→ Вводная часть (со ссылками на все статьи)
Сложные системы (распределённые/крупные/со сложной логикой/сложной системой данных) – как живой организм: подвижный, изменчивый и самостоятельный. Всё это требует постоянного контроля со стороны разработчиков/администраторов/DevOps-инженеров.
К этому выводу я пришёл, когда система несколько раз «загибалась» в ходе её разработки, настройки сервера и эксплуатации. Это натолкнуло меня на мысль, что мониторинг должен осуществляться не только на этапе производственной эксплуатации, но и на этапе разработки.
Обо всём по порядку…
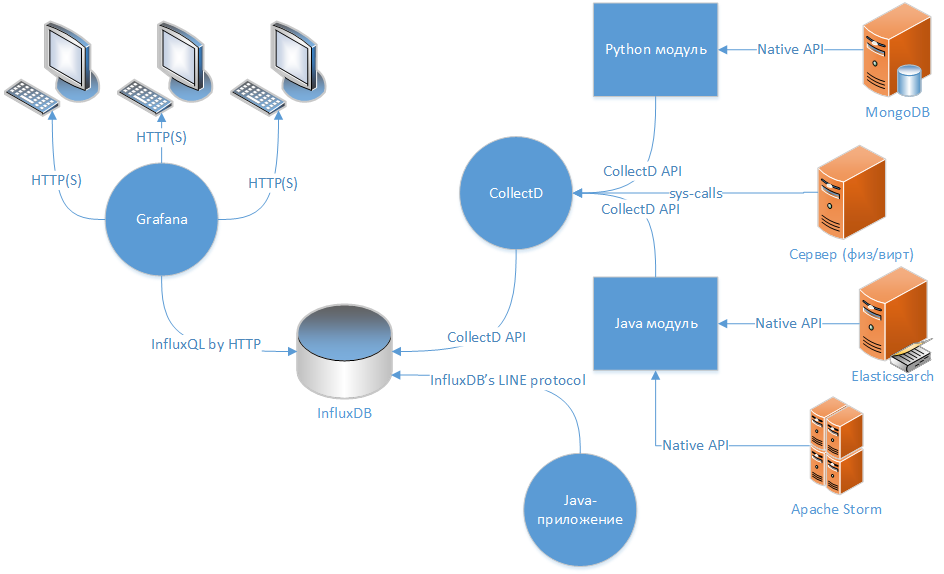
Когда я пришёл к выводу о необходимости мониторинга за проектом (как минимум серверной части) я решил, что идеальным вариантом для этого будет схема: «коллектор данных → TSDB → веб-клиент для отображения данных».
На текущий момент очень много статей посвящённых настройке Graphite в качестве TSDB, я же выбрал более современное и legacy-free решение на базе InfluxDB. Об InfluxDB уже писалось на Хабре в блоге компании Selectel. Не хочу копировать чужой текст, единственное могу сказать, что часть информации уже не соответствует действительности, но основа всё так же верна – система производительна, гибка, доступна для работы для разных языков и поддерживает разные протоколы других TSDB и агентов. Graphite же меня отпугнул наличием нескольких связанных друг с другом демонов, написанных на Python (излишняя сложность и дополнительные компоненты).
Выбор веб-клиента для отображения данных был сделан давно (видел его в действии давненько и всегда хотел использовать в своём проекте). Вот несколько скриншотов с моего проекта:
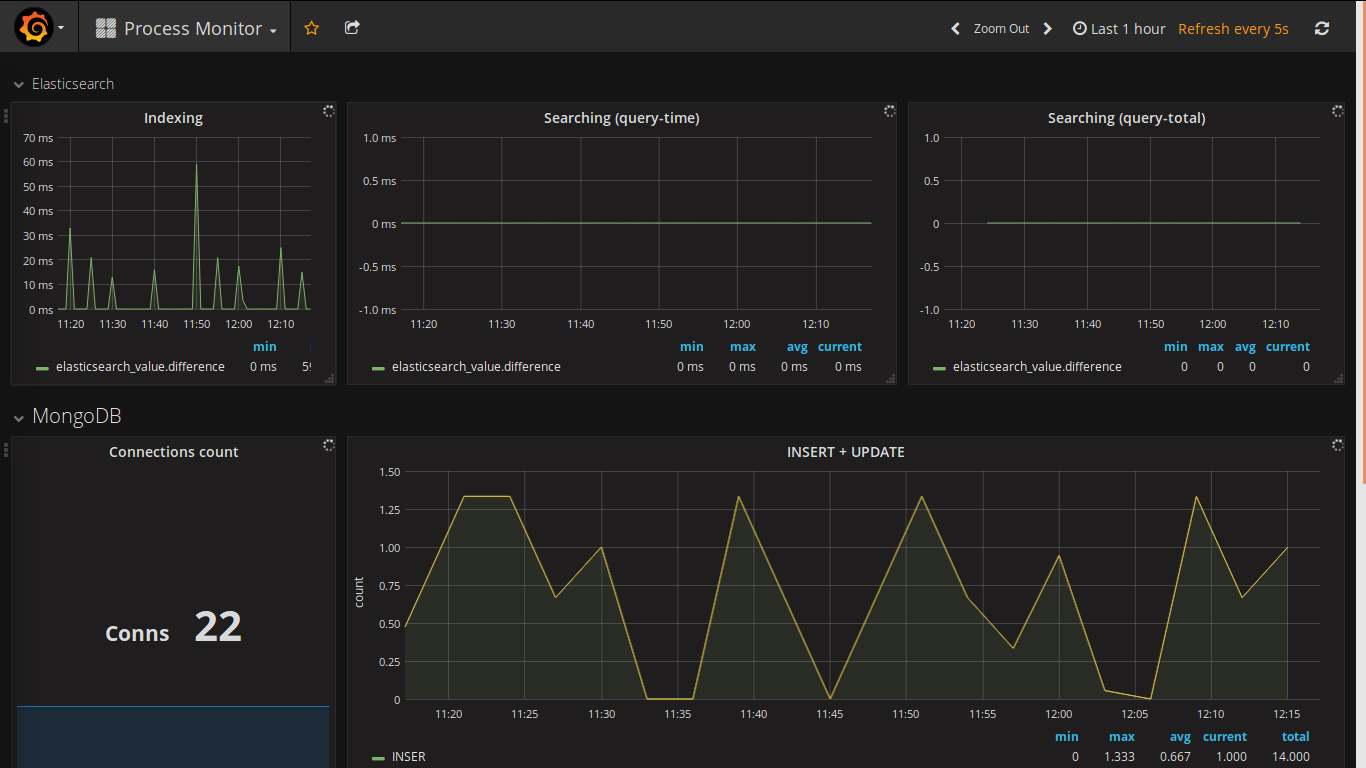
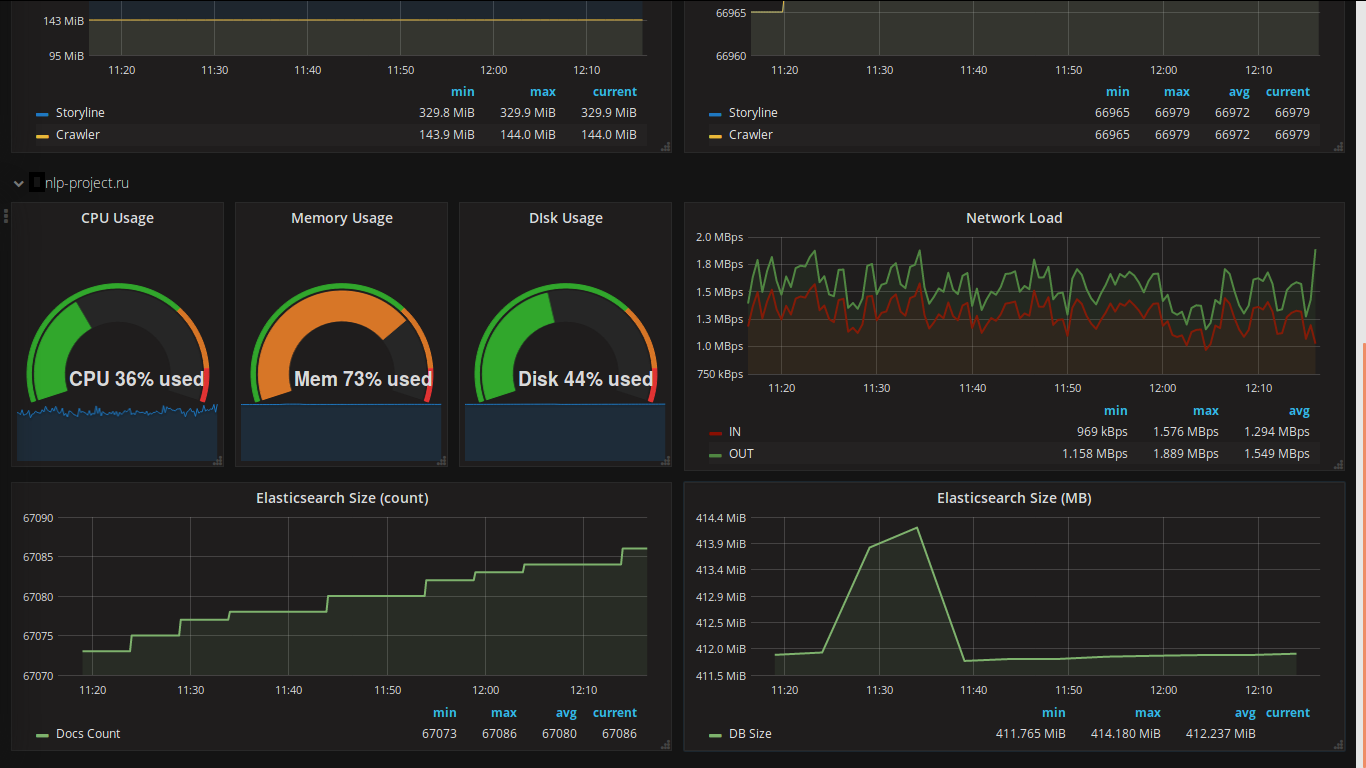
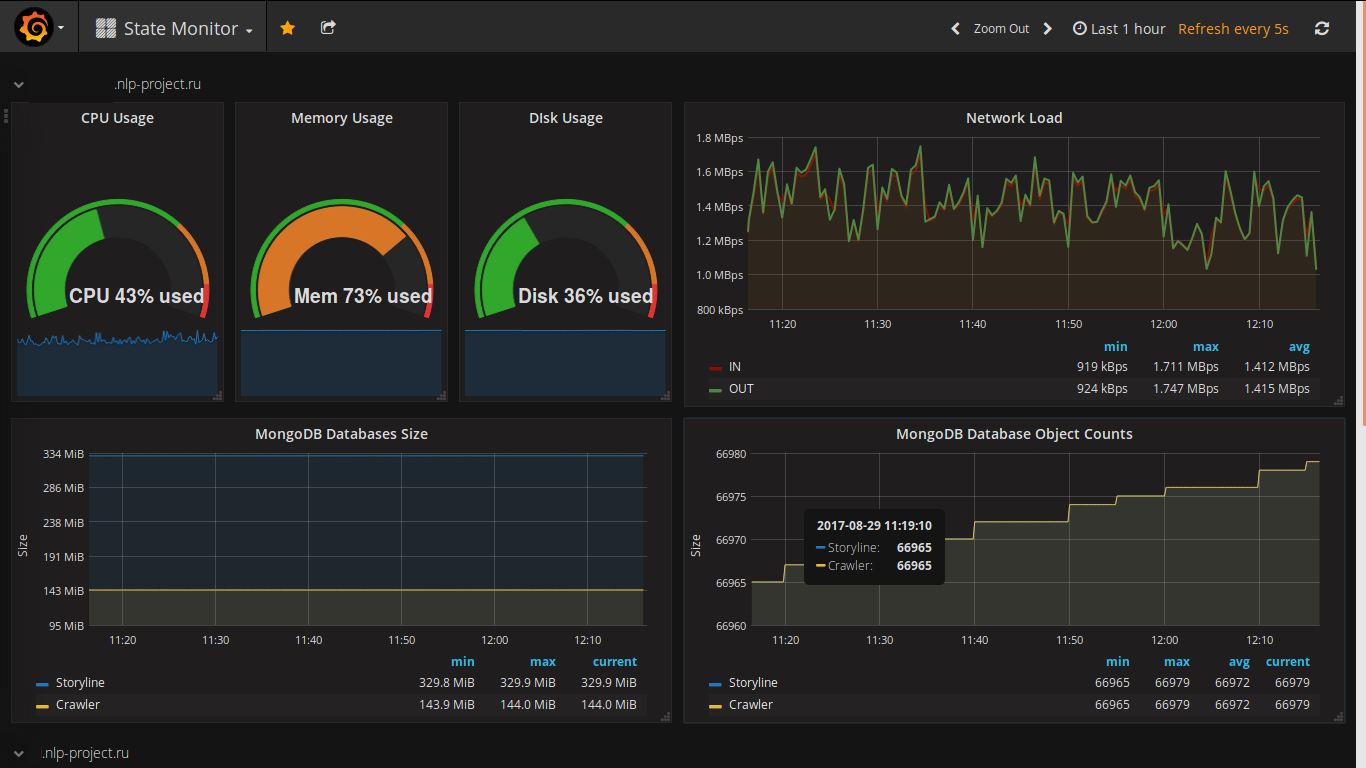
Особенностями grafana являются:
И ссылка на готовые dashboard'ы — есть чудесная возможность посмотреть как другие формируют графики и подчерпнуть что-то для себя (полезное и/или красивое). Я подчерпнул :)
Клиент, идущий в комплекте с самим InfluxDB – Chronograf пока не настолько хорош в части функционала.
Основным источником отображения данных являются time-series данные из InfluxDB, а в неё они попадают из 2-х источников: демона collectd и java-библиотеки «com.github.davidb:metrics-influxdb».
Collectd — демон, написанный на C, способный передавать данные своему сетевому аналогу, протокол которого InfluxDB и может эмулировать. «Из коробки» он может собирать достаточно большое количество метрик по серверному окружению и по части сервисов, возможность расширения достигается посредством модулей, написанных на python или Java.
Функционал collectd по сбору информации о функционировании сервера (физического и виртуального) меня вполне устраивает, однако дополнительные настройки требуемые для сбора данных со сторонних сервисов (в моём случае Elsticsearch, MongoDB и Apache Storm) достаточно нетривиальны и не всегда функциональны в полном объёме (например для Elsticsearch не корректно собирается информация по скорости выполнения запроса при наличии нескольких shard на разных репликах). Скорее всего следует посмотреть в сторону родного клиент InfluxDB — Telegraf.
Указанная библиотека фактически является адаптером для широко известной java-библиотеки метрик Metrics. Поддерживает протокол версии 0.9 для InfluxDB и позволяет передавать необходимую информацию в полном объёме.
Инициализация осуществляется примерно так:
В дальнейшем используется обычный Metrics API, что позволяет повысить прозрачность того что и как делается в моём ПО в любой момент времени.
Указанная система позволила не только следить за работой системы в рабочем режиме, но и отслеживать изменения, вызванные внесенными изменениями – как увеличилось потребление памяти, скорость обработки, объем данных и т.д. Сейчас, в принципе, страничка с общим дашбоардом является закладкой на кухонном ноутбуке и утренний завтрак всегда сопровождается просмотром событий за последние 9 часов.
Спасибо за внимание!
Сложные системы (распределённые/крупные/со сложной логикой/сложной системой данных) – как живой организм: подвижный, изменчивый и самостоятельный. Всё это требует постоянного контроля со стороны разработчиков/администраторов/DevOps-инженеров.
К этому выводу я пришёл, когда система несколько раз «загибалась» в ходе её разработки, настройки сервера и эксплуатации. Это натолкнуло меня на мысль, что мониторинг должен осуществляться не только на этапе производственной эксплуатации, но и на этапе разработки.
Обо всём по порядку…
Когда я пришёл к выводу о необходимости мониторинга за проектом (как минимум серверной части) я решил, что идеальным вариантом для этого будет схема: «коллектор данных → TSDB → веб-клиент для отображения данных».
Выбор TSDB
На текущий момент очень много статей посвящённых настройке Graphite в качестве TSDB, я же выбрал более современное и legacy-free решение на базе InfluxDB. Об InfluxDB уже писалось на Хабре в блоге компании Selectel. Не хочу копировать чужой текст, единственное могу сказать, что часть информации уже не соответствует действительности, но основа всё так же верна – система производительна, гибка, доступна для работы для разных языков и поддерживает разные протоколы других TSDB и агентов. Graphite же меня отпугнул наличием нескольких связанных друг с другом демонов, написанных на Python (излишняя сложность и дополнительные компоненты).
Puppet-скрипт для установки и настройки InfluxDB
class storyline_infra::influxdb () { include stdlib $params = lookup({"name" => "storyline_infra.influxdb", "merge" => {"strategy" => "deep"}}) $port_http = $params['port_http'] $port_rpc = $params['port_rpc'] $pid_file = $params['pid_file'] $init_script = $params['init_script'] $dir_data = $params['dir_data'] $dir_logs = $params['dir_logs'] $enabled_auth = $params['enabled_auth'] $enabled_startup = $params['enabled_startup'] $enabled_running = $params['enabled_running'] $version = $params['version'] $dist_name = $facts['os']['name'] user { 'influxdb': ensure => "present", managehome => true, } exec { "influxdb-mkdir": command => "/bin/mkdir -p /data/db && /bin/mkdir -p /data/logs", cwd => "/", unless => '/usr/bin/test -d /data/db -a -d /data/logs', } -> # working dir file { $dir_logs: ensure => "directory", recurse => "true", owner => "influxdb", group=> "influxdb", require => Exec['influxdb-mkdir'], } file { $dir_data: ensure => "directory", recurse => "true", owner => "influxdb", group=> "influxdb", require => Exec['influxdb-mkdir'], } # see by "gpg --verify keyfile" apt::key { 'influxdb-key': id => '05CE15085FC09D18E99EFB22684A14CF2582E0C5', source => 'https://repos.influxdata.com/influxdb.key', } -> # echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list apt::source { 'influxdb-repo': comment => 'influxdb repo', location => "https://repos.influxdata.com/${downcase($dist_name)}", release => "${facts['os']['distro']['codename']}", repos => 'stable', include => { 'deb' => true, }, } -> package { 'influxdb': ensure => $version, } -> file { "/etc/influxdb/influxdb.conf": replace => true, content => epp('storyline_infra/influxdb.epp'), owner => "influxdb", group=> "influxdb", notify => Service['influxdb'], }-> file { $init_script: replace => true, content => epp('storyline_infra/influxdb_startup.epp'), mode=>"ug=rwx,o=r", notify => Service['influxdb'], }-> service { 'influxdb': ensure => $enabled_running, enable => $enabled_startup, start => "${init_script} start", stop => "${init_script} stop", status => "${init_script} status", restart => "${init_script} restart", hasrestart => true, hasstatus => true, } if $enabled_startup != true { exec { "disable_influxdb": command => "/bin/systemctl disable influxdb", cwd => "/", } } logrotate::rule { 'influxdb': path => "${dir_logs}/*.log", rotate => 10, missingok => true, copytruncate => true, dateext => true, size => '10M', rotate_every => 'day', } }
Grafana
Выбор веб-клиента для отображения данных был сделан давно (видел его в действии давненько и всегда хотел использовать в своём проекте). Вот несколько скриншотов с моего проекта:
Особенностями grafana являются:
- Приятный внешний вид
- Динамичное обновление всех данных
- Визуальный конструктор
- Подключение большого количества типов источников данных (Graphite, InfluxDB, Prometheus, Elasticsearch…)
- Множество способов аутентификации
- Возможность отправки Alert`ов ( Slack, PagerDuty, VictorOps, OpsGenie...)
- Большое количество plugin`ов для расширения функционала
И ссылка на готовые dashboard'ы — есть чудесная возможность посмотреть как другие формируют графики и подчерпнуть что-то для себя (полезное и/или красивое). Я подчерпнул :)
Клиент, идущий в комплекте с самим InfluxDB – Chronograf пока не настолько хорош в части функционала.
Puppet-скрипт для установки и настройки Grafana
class storyline_infra::grafana () { include stdlib $params = lookup({"name" => "storyline_infra.grafana", "merge" => {"strategy" => "deep"}}) $port = $params['port'] $pid_file = $params['pid_file'] $init_script = $params['init_script'] $dir_data = $params['dir_data'] $dir_logs = $params['dir_logs'] $enabled_startup = $params['enabled_startup'] $enabled_running = $params['enabled_running'] $version = $params['version'] user { 'grafana': ensure => "present", managehome => true, } exec { "grafana-mkdir": command => "/bin/mkdir -p /data/db && /bin/mkdir -p /data/logs", cwd => "/", unless => '/usr/bin/test -d /data/db -a -d /data/logs', } -> # working dir file { $dir_logs: ensure => "directory", recurse => "true", owner => "grafana", group=> "grafana", require => Exec['grafana-mkdir'], } file { $dir_data: ensure => "directory", recurse => "true", owner => "grafana", group=> "grafana", require => Exec['grafana-mkdir'], } # see by "gpg --verify keyfile" apt::key { 'grafana-key': id => '418A7F2FB0E1E6E7EABF6FE8C2E73424D59097AB', source => 'https://packagecloud.io/gpg.key', } -> # deb https://packagecloud.io/grafana/stable/debian/ jessie main apt::source { 'grafana-repo': comment => 'grafana repo', location => "https://packagecloud.io/grafana/stable/debian/", release => "jessie", repos => 'main', include => { 'deb' => true, }, } -> package { 'grafana': ensure => 'present', } file { '/etc/init.d/grafana-server': ensure => 'absent', } -> file { '/etc/grafana': ensure => "directory", } -> file { "/etc/grafana/grafana.ini": replace => true, content => epp('storyline_infra/grafana.epp'), owner => "grafana", group=> "grafana", notify => Service['grafana'], } -> file { $init_script: replace => true, content => epp('storyline_infra/grafana_startup.epp'), mode=>"ug=rwx,o=r", notify => Service['grafana'], }-> service { 'grafana': ensure => $enabled_running, enable => $enabled_startup, start => "${init_script} start", stop => "${init_script} stop", status => "${init_script} status", restart => "${init_script} restart", hasrestart => true, hasstatus => true, } if $enabled_startup != true { exec { "disable_grafana": command => "/bin/systemctl disable grafana", cwd => "/", } } }
О сборе данных
Основным источником отображения данных являются time-series данные из InfluxDB, а в неё они попадают из 2-х источников: демона collectd и java-библиотеки «com.github.davidb:metrics-influxdb».
Collectd
Collectd — демон, написанный на C, способный передавать данные своему сетевому аналогу, протокол которого InfluxDB и может эмулировать. «Из коробки» он может собирать достаточно большое количество метрик по серверному окружению и по части сервисов, возможность расширения достигается посредством модулей, написанных на python или Java.
Функционал collectd по сбору информации о функционировании сервера (физического и виртуального) меня вполне устраивает, однако дополнительные настройки требуемые для сбора данных со сторонних сервисов (в моём случае Elsticsearch, MongoDB и Apache Storm) достаточно нетривиальны и не всегда функциональны в полном объёме (например для Elsticsearch не корректно собирается информация по скорости выполнения запроса при наличии нескольких shard на разных репликах). Скорее всего следует посмотреть в сторону родного клиент InfluxDB — Telegraf.
Puppet-скрипт для установки и настройки Collectd
class storyline_infra::collectd () { include stdlib $params = lookup({"name" => "storyline_infra.collectd", "merge" => {"strategy" => "deep"}}) $server_port = $params['server_port'] $server_address = $params['server_address'] $pid_file = $params['pid_file'] $init_script = $params['init_script'] $dir_data = $params['dir_data'] $dir_logs = $params['dir_logs'] $enabled_startup = $params['enabled_startup'] $enabled_running = $params['enabled_running'] $version = $params['version'] # mongo db $enabled_mongodb = $params['enabled_mongodb'] $mongodb_user = $params['mongodb_user'] $mongodb_password = $params['mongodb_password'] # storm db $enabled_storm = $params['enabled_storm'] $storm_ui_url = $params['storm_ui_url'] # elasticsearch $enabled_elasticsearch = $params['enabled_elasticsearch'] $elasticsearch_host = $params['elasticsearch_host'] $elasticsearch_port = $params['elasticsearch_port'] $elasticsearch_cluster = $params['elasticsearch_cluster'] exec { "collectd-mkdir": command => "/bin/mkdir -p /data/db && /bin/mkdir -p /data/logs", cwd => "/", unless => '/usr/bin/test -d /data/db -a -d /data/logs', } -> # working dir file { $dir_logs: ensure => "directory", recurse => "true", require => Exec['collectd-mkdir'], } file { $dir_data: ensure => "directory", recurse => "true", require => Exec['collectd-mkdir'], } package { 'collectd': # ensure => $version, ensure => "present", } -> file { "/etc/collectd/collectd.conf": replace => true, content => epp('storyline_infra/collectd.epp'), notify => Service['collectd'], }-> file { $init_script: replace => true, content => epp('storyline_infra/collectd_startup.epp'), mode=>"ug=rwx,o=r", notify => Service['collectd'], }-> service { 'collectd': ensure => $enabled_running, enable => $enabled_startup, start => "${init_script} start", stop => "${init_script} stop", status => "${init_script} status", restart => "${init_script} restart", hasrestart => true, hasstatus => true, } if $enabled_startup != true { exec { "disable_collectd": command => "/bin/systemctl disable collectd & /bin/systemctl disable collectd.service", cwd => "/", } } if $enabled_mongodb { package { 'python-pip': ensure => "present", } -> exec { "install-pymongo": command => "/usr/bin/python -m pip install pymongo", cwd => "/", unless => '/usr/bin/python -m pip show pymongo', } -> file { "/usr/share/collectd/mongodb": ensure => "directory", }-> file { "/usr/share/collectd/mongodb.py": replace => true, content => epp('storyline_infra/collectd_mongodb_py.epp'), }-> file { "/usr/share/collectd/mongodb/types.db": replace => true, content => epp('storyline_infra/collectd_mongodb_types_db.epp'), }-> file { "/etc/collectd/collectd.conf.d/mongodb.conf": replace => true, content => epp('storyline_infra/collectd_mongodb_conf.epp'), notify => Service['collectd'], } } # if $enabled_mongodb { # https://github.com/srotya/storm-collectd if $enabled_storm { file { "/usr/share/collectd/java/storm-collectd.jar": replace => true, ensure => file, source => "puppet:///modules/storyline_infra/storm-collectd.jar", }-> file { "/etc/collectd/collectd.conf.d/storm.conf": replace => true, content => epp('storyline_infra/collectd_storm_conf.epp'), notify => Service['collectd'], } } # if $enabled_mongodb { # https://github.com/signalfx/integrations/tree/master/collectd-elasticsearch # https://github.com/signalfx/collectd-elasticsearch if $enabled_elasticsearch { file { "/usr/share/collectd/elasticsearch.py": replace => true, content => epp('storyline_infra/collectd_elasticsearch_py.epp'), }-> file { "/etc/collectd/collectd.conf.d/elasticsearch.conf": replace => true, content => epp('storyline_infra/collectd_elasticsearch_conf.epp'), notify => Service['collectd'], } } # if $enabled_mongodb { }
com.github.davidb:metrics-influxdb
Указанная библиотека фактически является адаптером для широко известной java-библиотеки метрик Metrics. Поддерживает протокол версии 0.9 для InfluxDB и позволяет передавать необходимую информацию в полном объёме.
Инициализация осуществляется примерно так:
if (metricsConfiguration.enabled) { String hostName = InetAddress.getLocalHost().getCanonicalHostName(); final ScheduledReporter reporterInfluxDB = InfluxdbReporter.forRegistry(metricRegistry) .protocol(new HttpInfluxdbProtocol("http", metricsConfiguration.influxdbHost, metricsConfiguration.influxdbPort, metricsConfiguration.influxdbUser, metricsConfiguration.influxdbPassword, metricsConfiguration.influxdbDB)) // rate + dim conversions .convertRatesTo(TimeUnit.SECONDS).convertDurationsTo(TimeUnit.MILLISECONDS) // filter .filter(MetricFilter.ALL) // don't skip .skipIdleMetrics(false) // hostname tag .tag("host", hostName) // !!! converter // al metrics must be of form: "processed_links.site_ru .crawling" -> "crawling // source=site_ru, param=processed_links value=0.1" .transformer(new CategoriesMetricMeasurementTransformer("param", "source")) .build(); reporterInfluxDB.start(metricsConfiguration.reportingPeriod, TimeUnit.SECONDS); }
В дальнейшем используется обычный Metrics API, что позволяет повысить прозрачность того что и как делается в моём ПО в любой момент времени.
Указанная система позволила не только следить за работой системы в рабочем режиме, но и отслеживать изменения, вызванные внесенными изменениями – как увеличилось потребление памяти, скорость обработки, объем данных и т.д. Сейчас, в принципе, страничка с общим дашбоардом является закладкой на кухонном ноутбуке и утренний завтрак всегда сопровождается просмотром событий за последние 9 часов.
Спасибо за внимание!

