. Она написана математиком для математиков. Если вы попытаетесь его реализовать, у вас будет очередная вариация реализации PAXOS, которых очень много, даже страшно подумать, сколько. Она не совсем для людей, она не разбита на фазы. Это просто огромная портянка, описывающая математические конструкции. Надо многое додумывать. Все эти вариации PAXOS и реализации PAXOS именно о том, как додумать то, что написано в этой бумаге, в сторону реальной реализации, которую можно использовать в продакшене.
Чтобы такого не было, есть такой алгоритм RAFT. Он более новый, там учтены все проблемы, там описаны все те шаги, которые нужно сделать, чтобы реализовать хороший алгоритм консенсуса. Там всё классно. Есть огромное количество разных реализаций:
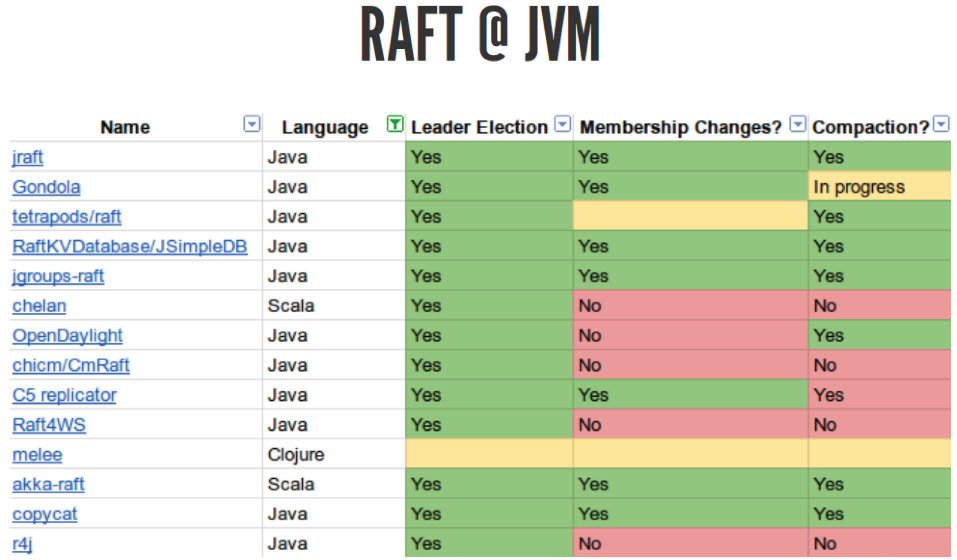
Тут только для Java, но есть реализации для всех языков, даже на PHP, думаю, есть, хоть и непонятно, зачем. Вы можете взять эту библиотеку и попытаться потестировать её для себя. Не все они реализуют корректный RAFT. Я пробовал использовать akka-raft, которая вроде как должна работать, но почему-то Jepsen-тесты она не прошла, хотя вроде написано, что иногда должна.
Алгоритмы консенсуса используются много где, даже в третьей версии MongoDB появился RAFT. В Cassandra всю жизнь был PAXOS. Во многих базах данных, системах очередей, когда они дорастают до зрелости, рано или поздно появляется алгоритм консенсуса.
В целом, когда вы пишете свою распределённую систему, вы должны понимать, что у вас есть много путей по которым вы можете идти. Вы должны знать, что эти пути есть и не делать еще один свой. Когда вы выбираете какой-то путь, вы должны понимать, что у вас каждый путь — это компромисс между целостностью, задержками, пропускной способностью и прочими разными штуками. Если вы понимаете этот компромисс и можете его применить к своей предметной области, то всё хорошо.
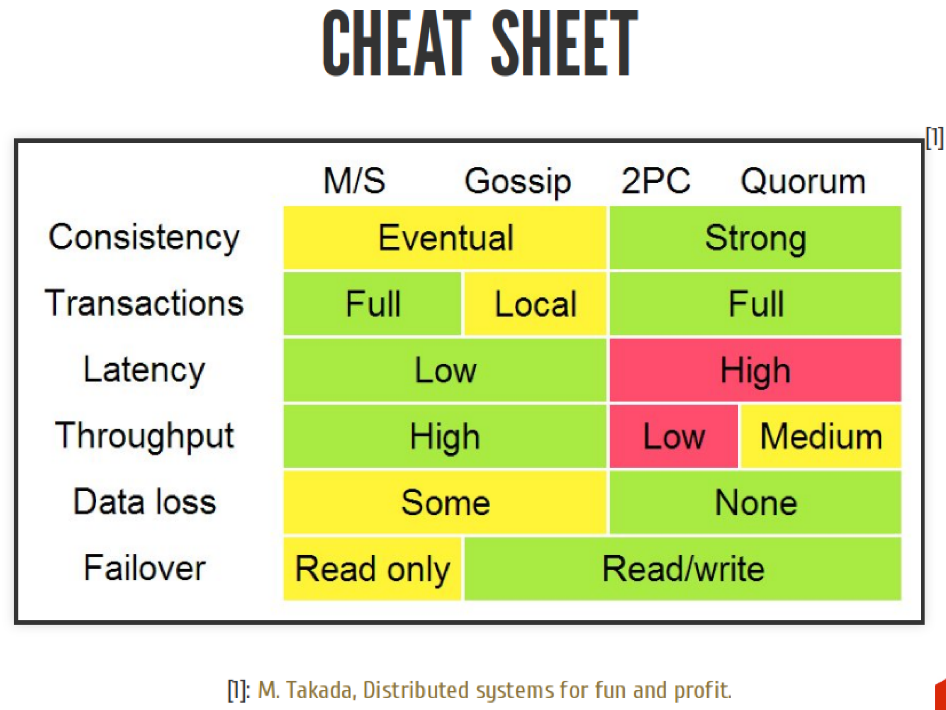
Нельзя говорить, какой из этих подходов лучше. Всё зависит от вас. Всё зависит от вашей бизнес-задачи. Это всего лишь инструменты.
Доклад: Страх и ненависть в распределённых системах.

