Всем привет.
С середины 2016 года мы проектируем и разрабатываем новое поколение платформы. Принципиальное отличие от первого поколения — поддержка API "тонкого" клиента. Если старая платформа предполагает, что на клиента при запуске загружается метаинформация о всем контенте, который доступен для абонента, то новая платформа должна отдавать срезы данных отфильтрованные и отсортированы для отображения на каждом экране/странице.
Высокоуровневая архитектура на уровне хранения данных внутри системы — постоянное хранение всех данных в централизованном реляционном SQL хранилище. Выбор пал на Postgres, тут никаких откровений. В качестве основного языка для разработки — выбрал golang.
У системы порядка 10м пользователей. Мы посчитали, что с учетом профиля теле-смотрения, 10М пользователей может дать сотни тысяч RPS на всю систему.

Это означает, что запросы от клиентов и близко не стоит подпускать к реляционной SQL БД без кэширования, а между SQL БД и клиентами должен быть хороший кэш.
Посмотрели на существующие решения — погоняли прототипы. Данных, по современным меркам у нас немного, но параметры фильтрации (читай бизнес-логика) — сложные, и главное персонализированные — зависящие от сессии пользователя, т.е. использовать параметры запроса как ключ кэширования в K-V кэше будет очень накладно, тем более пейджинг и богатый набор сортировок никто не отменял. По сути, под каждый запрос от пользователя формируется полностью уникальный набор отфильтрованных записей.
По итогам отсмотра готовых решений ничего не подошло. Простые K-V базы типа Redis отбросили практически сразу: не подходит по функционалу — всю фильтрацию и объединение придётся реализовывать на Application Level, а это накладно. Посмотрел на Tarantool. тоже не подошел функционально
Смотрели на Elastic — функционально подошел. Но производительность выдачи контента по требованиям бизнес-логики вышла в районе 300-500 RPS.
При ожидаемой нагрузке даже в 100К RPS — под эластик впритык нужно 200-300 серверов. В деньгах — это несколько миллионов долларов.
Когда это посчитали, у меня в голове уже практически созрел план — написать свой велик, in-memory движок кэша на C++ и провести наши тесты на нем. Сказано — сделано. Прототип был реализован практически за пару недель. Запустили тесты.
Вау! Получили 15к RPS на том же железе, с теми же условиями, где Elastic давал 500.
Разница в 20 раз. Больше чем на порядок, Карл!
Первая, уже не Proof-Of-Concept версия бэкенда со своим in-memory кэшем появилась в конце 2016 года. К середине 2017 Reindexer уже оформился во вполне полноценную БД, обзавелся собственным хранилищем и движком полнотекстового поиска, в это же время мы опубликовали ее на github.

Технические детали
Reindexer — это NoSQL in-memory БД общего назначения. По структуре хранения данных Reindexer сочетает все основные подходы:
- оптимизированное бинарное представление JSON с дополнением из табличной строки с индексируемыми полями
- опциональное колоночное хранение выбранных индексных полей
Такое сочетание позволяет добиться максимальной скорости доступа к значениям полей, а с другой стороны не требовать от приложения определения жесткой схемы данных.
Индексы
Для выполнения запросов есть 4 типа индекса:
- хэш таблица, самый быстрый индекс, для выборки по значению
- бинарное дерево, с возможностью быстрых выборок по условиям '<', '>' и сортировкой по полю
- колонка, минимальный оверхед по памяти, но поиск медленнее, чем у бинарного дерева и хэша
- полнотекстовый индекс, а точнее даже два: быстрый, не требовательный к памяти, и продвинутый на базе триграмм
При вставке записей в таблицы используется методика "ленивого" построения индексов т.е. вне зависимости от количества индексов, вставка происходит практически мгновенно, а индексы достраиваются только в тот момент, когда они требуются для выполнения запроса.
Дисковое хранилище
Вообще, Reindexer — полностью in-memory база данных, то есть, все данные с которыми работает Reindexer должны находиться в оперативной памяти. Поэтому, основное назначение дискового хранилища — загрузка данных на старте.
При добавлении записей в Reindexer данные в фоновом режиме пишутся на диск, практически не внося задержек на процесс вставки.
В качестве бэкенда дискового хранилища Reindexer использует leveldb.
Полнотекстовый поиск
Для полнотекстового поиска в Reindexer есть два собственных движка:
fast, с минимальными требованиями по памяти, на базе suffixarray, c поддержкой морфологии и опечаток.fuzzy, триграммный — дает лучшее качество поиска, но конечно требует больше памяти и работает медленнее. Пока он в экспериментальном статусе.
В обоих движках есть поддержка поиска транслитом и поиска с неверной раскладкой клавиатуры. Ранжирование результатов поиска происходит с учетом статистических вероятностей (BM25), точности совпадения и еще примерно 5 параметров. Формулу ранжирования можно гибко настроить в зависимости от решаемых задач.
Так же, есть возможность полнотекстового поиска по нескольким таблицам, с выдачей результатов отсортированных по релевантности.
Для формирования запросов к полнотекстовому поиску используется специальный DSL.
Join
Reindexer умеет делать Join. Если быть точным, в мире NoSQL, как правило, нет операции Join в чистом виде, а есть функционал, позволяющий вставить в каждый результат ответа поле, содержащее сущности из присоединяемой таблицы. Например, в Elastic этот функционал называется nested queries, в mongo — lookup aggregation.
В Reindexer этот функционал называется Join. Поддерживается механика left join и inner join.
Кэш десериализованных объектов
Данные в Reindexer хранятся в области памяти управляемой C++, и при получении выборки в golang приложении происходит десериализация результатов в golang структуру. Вообще, между прочим, у golang части Reindexer очень быстрый десериализатор: примерно в 3-4 раза быстрее JSON, и раза в 2 быстрее BSON. Но даже с учетом этого, десериализация — относительно медленная операция, которая создает новые объекты на куче и нагружает GC.
Object cache в golang части Reindexer-а решает задачу пере использования уже десериализованных объектов, не тратя лишнее время на медленную повторную десериализацию.
Использование Reindexer в Golang приложении
Пора перейти от слов к делу, и посмотреть как использовать Reindexer в golang приложении.
Интерфейс для Reindexer реализован в виде Query builder, например запросы в таблицы пишутся таким способом:
db := reindexer.NewReindex("builtin") db.OpenNamespace("items", reindexer.DefaultNamespaceOptions(), Item{}) it := db.Query ("media_items").WhereInt ("year",reindexer.GT,100).WhereString ("genre",reindexer.SET,"action","comedy").Sort ("ratings") for it.Next() { fmt.Println (it.Object()) }
Как видно из примера, можно конструировать сложные выборки по многим условиям фильтрации и с произвольными сортировками.
package main // Импортируем пакеты import ( "fmt" "math/rand" "github.com/restream/reindexer" // Выбор способа подключения Reindexer к приложения (в этом случае `builtin`, означает линковку в виде статической библиотеки) _ "github.com/restream/reindexer/bindings/builtin" ) // Определяем структуру с индексными полями, которые помечаем тэгом 'reindex' type Item struct { ID int64 `reindex:"id,,pk"` // 'id' первичный ключ Name string `reindex:"name"` // Добавляем хэш индекс по полю 'name' Articles []int `reindex:"articles"` // Добавляем хэш индекс по массиву 'articles' Year int `reindex:"year,tree"` // Добавляем btree индекс по полю 'year' Descript string // Просто поле в структуре, не индексируется } func main() { // Инициализируем БД, и выбираем биндинг 'builtin' db := reindexer.NewReindex("builtin") // Включаем дисковое хранилище (опциональный шаг) db.EnableStorage("/tmp/reindex/") // Создаем новую таблицу (namespace) с названием 'items', в которой будут храниться записи типа 'Item' db.OpenNamespace("items", reindexer.DefaultNamespaceOptions(), Item{}) // Генерируем рандомный датасет for i := 0; i < 100000; i++ { err := db.Upsert("items", &Item{ ID: int64(i), Name: "Vasya", Articles: []int{rand.Int() % 100, rand.Int() % 100}, Year: 2000 + rand.Int()%50, Descript: "Description", }) if err != nil { panic(err) } } // Делаем запрос к таблице 'items' - получаем 1 элемент, у которого поле id == 40 elem, found := db.Query("items"). Where("id", reindexer.EQ, 40). Get() if found { item := elem.(*Item) fmt.Println("Found document:", *item) } // Далеам запрос к таблице 'items' - получаем выборку элементов query := db.Query("items"). Sort("year", false). // Сортировка по полю 'year' в порядке возрастания WhereString("name", reindexer.EQ, "Vasya"). // В поле 'name' ищем значение 'Vasya' WhereInt("year", reindexer.GT, 2020). // В поле 'year' должно быть значение больше 2020 WhereInt("articles", reindexer.SET, 6, 1, 8). // В массиве 'articles' должно быть хотя одно из значений [6,1,8] Limit(10). // Вернуть не более 10-ти записей Offset(0). // с 0 позиции ReqTotal() // Запрос подсчета общего количества записей в таблице, удовлетворяющих условиям выборки // Выполнить запрос с БД iterator := query.Exec() // Не забыть закрыть Iterator defer iterator.Close() // Проверить, была ли ошибка в запросе if err := iterator.Error(); err != nil { panic(err) } fmt.Println("Found", iterator.TotalCount(), "total documents, first", iterator.Count(), "documents:") // Итерируемся по результатам запроса for iterator.Next() { // Получить следующий результат выборки и привести тип elem := iterator.Object().(*Item) fmt.Println(*elem) } }
Кроме Query Builder в Reindexer-е есть встроенная поддержка запросов в SQL формате.
Производительность
Одной из главных мотивирующих причин появления Reindexer-а — была разработка самого производительного решения, существенно превосходящего существующие решения. Поэтому статья была бы не полной без конкретных цифр — замеров производительности.
Мы провели сравнительное нагрузочное тестирование производительности Reindexer и других популярных SQL и NoSQL БД. Основным объектом сравнения исторически выступает Elastic и MongoDB, которые функционально наиболее близки к Reindexer.
Так же в тестах участвуют Tarantool и Redis, которые функционально скромнее, но тем не менее так же часто используются в качестве кэша горячих данных между SQL DB и клиент API.
Для полноты картины в список тестируемых БД включили пару SQL решений — Mysql и Sqlite.
В Reindexer есть полнотекстовый поиск, поэтому мы не смогли отказать себе в соблазне сравнить производительность со Sphinx
И последний участник — Clickhouse. Вообще, Clickhouse — БД заточенная под другие задачи, но тем не менее, к нам периодически прилетают вопросы, 'а почему не Clickhouse', поэтому решили добавить в тесты и его.
Бенчмарки и их результаты
Начнем с результатов, а технические детали тестов, описание методики и датасет сразу после графиков.
- Получить запись по первичному ключу. Эта функциональность есть во всех БД участвующих в тесте.

- Получить список из 10-ти сущностей с фильтрацией по одному полю, не primary key
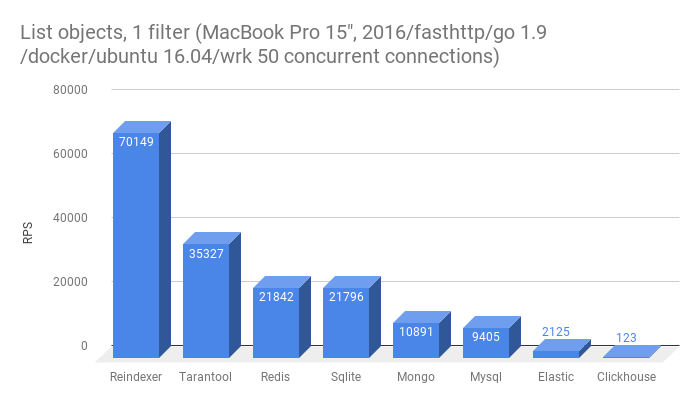
- Получить список из 10-ти сущностей с фильтрацией по двум полям
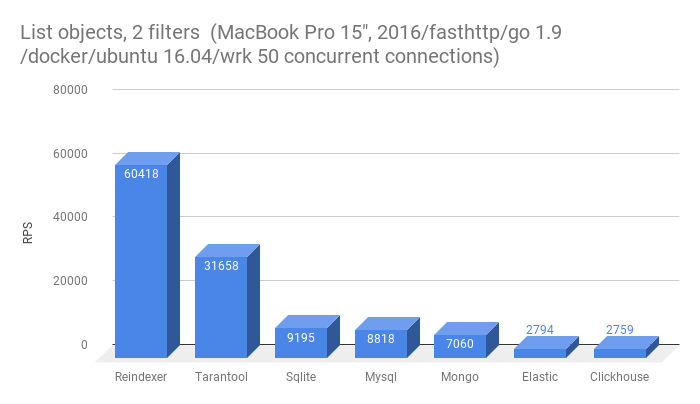
Из этого теста выбыл Redis, да в нем есть возможность эмуляции secondary index, однако это требует от приложения дополнительных действий при сохранении/загрузки записей в Redis.
- Перезаписать сущность в БД
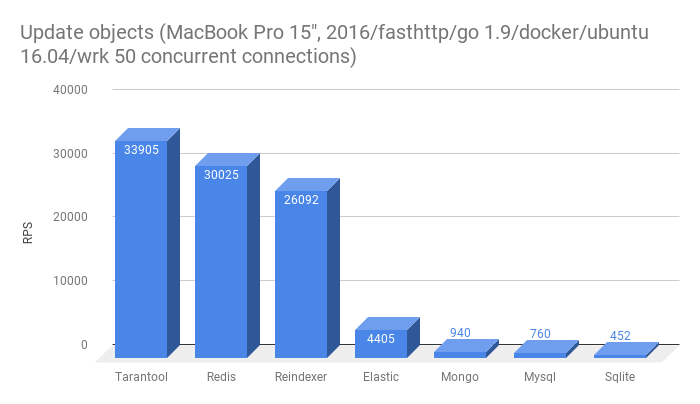
Из этого теста выбыл Clickhouse, т.к. в нем нет поддержки Update. Низкая скорость перезаписи в многие базы — скорее всего результат наличия полнотекстового индекса в таблице, в которую вставляются данные. У Tarantool и Redis нет полнотекстого поиска.
- Полнотекстовый поиск точных словоформ
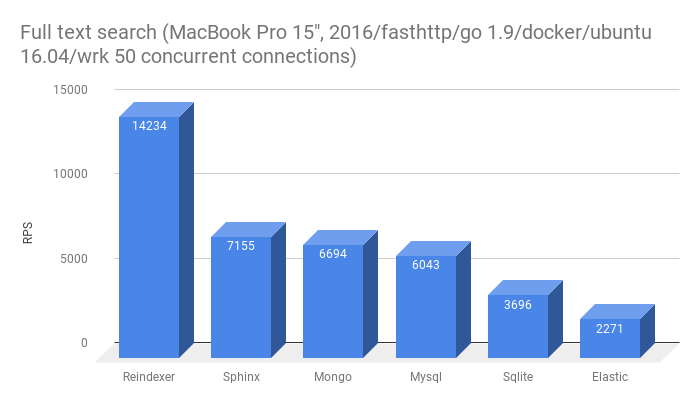
- Полнотекстовый поиск неточных словоформ (префиксы и опечатки)

Среда тестирования
Все тесты проводились в docker контейнере, запущенном на MacBookPro 15", 2016. Гостевая ОС — Ubuntu 16.04 LTS. Чтобы минимизировать влияние сетевого стека, все БД, тестовый микро-бэкенд и обстрел запускались внутри общего контейнера и все сетевые соединения были на localhost.
На контейнер выделено 8GB ОЗУ и все 8 ядер CPU.
Тестовый бэкенд
Для проведения тестов мы сделали микро-бэкенд на golang, обрабатывающий запрос на url-ы вида: http://127.0.0.1:8080/<название теста>/<название БД>
Структура микро-бэкенда хоть и очень простая, но повторяет структуру реального приложения: есть слой репозитория с коннекторами к тестируемым БД и слой http API, отдающий ответы клиенту в JSON формате.
Для обработки http запросов используется пакет fasthttp, для сериализации ответов — штатный пакет encoding/json.
Работа с SQL БД через пакет sqlx. Connection Pool — 8 соединений. Немного забегая вперед, это число получено экспериментально — с такими настройками SQL базы дали лучший результат.
Для работы с Elastic использован gopkg.in/olivere/elastic.v5 — с ним пришлось немного поколдовать. Штатно он никак не хотел работать в режиме keep alive — проблему удалось решить только передав ему http.Client с настройкой MaxIdleConnsPerHost:100.
Коннекторы Tarantool, Redis, Mongo не доставили хлопот — они из коробки эффективно работают в многопоточном режиме и не нашлось никаких настроек, позволяющих существенно их ускорить.
Больше всего хлопот доставил коннектор Sphinx github.com/yunge/sphinx — он не поддерживает много поточность. А тестировать в 1 поток — заведомо не корректный тест.
Поэтому нам ничего не оставалось делать, как реализовать свой connection pool для этого коннектора.
Тестовые данные
В тестовом сете данных 100к записей. В записи 4 поля:
idуникальный идентификатор записи, число от 0 до 99999nameимя. строка из двух случайных имен. ~1000 уникальных ключейyearгод. целое число от 2000 до 2050descriptionслучайный текст 50 слов из словаря в 100к слов
Размер каждой записи в формате Json ~ 500 байт. Пример записи
{ "id": 73, "name": "welcome ibex", "description": "cheatingly ... compunction ", "year": 2015 }
Обстрел
Обстрел велся утилитой wrk в 50 конкурирующих соединений. На каждый тест каждой базы проводилось 10 обстрелов и выбирался лучший результат. Между тестами пауза в несколько секунд, чтобы не дать процессору перегреться и уйти в throttling.
Итоги тестов
В рамках тестов было важно собрать решение, по структуре аналогичное продакшн решению, без 'триков', `хаков' и в равных условиях для всех БД входящих в тест.
Бенчмарки не претендуют на 100% полноту, но в них отражен основной набор кейсов работы с базой.
Исходники микробэкенда и Dockerfile тестов я разместил на github, и при желании их не сложно воспроизвести.
Что дальше
Сейчас основная функциональность Reindexer стабилизирована и Production Ready. Golang API стабилизирован, и в нем не ожидается breaking changes в обозримом будущеем.
Однако, Reindexer пока еще очень молодой проект, ему чуть больше года, в нем пока не все реализовано. Он активно развивается и улучшается и, как следствие, внутренний C++ API еще не зафиксирован и иногда он меняется.
Сейчас доступно три варианта подключения Reindexer-а к проекту:
- библиотекой к Golang
- библиотекой к C++
- standalone server, работающий по http протоколу
В планах есть реализация биндинга для Python и реализация бинарного протокола в сервере.
Также, в настоящий момент не реализована репликации данных между нодами на уровне Reindex-а. Для основного кейса использования Reindexer, как быстрого кэша между SQL и клиентами — это не критично. Ноды реплицируют данные с SQL на уровне Application, и этого кажется вполне хватает.
Вместо заключения
Кажется, получилось реализовать красивое и, не побоюсь этого слова, уникальное решение, которое сочетает в себе функциональность сложных БД и производительность в разы, а то и на порядок превосходящее существующее решения.
Что самое важное — Reindexer позволяет сэкономить миллионы долларов на железе уже сейчас, при этом не увеличивая затраты на разработку Application Level — ведь Reindexer обладает высокоуровневым API, использование которого не сложнее обычного SQL или ORM.
PS. В комментариях попросили добавить ссылку на github в конце статьи. Вот она:
Репозиторий Reindexer на github.

